Solr5.3.1 IK分析器配置,SolrTemplate操作Solr索引库
solr5.3.1的安装请参考我的上一篇博客:solr5.3.1linux下安装与基本使用
本篇文章起点:一个干净的solr服务器环境,在这里将和大家分享怎么导入数据到索引库,如何通过java代码操作solr索引库
一:通过后台管理页面,将自己创建的collection(索引库)和solrhome关联起来
1.1: 访问自己的solr项目地址,我的是http://192.168.25.192:28081/solr
1.1.1:刚开始是没有关联core的,需要自己手动添加,如下图

1.1.2:点击No cores 弹出添加页面,如下图:

上图中输入的信息:
name: 表示在solrhome下创建的collection文件夹的名字
instanceDir: 表示索引库(solr实例)存放的路径的相对路径,相对solrhome路径,因为collection1是在solrhome/collection1所以可以直接写
其他的dataDir和config以及schema的值使用默认的即可
添加完成后效果图:

二:配置IK分词器
IK分词器简介:
IK Analyzer 是一个开源的,基亍 java 语言开发的轻量级的中文分词工具包。从 2006年 12 月推出 1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开始,IK 发展为面向 Java 的公用分词组件,独立亍 Lucene 项目,同时提供了对Lucene的默认优化实现。在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化。
2.1: 刚开始在如下页面中是没有IK分词器的

2.2: 准备IK分词器的相关jar包和配置文件
网盘资源:
链接:https://pan.baidu.com/s/1dphEHUvzo1NcAetcimCxeg
提取码: mzl6
下载后文件结构如下:
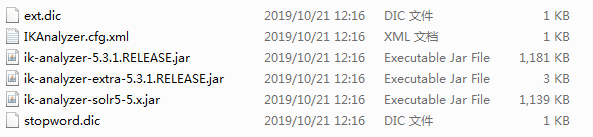
2.3: 将下载的IK分词器的jar包上传到服务器的solr工程的WEB-INF/lib中
2.3.1:打开sftp操作窗口进行文件上传 如果是SecureCRT,alt+p可进入,上传IK分词器需要用的 jar包
在sftp窗口下:
cd命令:指定文件上传的位置,这里是WEB-INF/lib下
lcd命令:指定需要上传的文件在window中的地址,这里是F:/IKAnalyzer
put命令:后面直接跟上需要上传的文件*.jar表示上传所有的jar包
sftp> cd /home/xiuxiang/apache-tomcat-8.5.47/webapps/solr/WEB-INF/lib/
sftp> lcd F:\IKAnalyzer
sftp> put *.jar
Uploading ik-analyzer-5.3.1.RELEASE.jar to /home/xiuxiang/apache-tomcat-8.5.47/webapps/solr/WEB-INF/lib/ik-analyzer-5.3.1.RELEASE.jar
100% 1180KB 1180KB/s 00:00:00
F:\IKAnalyzer\ik-analyzer-5.3.1.RELEASE.jar: 1208981 bytes transferred in 0 seconds (1180 KB/s)
Uploading ik-analyzer-extra-5.3.1.RELEASE.jar to /home/xiuxiang/apache-tomcat-8.5.47/webapps/solr/WEB-INF/lib/ik-analyzer-extra-5.3.1.RELEASE.jar
100% 2KB 2KB/s 00:00:00
F:\IKAnalyzer\ik-analyzer-extra-5.3.1.RELEASE.jar: 2490 bytes transferred in 0 seconds (2490 bytes/s)
Uploading ik-analyzer-solr5-5.x.jar to /home/xiuxiang/apache-tomcat-8.5.47/webapps/solr/WEB-INF/lib/ik-analyzer-solr5-5.x.jar
100% 1138KB 1138KB/s 00:00:00
F:\IKAnalyzer\ik-analyzer-solr5-5.x.jar: 1165904 bytes transferred in 0 seconds (1138 KB/s)
2.3.2:把扩展词典、停用词词典、配置文件放到 solr 工程的 WEB-INF/classes 目录下
ext.dic: 扩展词典
stopword.dic: 停用词典
IKAnalyzer.cfg.xml:配置文件
注意:先使用cd命令切换到solr工程的WEB-INF/classes下
sftp> cd ..
sftp> cd classes/
sftp> put *.dic
Uploading ext.dic to /home/xiuxiang/apache-tomcat-8.5.47/webapps/solr/WEB-INF/classes/ext.dic
100% 12 bytes 12 bytes/s 00:00:00
F:\IKAnalyzer\ext.dic: 12 bytes transferred in 0 seconds (12 bytes/s)
Uploading stopword.dic to /home/xiuxiang/apache-tomcat-8.5.47/webapps/solr/WEB-INF/classes/stopword.dic
100% 260 bytes 260 bytes/s 00:00:00
F:\IKAnalyzer\stopword.dic: 260 bytes transferred in 0 seconds (260 bytes/s)
sftp>
sftp>
sftp> put IKAnalyzer.cfg.xml
Uploading IKAnalyzer.cfg.xml to /home/xiuxiang/apache-tomcat-8.5.47/webapps/solr/WEB-INF/classes/IKAnalyzer.cfg.xml
100% 404 bytes 404 bytes/s 00:00:00
F:\IKAnalyzer\IKAnalyzer.cfg.xml: 404 bytes transferred in 0 seconds (404 bytes/s)
2.4: 修改solrhome的schema.xml文件,新增一个域配置
cd /home/xiuxiang/apache-tomcat-8.5.47/webapps/solr/solrhome/collection1/conf
vim schema.xml
--编辑页面中使用set nu 设置下行号
schema.xml内容中增加的信息如下:
<!--IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
</analyzer>
</fieldType>
增加的位置如下图所示:

2.5:检验配置的域类型是否在后台页面中能检索到
说明:需要重启solr工程所在的tomcat,才能让schema.xml文件生效
cd /home/xiuxiang/apache-tomcat-8.5.47/bin
./shutdown.sh
./startup.sh
访问页面如下:

出现错误:unsupported major.minor version 52.0,一般是jdk版本太低,需要保证运行环境jdk版本高于1.8
这里给大家附上jdk的网盘连接,安装过程请参考linux下安装jdk.8
jdk1.8网盘地址:
32位系统
链接:https://pan.baidu.com/s/1VTn9FCgPv0kFPrOcXQzkBQ
提取码:scmx
64位系统
链接:https://pan.baidu.com/s/1bs1K5VBZfM0WlPzPpXVmAg
提取码:cyon
我系统升级到jdk1.8后,便不出现之前那个错误了
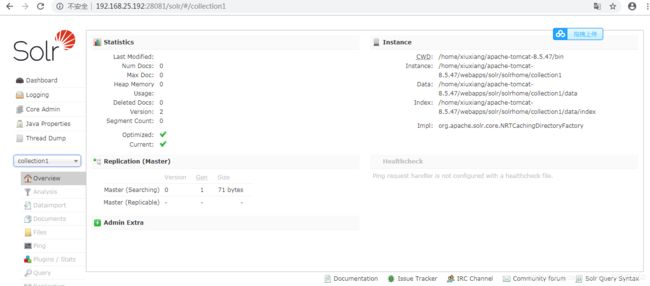
检验IK分词器的效果,按照下图操作

三:导入数据到索引库
3.1:根据简单的业务配置几个域
solr中域简单介绍:
域相当于数据库的表字段,用户存放数据,因此用户根据业务需要去定义相关的Field(域),一般来说,每一种对应着一种数据,用户对同一种数据进行相同的操作。
域的常用属性:
name:指定域的名称
type:指定域的类型
indexed:是否索引
stored:是否存储
required:是否必须
multiValued:是否多值
3.1.1: 配置域需要在实例 collection1下的 schema.xml 中配置
cd /home/xiuxiang/apache-tomcat-8.5.47/webapps/solr/solrhome/collection1/conf/
vim schema.xml
拿一个默认的 field 进行分析
其中name 指明域的名字,type则是域的类型,这个值是通过fieldType配置过的, indexed如果是true表示这个域会添加索引,false则不会;
stored表示这个域的值是否被存储 …
添加的域内容如下:
<!--id域是必须要有的,确保唯一性,注意schema.xml中有一个默认的id域了,值类型是String,如果自行配置ID域,请保持唯一性,域name要唯一-->
<field name="id" type="String" indexed="true" stored="true"/>
<field name="item_title" type="text_ik" indexed="true" stored="true"/>
<field name="item_price" type="double" indexed="true" stored="true"/>
<field name="item_category" type="string" indexed="true" stored="true" />
<field name="item_brand" type="string" indexed="true" stored="true" />
<field name="item_seller" type="string" indexed="true" stored="true" />
<!--当查询的时候是根据关键词查询,关键词可能出现在多个域中的时候,可以使用拷贝域-->
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<!--source: 源域 dest: 目标域 当根据item_keywords域的值进行查询的时候,会查询包含在item_title域、item_category域、item_seller域、item_brand域中的相关数据-->
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_category" dest="item_keywords"/>
<copyField source="item_seller" dest="item_keywords"/>
<copyField source="item_brand" dest="item_keywords"/>
<!--动态域,当匹配的数据对应的域符合item_spec_开头的时候,会自动创建一个域来存储相应的数据值-->
<dynamicField name="item_spec_*" type="string" indexed="true" stored="true" />
提示: 修改了schema.xml后需要重启tomcat才能让配置生效
3.1.2:业务场景:假如需要将商品信息导入到索引库中用于后续的搜索服务,其中商品信息,用Item对象封装,包含的字段如下描述:
注意: 属性使用@Field注解标识,如果属性与配置文件定义的域名称不一致,需要在注解中指定域名称
package com.xiuxiang.domain;
import org.apache.solr.client.solrj.beans.Field;
import org.springframework.data.solr.core.mapping.Dynamic;
import java.util.Map;
public class Item {
/**
* 商品id,同时也是商品编号 如果属性名和域name一致,那么可以省略@Filed(value="")里面的value信息
*/
@Field
private String id;
/**
* 商品标题
*/
@Field("item_title")
private String title;
/**
* 商品价格,单位为:元
*/
@Field("item_price")
private double price;
/**
* 商品分类
*/
@Field("item_category")
private String category;
/**
*商品品牌
*/
@Field("item_brand")
private String brand;
/**
* 商品所属商家
*/
@Field("item_seller")
private String seller;
/***
* @Dynamic:表示该属性对应的是一个动态域
* @Field(value = "item_spec_*"):表示动态域的前缀是item_spec_
*
* 创建动态域的时候,会将Map的可以作为动态域后面通配符匹配的部分,值作为域的值
* specMap:key=网络 value=联通3G
* specMap:key=机身内存 value=128G
*
* 往Solr索引库中添加对应的动态域:
* 域的名字:item_spec_网络
* 域的值:联通3G
*
* 域的名字:item_spec_机身内存
* 域的值:128G
*/
@Dynamic
@Field(value = "item_spec_*")
private Map<String,String> specMap;
/**
*用来存储高亮数据
*/
private String tempHighLightData ;
public void setTempHighLightData(String tempHighLightData) {
this.tempHighLightData = tempHighLightData;
}
public String getTempHighLightData() {
return tempHighLightData;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public String getSeller() {
return seller;
}
public void setSeller(String seller) {
this.seller = seller;
}
public Map<String, String> getSpecMap() {
return specMap;
}
public void setSpecMap(Map<String, String> specMap) {
this.specMap = specMap;
}
@Override
public String toString() {
return "Item{" +
"id='" + id + '\'' +
", title='" + title + '\'' +
", price=" + price +
", category='" + category + '\'' +
", brand='" + brand + '\'' +
", seller='" + seller + '\'' +
", specMap=" + specMap +
'}';
}
}
3.2: 使用Spring data solr操作solr索引库
简介:Spring Data Solr就是为了方便Solr的开发所研制的一个框架,其底层是对SolrJ(官方API)的封装
3.2.1 工程搭建:
(1) 创建maven工程,pom.xml中引入依赖,pom文件依赖如下
<dependencies>
<!--Spring-Data-Solr-->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-solr</artifactId>
<version>1.5.5.RELEASE</version>
</dependency>
<!--spring测试依赖-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.1.9.RELEASE</version>
<scope>test</scope>
</dependency>
<!-- Test dependencies -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<!--指定下maven编译jdk的版本是1.8,因为后面会用到lambda表达式-->
<build>
<finalName>solr-test</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<compilerArguments>
<verbose />
<bootclasspath>${java.home}/lib/rt.jar;${java.home}/lib/jce.jar</bootclasspath>
</compilerArguments>
</configuration>
</plugin>
</plugins>
</build>
( 2 ) 在src/main/resources/spring下创建 spring-solr.xml,文件内容如下:
注意:配置solr的服务端地址需要根据自己情况调整
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:solr="http://www.springframework.org/schema/data/solr"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/data/solr
http://www.springframework.org/schema/data/solr/spring-solr.xsd">
<!--指定solr地址 注意:
url配置的地址不能是http://192.168.25.192:28081/solr/#/collection1
如果加上#号标志符,会报一个
**org.apache.solr.client.solrj.impl.HttpSolrClient$RemoteSolrException
Expected mime type application/octet-stream but got text/html**
类似的错误
-->
<solr:solr-server id="solrServer" url="http://192.168.25.192:28081/solr/collection1" />
<!-- solr模板,使用solr模板可对索引库进行CRUD的操作 -->
<bean id="solrTemplate" class="org.springframework.data.solr.core.SolrTemplate">
<constructor-arg ref="solrServer" />
</bean>
</beans>
3.3: 创建测试类,进行对solr索引库的操作
在项目中,创建一个测试类,自主命名,我这是SpringDataSolrTest类,
使用Spring提供的测试包进行加载spring配置文件,创建IOC容器,测试类中注入SolrTemplate对象
SpringDataSolr类描述如下:
package com.xiuxiang.service;
import com.alibaba.fastjson.JSON;
import com.xiuxiang.domain.Item;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.solr.core.SolrTemplate;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = {"classpath:spring-solr.xml"})
public class SpringDataSolrTest {
@Autowired
private SolrTemplate solrTemplate;
}
下面将基于这个类对solr索引库进行增删改查操作
提示: 如果增加的记录的id在索引库中已经存在,再次执行增加,会覆盖之前的记录,实现修改。
3.3.1: 增加一条记录操作
/**
* 测试添加一条记录
*/
@Test
public void testAdd(){
Item item = new Item() ;
item.setBrand("华为"); // 设置品牌
item.setCategory("手机"); // 设置类别
item.setId(10 + ""); // 设置ID
item.setPrice(Double.valueOf("12321.88")); // 设置价格
item.setSeller("xiuxiang"); // 设置商品所属商家的名字
item.setTitle("华为5G时代"); // 设置商品标题
String specStr = "{\"网络\":\"移动4G\",\"机身内存\":\"32G\"}" ; // 设置动态域的内容 specStr是一个json字符串
Map<String,String> specMap = JSON.parseObject(specStr,Map.class) ; // 将json字符串转成Map集合
item.setSpecMap(specMap); // 设置到动态域对应的属性中,会将specMap的key拼接到定义的动态域的后面,以item_spec_{{key}}的形式创建域
solrTemplate.saveBean(item) ;
solrTemplate.commit();
}
通过后台查询看看有没有新增的记录

3.3.2: 批量导入数据到索引库
/**
* 批量增加数据测试,这里模拟创建150个商品信息,生产环境需要查询数据库
*/
@Test
public void testBatchAdd(){
String[] brandsStrs = new String[5] ;
brandsStrs[0] = "华为" ;
brandsStrs[1] = "小米" ;
brandsStrs[2] = "vivo" ;
brandsStrs[3] = "锤子" ;
brandsStrs[4] = "oppo" ;
String specStr = "{\"网络\":\"移动4G\",\"机身内存\":\"32G\"}" ;
Map<String,String> specMap = JSON.parseObject(specStr,Map.class) ;
List<Item> itemList = new ArrayList<Item>() ;
for(int i = 0 ; i <= 150 ; i++) {
Item item = new Item() ;
item.setBrand(brandsStrs[i%5] + i);
item.setCategory("类型" + i%10);
item.setId(i + "");
item.setPrice(Double.valueOf((i + 10) * 60 ));
item.setSeller("商家" + i % 6);
item.setTitle("好手机" + i % 60);
item.setSpecMap(specMap);
itemList.add(item) ;
}
solrTemplate.saveBeans(itemList) ;
solrTemplate.commit();
}
后台查询结果如下:

3.3.3: 条件查询,根据id域查询
@Test
public void testFindById(){
Item item = solrTemplate.getById("100", Item.class);
System.out.println(item);
}
3.3.4: 根据ID域删除记录
@Test
public void testDeleteById(){
solrTemplate.deleteById("3") ;
solrTemplate.commit();
}
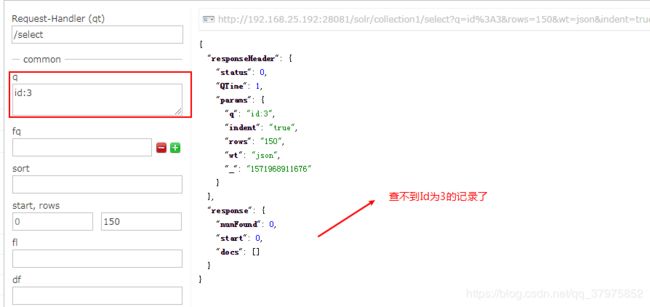
3.3.5: 分页查询
Query 对象是在org.springframework.data.solr.core.query包下
SimpleQuery 同上
/**
* 分页查询
*/
@Test
public void testPageFind(){
// import org.springframework.data.solr.core.query.Query;
Query query = new SimpleQuery("*:*") ; // 创建一个查询条件对象
// 设置分页信息
query.setOffset(0) ; // 设置从下标几开始查询 , 0 表示第一条开始查询
query.setRows(20) ; // 设置查询的记录数 查询20条记录
// 执行查询
ScoredPage<Item> items = solrTemplate.queryForPage(query, Item.class);
// 获取总页数
System.out.println("总页数: " + items.getTotalPages());
// 获取总记录数
System.out.println("总记录数:" + items.getTotalElements());
//输出查询的记录
items.getContent().stream().forEach(item -> {
System.out.println(item);
});
}
结果:
总页数: 8
总记录数:150
Item{id='0', title='好手机0', price=600.0, category='类型0', brand='华为0', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='1', title='好手机1', price=660.0, category='类型1', brand='小米1', seller='商家1', specMap={网络=移动4G, 机身内存=32G}}
Item{id='2', title='好手机2', price=720.0, category='类型2', brand='vivo2', seller='商家2', specMap={网络=移动4G, 机身内存=32G}}
Item{id='4', title='好手机4', price=840.0, category='类型4', brand='oppo4', seller='商家4', specMap={网络=移动4G, 机身内存=32G}}
Item{id='5', title='好手机5', price=900.0, category='类型5', brand='华为5', seller='商家5', specMap={网络=移动4G, 机身内存=32G}}
Item{id='6', title='好手机6', price=960.0, category='类型6', brand='小米6', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='7', title='好手机7', price=1020.0, category='类型7', brand='vivo7', seller='商家1', specMap={网络=移动4G, 机身内存=32G}}
Item{id='8', title='好手机8', price=1080.0, category='类型8', brand='锤子8', seller='商家2', specMap={网络=移动4G, 机身内存=32G}}
Item{id='9', title='好手机9', price=1140.0, category='类型9', brand='oppo9', seller='商家3', specMap={网络=移动4G, 机身内存=32G}}
Item{id='10', title='好手机10', price=1200.0, category='类型0', brand='华为10', seller='商家4', specMap={网络=移动4G, 机身内存=32G}}
Item{id='11', title='好手机11', price=1260.0, category='类型1', brand='小米11', seller='商家5', specMap={网络=移动4G, 机身内存=32G}}
Item{id='12', title='好手机12', price=1320.0, category='类型2', brand='vivo12', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='13', title='好手机13', price=1380.0, category='类型3', brand='锤子13', seller='商家1', specMap={网络=移动4G, 机身内存=32G}}
Item{id='14', title='好手机14', price=1440.0, category='类型4', brand='oppo14', seller='商家2', specMap={网络=移动4G, 机身内存=32G}}
Item{id='15', title='好手机15', price=1500.0, category='类型5', brand='华为15', seller='商家3', specMap={网络=移动4G, 机身内存=32G}}
Item{id='16', title='好手机16', price=1560.0, category='类型6', brand='小米16', seller='商家4', specMap={网络=移动4G, 机身内存=32G}}
Item{id='17', title='好手机17', price=1620.0, category='类型7', brand='vivo17', seller='商家5', specMap={网络=移动4G, 机身内存=32G}}
Item{id='18', title='好手机18', price=1680.0, category='类型8', brand='锤子18', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='19', title='好手机19', price=1740.0, category='类型9', brand='oppo19', seller='商家1', specMap={网络=移动4G, 机身内存=32G}}
Item{id='20', title='好手机20', price=1800.0, category='类型0', brand='华为20', seller='商家2', specMap={网络=移动4G, 机身内存=32G}}
3.3.6: 单条件查询
封装条件需要用到Criteria对象
对象所在包:import org.springframework.data.solr.core.query.Criteria;
/**
* 条件查询
*/
@Test
public void testFindByConditions(){
// 创建查询对象
Query query = new SimpleQuery("*:*") ; // *:* 表示查询所有
// 创建一个条件对象,这里是指定item_brand域中包含华为的数据
Criteria criteria = new Criteria("item_brand").contains("华为") ;
//将条件对象和查询对象进行关联
query.addCriteria(criteria) ;
// 设置分页
query.setOffset(0) ;
query.setRows(10) ;
// 执行查询
ScoredPage<Item> items = solrTemplate.queryForPage(query, Item.class);
// 输出总记录数
System.out.println("总记录数: " + items.getTotalElements());
// 输出总页数
System.out.println("总页数: " + items.getTotalPages());
// 输出查询的数据
items.getContent().stream().forEach(item -> {
System.out.println(item);
});
}
输出结果:
总记录数: 31
总页数: 4
Item{id='0', title='好手机0', price=600.0, category='类型0', brand='华为0', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='5', title='好手机5', price=900.0, category='类型5', brand='华为5', seller='商家5', specMap={网络=移动4G, 机身内存=32G}}
Item{id='10', title='好手机10', price=1200.0, category='类型0', brand='华为10', seller='商家4', specMap={网络=移动4G, 机身内存=32G}}
Item{id='15', title='好手机15', price=1500.0, category='类型5', brand='华为15', seller='商家3', specMap={网络=移动4G, 机身内存=32G}}
Item{id='20', title='好手机20', price=1800.0, category='类型0', brand='华为20', seller='商家2', specMap={网络=移动4G, 机身内存=32G}}
Item{id='25', title='好手机25', price=2100.0, category='类型5', brand='华为25', seller='商家1', specMap={网络=移动4G, 机身内存=32G}}
Item{id='30', title='好手机30', price=2400.0, category='类型0', brand='华为30', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='35', title='好手机35', price=2700.0, category='类型5', brand='华为35', seller='商家5', specMap={网络=移动4G, 机身内存=32G}}
Item{id='40', title='好手机40', price=3000.0, category='类型0', brand='华为40', seller='商家4', specMap={网络=移动4G, 机身内存=32G}}
Item{id='45', title='好手机45', price=3300.0, category='类型5', brand='华为45', seller='商家3', specMap={网络=移动4G, 机身内存=32G}}
3.3.7: 删除全部数据
/**
* 删除全部数据
*/
@Test
public void testDeleteAll(){
// 这里也可以设置条件,根据条件删除
Query query = new SimpleQuery("*:*") ;
solrTemplate.delete(query) ;
solrTemplate.commit();
}
3.3.8: 根据关键词搜索,item_keywords域,是一个拷贝域
/**
* keywords会被IK分词器进行分词
* 分词结果:
* 手机 | 手 | 机 | 0
* 如果是使用criteria.is和criteria.contains的区别,暂时还没弄清楚,有知道的博友,求告知,谢谢
* 所以会查询出item_title,item_category,item_seller,item_brand域中包含上面分词结果的数据
*/
@Test
public void testFindByKeywords(){
/**
* keywords会被IK分词器进行分词
* 分词结果:
* 手机 | 手 | 机 | 0
* 所以会查询出item_title,item_category,item_seller,item_brand域中包含上面分词结果的数据
*/
String keyWords = "手机0" ;
Query query = new SimpleQuery("*:*") ;
Criteria criteria = new Criteria("item_keywords").is(keyWords) ; // 创建查询条件对象
query.addCriteria(criteria) ;
//设置分页
query.setOffset(0) ;
query.setRows(10) ;
ScoredPage<Item> items = solrTemplate.queryForPage(query, Item.class);
// 输出数据
items.getContent().stream().forEach(System.out::println);
}
结果如下:
Item{id='0', title='好手机0', price=600.0, category='类型0', brand='华为0', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='60', title='好手机0', price=4200.0, category='类型0', brand='华为60', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='120', title='好手机0', price=7800.0, category='类型0', brand='华为120', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='30', title='好手机30', price=2400.0, category='类型0', brand='华为30', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='90', title='好手机30', price=6000.0, category='类型0', brand='华为90', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='150', title='好手机30', price=9600.0, category='类型0', brand='华为150', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='6', title='好手机6', price=960.0, category='类型6', brand='小米6', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='10', title='好手机10', price=1200.0, category='类型0', brand='华为10', seller='商家4', specMap={网络=移动4G, 机身内存=32G}}
Item{id='12', title='好手机12', price=1320.0, category='类型2', brand='vivo12', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='18', title='好手机18', price=1680.0, category='类型8', brand='锤子18', seller='商家0', specMap={网络=移动4G, 机身内存=32G}}
3.3.9: 多条件查询
有些时候需要根据多个条件进行查询索引库,比如查询手机,品牌是华为,分类是类型1,规格中包含网络是4G,屏幕尺寸是6.5的等多条件进行查询的情况
/**
* 测试多条件,假如多条件用Map封装
*/
@Test
public void testFindByMutiConditions() {
// 组装条件集合
Map<String,Object> conditionsMap = new HashMap<>() ;
conditionsMap.put("keyword","手机") ;
conditionsMap.put("category","类型0") ;
conditionsMap.put("spec","{\"网络\":\"移动4G\",\"机身内存\":\"32G\"}") ; // 规格信息是一个json串
// 多条件查询
Query query = new SimpleQuery("*:*") ;
if(conditionsMap != null) {
String keyword = (String)conditionsMap.get("keyword");
if(StringUtils.isNotBlank(keyword)) {
// 根据关键字查询
Criteria criteria = new Criteria("item_keywords").is(keyword) ;
query.addCriteria(criteria) ;
}
String category = (String)conditionsMap.get("category");
if(StringUtils.isNotBlank(category)) {
// 过滤类别数据
Criteria criteria = new Criteria("item_category").is(category) ;
FilterQuery filterQuery = new SimpleFilterQuery() ;
filterQuery.addCriteria(criteria) ;
query.addFilterQuery(filterQuery) ;
}
String spec = (String)conditionsMap.get("spec");
if(StringUtils.isNotBlank(spec)) {
// 过滤规格
Map<String,String> specMap = JSON.parseObject(spec,Map.class) ;
Objects.requireNonNull(specMap).entrySet().stream().forEach(entry -> {
Criteria criteria = new Criteria("item_spec_" + entry.getKey()).is(entry.getValue()) ;
FilterQuery filterQuery = new SimpleFilterQuery() ;
filterQuery.addCriteria(criteria) ;
query.addFilterQuery(filterQuery) ;
});
}
}
query.setOffset(0) ;
query.setRows(10) ;
ScoredPage<Item> items = solrTemplate.queryForPage(query, Item.class);
items.getContent().stream().forEach(item -> {
System.out.println(item);
});
}
控制台输出如下:
Item{id='0', title='好手机0', price=600.0, category='类型0', brand='华为0', seller='手机商0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='10', title='好手机10', price=1200.0, category='类型0', brand='华为10', seller='手机商4', specMap={网络=移动4G, 机身内存=32G}}
Item{id='20', title='好手机20', price=1800.0, category='类型0', brand='华为20', seller='手机商2', specMap={网络=移动4G, 机身内存=32G}}
Item{id='30', title='好手机30', price=2400.0, category='类型0', brand='华为30', seller='手机商0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='40', title='好手机40', price=3000.0, category='类型0', brand='华为40', seller='手机商4', specMap={网络=移动4G, 机身内存=32G}}
Item{id='50', title='好手机50', price=3600.0, category='类型0', brand='华为50', seller='手机商2', specMap={网络=移动4G, 机身内存=32G}}
Item{id='60', title='好手机0', price=4200.0, category='类型0', brand='华为60', seller='手机商0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='70', title='好手机10', price=4800.0, category='类型0', brand='华为70', seller='手机商4', specMap={网络=移动4G, 机身内存=32G}}
Item{id='80', title='好手机20', price=5400.0, category='类型0', brand='华为80', seller='手机商2', specMap={网络=移动4G, 机身内存=32G}}
Item{id='90', title='好手机30', price=6000.0, category='类型0', brand='华为90', seller='手机商0', specMap={网络=移动4G, 机身内存=32G}}
四、高亮数据查询(难点)
说明:方法仍然是步骤3中的测试类
/**
* 查询并且设置高亮
*/
@Test
public void testFindAndSetHighLight(){
// 之前的Query对象不支持高亮查询,需要替换成
// SimpleStringCriteria 是Criteria的子类,这里是设置查询所有
HighlightQuery query = new SimpleHighlightQuery(new SimpleStringCriteria("item_title:手机 AND item_seller:手机商0")) ;
// 开启高亮,默认是不开启的,需要添加高亮选项设置
HighlightOptions highlightOptions = new HighlightOptions() ;
// 添加高亮域
highlightOptions.addField("item_title") ; // 这里假如商品标题需要高亮
highlightOptions.addField("item_seller") ; // 商家也进行高亮
// 前缀,将需要高亮的数据添加样式前缀 假如高亮数据是 "手机" => 添加高亮后变成 手机
highlightOptions.setSimplePrefix("") ;
// 后缀
highlightOptions.setSimplePostfix("") ;
// 将高亮选项添加到query中
query.setHighlightOptions(highlightOptions) ;
// 执行查询
query.setOffset(0) ;
query.setRows(5) ;
/**
* items中包含了查询出来的高亮数据和非高亮数据
*/
HighlightPage<Item> items = solrTemplate.queryForHighlightPage(query, Item.class);
// 从查询的结果中获取数据 highlighted中既有高亮数据也有非高亮数据,需要自主替换
List<HighlightEntry<Item>> highlighted = items.getHighlighted();
highlighted.stream().forEach(itemHighlightEntry -> {
// itemHighlightEntry是一个集合对象,里面包含了当前非高亮数据和高亮数据
Item item = itemHighlightEntry.getEntity(); // 这是非高亮数据
//System.out.println("item信息:");
//System.out.println(item);
List<HighlightEntry.Highlight> highlights = itemHighlightEntry.getHighlights(); // 这是高亮数据
// 遍历高亮数据,将需要高亮的内容替换掉非高亮数据
// Objects.requireNonNull(highlights) 判断highlights不为空的时候进行遍历
Objects.requireNonNull(highlights).stream().forEach(highlight -> {
// highlight 是所有的高亮数据
List<String> snipplets = highlight.getSnipplets();
String highLightData = "" ;
for (String str : snipplets) {
highLightData += str ; // 组装高亮数据
}
String fieldName = highlight.getField().getName() ; // 获取高亮数据对应的域
// System.out.println(fieldName);
// System.out.println(highLightData);
item.setTempHighLightData(highLightData);
// 获取Item上所有的属性
Field[] fileds = Item.class.getDeclaredFields();
//打印所有的属性名字
//System.out.println("属性名");
//Arrays.stream(fileds).forEach(filed -> System.out.println(filed.getName()));
Method[] methods = Item.class.getDeclaredMethods() ;
// 打印所有的方法名
//System.out.println("方法名");
//Arrays.stream(methods).forEach(method -> System.out.println(method.getName()));
Arrays.stream(fileds).forEach(field -> {
// 获取属性上的@Filed注解
org.apache.solr.client.solrj.beans.Field annotation = field.getAnnotation(org.apache.solr.client.solrj.beans.Field.class);
if(annotation != null) {
String value = annotation.value() ;
// 获取注解的value值
//String value = annotation.value();
if(value.equals(fieldName)) {
// 如果高亮域和当前注解的属性值一致
// 调用相应的set方法
// 根据属性名获取set方法并且执行
Arrays.stream(methods).forEach(method -> {
if(("set" + field.getName()).toLowerCase().equals(method.getName().toLowerCase())) {
// 找到set方法并且执行
try {
method.invoke(item,item.getTempHighLightData()) ;
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
});
}
}
});
});
});
// 验证高亮数据
items.getContent().stream().forEach(item -> {
System.out.println(item);
});
}
结果
如下所示,因为高亮域设置了两个,所以title和seller的值都被高亮数据所替换,关键词“手机“加上了前缀和后缀设置样式。
Item{id='0', title='好手机0', price=600.0, category='类型0', brand='华为0', seller='手机商0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='6', title='好手机6', price=960.0, category='类型6', brand='小米6', seller='手机商0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='12', title='好手机12', price=1320.0, category='类型2', brand='vivo12', seller='手机商0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='18', title='好手机18', price=1680.0, category='类型8', brand='锤子18', seller='手机商0', specMap={网络=移动4G, 机身内存=32G}}
Item{id='24', title='好手机24', price=2040.0, category='类型4', brand='oppo24', seller='手机商0', specMap={网络=移动4G, 机身内存=32G}}
五:分组查询
需求假设: 查询出solr索引库中所有的分类和品牌信息
需要根据分类和品牌域进行分组查询
/**
* 需求假设: 查询出solr索引库中所有的分类和品牌信息
* 需要根据分类和品牌域进行分组查询
*/
@Test
public void testFindAndGroup(){
Query query = new SimpleQuery("*:*") ;
// 设置分组信息
GroupOptions groupOptions = new GroupOptions() ;
// 添加分组域
groupOptions.addGroupByField("item_brand") ;
groupOptions.addGroupByField("item_category") ;
// 添加分组选项
query.setGroupOptions(groupOptions) ;
//执行分组查询
GroupPage<Item> items = solrTemplate.queryForGroupPage(query, Item.class);
// 获取指定 item_brand域的分组数据
GroupResult<Item> item_brand = items.getGroupResult("item_brand");
// 获取指定 item_category域的分组数据
GroupResult<Item> item_category = items.getGroupResult("item_category");
// 拼接数据,得到所有的分类数据和品牌数据
List<String> brandList = new ArrayList<>() ;
Page<GroupEntry<Item>> groupEntries = item_brand.getGroupEntries(); // 获去分组数据
for (GroupEntry<Item> groupEntry : groupEntries) {
// 获取每一种品牌信息
String brand = groupEntry.getGroupValue();
brandList.add(brand) ;
}
List<String> catagoryList = new ArrayList<>() ;
Page<GroupEntry<Item>> categoryGroupEntries = item_category.getGroupEntries(); // 获去分组数据
for (GroupEntry<Item> groupEntry : categoryGroupEntries) {
// 获取每一种分类信息
String catagory = groupEntry.getGroupValue();
catagoryList.add(catagory) ;
}
// 输出结果进行验证
System.out.println("所有品牌如下:");
brandList.stream().forEach(System.out::println);
System.out.println("所有分类如下:");
catagoryList.stream().forEach(System.out::println);
}
结果如下:
所有品牌如下:
华为0
小米1
vivo2
锤子3
oppo4
华为5
小米6
vivo7
锤子8
oppo9
所有分类如下:
类型0
类型1
类型2
类型3
类型4
类型5
类型6
类型7
类型8
类型9
后期会继续更新本篇文章,如有哪里不对的地方,请各位博友多多指教。