MySQL-底层数据结构及优化
数据结构可视化网站:https://www.cs.usfca.edu/~galles/visualization/BST.html
注:该文章下的所有数据结构图片来源该网站;
注:在mysql中,数据表是通过文件形式存储在本地磁盘中的,遍历一次数据结构被成为一次磁盘I/O(I/O指:input / output)
二叉树的原则:父节点的右边总是大于等于父节点,左边总是小于父节点;
目录
一、数据结构
· 1、数据结构分析之Binary Search Tree;
2、数据结构之红黑树(Red/Black Tree)
3、数据结构之B树(B-Trees)
4、数据结构之B+树(B+ Trees)
二、mysql采用的数据结构以及为什么采用?
1、mysql采用数据何数据结构做索引?
2、为什么mysql采用B+树作为索引的数据结构?
三、存储引擎的数据结构总结
四、B+树高度为3的时候能存储多少数据?
一、数据结构
· 1、数据结构分析之Binary Search Tree;

图1:Binary Search Tree 递增插入;
图中可见,插入123456,如果插入的数据是连续的,那么每次在做递增的时候,都会遍历每个数据,从而把数据插入到尾部。
查询数据的时候,也需要小于查询值之前得所有节点;如果mysql底层采用了二叉树作为索引存储结构,那么肯定是存在查询慢,且非常消耗性能的;
那么问题来了,如果插入的数据不是连续的会出现什么情况;

图2:Binary Search Tree 非递增插入;
如图可见,插入数字为2、4、6、1、3、5, 此时并没有进行排序操作,而是产生了分裂,且顺序是无序的,此时如果我需要查询6,那么只需要做一次做三次节点遍历就可以;很显然,如果在使用二叉树且数据连续的情况下,插入和查询的速度是非常慢且耗费性能的,如果是一棵产生了分裂的二叉树显然在插入和查询的效率上是要高于递增的;此时我暴露出了一个疑问,mysql现在推荐用户使用递增的主键,这样是不是很不合理?是的,很不合理,因为mysql并没有采用Binary Search Tree(二叉树)。
2、数据结构之红黑树(Red/Black Tree)
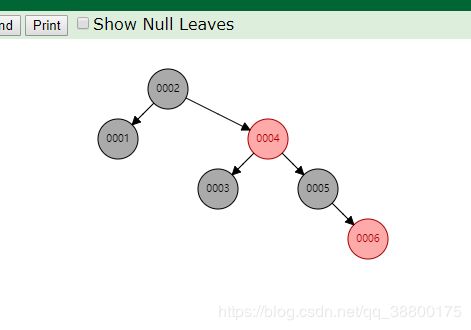
图3:红黑树 顺序插入
插入:数据1、2、3、4、5、6;该数据结构是一棵完全平衡的二叉树;在和图1做对比的时候,图3顺序插入都产生了分裂,且插入的时候只需要做对比父节点做比较,如果大于了父节点,则比较父节点下一个子节点的右边,左边不理会,直到找到合适的位置,严格遵循了二叉树的原则;
查询:查询时,首先从顶层进行比较,如果顶层节点的数据大于则走右边节点,如果小于则走左边;此时又暴露出一个问题,如图3所示,图中没有0,如果查询0会存在什么情况;

图4:查询二叉树中不存在的数据
查询二叉树不存在数据时,依然会遵循比较大小原则,如果没有,就没有呗!!!

图5:红黑树插入非连续的数据
插入:插入2、4、6、1、3、5非连续数据,如图5所示,本质上和图3无太大的却别,由此可见,红黑树是完全平衡的二叉树,
查询:查询数据的时候和插入完全相似,遵循二叉树原则
3、数据结构之B树(B-Trees)

图6:B树 插入
插入:插入1、2、3、4、5、6、7或者(2、4、6、1、3、5、7)都是图6所示。在插入的时候,我选择了节点数量为4的时候产生分裂。由图可见,父节点和总数保存了分裂叶子节点的中间数,左边小于父节点,右边总是大于等于叶子节点,而父节点指向子节点的指针位置却在空白位置,这样保存的好处是当查询一个数据的时候,先比较查找的数据与父节点的数据大小,如果在2-4之间,就直接得到2-4之间指向的叶子节点,从而得到叶子节点,如果叶子节点内有多个数据,则比较叶子节点的数据即可。
4、数据结构之B+树(B+ Trees)

图7 B+树 插入
插入:插入数据1、2、3、4、5、6、7(或者2、4、6、1、3、5、7)均如图7所示
插入时候类似于B树的插入,不过还是存在不同的地方。叶子节点保存了父节点所有的数据,并且每个叶子节点右侧存在一个指针指向下一个叶子节点,最开始我有两个问题我想不明白,为什么B+树叶子节点会存储所有的数据切每个叶子节点之间是有指针相互连接的,该问题留到后续解答。
查询:查询7的时候,只做了两次的节点遍历得到了结果7。
二、mysql采用的数据结构以及为什么采用?
1、mysql采用数据何数据结构做索引?
答:mysql采用了B+树作为存储引擎的索引。
2、为什么mysql采用B+树作为索引的数据结构?
答:
a、如果mysql采用了二叉树作为存储引擎会出现什么样的情况,都知道mysql的主键是可以做递增的,二叉树中递增的树,会一直增加树的高度,从顶层获取会经过无数次的磁盘I/O才能将数据插入到最后的节点,如图

图8:二叉树插入和读取
b、红黑树类似于普通的二叉树、深度也会增加,不利于读写、一次磁盘I/O的效率很低。
c、B树在二叉树上做了哪些改进?首先二叉树读取子节点称为磁盘I/O,要减少mysql的磁盘I/O如何去控制,那么是不是在二叉树节点上做横向扩展,得到B树,减少了树的高度增加了效率。 那么B树作为存储引擎的数据结构会有哪些弊端呢,眨眼一看没什么问题,但是如果使用sql语句例如:select * from a where a > 1的时候,会出现如图的情况:

图9:B树执行范围sql
在图中可以看出B树执行范围查询的时候,会执行3次磁盘I/O才能查询7个数,如果数据是上千万的量,将会执行多少次?
d、B+数作为mysql存储引擎的数据结构会出现什么情况,如图:

图10 B+树进行范围查询
有图10可见,范围查询只做了一次磁盘I/O即可获取到大于1的所有范围,效率胜过B树,为什么只做了一次的磁盘I/O? 因为每个叶子节点的右侧有一个指针指向下一个叶子节点,不需要再像B树,因为完整的数据全存储在叶子节点。
三、存储引擎的数据结构总结
综上所述,B+树是最适合做mysql的索引的数据结构,无论是从查询还是插入都是最快的。
四、B+树高度为3的时候能存储多少数据?
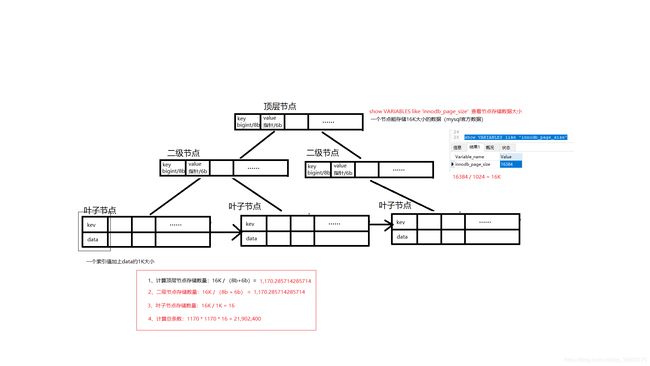
如图中,3层B+树能存储2千万条数据