极限学习机(ELM)算法原理及C++代码实现
从事机器学习研究两年多了,第一个用的算法就是极限学习机,CSDN算是我的领路人,在此感谢一下CSDN上分享知识的大神们,即将毕业,所学颇杂,想在此开始总结一下,顺便也为即将入坑的新手们做一些贡献。第一篇博文,或有许多不足之处,请各路大神指教,尽量做到按以下步骤能够理解并实现极限学习机算法。
算法介绍
极限学习机是一种单隐含层的前馈神经网络,其效率高,正确率高,泛化性能强,从初学该算法至今一直有在使用。与BP等传统神经网络结构相似,但是其计算原理与传统网络却大相径庭。传统网络通过正向传播,可求出模型的实际输出,通过模型输出与实际标签的误差可以求出误差函数,使用误差反向传播算法和梯度下降,通过不断迭代求出使得误差最小的模型参数。而极限学习机输入层到隐含层的权重,及隐含层的偏置可以随机初始化,不需要迭代修正,而隐含层到输出层的权重通过求解矩阵方程得到。这也是极限学习机的一大特点:不需迭代学习,训练速度快
算法原理
设输入特征矩阵为Xk×n ,输出类别矩阵为 Yk×m ,其中k为训练数据个数,n为输入的特征向量维数,m为输出的类别个数,输入层到隐含层的权重为ωn×L ,ω=random(-1, 1) , 隐含层偏置为B1xL ,B=random(0, 1) , 隐含层到输出层的权重为βL×m ,其中L为隐含层节点数。设隐含层输出矩阵为H:
![]() (编辑器太麻烦了,部分公式就截图吧,这里需要注意的是,Xw得到的是k*L的矩阵,B是1*L的向量,这里的“+”是指,矩阵的每一行加上B)
(编辑器太麻烦了,部分公式就截图吧,这里需要注意的是,Xw得到的是k*L的矩阵,B是1*L的向量,这里的“+”是指,矩阵的每一行加上B)
其中G为激活函数,
![]()
输出类别求解公式:
Y=Hβ
训练时已知X,Y,且ω 和B通过随机初始化,即已知H和Y,通过上式求β :
![]()
但是在实际问题中H的逆不一定存在,因此需引入广义逆求法:
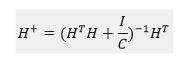
其中H+ 为H的广义逆,I为单位矩阵,C为惩罚因子,决定了系统结构与数据对模型性能的影响比重。即上式变为
![]()
经过训练得到了β ,至此模型所有参数均已获得,可以在测试集中进行测试啦。
C++代码实现(经过本人严格调试,复制黏贴,更换数据路径和参数即可使用,谢谢支持)
ELM.h(因为涉及矩阵运算,为了方便引入了Eigen矩阵计算库)
#pragma once
#include"pch.h"
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
using namespace Eigen;
class ELM
{
public:
#define actsigmoid 1
#define actrelu 2
#define actprelu 3
#define acttanh 4
#define actsoftplus 5
#define actsoftsin 6
#define actsin 7
#define pi 3.141592654
ELM(int m, int n, int L, double C );//类别数 特征数 隐含层节点数 惩罚因子
~ELM();
MatrixXd X;//输入特征
MatrixXd H;//隐含层输出矩阵
MatrixXd Y;//输出层类别
MatrixXd W;//输入层到隐含层权重
MatrixXd B;//隐含层偏置
MatrixXd B_1;
MatrixXd P;//在线学习迭代参数
MatrixXd beta;//隐含层到输出层权重
MatrixXd output;//训练时的实际输出
MatrixXd X_test;
MatrixXd Y_test;
vector doubleX_test;
vector doubleX;
MatrixXd y;//验证集实际输出
void GetTrainData(string filename);
void GetTestData(string filename);
double Train(MatrixXd X1);
vector Test(MatrixXd feature);
void valid(vectora);
void valid(MatrixXd feature, MatrixXd label);
void loadParm();
int actmode;
int mode;
MatrixXd OnlineLearning(MatrixXd newData, MatrixXd label);
int L;//隐含层节点
double C;//损失因子
int n;//特征数
int m;//类别数
};
ELM.cpp(各函数实现方式)
// ELM.cpp : 定义控制台应用程序的入口点。
//
#include "pch.h"
#include"ELM.h"
#include
ELM::ELM(int m, int n, int L, double C)
{
this->m = m;
this->n = n;
this->L = L;
this->C = C;
mode = 1;//beta计算模式,0为随机生成
actmode = actsigmoid;
}
ELM::~ELM()
{
}
void ELM::GetTrainData(string filename)
{
ifstream trainfile;
trainfile.open(filename);
if (!trainfile)
{
cout << "文件出错!" << endl;
return;
}
vector> traindata;
vector rowdata;
VectorXd temp_1(1 + n), temp;
temp = temp_1.transpose();
while (trainfile >> temp(0))
{
rowdata.push_back(temp(0));
if (trainfile.eof())break;
for (int i = 1; i < (1 + n); i++)
{
trainfile >> temp(i);
rowdata.push_back(temp(i));
}
traindata.push_back(rowdata);
rowdata.erase(rowdata.begin(), rowdata.end());
}
trainfile.close();
X = MatrixXd(traindata.size(), n);//特征?
Y = MatrixXd(traindata.size(), m);
for (int i = 0; i < traindata.size(); i++)
{
for (int j = 0; j < (1 + n); j++)
{
if (j < n)
X(i, j) = traindata[i][j];
else
{
Y(i, j - n) = traindata[i][j];
}
}
}
vector feature_av(m);
vector>feature_n(m);
for (int i = 0; i < m; i++)
{
feature_av[i] = VectorXd::Zero(n);
}
for (int i = 0; i < traindata.size(); i++)
{
int flag = Y(i, 0);
Y.row(i) = VectorXd::Zero(m);
Y.row(i)(flag - 1) = 1;
feature_n[flag - 1].push_back(X.row(i));
feature_av[flag - 1] = (feature_av[flag - 1] + X.row(i).transpose()) / 2;
}
}
void ELM::GetTestData(string filename)
{
ifstream trainfile;
trainfile.open(filename);
if (!trainfile) cout << "文件出错!" << endl;
vector> traindata;
vector rowdata;
VectorXd temp_1(1 + n), temp;
temp = temp_1.transpose();
while (trainfile >> temp[0])
{
rowdata.push_back(temp[0]);
if (trainfile.eof())break;
for (int i = 1; i < (1 + n); i++)
{
trainfile >> temp[i];
rowdata.push_back(temp[i]);
}
traindata.push_back(rowdata);
rowdata.erase(rowdata.begin(), rowdata.end());
}
trainfile.close();
X_test = MatrixXd(traindata.size(), n);//特征?
Y_test = MatrixXd(traindata.size(), m);
cout < feature_av(m);
vector>feature_n(m);
for (int i = 0; i < m; i++)
{
feature_av[i] = VectorXd::Zero(n);
}
for (int i = 0; i < traindata.size(); i++)
{
int flag = Y_test(i, 0);
Y_test.row(i) = VectorXd::Zero(m);
Y_test.row(i)(flag - 1) = 1;
feature_n[flag - 1].push_back(X_test.row(i));
feature_av[flag - 1] = (feature_av[flag - 1] + X_test.row(i).transpose()) / 2;
}
}
double ELM::Train(MatrixXd X1)
{
int N = Y.size() / m;//输入样本数
MatrixXd R, Tem;
W = MatrixXd::Random(n, L);//随机产生输入权重
B_1 = (MatrixXd::Random(1, L) + MatrixXd::Ones(1, L)) / 2;
B = MatrixXd::Ones(N, 1)*B_1;//随机产生偏置
switch (actmode)
{
case actsigmoid:H = 1 / (exp(-(X1*W + B).array()) + 1); break;
case actrelu:
{
H = X1 * W + B;
for (int i = 0; i < H.rows(); i++)
{
for (int j = 0; j < H.cols(); j++)
if (H(i, j) < 0)
H(i, j) = 0.01*H(i, j);
}
}break;
case actprelu:
{
H = X1 * W + B;
for (int i = 0; i < H.rows(); i++)
{
for (int j = 0; j < H.cols(); j++)
if (H(i, j) < 0)
H(i, j) = 0;
}
}break;
case acttanh: {
H = X1 * W + B;
H.array() = (exp(H.array()) - exp(-H.array())) / (exp(H.array()) + exp(-H.array()));
}break;
case actsoftplus: {
H = X1 * W + B;
H.array() = log(exp(H.array()) + 1);
}break;
case actsoftsin: {
H = (X1*W + B).array() / (abs((X1*W + B).array()) + 1);
}break;
case actsin: {
H = (X1*W + B);
for (int i = 0; i < H.rows(); i++)
{
for (int j = 0; j < H.cols(); j++)
if (H(i, j) < -pi / 2)
H(i, j) = -1;
else if
(H(i, j) > pi / 2)
H(i, j) = 1;
else
H(i, j) = sin(H(i, j));
}
}break;
default:break;
}
MatrixXd result(L, N);
MatrixXd Ones = MatrixXd::Identity(L, L);
result = ((H.transpose()*H) + Ones / C).inverse()*H.transpose();//C为惩罚因子, 当样本数大于节点数时
switch (mode)
{
case 1:beta = result * Y; break;//输出权重
case 0:beta = MatrixXd::Random(L, m); break;
default:
break;
}
output = H * beta;//实际输出
float loss = 0;
int m_icorrect = 0;
int m_imax_index1 = 0;
int m_imax_index = 0;
for (int i = 0; i < N; i++)
{
double m_dmax = 0;
double m_dmax1 = 0;
for (int j = 0; j < m; j++)
{
output(i, j) = pow(output(i, j), 2) / (output.row(i)*output.row(i).transpose());
if (m_dmax < output(i, j))
{
m_dmax = output(i, j);
m_imax_index = j;
}
if (m_dmax1 < Y(i, j))
{
m_dmax1 = Y(i, j);
m_imax_index1 = j;
}
}
if (m_imax_index == m_imax_index1)
m_icorrect++;
loss = loss + (output.row(i) - Y.row(i))*(output.row(i) - Y.row(i)).transpose();
}
ofstream betafile, bfile, Wfile;
betafile.open("参数文件\\beta.txt");
if (!betafile) cout << "open file error" << endl;
else
{
for (int i = 0; i < beta.col(0).size(); i++)
{
for (int j = 0; j < beta.row(0).size(); j++)
betafile << beta(i, j) << " ";
betafile << endl;
}
}
bfile.open("参数文件\\b.txt");
if (!bfile) cout << "open file error" << endl;
else
{
for (int j = 0; j < B.row(0).size(); j++)
bfile << B(0, j) << endl;
}
Wfile.open("参数文件\\W.txt");
if (!Wfile) cout << "open file error" << endl;
else
{
for (int i = 0; i < W.col(0).size(); i++)
{
for (int j = 0; j < W.row(0).size(); j++)
Wfile << W(i, j) << " ";
Wfile << endl;
}
}
//指导性参数更新
//for (int j = 0;j < beta.rows();j++)
//{
// beta(j, 4) = 1.5*beta(j, 4);
// beta(j, 6) = 1.1*beta(j, 6);
//}
cout << "损失率:" << loss / N << " 训练正确率: " << m_icorrect << " / " << N << " = " << (double)m_icorrect / N << endl;
return loss;
}
vector ELM::Test(MatrixXd feature)
{
vector species;
vectormaxy;
MatrixXd temp = MatrixXd::Ones(feature.rows(), 1);
B = temp*B.row(0);
MatrixXd h;
switch (actmode)
{
case actsigmoid:h = 1 / (exp(-(feature*W + B).array()) + 1); break;
case actrelu:
{
h = feature*W + B;
for (int i = 0; i < h.rows(); i++)
{
for (int j = 0; j < h.cols(); j++)
if (h(i, j) < 0)
h(i, j) = 0.01*h(i, j);
}
}break;
case actprelu:
{
h = feature*W + B;
for (int i = 0; i < h.rows(); i++)
{
for (int j = 0; j < h.cols(); j++)
if (h(i, j) < 0)
h(i, j) = 0;
}
}break;
case acttanh: {
//h = (exp((feature*W + B).array())- exp(-(feature*W + B).array()))/ (exp((feature*W + B).array()) + exp(-(feature*W + B).array()));
h = feature*W + B;
h = (exp(h.array()) - exp(-h.array())) / (exp(h.array()) + exp(-h.array()));
}break;
case actsoftplus: {
h = feature*W + B;
h = log(exp(h.array()) + 1);
}break;
case actsoftsin: {
h = (feature*W + B).array() / (abs((feature*W + B).array()) + 1);
}break;
case actsin: {
h= (feature*W + B);
for (int i = 0; i < h.rows(); i++)
{
for (int j = 0; j < h.cols(); j++)
if (h(i, j) < -pi / 2)
h(i, j) = -1;
else if
(h(i, j) > pi / 2)
h(i, j) = 1;
else
h(i, j) = sin(h(i, j));
}
}break;
default:break;
}
y=h*beta;
//cout << y << endl;
for (int i = 0; i < y.rows(); i++)
{
y.row(i).array() = pow(y.row(i).array(), 2) / (y.row(i)*y.row(i).transpose());
maxy.push_back(0);
species.push_back(0);
for (int j = 0; j < y.cols(); j++)
{
if (maxy[i] < y(i, j))
{
maxy[i] = y(i, j);
species[i] = j+1;
}
}
}
//for (int i = 0; i < species.size(); i++)
// cout << species[i] << " ";
return species;
}
void ELM::loadParm()
{
cout << "加载参数" << endl;
ifstream betafile, bfile, Wfile;
betafile.open("参数文件\\beta.txt");
if (!betafile)
cout << "open beta error!" << endl;
else
{
while (!betafile.eof())
{
for (int i = 0; i < beta.col(0).size(); i++)
{
for (int j = 0; j < beta.row(0).size(); j++)
{
betafile >> beta(i, j);
}
}
}
cout << "beta load success!" << endl;
}
bfile.open("参数文件\\b.txt");
if (!bfile)
cout << "open b error!" << endl;
else
{
while (!bfile.eof())
{
for (int j = 0; j < B_1.row(0).size(); j++)
{
bfile >> B_1(0, j);
}
}
cout << "b load success!" << endl;
B = MatrixXd::Ones(X.rows(), 1)*B_1;
}
Wfile.open("参数文件\\W.txt");
if (!Wfile)
cout << "open W error!" << endl;
else
{
while (!Wfile.eof())
{
for (int i = 0; i < W.col(0).size(); i++)
for (int j = 0; j < W.row(0).size(); j++)
{
Wfile >> W(i, j);
}
}
cout << "W load success!" << endl;
}
}
void ELM::valid(vector a)
{
long t1 = clock();
//vectora = Test(X_test1);
vectorb(Y_test.cols());
vectorc(Y_test.cols());
VectorXi d = VectorXi::Zero(Y_test.cols());
for (int i = 0;i < Y_test.cols();i++)
c[i] = d;
cout << "验证耗时: " << clock() - t1 << endl;
int correct = 0;
for (int i = 0; i < a.size(); i++)
{
int y = 0;
int spec = 1;
for (int j = 0; j < Y_test.cols(); j++)
{
if (y < Y_test(i,j))
{
y = Y_test(i,j);
spec = j + 1;//实际类别
}
}
if (a[i] == spec)
{
correct++;
c[spec - 1](a[i] - 1)++;
}
else
{
//cout << spec << " error to: " << a[i] << endl;
b[spec - 1]++;
c[spec - 1](a[i]-1)++;
}
}
cout << "识别错误:" ;
for (int j = 0; j < b.size(); j++)
cout << b[j] << " ";
cout << endl<<"验证正确率: " << correct << " / " << Y_test.rows() << " = " << (double)correct / Y_test.rows() << endl;
for (int i = 0;i < c.size();i++)
{
for (int j = 0;j < c[i].size();j++)
cout << c[i](j) << " ";
cout << endl;
}
} main.cpp(测试程序,训练数据和测试数据分成两个文件,懂c++的也可以自己稍微操作一下,研究所用数据不方便透露,只需将读取数据中的路径改成自己的文件,根据自己数据的特征数和类别数修改参数即可)
#include "pch.h"
#include
#include"ELM.h"
#include
int main()
{
ELM ETest(6, 28, 300, 5000);//6分类,特征向量维数28,隐含层节点数300,惩罚因子5000
cout << "参数:特征数 m: 类别数n: 惩罚因子C: 节点数L: " << ETest.n << " " << " " << ETest.m << " " << ETest.C << " " << ETest.L << endl;
ETest.GetTrainData("E:\\1Dataset\\ROI数据\\20190917_50000I3R1WT3.txt");
ETest.GetTestData("E:\\1Dataset\\ROI数据\\20190917_30000I4R1WT3.txt");
long t1 = clock();
ETest.actmode = actsigmoid;
ETest.Train(ETest.X);
cout << "train time:" << clock() - t1;
ETest.valid(ETest.X_test, ETest.Y_test);
}
附一张本人数据中运行的效果
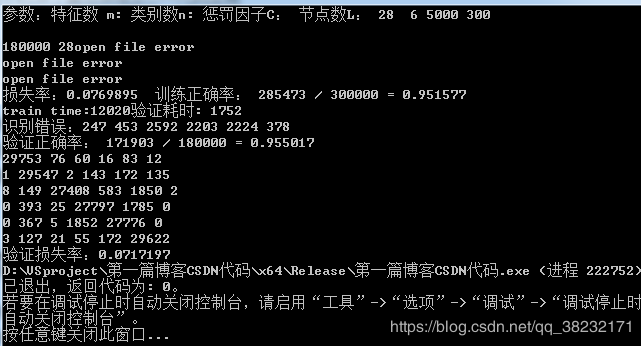
本人测试用的数据,训练集30万组28维特征的6分类数据,训练耗时近12秒,速度远超过传统的BP方式,测试集18万个数据,训练和测试正确率均约95%,测试总耗时175ms。说明其泛化性能很好,正确率高,效率高,修改参数C可以改变泛化性能,C越小泛化性能越好,但是太小的C会导致正确率下降,反之亦然。(美的不行,反正我现在是很推崇这算法的,研究应用中还修改了增加核函数的方式,以及在线学习的功能,后续有时间还会来分享的)。不知道会不会有人看,但是文中出现的所有文字,公式,代码均为自己手动敲的,欢迎转载,但请尊重作者的劳动成果,谢谢。(没人看的话那就尴尬了啊,哈哈哈)