百亿数据入库mongodb生产实践(一)
一、mongo基本概念
请参考我之前的一篇文章:mongo基本概念 和使用,也可通过官方文档或者别的博客进行了解。
二、数据背景和业务诉求
(看到这里,笔者认为您是对mongo已经有所了解了)
2.1 目标数据
鉴于公司数据安全要求,这里不对数据具体内容做描述。源数据通过一个中转集群拷贝至我们的生产环境hadoop集群中,业务数据分为几块大的领域,但是每个领域的数据结构基本相同。主要是三个事实表(这里用r1,r2,r3代称)和若干个维度表。维表数据量大概在几万条左右,每天以overwrite方式刷新对应hive表。三个事实表按照顺序:r1=>r2=>r3,依次是前者一对多后者。r1可以通过主键r1id与r2、r3进行join,r2可以通过主键r2id与r3进行join,所以r3中包含r1id和r2id。三个事实表按照每天增量的方式从源端集成,以日分区入库Hive分区表。每天增量数据依次为:r1-400万、r2-3000万、r3-3亿,基本每层十倍的比例。截至我着手开发时,历史数据有6个月的数据,要处理的一块领域的历史数据大概为500亿。
2.2 业务需求
源端数据集成至hadoop平台中,不同的业务部门需要获取自己业务领域的数据进行数据聚合处理、明细查询,以及时对对应业务产品做质量分析、性能校正等方面用途。
数据跨天的集成性质,当天集成的都是昨天生成的数据,这本身就是离线数据处理,所有一些聚合运算可以放Hive中处理好后,落地一个结果表。再通过协作工具sqoop或者相应jdbc程序export至RDBMS或者NOSQL数据库提供查询服务。
除了聚合结果,有时候业务场景是需要查询明细数据的。如果直接用Hive以jdbc方式提供查询,将无法达到实时查询的需求。对此,在结合源数据的关系模型和mongodb的适用场景后,我们选型Mongo,利用mongo支持的层级文档特性构建一个RDMBS概念中的宽表。
三、需求目标
3.1 快速完成海量历史数据的入库初始化和后期日增长数据的增加
3.2 实现海量嵌套数据快速检索查询,根据业务需要返回需要的数据
四、入库实践
笔者在着手做这个mongo入库的时候,与Mongo也是初遇。当时,既不懂mongo的架构原理,也不清楚基本的操作。所以,本文主要是以时间轴线,来阐述下个人的踩坑经历。直到现在,我对Mongo也只是达到一知半解的地步,各位看官发现不对的地方请及时指正。
废话不多说,进入实践正题。
pit 1: 现在有源数据,如何将数据写入Mongo?
在啥都不会的情况下,不要慌(虽然当时比梅西还慌得一批),先花点时间大概了解下架构原理、基本操作和对应api。
mongodb的基本概念和操作可参考mongo基本概念 和使用或者官方文档。建议自己装个单机版的,然后按照官方文档敲一遍crud,基本就算入门了。
从hive往mongo写数据,不要着急操作,还要进一步分析。要入库的数据主要是三个事实表(本文只讨论这三个表),这三个表都是每天增量的方式进行集成。通过数据发现,r1层与r2层或者r2层与r3层都是错位的,比如当前日期为2018-07-01,r1层(r1表)在这天的某些数据所对应的子项r2层数据并不一定也在当天分区,可能会滞后到明天、后天甚至更多天,r3的情况同理。在这种情况下,数据入mongo就不能提前先整合成层级文档一次写入了。所以需要按照层级顺序依次写入1,2,3层数据,不过这也有个大问题,具体后文再论述。
明确写入顺序,再研究具体操作,笔者是先在mongo shell中实现功能,再转化成对应api进行批量操作的。
在公司的大兄弟们可以直接用公司的机器进行操作,在校或者没环境的同学可以点击这里,参考文档搭建个单机进行操作。
mongo shell(或者第三方客户端软件):
写入第一层数据,提前看了操作文档后非常简单,直接用insert操作命令。
db.embedded_collection.insertMany(
[
{_id:NumberLong(123),
"r1_field1":"r1_value1_1",
"r1_field2":"r1_value2_1",
"r1_field3":"r1_value3_1",
"r1_field4":"r1_value4_1",
"r1_field5":"r1_value5_1"
},
{"_id":NumberLong(456),
"r1_field1":"r1_value1_2",
"r1_field2":"r1_value2_2",
"r1_field3":"r1_value3_2",
"r1_field4":"r1_value4_2",
"r1_field5":"r1_value5_2"
},
{"_id":NumberLong(789),
"r1_field1":"r1_value1_3",
"r1_field2":"r1_value2_3",
"r1_field3":"r1_value3_3",
"r1_field4":"r1_value4_3",
"r1_field5":"r1_value5_3"
}
]
)
需要花点心思的是二三层数据,这里,我们需要用到array类型的操作符。数组更新操作符有$addToSet $pop $pull $push $slice $sort等。mongo的操作符功能比较强大,这个需要根据应用场景去运用理解,初次碰面,不好理解是正常的。我在生产环境选择使用了$addToSet,$addToSet与$push 的作用类似,区别是push会判断去重,而addToSet是直接往里塞数据不管重复与否。我觉得这个addToSet这个对于处理历史数据会效率高一些(未找到官方验证)。通过下面语句追加第2层数据,upset选项为true时,如果条件查询的文档不在时,则会insert一条数据进去,依然保持有内嵌层级结构。
db.embedded_collection.updateOne(
{
_id:NumberLong(123)
},
{
$push:{
"r2_info":{
"r2_id":NumberLong(123111),
"r2_field1":"r2_value1_1",
"r2_field2":"r2_value2_1",
"r2_field3":"r2_value3_1",
"r2_field4":"r2_value4_1",
"r2_field5":"r2_value5_1"
}
},
$currentDate: { lastModified: true }
},
{
upset:false
}
)结果:
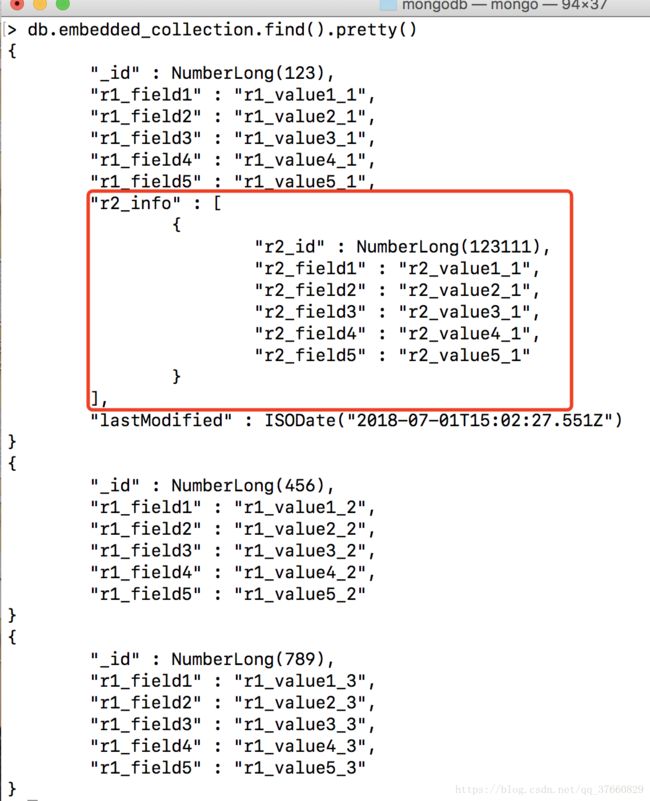
继续处理r3层:
db.embedded_collection.updateOne(
{
_id:NumberLong(123),
"r2_info.r2_id":NumberLong(123111)
},
{
$push:{
"r2_info.$.r3_info":
{
"r3_id":NumberLong(123111555)
"r3_field1":"r3_value1_1",
"r3_field2":"r3_value2_1",
"r3_field3":"r3_value3_1",
"r3_field4":"r3_value4_1",
"r3_field5":"r3_value5_1"
}
},
$currentDate: { lastModified: true }
},
{
upset:false
}
)写入三条数据:

追加第三层数据的时候需要两个条件,先定位到具体的文档,再确定在r2_info的哪个数组元素中进行push。这里用了r2_info.$.r3_info,其中$是定位符,很强大的一个功能,根据前面的r2_info.r2_id条件确定具体是哪个第二层元素。另外,这里的
lastModified时间也发生了错位,小了8小时,中国是用的东八区,这里默认是+0时区,需要进行设置。了解elasticsearch的同学,会发现也有类似问题。
java api: 了解了shell的语法实现后,用java api大批量写数据也知道怎么写了。
package cn.itcat
import java.util
import com.mongodb.client.MongoCollection
import com.mongodb.client.model._
import com.mongodb.spark.MongoConnector
import com.mongodb.spark.config.WriteConfig
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
import org.bson.Document
import scala.collection.JavaConverters._
import scala.reflect.ClassTag
/**
* Created by zhang on 2018/7/1.
*/
object Embedded_collection {
private val DefaultMaxBatchSize = 1024
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ttttt").setMaster(args(0))
val sc = new SparkContext(conf)
val sqlContext = new HiveContext(sc)
// val rdd = sc.makeRDD(Seq(new Document()))
val rdd = sqlContext.sql(
"""
|select filed1,
|filed2,
|filed3,
|...
|filedn from db.tablename where per_day='$date'
""".stripMargin.replace("$date", args(1)))
.map(row=>{
val doc = new Document()
.append("filed1", row.getAs[String]("filed1"))
//...
.append("filedn", row.getAs[String]("filedn"))
doc
})
val writeOverrides = new util.HashMap[String, String]()
writeOverrides.put("spark.mongodb.output.uri", "mongodb://localhost:27017/mydb.embedded_collection")
// writeOverrides.put("replaceDocument", "false")
val writeConfig = WriteConfig.create(conf, writeOverrides)
saveR1(rdd, writeConfig)
sc.stop()
}
//源码
def save[D: ClassTag](rdd: RDD[D], writeConfig: WriteConfig): Unit = {
val mongoConnector = MongoConnector(writeConfig.asOptions)
rdd.foreachPartition(iter => if (iter.nonEmpty) {
mongoConnector.withCollectionDo(writeConfig, { collection: MongoCollection[D] =>
iter.grouped(DefaultMaxBatchSize).foreach(batch => collection.insertMany(batch.toList.asJava))
})
})
}
def saveR1(rdd: RDD[Document], writeConfig: WriteConfig): Unit = {
val mongoConnector = MongoConnector(writeConfig.asOptions)
rdd.foreachPartition(iter => if (iter.nonEmpty) {
val writes = new util.ArrayList[WriteModel[Document]]()
val options = new BulkWriteOptions().ordered(false)//海量历史数据入库设为FALASE
mongoConnector.withCollectionDo(writeConfig, { collection: MongoCollection[Document] =>
iter.grouped(DefaultMaxBatchSize).foreach(batch => {
batch.foreach(docbase=>if(null!=docbase){
val doc = new Document(docbase)
doc.remove("r1_id ")
writes.add(new ReplaceOneModel[Document](Filters.eq("_id", docbase.get("r1_id")), docbase))
})
if(writes.size()>0){
collection.bulkWrite(writes, options)
writes.clear()
}
})
})
})
}
def saveR2(rdd: RDD[Document], writeConfig: WriteConfig): Unit = {
val mongoConnector = MongoConnector(writeConfig.asOptions)
rdd.foreachPartition(iter => if (iter.nonEmpty) {
val writes = new util.ArrayList[WriteModel[Document]]()
val options = new BulkWriteOptions().ordered(false)
mongoConnector.withCollectionDo(writeConfig, { collection: MongoCollection[Document] =>
iter.grouped(DefaultMaxBatchSize).foreach(batch => {
batch.foreach(docbase=>{
val doc = new Document(docbase)
doc.remove("r1_id ")
writes.add(new UpdateOneModel[Document](Filters.eq("_id", docbase.get("r1_id")), Updates.push("r2_info", doc)))
})
if(writes.size()>0){
collection.bulkWrite(writes)
writes.clear()
}
})
})
})
}
def saveR3(rdd: RDD[Document], writeConfig: WriteConfig): Unit = {
val mongoConnector = MongoConnector(writeConfig.asOptions)
rdd.foreachPartition(iter => if (iter.nonEmpty) {
val writes = new util.ArrayList[WriteModel[Document]]()
val options = new BulkWriteOptions().ordered(false)
mongoConnector.withCollectionDo(writeConfig, { collection: MongoCollection[Document] =>
iter.grouped(DefaultMaxBatchSize).foreach(batch => {
batch.foreach(docbase=>if(null!=docbase){
val doc = new Document(docbase)
doc.remove("r1_id ")
doc.remove("r2_id ")
writes.add(new UpdateOneModel[Document](Filters.and(Filters.eq("_id", docbase.get("r1_id")), Filters.eq("r2_info.r2_id", docbase.get("r2_id"))),
Updates.push("r2_info.$.r3_info" ,doc)))
})
if(writes.size()>0){
collection.bulkWrite(writes)
writes.clear()
}
})
})
})
}
}上面代码是相应的逻辑实现,开始是只用了java处理,后面改成了spark处理。方法参考mongo-spark-connector中mongospark.save()方法进行的简单修改,主要是利用了这个connector封装的客户端连接。通过查看源码发现内部是withXXXDo方法递归调用通过传入参数获取数据库连接直接获取集合,自己维护了数据库连接的管理。在foreachpartition算子中,自己封装个连接获取方法代替mongoconnector的方法也是一样的,就是需要自己去维护数据库连接的管理。
pit 2: 数据能写了,但是速度太慢?
作为一个spark developer,首先自然想到了用spark进行并行写入。官网找到有mongo spark connector,天助我也!马上去找对应版本,发现没有适配的(生产上为spark1.5.1版本),咨询了Mongo 技术支持也说版本太老,没有!!!

但后来还是用老版本去试粗来了。引入0.4版的connector是适配spark1.5.1的,1.6.1测试也是OK的。
org.mongodb.spark
mongo-spark-connector_2.10
0.4
在调用了MongoSpark封装的save方法后,又发现个问题,该方法的实现只能处理insertMany。对于内层的子文档操作实现没有,包括其他一些update也没有。所以,在原来方法基础上进行简单修改。
修改前,默认实现:
/** 源码
* Save data to MongoDB
*
* @param rdd the RDD data to save to MongoDB
* @param writeConfig the writeConfig
* @tparam D the type of the data in the RDD
*/
def save[D: ClassTag](rdd: RDD[D], writeConfig: WriteConfig): Unit = {
val mongoConnector = MongoConnector(writeConfig.asOptions)
rdd.foreachPartition(iter => if (iter.nonEmpty) {
mongoConnector.withCollectionDo(writeConfig, { collection: MongoCollection[D] =>
iter.grouped(DefaultMaxBatchSize).foreach(batch => collection.insertMany(batch.toList.asJava))
})
})
}修改后:
def saveR2(rdd: RDD[Document], writeConfig: WriteConfig): Unit = {
val mongoConnector = MongoConnector(writeConfig.asOptions)
rdd.foreachPartition(iter => if (iter.nonEmpty) {
mongoConnector.withCollectionDo(writeConfig, { collection: MongoCollection[Document] =>
// iter.grouped(DefaultMaxBatchSize).foreach(batch => collection.insertMany(batch.toList.asJava))
var writes = new util.ArrayList[WriteModel[Document]]()
iter.foreach(doc=>{
writes.add(new UpdateManyModel[Document](Filters.eq("_id",doc.get("result1_id")), Updates.push("result2", doc)))
if(writes.size()>500000){
collection.bulkWrite(writes)
writes.clear()
}
})
if(writes.size()>0)
collection.bulkWrite(writes)
})
})
}pit 3: 如何根据业务场景进行查询?
根据对接的几个业务查询场景发现:查询条件有多样组合,涉及到时间范围查询、精确查询、模糊查询还有三层文档每层都有查询条件。除了这些入参,出参(查询结果字段)也有要求。出参需要设置为需要的字段,对于内层文档有多个的只返回符合条件的那一个。
db.embedded_collection.aggregate(
{
$match:{"_id":NumberLong(123)}
},
{
$project:{"r2_info.r2_id":1,"r2_info.r3_info.r3_id":1}
},
{
"$unwind":"$r2_info"
},
{
"$unwind":"$r2_info.r3_info"
},
{
$match:{"r2_info.r3_info.r3_id":NumberLong(123111777)}
}
) 结果:
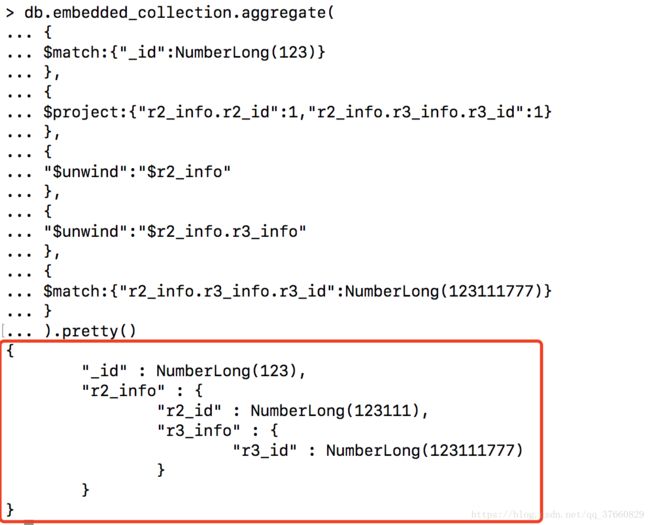
这里用到了几个聚合管道操作符:
$match 条件匹配;
$project 返回字段过滤;
$unwind 数组元素展开。
pit 4: 存在“极端”document,瞬间撑满16MB?
在写r3数据时,发现写了一半时候抛了异常:OperationFailure: Resulting document after update is larger than 16777216。那个时候才知道原来单个文档是有size上限的,官方解释是,主要考虑后续的文档迁移的问题。发现这个问题后,又去Hive原表中统计了下发现,r1最多下面有7万多条r2,r2最多下面有13万多条r3。但是这样的数据并不是很多,大概是几百条,其他的都是一对10条以下的。当时想的应对方案是,将这少数的“极端分子”try catch捕捉关到另一个collection里去。程序中将ordered关闭了,异常的都能捕捉到,没捕捉到的正常都是嵌入进去了。
在现在来看,根据官方建议,可以将r3层内嵌模式改成引用模式。这样用内嵌和引用模式结合使用可以解决这个size上限问题,不过对于update太频繁的问题也没有解决。
pit 4: spark job频频 outofmemory
源数据在hive中存储格式为ORC格式,spark通过对应inputformat实现类拉取数据后,一方面数据一定程序解压缩,另一方面数据进行了document的转换生成了大量的java对象。在进行spark shuffle write的时候,数据体积已经增长了好几倍。而在shuffle read时,还需要进一步消耗内存,所以读个几百兆的源数据,10个executor每个5G还是会遇到某个executor先内存爆掉。
解决这个没什么办法,就是加内存。
pit 5: big boom, 单位时间bulkwrite量太大,mongod主从不一致!
由于有大概500亿历史数据要快速入库,按照业务需求是要尽快入库的,但是mongo写入更新性能承载力有限。所以,这个生产实践最后没有成功落地。
五、实践总结
在我的实践中,业务场景没有能在生产环境中跑起来。主要归结为2个原因:1.历史数据太大,要处理这些数据对资源消耗太大,处理时间不好压缩;2.update对数据库性能消耗太大,忽略历史数据的处理,后面只做增量处理的话,调度处理的时间段内也会对mongo造成比较大的负载。
通过此次开发实践,让我对mongo的操作和数据模型的构建有了进一步的了解。知识的海洋很大,还需要慢慢的积累。
最近,在别的项目组做技术支撑,经过需求分析发现其数据模型跟这个类似。于是我把这个模型处理搬了过去,对方的数据源是kafka中的消息数据,有若干个topic,每个topic对应一个表,表数据也是自增模型。消息数据数据量每天最多千万级,单位时间内的数据量是较少的,所以不存在本文论述的痛点问题,理论是可以处理的。借由这个数据处理,让我回忆了下mongo的一些开发经历,尝试成文总结一下。