最全面的Jemter性能测试教程——Jmeter安装、基本组件使用、Windows和Linux上命令行执行
由于之前用Jmeter做了几次性能测试,所以写了下面这篇博客总结下。但是性能测试的知识点有很多,这个只能算一个初级教程。写的不好的地方,还请见谅。如果写的可以的话,可以关注我的博客,或者查看我的博客目录:YFF
目录
- 一、Jmeter下载、安装、启动、基本配置
- 1.1 Java环境
- 1.2 Jmeter下载
- 1.3 Jmeter安装及环境变量配置
- 1.4 启动Jmeter
- 1.5 Jemter配置中文环境
- 二、Jmeter基本使用
- 2.1.接口信息查看
- 2.2 脚本编写
- 三、Jmeter常用组件
- 3.1 配置原件
- 3.2 前置处理器
- 3.3 定时器
- 3.4 取样器
- 3.5 后置处理器
- 3.6 响应
- 3.7 监听器
- 3.8 逻辑控制器
- 3.9 BeanShell
- 四、命令行执行压测
- 4.1 Windows环境
- 4.2 Linux环境
- 4.2.1 Linux上Jemter环境搭建
- 4.2.2 修改脚本
- 4.2.3 执行性能测试
- 4.2.4 HTML报告解读
一、Jmeter下载、安装、启动、基本配置
1.1 Java环境
- 由于Jemter是基于java语言开发的,所以使用Jemter需要安装JDK。(Jemter5.0版本要求JDK版本为1.8或1.9,一般来说就是安装JDK1.8)。
- JDK1.8下载:链接:https://pan.baidu.com/s/1QUCU5sFvM0RFOWEhGxe0sw 提取码:fbhv
- java环境变量配置:https://jingyan.baidu.com/article/597035529700548fc0074039.html
1.2 Jmeter下载
- 最新版Jemter下载路径:http://jmeter.apache.org/download_jmeter.cgi
- 其他版本Jmeter下载路径:https://www.apache.org/dist/jmeter/binaries
一般来说,都是下载二进制的bin文件。

1.3 Jmeter安装及环境变量配置
- 安装的话,解压安装即可
- 环境变量配置
-
JMETER_HOME:D:\jmeter\apache-jmeter-5.1.1(Jmeter解压后目录)

-
Path:%JMETER_HOME%\bin
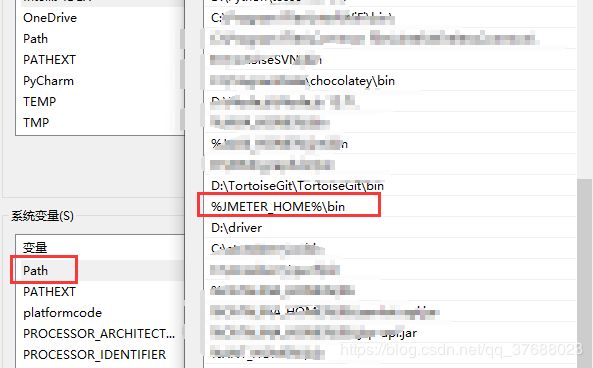
-
- 查看环境变量是否配置成功
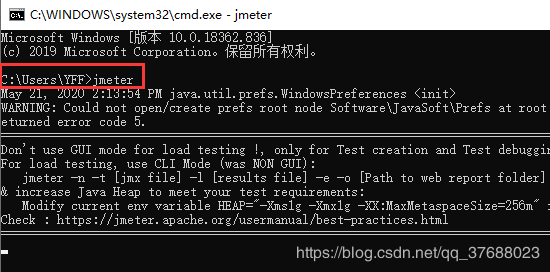
- 运行->cmd->
jmeter -v命令查看是否能查看到Jmeter版本信息 - 运行->cmd->
jmeter命令查看是否能启动jmeter
- 运行->cmd->
1.4 启动Jmeter
- 启动jmeter的bin目录下的
jmeter.bat文件

- 在jmetet配置环境变量后,
cmd中输入jmeter打开。
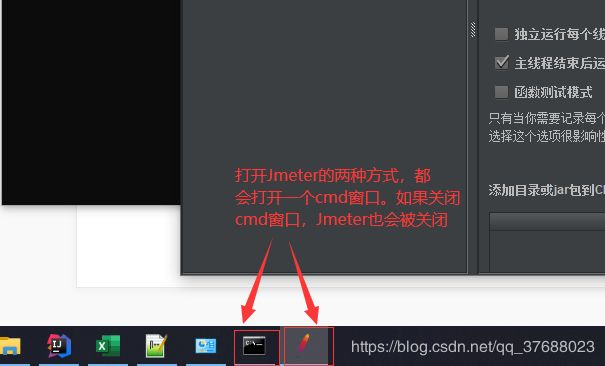
- 注意:不管用那种方式打开,都会打开一个cmd窗口。如果关闭这个cmd窗口,打开的jmeter也会被关闭。
1.5 Jemter配置中文环境
将Jemter的bin目录下的Jmeter.properties文件
将language=en修改为language=zh_CN

参考链接:https://jingyan.baidu.com/article/37bce2bedfc7135002f3a291.html
二、Jmeter基本使用
首先介绍Jemter基本使用,这里我就以一个登录接口作为例子,来进行基本脚本编写。
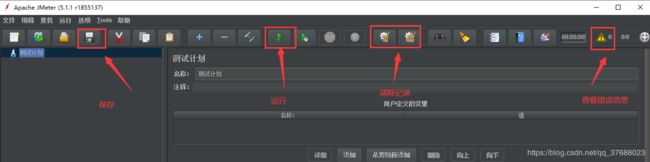
- Jemter常用按钮
2.1.接口信息查看
第一步肯定是了解需要进行性能测试的接口信息,如果有现成的接口文档更好。这里是在浏览器中通过F12键去网页中获取接口信息。
- General数据

协议类型:http或者https
域名或者IP:例如访问百度就是www.baidu.com
方法类型:POST或GET
请求路径:例如我这里是/auth/oauth/token
端口号:例如我这里是443
- Request Headers请求头
一般情况下,对一个借口进行访问的时候,必须带上相关的请求头。如果不清楚哪些请求头参数需要添加上,就一个个添加名称中不含:的请求头。例如我这里就需要将authorization这个请求头加上。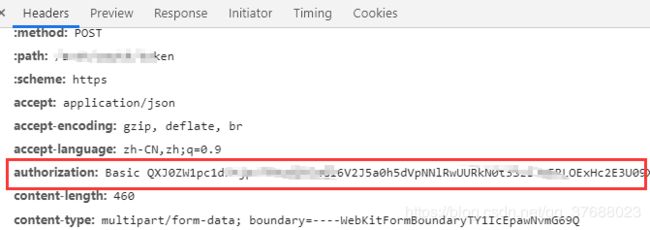
- 请求参数
请求参数有的时候是以Form Data形式,有的时候是以JSON串的形式显示。

2.2 脚本编写
- 创建线程组
(1)测试计划下添加->线程->线程组
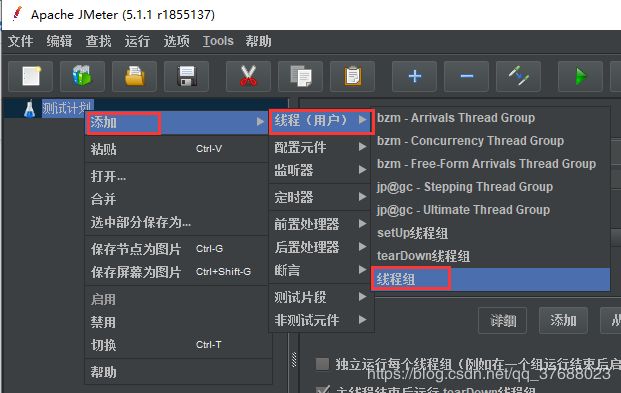
(2)填写相关参数
线程数:即为虚拟用户数。一个虚拟用户占用一个进程或线程。
Ramp-Up时间:设置虚拟用户数启动需要的时间。
循环次数:即为循环
调度器:需要设置持续时间或者启动延迟的时候,才需要勾选。勾选该选项后,需要将循环次数勾选永远
持续时间:测试持续时间
下面给出两种设置的情况:
一种是设置线程数、Ramp-Up时间、循环次数。
另一种是设置线程数、Ramp-Up时间、持续时间
- 设置10、2、10,含义就是在2秒内启动10个线程,并循环10次,最后发送的总请求数就为10*10=100.
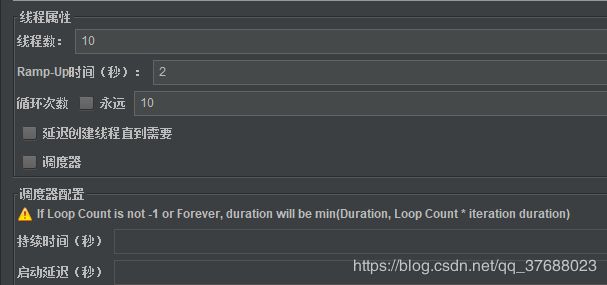
- 设置10、2、10,含义就是在2秒内启动10个线程,并持续压测10秒。
在实际情况中,我们进行性能测试中,一般会对一个接口压测5~10分钟,甚至更长。

- 创建HTTP请求
线程数上 添加->取样器->HTTP请求,然后根据最初查看到的接口信息,填写相关数据。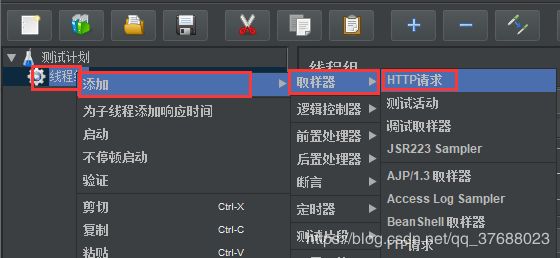

- 创建HTTP信息头管理器
HTTP请求上 添加->配置原件->HTTP信息头管理器,然后填写请求信息头相关的数据。

- 创建响应断言
没有断言的测试,是没有意义的。所以需要根据响应结果添加断言。HTTP请求上添加->断言->响应断言。


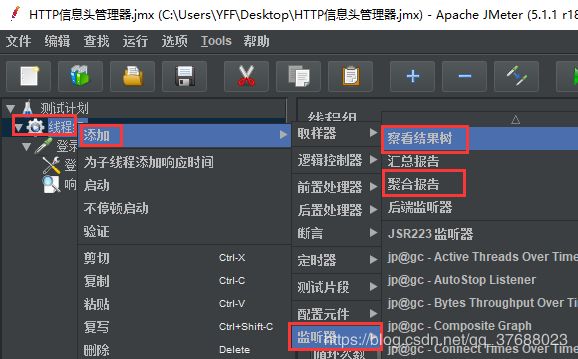
- 创建监听器(察看结果树、聚合报告)
在线程组上右键添加->监听器->察看结构树、聚合报告。
察看结果树:能查看每个请求的详细数据。请求相关信息、响应相关数据。
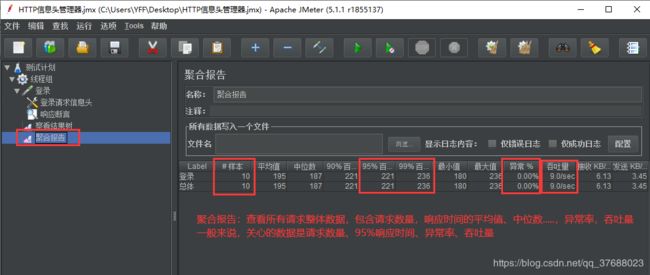
聚合报告:查看整体所有请求的整体数据。

三、Jmeter常用组件
上面以一个简单的登录接口,讲解了Jemter的基本使用。下面以组件的分类,讲解一下常用的几大类组件。按照组件执行顺序,依次为:配置原件->前置处理器->定时器->取样器->后置处理器->断言->监听器。同一层级的,顺序执行。
3.1 配置原件
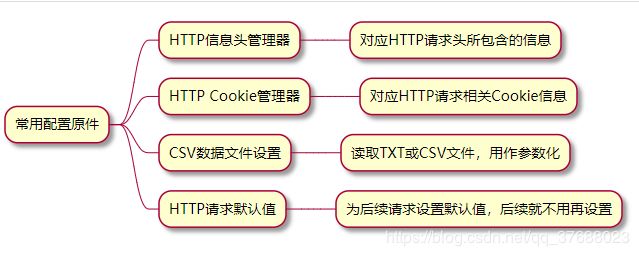
重点介绍一下CSV数据文件设置这个配置原件,因为参数化在性能测试中几乎是必不可少的。因为在实际相关接口性能测试时,不太可能每次请求都是同一个请求参数。
-
设置CSV数据文件


-
读取变量

3.2 前置处理器
前置处理器的含义:即为在请求启动前运行的原件。由于使用的较少,就不在这里说了,可自行百度。
3.3 定时器
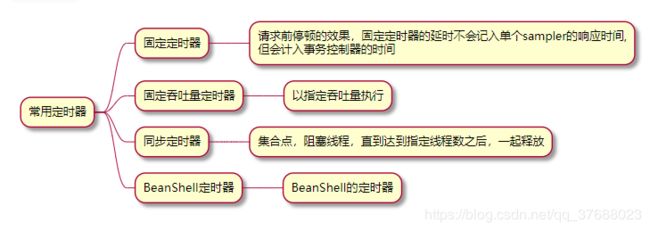
参考链接:
同步定时器:https://www.cnblogs.com/zichuan/p/6938783.html
3.4 取样器
取样器,即为发送的请求。常用的有HTTP请求、调试取样器、FTP请求、JDBC Request(连接数据库)等。HTTP请求由于上面已经说过了。
- 调试取样器
用于查看测试计划中及外部文件中的变量,可以定位问题,使用就是查看调试取样器的响应结果。
https://blog.csdn.net/caohongxing/article/details/82993026
- JDBC Request
https://www.cnblogs.com/liu-xiaoliu/p/9146449.html
https://www.jianshu.com/p/23526221c8dc
3.5 后置处理器
后置取样器,即为发送请求完成后的处理,也是比较常用的一个组件。常用的后置处理器有正则表达式提取器、JSON提取器、调试后置处理程序、BeanShell后置处理程序。这里就重点说一下正则表达式提取以及关联。
- 正则表达式提取器
参考链接:
https://www.jianshu.com/p/d47a1f67c959
https://blog.csdn.net/quiet_girl/article/details/50724313
https://www.cnblogs.com/tudou-22/p/9566894.html
引用名称:下一个请求中引用的参数名称
正则表达式:
() 括起来的部分为提取的内容
. 匹配任意字符串
+ 匹配一次或多次
? 找到第一个匹配项之后就停止匹配
\d 匹配数字
\n 匹配结尾,例如匹配响应头中一行的数据
带有转义字符的:id?test\":"1234" id\?test\\":"(.+?)" 提取出1234
模板:用$$引用起来,$1$表示将匹配到的第一个值赋给引用名称、同理可以使用$1$$4$是将
第一个和第四个值赋给引用名称。例如引用名称为user,模板为$1$$4$,后续取第一个
正则的值就是user_g1,第四个就是user_g4.
匹配数字:0代表随机取值、1代表全部取值
缺省值:即为正则表达式没有匹配到值,则使用缺省值给引用名
实际举例
响应文本内容:
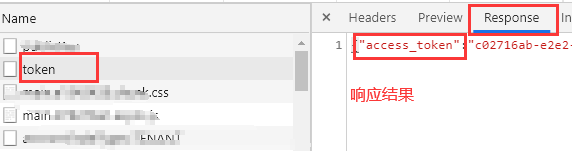
{"access_token":"0cdd295e-3803-4201-b945-2149bebda9a4",
"token_type":"bearer","refresh_token":"b832edd8-ed5b-4fd2-980b-65036412410b"
,"expires_in":6636,"scope":"read write","isDeviceValidate":true}
引用名称:token
正则表达式:"access_token":"(.+)","token_type":"(.+)","refresh_token":"(.+)","expires_in"
模板:$1$$2$$3$
匹配数字:1
Debug调试取样器结果
token=0cdd295e-3803-4201-b945-2149bebda9a4bearerb832edd8-ed5b-4fd2-980b-65036412410b
token_g=3
token_g0="access_token":"0cdd295e-3803-4201-b945-2149bebda9a4",
"token_type":"bearer","refresh_token":
"b832edd8-ed5b-4fd2-980b-65036412410b","expires_in"
token_g1=0cdd295e-3803-4201-b945-2149bebda9a4
token_g2=bearer
token_g3=b832edd8-ed5b-4fd2-980b-65036412410b
所以后续想要调用相关的参数的时候可以通过 引用名_g下标
- 关联
关联:可以理解为我们需要取服务器返回的值。举个常用的例子,就是一般系统一些接口请求的时候,请求头中参数需要登录返回的响应数据。关联中有两种情况,一种是一个线程组内请求之间的关联;另一种是两个线程组之间的关联。
| 相关参数 | 一个线程组 | 两个线程组 |
|---|---|---|
| 正则表达式提取器 | 引用名称:_access_token 正则表达式:“access_token”:"(.+?)" |
引用名称:_access_token 正则表达式:“access_token”:"(.+?)" |
| BeanShell 后置 | 无 | 输入值 |
| 后面取值 | ${_access_token} | ${__P(_access_token)} |
输入值为:
参数:${_access_token}
输入框值:
${__setProperty(_access_token,${_access_token})}


3.6 响应
断言,由于前面也大致说过了,具体可以参考下面链接。
https://www.cnblogs.com/xiehong/p/9959704.html
3.7 监听器
监听器,由于前面也大致说过了,具体可以参考下面链接。
察看结果树:https://www.cnblogs.com/syw20170419/p/9845985.html
聚合报告:https://blog.csdn.net/lijing742180/article/details/81183036
3.8 逻辑控制器
- 事务控制器
将多个请求当做一个事务,由于实际场景中不仅有数据返回,还有页面渲染加载,所以需要将多个接口放在一个事务中。
参考链接:
https://www.cnblogs.com/testlearn/p/11176257.html
https://www.cnblogs.com/mawenqiangios/p/7886068.html
- ForEach控制器
通常是几个类似的值需要循环使用的时候,通常结合自定义变量来使用。(是把ForEach控制器套在请求的上面)。
参考链接:
https://blog.csdn.net/adonis_lu37/article/details/77771019
- if控制器
参考链接:
https://blog.csdn.net/haiou24/article/details/83545442
https://www.cnblogs.com/sandymonk/p/11506222.html
3.9 BeanShell
由于BeanShell是Jmeter中一个强大的功能,这里可以参考下面链接。
https://www.cnblogs.com/cty136/p/11335092.html
四、命令行执行压测
在打开Jmeter的时候,就会有一个提示。大致含义就为不要用GUI界面来做测试,只用GUI界面来做调试脚本。给出的命令模板为:jmeter -n -t [jmx file] -l [result file] -e -o [Path to web report folder]。

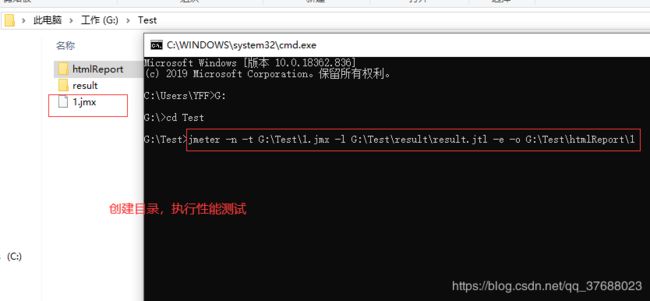
4.1 Windows环境
- 执行命令
例如:这里默认Windows中安装好Jmeter环境,且配置环境变量。执行命令。
jmeter -n -t G:\Test\1.jmx -l G:\Test\result\result.jtl -e -o G:\Test\htmlReport\1
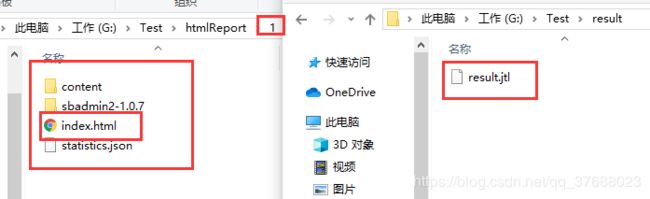
压测报告:1.rar
- 注意点
- bin\jmeter.properties配置jmeter.save.saveservice.output_format=xml需要注释掉,才能执行成功
- jtl文件路径和html报告路径需要不存在,否则会提示错误
4.2 Linux环境
4.2.1 Linux上Jemter环境搭建
- (1)确定Java环境
java -version
- (2)下载和解压安装Jmeter
/*wget命令下载Jmeter或者上传Jemter的tgz包*/
wget http://mirrors.tuna.tsinghua.edu.cn/apache//jmeter/binaries/apache-jmeter-5.1.1.tgz
/*解压Jemter*/
[yff@192 Desktop]$ ls
apache-jmeter-5.1.1.tgz
[yff@192 Desktop]$ tar zxvf apache-jmeter-5.1.1.tgz -C ./
apache-jmeter-5.1.1.tgz
- (3)配置环境变量
/*1.修改/etc/profile文件*/
vim /etc/profile
/*2.添加配置 路径根据实际修改*/
export PATH=/home/yff/Jmeter/apache-jmeter-5.2.1/bin/:$PATH
/*3.生效配置*/
source /etc/profile
/*查看配置是否成功*/
jmeter -v
- (4)修改端口
将/bin/jmeter.properties文件修改为jmeterengine.nongui.port=0
- (5)创建相关文件夹
/*在apache-jmeter-5.1.1目录下创建文件夹,为后续性能测试做准备*/
mkdir result log script file htmlReport
/*每个文件夹含义*/
result文件夹:用于存放压测结果
log文件夹:用于存放日志文件
file文件夹:用于存放CSV等文件
script文件夹:用于存放脚本文件
htmlReport文件夹:存放压测html报告
4.2.2 修改脚本
- CSV数据文件路径
如果Jmeter脚本中使用到CSV文件,在Linux执行性能测试前,需要将CSV文件上传到Linux上刚才创建的file文件夹下,然后将脚本中CSV数据文件路径修改为Linux上对应路径。
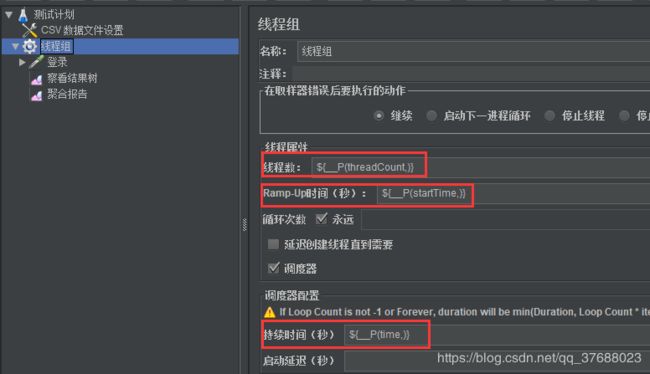
- 线程组参数参数化
由于在实际性能测试过程中,会进行不同并发数、不同持续时间的性能测试,就将线程组中相关参数修改为指定参数,然后执行命令中对参数赋不同的值。
${__P(threadCount,)} 线程数
${__P(startTime,)} 启动时间
${__P(time,)} 持续时间
4.2.3 执行性能测试
执行下面命令运行测试并生成报告。
/*执行命令*/
nohup jmeter -n -t /home/yff/Jmeter/apache-jmeter-5.1.1/script/1.1login_linux.jmx -l /home/yff/Jmeter/apache-jmeter-5.1.1/reslt/$(date +%y%m%d%H%M).jtl > /home/yff/Jmeter/apache-jmeter-5.1.1/log/$(date +%y%m%d%H%M).log -e -o /home/yff/Jmeter/apache-jmeter-5.1.1/htmlReport/8 -JthreadCount=0 -JstartTime=2 -Jtime=3
/*命令含义*/
nohup jmeter -n -t jmx脚本路径 -l jtl文件路径 > log文件路径 -e -o html路径 参数赋值
需要注意的是,html路径应该是不存在的,如果命令中html路径已经存在,执行命令时会报错
脚本参数设置及命令对应
${__P(threadCount,)}
${__P(startTime,)}
${__P(time,)}
-JthreadCount=10
-JstartTime=2
-Jtime=3
4.2.4 HTML报告解读
报告.rar
关于HTML中数据的解析,可以参考下面链接https://www.jianshu.com/p/4f32918d66bb
https://www.cnblogs.com/imyalost/p/10239317.html