使用多种机器学习算法挖掘ADFA-FD数据集的攻击行为
ADFA-FD数据集
是澳大利亚国防学院对外发布的一套主机及入侵检测系统的数据集合,被广泛应用于入侵检测类产品的测试。它记录了系统调用数据:

ADFA-LD数据集将系统操作的顺序抽象成序列向量:
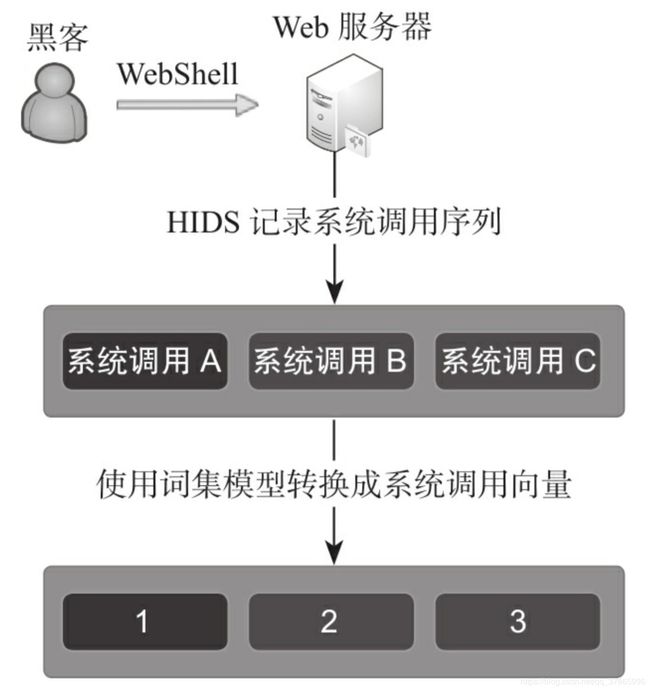
1.使用K近邻算法检测WebShell
# -*- coding:utf-8 -*-
import re
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import cross_validation
import os
from sklearn.datasets import load_iris
from sklearn import tree
import pydotplus
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
#加载文件
def load_one_flle(filename):
x=[]
with open(filename) as f:
line=f.readline()
line=line.strip('\n')
return line
#读取正常样本数据
def load_adfa_training_files(rootdir):
x=[]
y=[]
list = os.listdir(rootdir)#os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
for i in range(0, len(list)):#range() 函数可创建一个整数列表,一般用在 for 循环中。
path = os.path.join(rootdir, list[i])
if os.path.isfile(path):
x.append(load_one_flle(path))
y.append(0)
return x,y
#遍历目录下文件的函数
def dirlist(path, allfile):
filelist = os.listdir(path)
for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath): #os.path.isdir()用于判断对象是否为一个目录
dirlist(filepath, allfile)
else:
allfile.append(filepath)
return allfile
#在攻击数据集中,匹配和WebShell相关的数据,然后提取出来。
def load_adfa_webshell_files(rootdir):
x=[]
y=[]
allfile=dirlist(rootdir,[])
for file in allfile:
if re.match(r"/Users/zhanglipeng/Desktop/Data/Attack_Data_Master/Web_Shell_\d+/UAD-W*",file):
x.append(load_one_flle(file))
y.append(1)
return x,y
#数据集中的序列可能不一致,因此参考图书《web安全之机器学习入门》资料使用词集模型
if __name__ == '__main__':
x1,y1=load_adfa_training_files("/Users/zhanglipeng/Desktop/Data/ADFA-LD/Training_Data_Master/")
x2,y2=load_adfa_webshell_files("/Users/zhanglipeng/Desktop/Data/ADFA-LD/Attack_Data_Master/")
x=x1+x2
y=y1+y2
#print x
vectorizer = CountVectorizer(min_df=1)
x=vectorizer.fit_transform(x)
x=x.toarray()
#print y
clf = KNeighborsClassifier(n_neighbors=3)
scores=cross_val_score(clf, x, y, n_jobs=-1, cv=10)
print scores
print np.mean(scores)[0.94791667 0.96875 0.95833333 0.97894737 0.96842105 0.95789474
0.98947368 0.96842105 0.9893617 0.93617021]
0.9663689809630458
2.使用决策树算法检测FTP暴力破解
# -*- coding:utf-8 -*-
import re
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import cross_val_score
import os
from sklearn.datasets import load_iris
from sklearn import tree
import pydotplus
def load_one_flle(filename):
x=[]
with open(filename) as f:
line=f.readline()
line=line.strip('\n')
return line
def load_adfa_training_files(rootdir):
x=[]
y=[]
list = os.listdir(rootdir)
for i in range(0, len(list)):
path = os.path.join(rootdir, list[i])
if os.path.isfile(path):
x.append(load_one_flle(path))
y.append(0)
return x,y
def dirlist(path, allfile):
filelist = os.listdir(path)
for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
dirlist(filepath, allfile)
else:
allfile.append(filepath)
return allfile
#筛选与FTP暴力破解相关的数据
def load_adfa_hydra_ftp_files(rootdir):
x=[]
y=[]
allfile=dirlist(rootdir,[])
for file in allfile:
if re.match(r"/Users/zhanglipeng/Desktop/data/ADFA-LD/Attack_Data_Master/Hydra_FTP_\d+/UAD-Hydra-FTP*",file):
x.append(load_one_flle(file))
y.append(1)
return x,y
if __name__ == '__main__':
x1,y1=load_adfa_training_files("/Users/zhanglipeng/Desktop/data/ADFA-LD/Training_Data_Master/")
x2,y2=load_adfa_hydra_ftp_files("/Users/zhanglipeng/Desktop/data/ADFA-LD/Attack_Data_Master/")
x=x1+x2
y=y1+y2
#print x
vectorizer = CountVectorizer(min_df=1)#文本特征提取中,关注词汇的出现频率
x=vectorizer.fit_transform(x)#先拟合数据,然后转化它将其转化为标准形式
x=x.toarray()
#print y
clf = tree.DecisionTreeClassifier()
print cross_val_score(clf, x, y, n_jobs=-1, cv=10)
clf = clf.fit(x, y)
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("/Users/zhanglipeng/Desktop/photo/6/ftp.pdf")
[0.97029703 0.96039604 0.97 0.96969697 0.94949495 0.98989899
1. 0.96969697 0.94949495 0.94949495]
3.使用随机森林算法检测FTP暴力破解
随机森林可以看成多棵决策树进行决策,最后选择最好的一棵树作为样本判断结果。
# -*- coding:utf-8 -*-
import re
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
import os
from sklearn.datasets import load_iris
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
import numpy as np
def load_one_flle(filename):
x=[]
with open(filename) as f:
line=f.readline()
line=line.strip('\n')
return line
def load_adfa_training_files(rootdir):
x=[]
y=[]
list = os.listdir(rootdir)
for i in range(0, len(list)):
path = os.path.join(rootdir, list[i])
if os.path.isfile(path):
x.append(load_one_flle(path))
y.append(0)
return x,y
def dirlist(path, allfile):
filelist = os.listdir(path)
for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
dirlist(filepath, allfile)
else:
allfile.append(filepath)
return allfile
def load_adfa_hydra_ftp_files(rootdir):
x=[]
y=[]
allfile=dirlist(rootdir,[])
for file in allfile:
if re.match(r"/Users/zhanglipeng/Data/ADFA-LD/Attack_Data_Master/Hydra_FTP_\d+/UAD-Hydra-FTP*",file):
x.append(load_one_flle(file))
y.append(1)
return x,y
if __name__ == '__main__':
x1,y1=load_adfa_training_files("/Users/zhanglipeng/Desktop/Data/ADFA-LD/Training_Data_Master/")
x2,y2=load_adfa_hydra_ftp_files("/Users/zhanglipeng/Desktop/Data/ADFA-LD/Attack_Data_Master/")
x=x1+x2
y=y1+y2
#print x
vectorizer = CountVectorizer(min_df=1)
x=vectorizer.fit_transform(x)
x=x.toarray()
#print y
clf = RandomForestClassifier(n_estimators=10, max_depth=None,min_samples_split=2, random_state=0)
score=cross_val_score(clf, x, y, n_jobs=-1, cv=10)
print np.mean(score)
0.9838684868486848
可以看到,因为机制的问题,随机森林的效果必然不会差于决策树。
4.使用逻辑回归算法检测Java溢出攻击
# -*- coding:utf-8 -*-
import re
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
import os
import numpy as np
from sklearn.neural_network import MLPClassifier
from sklearn import linear_model, datasets
def load_one_flle(filename):
x=[]
with open(filename) as f:
line=f.readline()
line=line.strip('\n')
return line
def load_adfa_training_files(rootdir):
x=[]
y=[]
list = os.listdir(rootdir)
for i in range(0, len(list)):
path = os.path.join(rootdir, list[i])
if os.path.isfile(path):
x.append(load_one_flle(path))
print "Load file(%s)" % path
y.append(0)
return x,y
def dirlist(path, allfile):
filelist = os.listdir(path)
for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
dirlist(filepath, allfile)
else:
allfile.append(filepath)
return allfile
def load_adfa_java_files(rootdir):
x=[]
y=[]
allfile=dirlist(rootdir,[])
for file in allfile:
if re.match(r"/Users/zhanglipeng/Desktop/Data/ADFA-LD/Attack_Data_Master/Java_Meterpreter_\d+/UAD-Java-Meterpreter*",file):
print "Load file(%s)" % file
x.append(load_one_flle(file))
y.append(1)
return x,y
if __name__ == '__main__':
x1,y1=load_adfa_training_files("/Users/zhanglipeng/Desktop/Data/ADFA-LD/Training_Data_Master/")
x2,y2=load_adfa_java_files("/Users/zhanglipeng/Desktop/Data/ADFA-LD/Attack_Data_Master/")
x=x1+x2
y=y1+y2
#print x
vectorizer = CountVectorizer(min_df=1)
x=vectorizer.fit_transform(x)
x=x.toarray()
#多层感知机
mlp = MLPClassifier(hidden_layer_sizes=(150,50), max_iter=10, alpha=1e-4,
solver='sgd', verbose=10, tol=1e-4, random_state=1,
learning_rate_init=.1)
logreg = linear_model.LogisticRegression(C=1e5)
score=cross_val_score(logreg, x, y, n_jobs=-1, cv=10)
print np.mean(score)通过读取ADFA-FD数据集中的java攻击有关数据集,读取里面的序列,进行逻辑回归算法的使用和学习。
0.9520895505516369