机器学习---编程练习(七):K 均值聚类(K-means)与主成成份分析(PCA)
机器学习—编程练习(七):K 均值聚类(K-means)与主成成份分析(PCA)
文件列表
ex7.m - Octave/MATLAB script for the first exercise on K-means
ex7 pca.m - Octave/MATLAB script for the second exercise on PCA
ex7data1.mat - Example Dataset for PCA
ex7data2.mat - Example Dataset for K-means
ex7faces.mat - Faces Dataset
bird small.png - Example Image
displayData.m - Displays 2D data stored in a matrix
drawLine.m - Draws a line over an exsiting figure
plotDataPoints.m - Initialization for K-means centroids
plotProgresskMeans.m - Plots each step of K-means as it proceeds
runkMeans.m - Runs the K-means algorithm
submit.m - Submission script that sends your solutions to our servers
[*] pca.m - Perform principal component analysis
[*] projectData.m - Projects a data set into a lower dimensional space
[*] recoverData.m - Recovers the original data from the projection
[*] findClosestCentroids.m - Find closest centroids (used in K-means)
[*] computeCentroids.m - Compute centroid means (used in K-means)
[*] kMeansInitCentroids.m - Initialization for K-means centroids
* 表示需要完成的内容
1 K 均值聚类
在本次练习中,你将会实现 K -均值聚类算法并且使用它进行图像压缩。首先从一个 2D 的数据开始,它将帮助你对 K 均值算法有一个直观的印象。之后,你将会使用 K 均值算法进行图像压缩,通过将图像中颜色的数量减少到图像最常用的颜色。
1.1 实现 K 均值算法
K 均值算法是一种自动将相似数据聚集起来的方法。具体来说,你有一个训练集,并且想要想要将他们分成一些紧密结合的聚类。
直观上讲,K 聚类算法是一个循环程序,这个程序从推断初始的聚类中心开始,之后推断聚类中心,然后通过标记样本最接近的聚类中心对猜测不断精炼,之后根据标定重新计算聚类中心。
K 聚类算法如下所示
% Initialize centroids
centroids = kMeansInitCentroids(X, K);
for iter = 1:iterations
% Cluster assignment step: Assign each data point to the
% closest centroid. idx(i) corresponds to cˆ(i), the index
% of the centroid assigned to example i
idx = findClosestCentroids(X, centroids);
% Move centroid step: Compute means based on centroid
% assignments
centroids = computeMeans(X, idx, K);
end
内循环算法重复的执行两步:
- 将每个训练样本 x(i) 分配给最接近的聚类中心
- 使用分配点重复计算每一个聚类中心值的均值
对于聚类中心,K -均值算法总是收敛到最后一组均值。注意收敛解可能不总是最理想的,这取决于初始设置的聚类中心。因此,在实际中,K 均值聚类算法经常使用不同的初始值先运行几次。从这些不同的初始值得到的不同的解中选择的一种方法是选择一个最低的成本函数值。
1.1.1 寻找最接近的聚类中心
在 K 均值算法的聚类分配阶段,给出当前聚类中心的位置后,算法将每个训练样本 x(i)分配给最接近的聚类中心。对于每一个样本 i ,我我们设
![]()
c(i)是最接近x(i)的聚类中心,μj 是第 j 个聚类中心的位置(值)
注意 c(i)对应于开始代码中的 idx(i)
目标:
完成 findClosestCentroids.m
给出:
数据矩阵 X
所有聚类中心位置 centroids
要求:
输出一个一维数组 idx ,idx 中有每个训练样本最接近的聚类中心的索引
算法思路:
遍历每一个样本,找出每个样本距离最近的聚类中心
输出该样本所属聚类中心的索引
%需要注意的是,X 和 centroids 是一个二维向量
%每一行表示一个样本数据,每一列是他们的特征坐标,
dis = 0; %聚类中心到x(i)的距离
for i = 1:size(X,1)
min_dis = Inf;%聚类中心到x(i)的距离的最小值
for j = 1:K
dis = (X(i,:)-centroids(j,:))*(X(i,:)-centroids(j,:))';
% X n*2 centroids k*2
if dis < min_dis
min_dis = dis;
idx(i) = j;
endif
endfor
endfor
1.1.2 计算聚类均值
得到每个点对聚类的分配后,第二段的再计算是求出每一个聚类中心分配的点的均值。对于每一个聚类中心 k 我们设
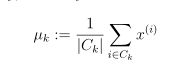
Ck是分配给聚类中心 k 的一组样本。具体来说,
如果有两个样本 x(3)和 x(5)分配给了聚类中心 k = 2
之后更新 μ2 = 1/2*(x(3) + x(5))
目标:
完成 computeCentroids.m 中的代码
给出:
数据矩阵 X
X中每个元素所属聚类的类别 idx
聚类 K
算法:
计算每个聚类所属点的均值
numberOfElementsHavingCentroid_k = zeros(K,1);
sumOfElementsHavingCentroid_k = zeros(K,n);
for i = 1:size(idx,1)
z = idx(i);
numberOfElementsHavingCentroid_k(z) += 1;
sumOfElementsHavingCentroid_k(z,:) += X(i,:);
end
centroids = sumOfElementsHavingCentroid_k./numberOfElementsHavingCentroid_k;
这段代码我自己写了一个,但有些繁琐,还出现了一些问题。就把参考答案上代码贴上来了
1.2 样本数据中的 K 均值算法
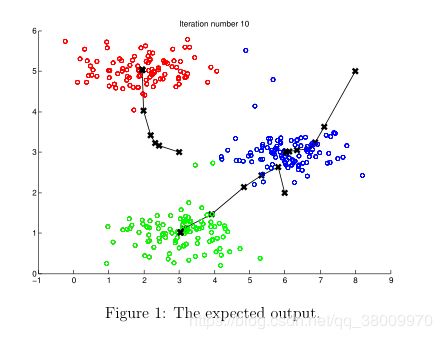
一步步按下回车后,Octave/Matlab 将会一步步显示 K 均值算法怎么找到最合适的聚类中心的。最终结果如下图:
1.3 随机初始化
% Initialize the centroids to be random examples
% Randomly reorder the indices of examples
randidx = randperm(size(X, 1));
% Take the first K examples as centroids
centroids = X(randidx(1:K), :);
比较简单。
课程中提过,可以多次初始化,求得其中最小的成本函数。以此来寻找比较合适的初始值
1.4 K 均值算法对图像压缩
我想要了解一下这部分的内容,不想看的可以跳过去第二部分了。下面是大段翻译:
在本次练习中,你将会应用 K 均值算法对图像进行压缩。在一个 24 位颜色表示的图像中,每个像素表示为 3 个 8 位 的无符号整数(0-255),分别是红色、绿色和蓝色的强度值。这个编码经常表示为RGB编码。我们的图像包含几千种颜色,在这部分的练习中,我们会将颜色的数量减少到 16 个。
通过这次削减颜色数量,能够将图像用一个有效的方式表示。尤其你仅需要用 16 个挑选出来的颜色存储 RGB 值,并且对于图像中每个像素,你现在只需要存储位置颜色中的索引( 4 位就足以表示 16)
在本次练习中,你将会使用 K 均值算法挑选出 16 个颜色来表示压缩的图像。具体来说,你将会把源图像中每一个像素作为一个数据样本,使用 K 均值算法寻找 16 种 3 维 RGB 空间中的最佳聚类。一旦你完成对图像聚类中心的计算,你就可以用 16 种颜色表示原始图像中的像素。
1.4.1 K均值算法用于像素
在 Octave/Matlab 中,图像可以被如下代码读取:
% Load 128x128 color image (bird small.png)
A = imread('bird small.png');
% You will need to have installed the image package to used
% imread. If you do not have the image package installed, you
% should instead change the following line to
%
% load('bird small.mat'); % Loads the image into the variable A
这创造了一个 3 维矩阵 A,A 的前两个索引表示一个像素的位置,最后一个索引表示 红,绿,蓝。比如,A(50, 33, 3) 表示 50 行 33 列 的蓝色像素。
ex7.m中的代码首先输入了图像,之后用一个 m x 3 维的像素颜色矩阵(m = 16384 = 128 x 128)重构了它,并且调用 K 均值函数处理它。
在找到最优的 K = 16 个颜色表示图像后,你现在可以使用 findClosestCentroids 函数将每个像素位置划分到最接近它的聚类中心。这允许你使用每个像素点的聚类中心分配表示原图像。注意,你已经显著减少了描述一个图像所需要的数量。
对于 128 x 128 像素位置中的每一个像素,原始图像需要 24 位表示,总大小为
128 x 128 x 24 = 393,216 位。新的表示形式需要16种颜色的字典形式的开销存储
(什么意思? The new representation requires some overhead storage in form of a dictionary of 16 colors,)每种颜色 24 位,但是图像每个像素位置本身仅需要 4 位(16需要4个二进制数表示)。那么最后位数为:
16 x 24 + 128 x 128 x 4 = 65920 位,将原始图像大约压缩了 6 倍。
(这里为什么还要加 16 x 24?)
2 主成成份分析(PCA)
在本次的练习中,你将会使用 PCA 实现维度压缩。首先,你会用一个 2 维的数据对 PCA 如何工作有一个直观的印象,之后你将会在一个 5000 人脸图像数据上使用它。
2.1 示例数据
在这部分,你将会看到当使用 PCA 将数据从 2 维减少到 1 维时会发生什么。
2.2 实现 PCA
PCA 由两步运算组成:
1 计算数据的协方差
2 使用 Octave/Matlab 中 SVD 函数计算 特征向量 U~1~,U~2~,……,U~n~。这些对应数据主成成分。
在使用 PCA 之前,需要对数据归一化处理
任务:
完成 pca.m,计算数据的主成成份。
给出:
数据矩阵 X,每一行表示一个样本。
m 样本数
算法:
1.计算数据的协方差矩阵,公式:
Sigma = 1/m * X'*X
注意 Sigma 是一个 n * n 的矩阵
2.使用 SVD 函数,计算主成成份。 调用格式:
[U, S, V] = svd(Sigma);
U 包含了主成成份,S 包含一个对角阵
Sigma = zeros(n);
Sigma = 1/m * (X'*X);
[U, S, V] = svd(Sigma);
补充资料(svd 函数 待做)
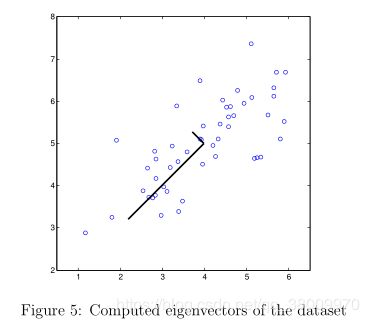
代码正确后运行图:
2.3 使用 PCA 降维
在这部分的练习中,你将会使用 PCA 返回的特征向量将样本数据映射为到 1 维空间中
数据降维的作用:
在处理实际问题时,如果你使用一个学习算法比如线性回归或者神经网络,你可以使用映射后的数据代替原始数据。因为输入维度降低,使用映射后的数据可以让你更快的训练模型。
2.3.1 将数据映射到主成成份中
任务:
完成 projectData.m ,将数据维度减小到 K
给出:
数据 X
主城成分 U
所需维度 K
算法:
得出 U 的前 K 个特征 U_reduce
计算降维后的数据
Z = X * U_reduce
要求:
将 X 中每个样本映射到 U 中主要的 K 个成分。
注意:U 中主要的 K 的成分由 U 的前 K 列得到。
U_reduce = U(:, 1:K)
U_reduce = U(:,1:K); %U_reduce n*K
Z = X * U_reduce % z m*k
2.3.2 重构一个近似数据
任务:
完成 recoverData.m ,重构被降维的数据
给出:
降维后数据 Z
特征向量 U
算法:
X_rec = Z * U(j, 1:K)';
X_rec = Z * U(j, 1:K)';
2.3.3 可视化投影
图 6 中,原始数据点用蓝色圆圈表示,投影数据点用红色圈表示,投影只能在 U1 的方向有效表示数据。
将原图(左)与近似还原图(右)对比一下就明白了。

|

|
2.4 面部图像数据
在这部分的练习中,你将会在面部图像数据中运行 PCA,来观察它在实际中是怎样实现降维的。
面部图像数据集 X,每个图像是 32 x 32 的灰度图
X 的每一行对应一个人脸图像 (长度为 1024 的行向量)

2.4.1 PCA 用于面部数据
将 PCA 用于面部数据后,U 的每一行(每一个主成成份)都是一个长度为 n 的向量。这表示,我没可以通过将这些主成成份重构成对应原始数据的 32 x 32 的矩阵来可视化他们。
图 8 显示了描述最大变化的前 36 个主成成份

2.4.2 降维
完成主成成份的计算后,就可以对数据降维。将原始数据的 1024 维压缩成 100 维,加快模型学习速度。
对映射后的数据恢复后,将原图(左)与恢复图(右)对比,来了解降维后发生了什么

通过对比,可以观察到:
尽管恢复后的数据保持了大部分的面部结构和外貌,然而却丢失了部分的细节。因此,尽管PCA 能极大提升模型训练速度,但如果不用 PCA 就能很轻松解决问题,就不用 PCA。因为它会丢失部分数据,而丢失的数据中可能含有有用信息。相对的,如果训练数据特别大,而且模型对细节要求不是很高,例如人脸识别,就能极大提升训练速度(1024 → 100)
选作部分就不再多说了,自己看代码理解就行。
选作部分就不再多说了,自己看代码理解就行。描述大部分都是自己直接翻译,如果有什么问题请在评论留言。有其他的问题也欢迎一起讨论。