C# 学习笔记:散列与哈希
哈希表
我们在C#中,除了数据结构的顺序表链表栈队列之外,还有一个比较重要的就是哈希表,也就是数据结构中的散列表。
散列表:建立一个确定的对应关系H,使得每个关键码key都和它唯一的存贮位置H(key)相对应。
- 存储记录时,通过散列函数计算记录的散列地址,并用该地址存储记录。
- 查找记录时,通过同样的散列函数计算记录的散列地址,并访问该记录。
在C#的哈希表(HashTable)是根据关键码/值进行直接访问的数据结构,它通过吧关键码/值映射到一个表中来访问记录。这个表就是我们的哈希表。
它的具体用法在C#中非常简单:
创建哈希表并放入元素:
Hashtable hash = new Hashtable();
hash.Add(3, "骑马与砍杀");
hash.Add(1, "彩虹六号");
hash.Add(2, "赛博朋克");在哈希表中,前面的值为关键码(Key)后面的为元素(Value)。
C#哈希表可以自定义键值的原因:
在散列表中,一个值存入散列表是要根据散列函数来确定存放的索引位置的,但是在C#中,由于有了System.Object里的GetHashCode方法,它默认返回一个唯一的证书,并且在对象的生命周期中保持不变。所以在C#的哈希表中,Key和Value都是可以自定义的。
在散列表中,最重要的是如何处理冲突,由于两个关键码算出来的结果可能是同一个地址,所以散列表中解决冲突的方法非常重要。
散列表解决冲突的方式:
线性探测法:从冲突的下一个位置起,依次寻找空的散列地址。
即对于键值key,存放在表长为m的散列表中,有:
H=(H(key)+d)%m d=(1,2,3,.....m-1)
其中,d表示查找到下一次地址的次数,如果查找到的位置已经有人了,d=d+1然后带入公式计算。
二次探测法:二次探测法与线性的区别在于d。
H=(H(key)+d)%m d=(
、
、
、
......
、
)(q小于等于根号m)
C#的HashTable解决冲突的方式 :
在C#的哈希表中解决冲突的方式称为二度哈希(rehashing)
在C#中,有一个包含一组哈希函数H1~~Hn的集合,当需要从哈希表中添加或获取元素时,先使用哈希函数H1,如果冲突,则使用哈希函数H2,以此类推,直到Hn。
散列表的性能:
在散列表中,产生的冲突越多,查找效率就越低。
影响冲突产生的概率有三个
- 散列表存放是否均匀,它直接影响冲突产生的效率
- 处理冲突的办法,线性探测的方式很有可能产生堆积(即延后了多个地址仍有冲突的情况)
- 散列表的装填因子α,有公式 α=key的个数/表的长度。装填因子表示散列表装满的程度。散列表的平均查找长度即为装填因子的函数。不同的冲突解决方法的装填因子α的函数不同。
哈希表的性能:
与散列表对应的是,在HashTable中也有一个私有成员loadFactor,即为散列表中的装填因子,哈希表的构造函数是允许用于指定装填因子的值的,定义的范围在0.1~1.0之间。但实际上无论我们指定它为多少,装填因子的不会超过0.72。
微软官方认为,装填因子的最佳值就是0.72,这个值正好平衡了速度与空间。
但是我们在构建哈希表的时候,需要检查以保证元素与空间的比例不会超过最大比例,如果超过了,哈希表的空间将被扩充,扩充的步骤如下:
- HashTable的位置空间增加。
- HashTable中保存的所有值都需要重新二度哈希(rehashing)。由于HashTable的位置空间增加了,在二度哈希时,HashTable类的实例所有元素值依赖于HashTable类实例的位置空间值。造成性能损耗。
所以,在构建哈希表时,应该预先估计HashTable中最有可能容纳的数据量,然后指定合适的哈希表长度,避免不必要的扩充。
C#哈希表的操作:
HashTable中各项操作都非常简单
| Add(object key, object item) | 向哈希表中添加一个元素 |
|---|---|
| Clear() | 清空哈希表 |
| Remove(object key) | 删除哈希表中的指定元素 |
| Contains(object key) | 查找哈希表某个特定的值,返回bool类型参数 |
| ContainValue(object value) | 查找哈希表某个特定的键,返回bool类型的参数 |
哈希表的遍历
哈希表的遍历使用foreach迭代器来完成,不过foreach创建的类型必须是DictionaryEntry才能访问到哈希表的内部
例如:
static void Main()
{
Hashtable hash = new Hashtable();
hash.Add(3, "骑马与砍杀");
hash.Add(2, "彩虹六号");
hash.Add(1, "赛博朋克");
foreach(DictionaryEntry dic in hash)
{
Console.WriteLine("当前的键是" + dic.Key + "当前的值是" + dic.Value); ;
}
}
输出的结果是 :
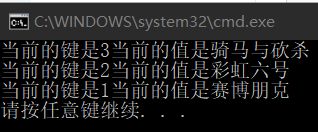
但是哈希表中是没有排序的,如果需要排序输出,则需要借助ArrayList来存储。
static void Main()
{
Hashtable hash = new Hashtable();
hash.Add(3, "骑马与砍杀");
hash.Add(1, "彩虹六号");
hash.Add(2, "赛博朋克");
ArrayList sort = new ArrayList(hash.Keys);
sort.Sort();
foreach (int key in sort)
{
Console.WriteLine(hash[key]);
}
}输出为:
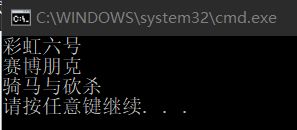
但是要注意到的是,我们在Hash表中放入的元素是无所谓类型的,这是由于哈希表中的元素都是Object类型的原因,所以我们可以指定任意类型的Key或Item给哈希表,所以,哈希表不是类型安全的。如果要使用类型安全的哈希表,在C#中我们可以使用Dictionary来代替哈希表的功能。
字典Dictionary
与哈希表不同的是,字典是泛型的,这表明它是强类型的数据结构。
Dictionary dic = new Dictionary(); 字典的冲突解决策略:
字典的冲突解决策略在数据结构称为拉链法,也叫桶列表。在哈希表中,一个地址只能存放一个元素。但是在字典中一个地址即为一个链表,当发生冲突时,算得同一个位置的元素将被放入该位置的同一个链表中。
对于链表的查询来说,它的时间复杂度为:O(1)。
但是,字典相较于哈希表要消耗更多空间,当有了一个字典以后,并非直接实现索引,而是通过创建额外的两个数组来实现间接索引。所以即便创建的是空字典,也会伴随而来两个数组,所以当处理的数据不多时,最好慎用字典。
字典的例子
字典在遍历的时候,可以用泛型的KeyValuePair
static void Main()
{
Dictionary dic = new Dictionary();
dic.Add(2, "彩虹六号");
dic.Add(3, "骑马与砍杀");
dic.Add(1, "神界原罪");
foreach (KeyValuePair str in dic)
{
Console.WriteLine(str);
}
} 输出的结果为:
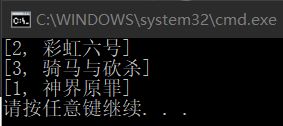
当然,由于字典是强类型的,所以字典的访问和遍历的方式也很多:
根据Keys或Values数组遍历:
foreach (int key in dic.Keys)
{
Console.WriteLine(key.ToString());
}
foreach (string value in dic.Values)
{
Console.WriteLine(value.ToString());
}或者把字典key转换成ArrayList表再遍历:
ArrayList list = new ArrayList(dic.Keys);
for (int i = 0; i < list.Count; i++)
{
Console.WriteLine(dic[(int)list[i]]);
}字典的许多操作都是和哈希表一致的,包括add、remove、Contains等等方法的使用逻辑都是一样的。没有太多区别。
那么,哈希表和字典的区别在哪里呢:
哈希表与字典
共同点:
都是通过键值来查询一个元素,在查询时元素可以重复,但是键值不能重复。
不同点:
1.从数据结构上来讲,
- 字典所使用的为顺序存储,它解决冲突的方式为拉链法。即一个地址存储一个链表,链表中存储哈希函数H(key)相等的值。
- 哈希表通过散列算法,是无序存储的,它解决冲突的方式是二度哈希。即通关不同的哈希函数使每个元素的位置各不相同。
2.从元素类型来讲:
- 字典是泛型的存储,存储的元素不需要进行类型转换。
- 哈希表存储的元素为Object类型,在存取时需要类型转换。
3.从多线程上来讲:
- 单线程程序中推荐使用 Dictionary, 有泛型优势, 且读取速度较快, 容量利用更充分.
- 多线程程序中推荐使用 Hashtable, 默认的 Hashtable 允许单线程写入, 多线程读取, 对 Hashtable 进一步调用 Synchronized()方法可以获得完全线程安全的类型. 而Dictionary 非线程安全, 必须人为使用 lock 语句进行保护, 效率大减.
4.从性能效率上来讲:
- 当键值为值类型(比如int)时字典效率更高(不需要装箱拆箱)。
- 当键值为引用类型(比如string)时哈希表效率更高。