分布式日志收集(ELK+Kafka)
问题:为什么需要ELK+Kafka实现分布式日志收集?
单纯使用EIK实现分布式日志收集缺点:
- 当产生日志的服务节点越来越多,Logstash也需要部署越来越多,扩展不好。
- 读取IO文件,可能会产生日志丢失。
- 读取文件不是实时性,中间需要引入到Kafka,日志实时发布到Kafka,Logstash订阅并实时获取消息。
面试题:Logstash数据来源有哪些?
本地文件、Kafka、数据库、MongoDB、Redis等
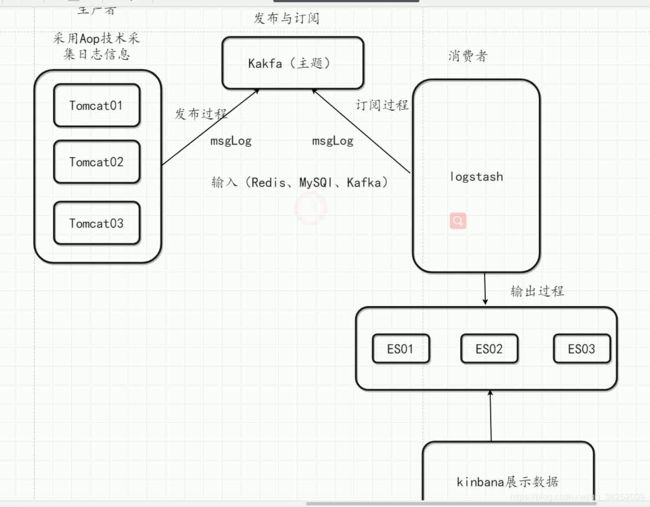
ELK分布式日志收集流程图:

ELK+Kafka分布式日志收集流程图:
ELK+Kafka架构在应用服务与Logstash之间多了一个Kafka,解决了日志丢失和非实时性的问题。
思考问题:
-
哪些日志信息需要输入logstash?(
error级别) -
AOP异常通知服务统一处理,服务之间如何区分日志索引文件?(
服务名称) -
在分布式日志收集中,相同的服务集群的话是不需要区分日志索引文件? (注意:集群环境代码都一样,理论上不需要做,并不代表就不做)
优点:统一管理相同节点日志信息
缺点:当发生JVM内存泄漏、内存溢出等情况无法定位到具体服务器 -
相同的服务集群的话,如果不区分日志索引文件搜索日志的时候,如何定位服务器节点信息呢?
(IP和端口号)
通过ip和端口弥补了第3点的不足,无法定位到具体的服务器。
当发生JVM内存泄漏、内存溢出时快速找到发生问题所在的服务器是非常重要的,这样便于快速排查问题。 -
分布式调用连与追踪系统查找
基于Docker搭建Kafka环境:
注:Kafka环境依赖于Zookeeper,安装Kafka前需要安装Zookeeper。
关于Docker安装及使用参考:Docker安装教程(CentOS 7.3) Docker常用命令
ELK搭建参考:分布式系统日志收集(ELK)
1. Kafka与Zookeeper的关系
-
zookeeper作为解决分布式一致性问题的工具而被kafka依赖。而分布式模式,即去中心化的集群模式,需要让消费者知道现在有哪些生产者(对于消费者而言,kafka就是生产者)是可用的。如果没了zk消费者如何知道呢?如果每次消费者在消费之前都去尝试连接生产者测试下是否连接成功,效率就会变得很低。
-
Kafka使用zk的分布式协调服务,将生产者,消费者,消息储存(broker,用于存储信息,消息读写等)结合在一起。同时借助zk,kafka能够将生产者,消费者和broker在内的所有组件在无状态的条件下建立起生产者和消费者的订阅关系,实现生产者的负载均衡。
链接:kafka依赖zookeeper原因解析及应用场景
2. 安装Zookeeper
- 下载Zookeeper镜像
docker pull wurstmeister/zookeeper - 运行Zookeeper环境
docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper
3. 安装Kafka
- 下载Kafka镜像
docker pull wurstmeister/kafka - 运行Kafka环境
docker run --name kafka01 \
-p 9092:9092 \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=192.168.2.101:2181 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.101:9092 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-d wurstmeister/kafka
问题:运行Kafka时,Kafka会连接Zookeeper可能会超时,导致Kafka容器没启动成功,启动时不加-d可以查看启动日志,或者使用命令查询日志
docker logs --tail="100" 容器名称,100表示从文件末尾往上显示多少行日志。
解决方案:这时可删除容器并重启Docker,然后再次启动Kafka。
- 进入容器
docker exec -it kafka01 /bin/bash - 创建topic
/opt/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.2.101:2181 --replication-factor 1 --partitions 1 --topic order_log - 查询创建topic
/opt/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.2.101:2181
基于Docker搭建Elasticsearch与Kibana环境
注意:Elasticsearch与Kibana执行Docker pull要加上版本号,否则会找不到镜像,镜像拉取命令如下:
docker pull elasticsearch:6.4.3
docker pull kibana:6.4.3
启动ES命令:(es实际应用中是要做集群的)
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 -p 5601:5601
-v /usr/local/es/config/es1.yml:/usr/share/elasticsearch/config/elasticsearch.yml
-v /usr/local/es/plugins1:/usr/share/elasticsearch/plugins
-v /usr/local/es/data1:/usr/share/elasticsearch/data --name ES01 elasticsearch:6.4.3
也可使用这条简单启动命令:
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 -p 5601:5601 --name ES01 elasticsearch:6.4.3
启动Kibana命令:
docker run -it -d -e ELASTICSEARCH _URL=http://127.0.0.1:9200
--name kibana --network=container:ES1 kibana:6.4.3
图:

基于AOP拦截服务器日志信息(Logstash订阅主题并输出到ES)
1. 新建common-elk-kafka项目(公共模块)
项目介绍:common-elk-kafka属于公共模块,其他项目若需要实现日志收集功能,只需要引入该项目的Maven依赖并通过简单配置即可。Demo演示就直接做成一个项目了,看下效果就行了。
Demo地址:TODO…
将请求和响应日志信息输出到Logstash中
实现思路:主要利用AOP的“前置通知” 和 “后置通知” 将请求和响应日志封装成JSON,并推送到Kafak中。
KafkaSender核心代码:
/**
* Kafka消息发送器
* @param 消息类型
*/
@Log4j2
@Component
public class KafkaSender<T> {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* Kafka发送消息
* @param obj 消息
*/
public void send(T obj){
String jsonObj = JSON.toJSONString(obj);
//TODO 发送消息后期实现可自动化配置,如主题名
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("order_log",jsonObj);
//回调通知
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
log.info("Produce: The message failed to be send: "+throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> stringStringSendResult) {
//TODO 业务处理
log.info("Produce: The message was send successfully: "+stringStringSendResult.toString());
}
});
}
}
AOP日志切面核心代码:
/**
* 收集请求日志和响应日志,并发送到Kafka
*
* 注意:
* 1. 多个项目每个项目对应不同的主题不同的主题对应不同的Logstash请求与响应的日志是如何区分呢?
* 使用标识符,如: 请求日志 {“request":{}} 响应日志 {“response":{}} 错误 {"error":{}}
*
* 2. 请求和响应或错误日志怎么联系起来呢?
* 唯一标识符
*
* @author wangxu
* @date 2019-10-27 18:53:00
*/
@Log4j2
@Aspect
@Component
public class AopLogAspect {
@Autowired
private KafkaSender<Object> kafkaSender;
/**
* 切点方法
*/
@Pointcut("execution(public * com.example.elk.controller.*.*(..))")
public void webLog(){ }
/**
* 前置通知,记录请求日志
* @param joinPoint
* @throws Throwable
*/
@Before("webLog()")
public void doBefore(JoinPoint joinPoint) throws Exception{
//获取请求对象
HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getRequest();
//输出请求日志信息
log.info("请求信息: URI: {} , Method: {} , Description: {} 》》》 ",request.getServletPath(),request.getMethod());
//将请求日志信息发送到Kafka
JSONObject jsonObject = new JSONObject();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
jsonObject.put("request_time", sdf.format(new Date()));
jsonObject.put("request_uri",request.getRequestURI());
jsonObject.put("request_params",request.getParameterMap());
jsonObject.put("signature",joinPoint.getSignature());
jsonObject.put("service_ip:","本地ip,linux上获取方式需要注意....");
jsonObject.put("service_port","配置文件中获取本机端口....");
jsonObject.put("service_name","配置文件中获取....");
JSONObject requestJsonObject = new JSONObject();
requestJsonObject.put("request",jsonObject);
kafkaSender.send(requestJsonObject);
}
/**
* 在方法执行完成后打印返回内容,并记录返回日志
* @param ret
* @throws Throwable
*/
@AfterReturning(returning = "ret",pointcut = "webLog()")
public void doAfterReturning(Object ret) throws Exception{
//处理完请求,返回内容
log.info("请求返回信息: "+JSONObject.toJSONString(ret));
//将响应日志信息发送到Kafka
JSONObject jsonObject = new JSONObject();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
jsonObject.put("response_time", sdf.format(new Date()));
jsonObject.put("response_content",JSONObject.toJSONString(ret));
JSONObject respJsonObject = new JSONObject();
respJsonObject.put("response",jsonObject);
kafkaSender.send(respJsonObject);
}
}
将异常日志输入到Logstash中(重要)
实现思路:
在SpringBoot全局异常处理里面做,当然利用AOP也可以拦截异常通知,但全局处理异常更简洁。
GlobalExceptionHandler核心代码:
/**
* 全局异常处理(将异常消息推送到Kafka,Logstash订阅主题并输出到Elasticsearch进行统一存储)
* @author wagnxu
* @date 2019-10-24 14:59:41
*/
@RestControllerAdvice
@Log4j2
public class GlobalExceptionHandler {
@Autowired
private KafkaSender<JSONObject> kafkaSender;
@ExceptionHandler(Exception.class)
public Map exceptionHandler(Exception e){
log.info("全局捕获异常: ", e);
//1.封装异常日志信息,发送到kafka
JSONObject logJson = new JSONObject();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getRequest();
//请求信息封装
logJson.put("request_time", sdf.format(new Date()));
logJson.put("request_ip",request.getRemoteAddr());
logJson.put("request_uri",request.getRequestURI());
logJson.put("request_param:",request.getParameterMap());
//本机的一些信息,用于排查JVM一些问题(如:内存泄漏、内存溢出),方便定位到 "发生异常的服务器" 和 "服务器上集群中的某个服务"
//可以记录下IP和端口信息,日后方便定位到该服务的异常)是在集群中那个节点抛出的
//注:一般来说同一个服务在集群中的代码虽然一样,一个节点报错其他节点业务逻辑也应该报错,但是有时候是JVM的一些原因,比如说内存溢出,这时候有了ip我们就好排查是哪台服务器有问题
//TODO 获取当前服务的IP
logJson.put("service_ip:","本地ip,linux上获取方式需要注意....");
//TODO 从配置文件获取当前服务端口
logJson.put("service_port","配置文件中获取本机端口....");
//TODO 从配置文件中获取当前服务名
logJson.put("service_name","配置文件中获取....");
logJson.put("error_info",e);
JSONObject errorJson = new JSONObject();
errorJson.put("request_error",logJson);
kafkaSender.send(errorJson);
//2.返回异常信息
Map map = new HashMap(2);
map.put("status",500);
map.put("msg","系统错误");
return map;
}
}
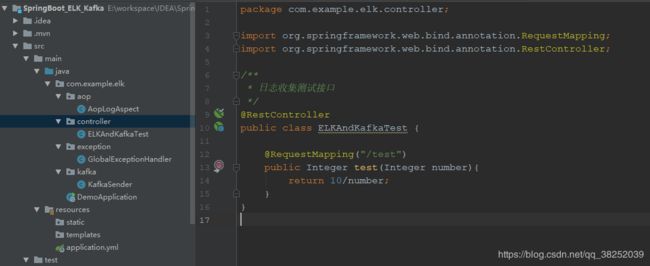
测试接口:可以自己写个接口进行测试,下面是我的测试接口
2. Logstash通过订阅topic,获取日志并输入到ES(Input来源Kafka,Output到ES)
- Logstash下载:
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.4.3.tar.gz - 进入Logstash的config目录新建配置文件
input_from_kafka.conf,文件名随意,启动时需要指定此配置文件,配置文件内容如下:
input {
kafka{
# 指定Kafka地址,集群则逗号分隔
bootstrap_servers => "192.168.2.101:9092"
# 订阅的主题
topics => ["order_log"]
}
}
output{
stdout { codec => rubydebug}
elasticsearch {
# 指定ES服务地址 做了集群的话可指定多个
hosts => ["192.168.2.101:9200","192.168.2.102:9201"]
# 指定索引名称,可自定义,但尽量有意义
index => "order_log"
}
}
- 启动:进入Logstash的bin目录执行命令
./logstash -f ../config/input_from_kafka.conf
我们可以发现Logstash日志输出了Kafka消费者的配置信息:

启动报错:
报错:Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the "path.data" setting.
原因:之前运行的instance有缓冲,保存在path.data里面有.lock文件,删除掉就可以。
解决:在 logstash.yml 文件中找到 Data path 的路径(默认在安装目录的data目录下)
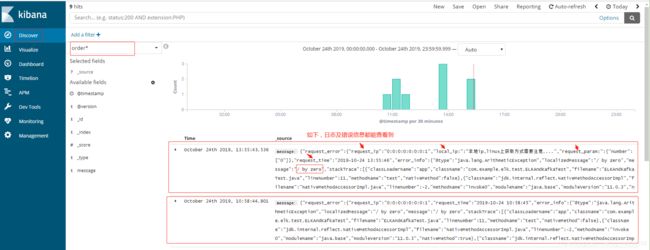
3. 通过Kibana查询日志
- 通过Kibana可视化界面查询ES日志信息,并且可以指定多种查询条件,我们只需要建立一个索引通配符即可;也可以通过ES提供的查询命令来查询。
- 可视化界面也可以不使用Kibana,有点公司会自己搭建一个后台系统调用ES查询接口。
Kibana界面查询日志如图:
4. Error预警系统
实现思路:通过定时任务,调用ES接口查询Error和异常信息,并以邮件的形式通知给相关人员。