以企业入侵检测日志分析为场景漫谈大数据安全
转载:http://netsecurity.51cto.com/art/201506/478622.htm
前言
写这篇文章有三个原因,一是在工作中一直艰难地摸索着这块也曾写过一篇很粗略的大数据之安全漫谈 (想继续吐槽);二是看到了阿里的招聘广告-一起来聊聊这个新职位:大数据安全分析师;三是整个2015的RSA会议 Intelligence Data-Driven 出境率太高了,于是想谈谈。

大数据安全,顾名思义,用大数据技术解决安全问题。核心——解决安全问题,手段——大数据技术。
我们从核心出发,安全问题抽象来说就是攻击与防御,接下来明确防御对象是什么?攻击目的是什么?攻击手段是怎样的?攻击者的特征?一句话——搞清楚谁为了什么目的通过什么手段攻击了谁。
比如说防御对象有企业内部安全,有对外发布产品安全,同时防御对象又决定了不同的攻击目的与攻击手段,有企业入侵,有对产品本身的攻击(比如说软件破解,游戏外挂,订单欺诈),有对产品用户的攻击(比如利用支付漏洞窃取用户财产),同样发起攻击的攻击者们特征又是迥异的,有无特定目的批量散弹攻击,有靠接单挣钱的赏金黑客,有外挂作坊等等。
在明确了的问题后,接下来就是确定解决问题的方法,传统方法的缺陷是什么?大数据技术解决问题的优势又是什么?比如说WAF系统中,传统的检测机制——基于签名库(黑名单),缺陷是对未知漏洞(0day) 不可感知。解决方案——基于异常(白名单),如何鉴定异常——机器学习(学习正常的行为模式),如何对大量数据鉴定异常——大数据技术支撑下的机器学习。
在这一过程,我们需要具备领域知识(安全知识),数据科学知识(数据分析知识,机器学习,文本分析,可视化),大数据知识(数据收集,数据存储,数据传输,数据分布式计算),编程知识。
路漫漫其修远兮,吾将死磕到底…
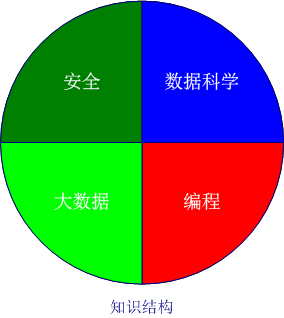
本文就以企业入侵检测日志分析为场景来谈谈大数据安全。
一、安全领域
大数据安全分析最容易走偏的就是过度强调数据计算平台(大数据),算法(机器学习),而失去了本心,忽略了我们使用这一技术的目的,以入侵检测为例,我们希望日志分析达到以下目的:
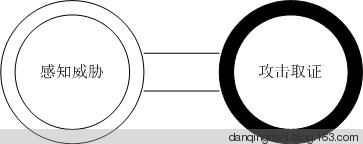
如何感知威胁,我们可以先对攻击者进行画像,攻击手段进行建模。
1. 攻击者画像

这里是非常粗略的分类,实际上我们可以用关系图(社交网挖掘)的方式将攻击者关联起来,对取证抓坏人也是有效果的。
2. 攻击手段建模
相信喜欢撸paper、ppt的人对Attack Models、 Attack Trees、 Kill Chain这三个术语特别熟悉,特别是看过2013年后的各大安全会议文档后,其实说的都是攻击行为建模。
(1) 渗透模型

(2)普通攻击模型

(3)攻击模型(升级版)
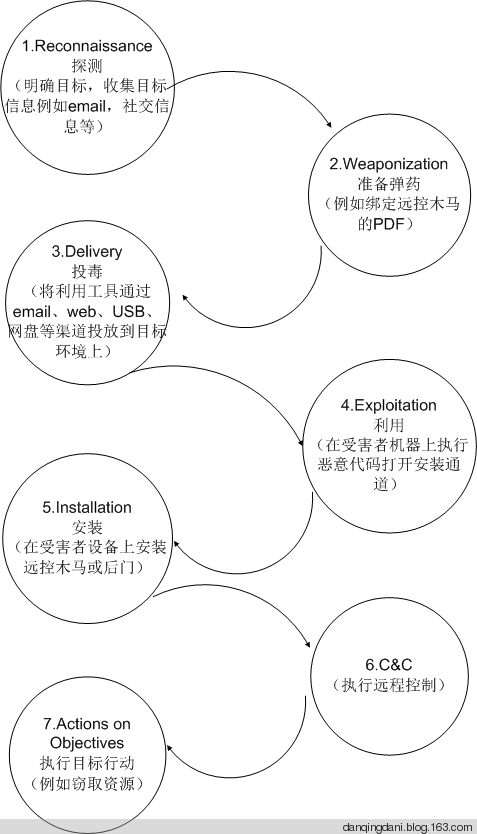
注意以上攻击手段只是高度精炼的攻击环节,实际的攻击检测中,我们需要尽可能精确的还原入侵场景(包括对应的正常场景是怎样的),从入侵场景中提炼关键环节,从而检测出异常的攻击行为。
在熟悉了杀生链(kill chain)后,接下来要做的就是在构成链的每个环节进行狙击,注意越往后成本越高。而每个阶段的操作必然会雁过留痕,这些痕迹,就是我们进行数据分析的数据源,知道对什么数据进行分析是最最重要的(数据量要恰到好处,要多到足够支撑数据分析与取证,要少到筛选掉噪音数据)。
二、数据科学
在明确了我们要解决的问题,接下来我们来普及一下数据分析的基本流程:
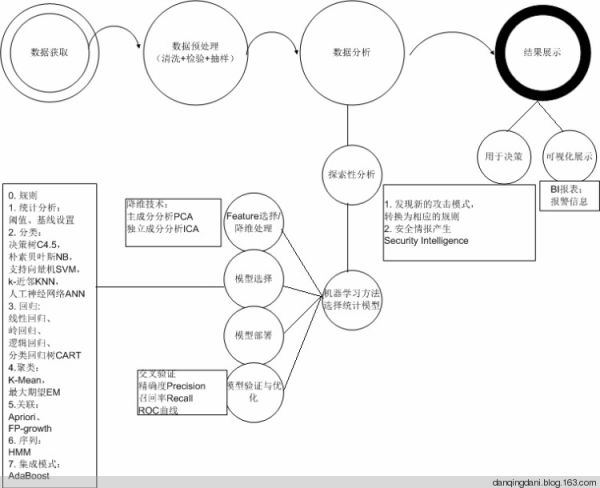
从上图可以看出,传统的数据分析在模型选择上都仅仅用了0——规则,1——统计分析,设置基线,依靠阈值的方法。
数据分析与领域知识是紧密耦合的,千万不要误入套用算法的误区,要进行基于行为建模(攻击行为,正常行为)的数据分析,可以从单点分析(单条数据的深度分析,例如分析单条HTTP请求是否是攻击请求),简单的关联分析(例如分析一个session下,多条HTTP请求的关联关系,是否为扫描器行为,是否有尝试绕过WAF的操作,是否符合攻击链的关键步骤),复杂的关联分析(例如Web日志,数据库日志,操作系统日志的联动分析,例如SQL注入写马攻击中HTTP请求对应的数据库操作,主机操作)来逐步深入分析,当攻击场景很复杂的时候,我们可以考虑从结果出发的方式来回溯,这些技巧都取决于领域知识。
下面列举一些传统的关联技巧:
1.规则关联
If the system sees an EVENT E1 where E1.eventType=portscan
followed by
an event E2 where E2.srcip=E1.srcip and E2.dstip = E1.dstip and
E2.eventType = fw.reject then
doSomething
2.漏洞关联:将漏洞扫描数据和实时事件数据结合起来,以便帮助减少假阳性 false positive
e.g. 如果IDS检测到了端口扫描,可以对网络进行例行的漏洞扫描,来验证问题中的主机是否真的打开了个端口,是否容易遭到攻击
3.指纹关联
4.反端口关联
if (event E1.dstport != (Known_Open_Ports on event E1.dstip))
then
doSomething
5.关联列表关联: 外部情报列表,例如攻击者列表
http://www.dshield.org/
6. 环境关联 e.g.如何知道公司的假期安排,可以使用这一信息,在每个人都不上班的时候发现内部资源的访问。
休假时间表
业务时间
假日计划
内部资源访问权限
重复的网络“事件”例如漏洞扫描
计划的系统、数据存储备份等
维护安排,例如操作系统补丁等
常见的关联搜索模式:
x次登录失败后有一次登录成功
创建非管理员账户之后进行权限提升
VPN用户在工作时间内/外登录,并向网络之外传输更多的数据
网络上的一台主机开始攻击或者探查网络上的其他主机
在很接近的时间内X次尝试访问用户没有权限的共享/文件/目录等
从同一个工作站以多个用户名登录
在多个系统上有多个防病毒软件失效
攻击DMZ系统,随后有出站连接
攻击DMZ系统,随后在同一个系统上更改配置
在几分钟内有许多Web 404,401 500和其他web错误码
以上都是单靠领域知识感知威胁,领域知识的缺陷是太依赖于专家知识了,而专家知识是有限的,这个时候机器学习就可以发挥长度了,例如理工渣眼中的HMM及安全应用。
即使是使用机器学习也仍离不开安全领域知识,有安全领域背景的人在数据预处理阶段、feature选择阶段会事半功倍,比如对访问日志进行白名单建模时,从访问日志中筛选出异常日志(攻击日志、不存在的日志、服务器错误日志),需要安全领域知识(知道什么是攻击)、web服务器知识(知道什么是异常,url重写)进行数据清理;比如HMM web安全检测 feature的选择,我们知道攻击注入点在哪里,就不需要进行运气流的feature选择、降维处理。
机器学习虽然能弥补单靠领域知识分析的缺陷,但由于其存在准确率的问题而不能直接在线上应用,只存在于运维离线的环境下。或许是算法需要优化,但个人认为能解决当前方法不能解决的问题就是很大的进步了,比如说能发现一个0 day。我想当电灯刚发明出来的时候,也是绝对没有蜡烛好用,也希望架构师们不要单一的靠准确率这个唯一的标准来评价机器学习的结果。
在知道了如何进行数据分析后,接下来的就是如何在数据量巨大的情况下进行分析。玩单机脚本的年代要一去不返了,分布式需要搞起。
三、大数据技术
我们要使用的大数据技术的核心其实就是是分布式存储与分布式计算,当然能利用已有的数据预处理接口,算法接口也是很有帮助的。
以下是一个完整的大数据分析架构图:
得出这个架构,也走了不少弯路,最开始由于不了解ElasticSearch的特性,采用的是直接使用ElasticSearch对数据源进行分析与结果存储,ElasticSearch全文索引的设计决定了ta不适合频繁写操作并且会很夸张的扩大数据量,所以最后引入了更适合及时读写操作的HBase数据库来做持久化存储,同时增加了算法层这块,只在ElasticSearch离存储最终结果。
大数据有着庞大的生态圈,较之机器学习(人工智能,深度学习)的发展,数据存储、数据计算方面简直是突飞猛进,为算法的发展提供了良好的支撑,当然学习的成本也非常高。以下是入门的一些文章:
大数据之hadoop伪集群搭建与MapReduce编程入门
大数据之hive安装及分析web日志实例
大数据之elasticsearch集群搭建与基本使用-渗透人员入门
大数据之Redis渗透人员入门—— 安装配置、基本操作及常用管理工具
大数据之MongoDB的安装配置、基本操作及Perl操作MongoDB
万事具备,就差第四个能力——编程,这是将想法落实的能力,否则都是镜花水月。不是有一句老话吗?“Talk is cheap, show me the code”。
四、编程
对于战斗力负5的渣,编程方面的心得是在太多了,每天都有新发现,这里就说说经验之谈吧。
1. 语言选择
先使用Python或者R去做小数据量(样本数据)的分析,然后使用Java实现分布式算法(在大数据的生态圈中,为了避免不必要的麻烦还是用原生语言Java好)。
2. 日志格式问题
日志处理中,输入日志的格式会直接影响模型运行时间,特别是采用正则的方式对文本格式的输入进行解析会极度消耗时间,所以在模型运算时需要先对日志进行序列化处理,Protocol Buffer就是很好的选择,但千万注意jar包的版本哦。
结语
大数据安全涉及的内容非常深入,每个方面都是几本厚厚的书,这里只是非常浅显的漫谈,给大家一幅平面的框架图,期待更多的数据科学(数据分析,机器学习,大数据处理)领域的人进入这个行业,或者安全行业的人开拓自己在数据分析方面的深度,大数据安全将发展的更好,不仅仅是叫好不叫座了。
(我写理工渣眼中的HMM及安全应用那篇文章时,有读者留言,为啥你也搞大数据,希望这篇文章能答疑)
最后一句,实践出真知,开练吧!
参考
《日志管理与分析权威指南》
《大数据日知录架构与算法》
http://security.tencent.com/index.php/blog/msg/21