Panoptic Feature Pyramid Networks阅读笔记
Panoptic Feature Pyramid Networks阅读笔记
论文地址:https://arxiv.org/abs/1901.02446
简介
全景分割任务是将实例分割和语义分割统一起来的任务,然而目前的该任务通常使用独立并不同的网络来执行以上两个任务并且不能共享计算。该篇文章目的是将全景分割任务集成与一个单一网络,为Mask R-CNN网络增加语义分割分支,该语义分割分支与Mask R-CNN共享FPN基础结构。值得一提的是,该结构不仅保留了原先Mask R-CNN的实例分割效果,还有高性能的语义分割效果。文章称该结构为Panoptic FPN,并且通过实验证明了其对于语义分割和实例分割任务的鲁棒性和准确性。文章作者希望该网络能称为以后全景分割的基线并助力全景分割的发展。
全景分割面临的困难
全景分割任务从概念上看起来很直观,然而实例分割和语义分割任务的高性能实现网络却有很多差别。语义分割任务常常使用由空洞卷积[55,10]助力的特定骨架的FCNs执行[17,14];实例分割任务常常由具有FPN[34]骨架的基于区域的Mask R-CNN[23]实现[35, 58, 41]。
一、概述文章方法
文章方法在Mask R-CNN的FPN骨架之上添加了语义分割分支,如下图1所示。

其中FPN框架保持原样以适应原先的实例分割任务,文章称该网络为Panoptic FPN。文章对语义分割分支有很多设计方案,然而文章方法对各个设计方案具有良好鲁棒性。文章的实例分割分支与原先的Mask R-CNN相同,在语义分割性能上堪比最近的性能优良的基于空洞卷积的DeepLabV3+[12]。通过合适的方法对单一FPN训练,可以达到单独训练两个FPN执行两个任务的精度,而计算量却减半。下图2是Panoptic FPN的效果示例。

文章方法具有记忆和计算效率,并且结构简单,对于骨架网络的选择也很灵活(如可选择ResNetX[53]),训练和推理速度很快。
二、相关工作
全景分割:
全景分割挑战在COCO和Mapillary Recognition Challenge都有出现,然而目前的框架都是将实例分割和语义分割独立开来执行,文章提出一种能同时执行以上任务的统一网络。
实例分割:
基于区域的目标检测网络如Slow/Fast/Faster/Mask R-CNN][21, 20, 46, 23]取得了有效成果,COCO检测挑战的2017和2018冠军都是使用了基于FPN的Mask R-CNN;除了基于区域的方法,还有方法是先进行语义分割,再将实例抽取聚集起来,这种方法前景广阔,然而它需要多个独立网路(如[30, 1, 36]使用独立网络分别预测实例边界、包围框和实例断点);另一种方法是使用全卷积方法预测位置敏感实例标签[33]以编码实例信息,[44, 9]基于此方法。然而基于区域的方法仍然占主要,因此文章基于该方法扩展网络。
语义分割:
语义分割的基线是FCN[39],为了提升分辨率从而提升分割效果,大多使用空洞卷积[55]方法。虽然有效,但是具有高计算量和存储,限制了可以使用的骨架网络。为了保证文章网络的灵活性并且为了与Mask R-CNN在计算量和存储上匹敌,文章没有使用空洞卷积。
作为空洞卷积的一种替代方案,一个编解码结构[2]或者U-Net[47]结构被提出以增加特征分辨率,编解码结构使用一个反馈结构将高级和低级特征融合并上采样,最终生成高分辨率的语义特征。如图5所示。
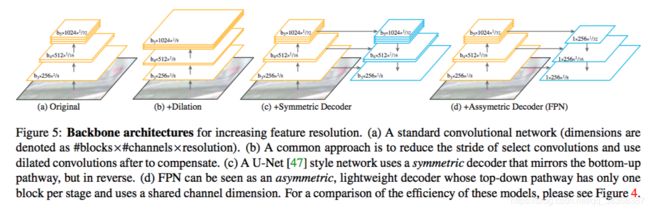
虽然目前占主导的方法是空洞卷积,编解码结构也被经常用与语义分割[47, 2, 19]。文章使用了简单编解码结构的FPN,它与传统对称编解码结构不同,FPN可用于实例分割,它是Mask R-CNN的默认骨架网络。文章后续证明了不需要对FPN做任何改进,它能很好地适用于语义分割。
多任务学习:
文章方法与多任务学习相关,通常使用单一网络执行多个任务会降低每个任务的性能[31],然而很多策略[28,40]可用于减轻这个现象。对于相关的任务,多任务学习可能会导致二者相互增益,如Mask R-CNN中的mask分支受益于box和class分支。文章研究了材料(stuff)和事物(thing)分割的多任务带来的相互增益。
三、Panoptic FPN
文章提出的Panoptic FPN是一个简单的单网络基线,用于同时执行实例分割、语义分割以及统一性的任务-全景分割。文章在Mask R-CNN on FPN的基础上作微小改进来执行语义分割,如图1所示。
3.1模型结构
FPN:
FPN的结构见图1a,FPN产生一个金字塔特征,尺寸为原图的1/4到1/32,每一个金字塔层级都具有相同的channel数(256默认)。
实例分割分支:
Faster R-CNN在不同金字塔层级上执行ROI pooling并为每个实例预测边界框和类别,文章使用Mask R-CNN执行实例分割,它是在Fater R-CNN基础上使用FPN做骨架,为每个实例生成二值掩模。如图1b。
全景FPN:
为了实现精准预测,用于该任务的特征应该满足:(a)为了捕捉精细结构,应该具有合适的高分辨;(b)具有足够丰富的语义信息来精准预测类别标签;(c)捕捉多范围信息来在多分辨率特征中预测材料区域。而FPN生成的额特征恰好满足要求。
语义分割分支:
文章提出了一种结构,它将FPN生成的金字塔所有层级的特征合并到一起生成一个输出,图3给出了详细示例。

从FPN最深层级开始,执行三次上采样,使其变为原尺寸的1/4,每次上采样过程包括一次3x3卷积、group norm[52]、ReLU激活函数和两倍的双线性上采样。对于FPN的其他几个层级也采取相似的上采样,使他们都变为原图的1/4尺寸,并且具有相同的channel(128)。将它们在element-wise上一对一相加,并使用一个1x1卷积和四倍上采样和softmax以在原图尺寸上产生像素级的标签,其中包括thing和stuff类标签。
实施细节:
文章使用了Mask R-CNN中的FPN生成的每个层级的特征都是256channel,通过语义分割分支后将其降低为128channel,对于FPN,使用ResNet/ResNetX结构,它们的权重是在ImageNet上使用批标准化[27]预训练过的。在微调中,文章用固定的通道仿射变换代替BN,这是典型的[24]。
3.2推测和训练
全景推测:
全景分割要求的输出是,每个像素都有类别(或void)标签和实例id(stuff类无实例id)。由于panoptic FPN输出的实例分割图和语义分割图可能会重合,使用[29]中提出的简单后处理解决重叠问题。这个后处理在想法上类似非极大值抑制,后处理执行步骤:(1)根据置信得分解决不同实例间的重叠(2)基于实例分割结果解决实例和语义输出间的重叠(3)移除任何被标记为‘other‘的stuff区域,也移除低于区域阈值的区域。
联合训练:
在训练实例分割时,有三个loss:Lc (classification loss), Lb (bounding-box loss), and Lm (mask loss),实例分割的总loss是以上三者加和。Lc和Lb基于采样ROI的数量进行平均,Lm基于前景ROI数目进行平均。语义分割loss为Ls,通过计算每个像素的预测标签和GT标签指之间的交叉熵损失得到,是基于具有标签的图像像素数目进行平均的。
可以看到两个分支的loss计算使用不同的平均policy和规模,简答加和两部分loss会降低任何一个任务的性能,解决办法是:在实例分割和语义分割两部分loss间使用一个simple loss re-weighting。最终loss如下:
L = λi(Lc +Lb +Lm)+λsLs
通过调节两个λ可以实现训练一个网络,达到匹敌两个独立任务网络性能但是却具有大约半计算量的效果。
3.3分析
这部分解释了为什么基于FPN做语义分割。原因:(1)为了与执行实例分割的Mask R-CNN网络和和睦相处(2)为了减小计算量和存储,提高效率,FPN的大小小于8倍的空洞卷积,然而其效果却能与16倍空洞卷积匹敌,并且比传统的编码解码结构高效两倍。对比如图4所示。

四、实验
语义FPN效果

从表1(a)可以看到,使用文章方法,在语义分割效果上能接近最好模型,然而文章方法计算量更少,占用存储更小。表1(b)给出了其在COCO上的表现。表1(c)(d)分别从语义分割分支中间输出特征深度和各级特征融合方式上进行了对比实验,可看出文章框架对语义分割分支的不同设计具有较好鲁棒性。
多任务训练
普遍的,多任务训练会降低单任务的表现,文章在训练时也出现了该情况。为此,文章使用对实例分割和语义分割两部分的loss进行了平衡,下表2给出示例。
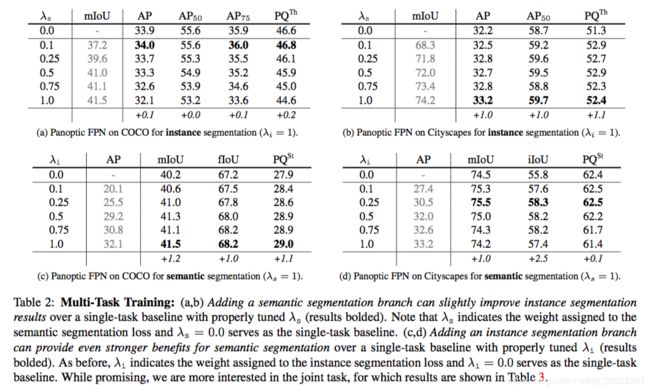
由上表可见适当的选择λs和λi可以有效的提升另一个任务的性能。关于全景分割性能如下表3所示。

由上表(a)看出,文章的使用单一网络执行全景分割与使用两个网络分别执行语义分割和实例分割相比,文章的方法计算量减半,但效果可与后者匹敌。由上表(b)看出,文章使用ResNet101-FPN(其计算量大约与ResNet50-FPNx2的计算量相同),其效果有效超过ResNet50-FPNx2。
效果展示
下图6给出了一些效果。

下表给出了文章方法ResNet101 panoptic FPN和最佳模型的对比,可以看到PQ性能提升巨大。

五、总结
文章为全景分割引入了一个概念上简单而有效的基线。该方法从带有FPN的Mask R-CNN开始,并为其添加了用于密集像素预测的轻量级语义分割分支。文章希望它可以作为未来研究的坚实基础。
六、参考论文
[1] A. Arnab and P. H. Torr. Pixelwise instance segmentation with a dynamically instantiated network. In CVPR, 2017. 1, 3, 8
[2] V. Badrinarayanan, A. Kendall, and R. Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv:1511.00561, 2015. 3
[3] S. Bell, C. Lawrence Zitnick, K. Bala, and R. Girshick. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, 2016. 3
[4] P. Bilinski and V. Prisacariu. COCO-Stuff 2017 Challenge: Oxford Active Vision Lab team. 2017. 6
[5] S. R. Bulo`, L. Porzi, and P. Kontschieder. In-place acti- vated batchnorm for memory-optimized training of DNNs. In CVPR, 2018. 3, 5, 6
[6] H. Caesar, J. Uijlings, and V. Ferrari. COCO-Stuff: Thing and stuff classes in context. In CVPR, 2018. 2, 5
[7] Z. Cai and N. Vasconcelos. Cascade R-CNN: Delving into high quality object detection. In CVPR, 2018. 3
[8] J. Cao, Y. Pang, and X. Li. Triply supervised decoder net- works for joint detection and segmentation. arXiv preprint arXiv:1809.09299, 2018. 3
[9] L.-C. Chen, A. Hermans, G. Papandreou, F. Schroff, P. Wang, and H. Adam. MaskLab: Instance segmentation by refining object detection with semantic and direction fea- tures. In CVPR, 2018. 1, 3
[10] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully con- nected crfs. arXiv:1606.00915, 2016. 1, 3, 6
[11] L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam. Re- thinking atrous convolution for semantic image segmenta- tion. arXiv:1706.05587, 2017. 6
[12] L.-C.Chen,Y.Zhu,G.Papandreou,F.Schroff,andH.Adam. Encoder-decoder with atrous separable convolution for se- mantic image segmentation. In ECCV, 2018. 2, 3, 6
[13] J.-T. Chien and H.-T. Chen. COCO-Stuff 2017 Challenge: Vllab team. 2017. 6
[14] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, 2016. 1, 2, 5
[15] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei. Deformable convolutional networks. In ICCV, 2017. 3
[16] N. Dvornik, K. Shmelkov, J. Mairal, and C. Schmid.
BlitzNet: A real-time deep network for scene understanding.
In ICCV, 2017. 3
[17] M. Everingham, S. A. Eslami, L. Van Gool, C. K. Williams,
J. Winn, and A. Zisserman. The PASCAL visual object
classes challenge: A retrospective. IJCV, 2015. 1, 5
[18] A. Fathi and K. Murphy. COCO-Stuff 2017 Challenge: G-
RMI team. 2017. 6
[19] G. Ghiasi and C. C. Fowlkes. Laplacian pyramid reconstruc-
tion and refinement for semantic segmentation. In ECCV,
2016. 3
[20] R. Girshick. Fast R-CNN. In ICCV, 2015. 3
[21] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich fea- ture hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014. 3
[22] R. Girshick, I. Radosavovic, G. Gkioxari, P. Dolla ́r, and K. He. Detectron. https://github.com/ facebookresearch/detectron, 2018. 2, 5
[23] K. He, G. Gkioxari, P. Dolla ́r, and R. Girshick. Mask R- CNN. In ICCV, 2017. 1, 2, 3, 4, 5
[24] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. 3, 4
[25] S. Honari, J. Yosinski, P. Vincent, and C. Pal. Recombinator networks: Learning coarse-to-fine feature aggregation. In CVPR, 2016. 3
[26] J. Hu, L. Shen, and G. Sun. Squeeze-and-excitation net- works. In CVPR, 2018. 6
[27] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015. 4
[28] A.Kendall,Y.Gal,andR.Cipolla.Multi-tasklearningusing uncertainty to weigh losses for scene geometry and seman- tics. In CVPR, 2018. 3, 6
[29] A. Kirillov, K. He, R. Girshick, C. Rother, and P. Dolla ́r. Panoptic segmentation. arXiv:1801.00868, 2017. 1, 2, 3, 4, 5, 8
[30] A. Kirillov, E. Levinkov, B. Andres, B. Savchynskyy, and C. Rother. InstanceCut: from edges to instances with multi- cut. In CVPR, 2017. 3
[31] I. Kokkinos. UberNet: Training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory. In CVPR, 2017. 3, 6
[32] J. Li, A. Raventos, A. Bhargava, T. Tagawa, and A. Gaidon. Learning to fuse things and stuff. arXiv:1812.01192, 2018. 2
[33] Y. Li, H. Qi, J. Dai, X. Ji, and Y. Wei. Fully convolutional instance-aware semantic segmentation. In CVPR, 2017. 3
[34] T.-Y.Lin,P.Dolla ́r,R.Girshick,K.He,B.Hariharan,and S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017. 1, 2, 3
[35] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ra- manan, P. Dolla ́r, and C. L. Zitnick. Microsoft COCO: Com- mon objects in context. In ECCV, 2014. 1, 2, 3, 5
[36] S. Liu, J. Jia, S. Fidler, and R. Urtasun. SGN: Sequen- tial grouping networks for instance segmentation. In CVPR, 2017. 3
[37] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia. Path aggregation network for instance segmentation. In CVPR, 2018. 3
[38] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y.
Fu, and A. C. Berg. SSD: Single shot multibox detector. In
ECCV, 2016. 5, 6
[39] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional
networks for semantic segmentation. In CVPR, 2015. 1, 3
[40] I. Misra, A. Shrivastava, A. Gupta, and M. Hebert. Cross-
stitch networks for multi-task learning. In CVPR, 2016. 3
[41] G. Neuhold, T. Ollmann, S. Rota Bulo`, and P. Kontschieder. The mapillary vistas dataset for semantic understanding of
street scenes. In CVPR, 2017. 1, 2, 3
[42] A. Newell, K. Yang, and J. Deng. Stacked hourglass net- works for human pose estimation. In ECCV, 2016. 3
[43] C. Peng, T. Xiao, Z. Li, Y. Jiang, X. Zhang, K. Jia, G. Yu, and J. Sun. Megdet: A large mini-batch object detector. In CVPR, 2018. 3
[44] V.-Q. Pham, S. Ito, and T. Kozakaya. BiSeg: Simultaneous instance segmentation and semantic segmentation with fully convolutional networks. In BMVC, 2017. 1, 3
[45] P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Dolla ́r. Learn- ing to refine object segments. In ECCV, 2016. 3
[46] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: To- wards real-time object detection with region proposal net- works. In NIPS, 2015. 3
[47] O. Ronneberger, P. Fischer, and T. Brox. U-Net: Convolu- tional networks for biomedical image segmentation. In MIC- CAI, 2015. 3, 5
[48] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015. 4
[49] J. Tighe, M. Niethammer, and S. Lazebnik. Scene pars- ing with object instances and occlusion ordering. In CVPR, 2014. 2
[50] Z. Tu, X. Chen, A. L. Yuille, and S.-C. Zhu. Image parsing: Unifying segmentation, detection, and recognition. IJCV, 2005. 2
[51] X.Wang,R.Girshick,A.Gupta,andK.He.Non-localneural networks. In CVPR, 2018. 6
[52] Y. Wu and K. He. Group normalization. In ECCV, 2018. 4
[53] S. Xie, R. Girshick, P. Dolla ́r, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In CVPR,
2017. 2, 4
[54] J. Yao, S. Fidler, and R. Urtasun. Describing the scene as
a whole: Joint object detection, scene classification and se-
mantic segmentation. In CVPR, 2012. 2
[55] F. Yu and V. Koltun. Multi-scale context aggregation by di-
lated convolutions. In ICLR, 2016. 1, 3
[56] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid scene
parsing network. In CVPR, 2017. 3
[57] H. Zhao, Y. Zhang, S. Liu, J. Shi, C. C. Loy, D. Lin, and
J. Jia. PSANet: Point-wise spatial attention network for
scene parsing. In ECCV, 2018. 3, 6
[58] B.Zhou,H.Zhao,X.Puig,S.Fidler,A.Barriuso,andA.Tor-
ralba. Scene parsing through ADE20K dataset. In CVPR, 2017. 1, 3