【机器学习之分类篇】一文读懂机器学习分类模型——分类模型构建与性能评价(基于分类MNIST数据集中的数据进行代码演示)
前言
本文章,主要是利用传统的机器学习方法构建传统分类器,进行分类任务,虽然目前利用神经网络的方法相较于传统机器学习效果更加优秀,但这里主要是为了介绍机器学习中分类任务构建的流程方法,是我本人学习分类任务过程中的一点总结。
在这里,将基于MNIST数据集进行分类任务,构建二元分类器、多元分类器(多标签分类、多输出分类),并对我们训练的分类器进行性能考核,考核方法包括:交叉验证测量精度、混淆矩阵、精度/召回率曲线、ROC曲线。同时,多模型进行错误分析,并利用网格搜索选择最佳的模型参数。
编译环境:个人喜好推荐jupyter notebook
机器学习中分类器的划分:
| 类别 | 该类别下典型的分类器 |
|---|---|
| 二元分类器 | SVM分类器、线性分类器等 |
| 多类别分类器 | 随机森林分类器、朴素贝叶斯分类器等 |
多个二元分类器也可以实现多类别分类。
目录:
1、MNIST数据集介绍
2、训练一个二元分类器
3、性能考核
3.1、使用交叉验证测量精度
3.2、混淆矩阵
3.3、精度和召回率的权衡
3.4、ROC曲线
**4、多类别分类器
5、错误分析
一、MNIST数据集介绍
MNIST数据集,一组包括70000个0~9的手写数字图片,相当于机器学习领域中的“Hello World”。
1、数据集的获取
Scikit-Learn提供了许多助手功能来进行数据集的下载。数据集的获取代码如下:
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original',data_home=r'C:\datasets')
mnist
data_home 为获取数据保存到本地的路径,获取数据的结果如下:

查看数据集的shape
#看数据集的大小形状 数据共有70000张,每张图片有28x28=784个特征,因为图片是28x28像素
X,y=mnist['data'],mnist['target']
print('数据集的形状:',X.shape)
print('标签大小:',y.shape)
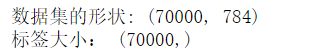
2、数据展示
挑选MNIST数据集中一张图片,进行可视化查看
#随机的抓取一张,来看一下
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
some_digit = X[35000]
#因为data中每个图片都是将28x28的像素平铺成一个数组,要还原所以需要reshape一下
some_digit_image = some_digit.reshape(28,28)
plt.imshow(some_digit_image,cmap=matplotlib.cm.binary,interpolation='nearest')
plt.axis('off')
plt.show()
print('该图片的标签为:',y[36000])

3、创建测试集
在进行分类任务之前,我们可先对数据集进行处理,即对整个数据集进行训练集和测试集的划分,训练集主要用于模型的训练阶段,而测试集主要是用来对训练出来的模型进行测试,看模型训练的程度如何,方便我们对模型进行下一步的优化调整。
事实上,该数据集已经分成训练集(前60000张图像)和测试集(后10000张图像)。
X_train,X_test,y_train,y_test = X[:60000],X[60000:],y[:60000],y[60000:]
4、训练集数据洗牌
训练集数据重新洗牌(保证交叉验证时每一折数据的随机性,同时也减少连续的数据对模型的干扰)
import numpy as np
#np.random.permutation 随机排序
shuffle_index = np.random.permutation(60000)
X_train,y_train = X_train[shuffle_index],y_train[shuffle_index]
二、训练一个二元分类器
为了简化问题,先只识别一个数字——比如数字5。即构建一个数字5的二元分类器,该分类器只能区分两个类别:5或非5。其余数字的分类器构建方法也如此。
选用随机梯度下降(SGD)分类器,该分类器的优势是可以有效处理大型数据集。
1、数字5的二元分类器
SGDclassifier在训练时完全是随机的,如果你想得到可以复现的结果,需要设置随机种子random_state。
#创建目标向量
y_train_5 = (y_train == 5)
y_test_5 = (y_test == 5)
#其实就是一个数字5的检测器(看检测出数据5的准确性)
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train,y_train_5)
分类器模型sgd_clf:
2、分类器验证
可以用它来检测数字5的图像了 该分类器猜测some_digit该图片为5(True)
sgd_clf.predict([some_digit])
模型预测的输出为:
![]()
可以看出,该分类器预测正确。
三、模型的性能考核
评估分类器要比评估回归器困难许多,将介绍4中分类器的评估方法。
3.1 、使用交叉验证测量精度
在Scikit-Learn库中,有专门的函数用来进行K-折交叉验证。采用K-fold进行交叉验证时,是将训练集分解成K个折叠,然后每次留下一个折叠进行预测,剩余的折叠用来训练。
#对SGD分类器进行交叉验证
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf,X_train,y_train_5,cv=3,scoring='accuracy')
在这里CV=3,表示只进行3次交叉验证,每次验证预测的结果保存在一个Array中,结果如下:
![]()
但是scoring=‘accuracy’准确率无法成为分类器的首选性能指标,特别时处理某些偏斜数据集(某些类比其它类更频繁)
3.2、混淆矩阵
混淆矩阵表:
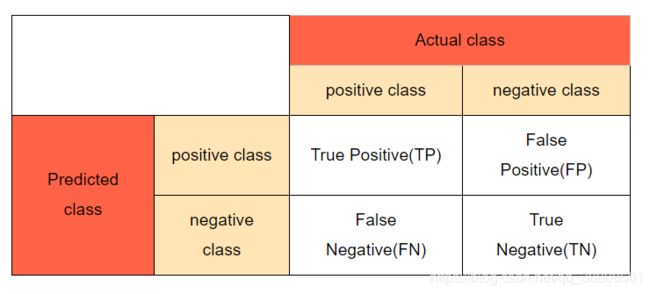

评估分类器更好的办法是利用混淆矩阵,思路:统计A类别实例被分成B类别的次数。
以上述的数字5二元分类器为例,对混淆矩阵进行解释:actual 表示真实情况,predicted 表示当前训练出来的模型的预测情况,剩下的就一目了然了。
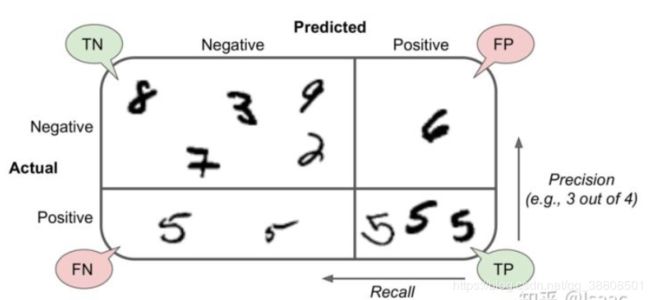
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf,X_train,y_train_5,cv=3)
print('数据为5的预测类别:',y_train_pred)
print(len(y_train_pred))
构建混淆矩阵:confusion_matrix()函数
#建立混淆矩阵 confusion_matrix()函数
#该矩阵的行表示实际类别,列表示预测类别
#本例中 第一行 负类(非5)中有53265张被正确的分为非5类别【真负类TN】 负类(非5)中有1314张被误判为5类别【假正类FP】
# 第二行 正类(为5)中有1293张被误判为非5类别【假负类FN】 正类(为5)中有4128张被正确的分为5类别【真正类TP】
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5,y_train_pred)

该矩阵的行表示实际类别,列表示预测类别。
第一行 负类(非5)中有53265张被正确的分为非5类别【真负类TN】 负类(非5)中有1314张被误判为5类别【假正类FP】
第二行 正类(为5)中有1293张被误判为非5类别【假负类FN】 正类(为5)中有4128张被正确的分为5类别【真正类TP】
3.3、精度、召回率(灵敏度)和F1分数
精度 = TP/(TP+FP) 召回率 = TP/(TP+FN) F1 = 2/(1/精度 + 1/召回率)
召回率:控制有多少的真正实列被检测出来。
精度:控制检测出来的实有多少的准确性。
F1分数 : 由精度和召回率组合成的指标,是精度和召回率的谐波平均值。可用来作为较两种分类器的指标。
from sklearn.metrics import precision_score,recall_score
precision_score(y_train_5,y_train_pred)
![]()
recall_score(y_train_5,y_train_pred)
![]()
由性能指标准确率和召回率可知,当该分类器说一张图片是5时,只有75.8%的准确率,并且也只有76.1%的数字5被该分类器检测出来。
from sklearn.metrics import f1_score
f1_score(y_train_5,y_train_pred)
![]()
在需要使用一个简单的方法来比较两种分类器时,F1分数是一个非常不错的指标。但是三种指标如何选择,要根据你的需要来,在某些情况下,你更关心的时精度,而在另一种情况下,你可能关心的是召回率。
3.4、精度/召回率权衡
增加精度,召回率会降低,精度和召回率不可同时兼得,所以会涉及到权衡的问题。 而阈值权衡,关键在于算法的决策函数计算的阈值是否合适,那么如何决定阈值呢?
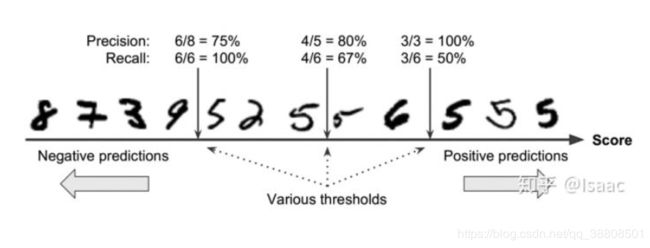
精度和召回率的变化关系,如下图:
阈值的确定方法:
首先使用cross_val_predict()函数获取训练集中所有实例的分数,利用其中的超参数method="decision_function"返回决策分数,有了分数再利用precision_recall_curve()函数来计算所有可能的精度和召回率。
from sklearn.metrics import precision_recall_curve
#y_scores是每个样本的得分,是由超参数method="decision_function"控制的
y_scores = cross_val_predict(sgd_clf,X_train,y_train_5,cv=3,method='decision_function')
precisions,recalls,thresholds = precision_recall_curve(y_train_5,y_scores)
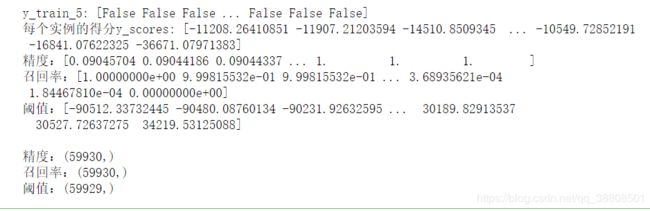
print('y_train_5:',y_train_5)
print('每个实例的得分y_scores:',y_scores)
print('精度:{}\n召回率:{}\n阈值:{}'.format(precisions,recalls,thresholds))
print('\n精度:{}\n召回率:{}\n阈值:{}'.format(precisions.shape,recalls.shape,thresholds.shape))
输出结果如下:
可视化展示:
#用图展示出他们之间的关系 因为shape的原因 所以要[:-1]切片,表示除最后一个外,全取出,前闭后开。
def plot_precision_recall_vs_threshold(precisions,recalls,thresholds):
plt.plot(thresholds,precisions[:-1],'b--',label='Precision')
plt.plot(thresholds,recalls[:-1],'g-',label='Recall')
plt.xlabel('Thresholds')
plt.legend(loc='best')
plt.ylim([0,1])
plot_precision_recall_vs_threshold(precisions,recalls,thresholds)
plt.show()
输出结果:
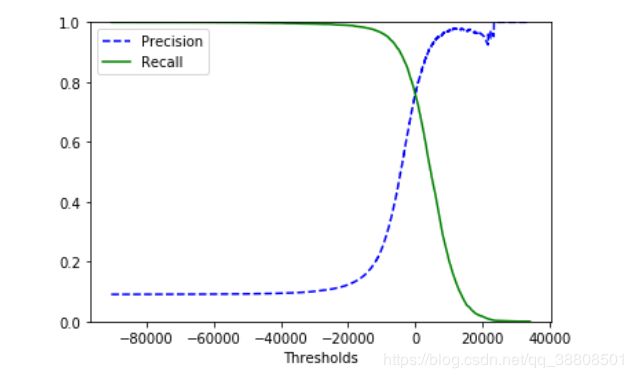
由上图可以看出,精度和召回率与决策阈值的关系。
这个时候,若我们的项目要求只关注精度,如要求检测出来的实列准确度90%以上,我们可以设置阈值threshold=22000,但是此时召回率却是极低的。
threshold=22000
y_train_pre_90 = (y_scores>threshold)
pre_s = precision_score(y_train_5,y_train_pre_90)
rec_s = recall_score(y_train_5,y_train_pre_90)
print('精度:{}\n召回率:{}'.format(pre_s,rec_s))
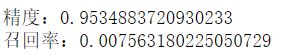
3.5、ROC曲线
常与二元分类器(只有是或非的两种类别的分类器)一起使用,绘制的是真正类率(召回率的另一名称)和假正类率(被错误分成正类的负类比例,等于1-真负类率(特异度))之间的曲线,即绘制的是灵敏度和(1-特异度)的关系。
ROC曲线厝绘制的是灵敏度和(1-特异度)的关系。
from sklearn.metrics import roc_curve
#tpr:真正类率 fpr:假正类率
fpr,tpr,thresholds = roc_curve(y_train_5,y_scores)
print('假正类率:{}\n真正类率:{}\n阈值:{}'.format(fpr,tpr,thresholds))
print('\n假正类率:{}\n真正类率:{}\n阈值:{}'.format(fpr.shape,tpr.shape,thresholds.shape))
#绘图展示
def plot_roc_curve(fpr,tpr,label=None):
plt.plot(fpr,tpr,linewidth = 2,label=label)
plt.plot([0,1],[0,1],'k--')
plt.xlim([0,1])
plt.ylim([0,1])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plot_roc_curve(fpr,tpr)
plt.show()
输出结果:
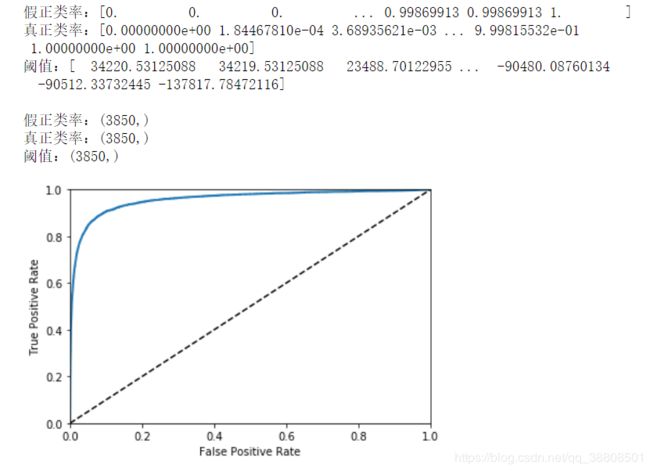
上图中的虚线表示纯随机分类器的ROC曲线,一个好的分类器应该离该线越远越好。
折中权衡:召回率(tpr)越高,假正类(fpr)也就越多
多个分类器的比较: 可用曲线下方面积来比较,也就是ROC AUG函数,完美的分类器的ROC AUG等于1。
该模型的ROC曲线的面积:
#我们该算法sgd_clf的ROC AUG
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_5,y_scores)
![]()
该分类器的ROC_AUG 得分不错是因为相较于非5的负类,正类实列相较于数据集太少。
3.6、不同分类器的ROC曲线
可以根据ROC曲线,对同一数据的多个分类器进行比较,选出最佳的分类器。 例如:训练一个RandomForestClassifier分类器,并与SGDclassifier分类器的ROC曲线和ROC AUG曲线的比较。
#首先获取训练集每个实列的分数 RandomForestClassifier分类器采用的是dict_proba()方法,返回一个数组,每行代表一个实列,每列为一个类别。
#表示某个给定的实例属于某个给定类别的概率
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest=cross_val_predict(forest_clf,X_train,y_train_5,cv=3,method='predict_proba')
print(y_probas_forest)
#对RandomForestClassifier绘制ROC曲线,需要分值数,而不是概率大小。
#解决方法:使用正类的概率作为分值数
#score = proba of positive class
y_scores_forest = y_probas_forest[:,1]
print(y_scores_forest)
fpr_forest,tpr_forest,thresholds_forest = roc_curve(y_train_5,y_scores_forest)
plt.plot(fpr,tpr,'b:',label='SGD')
plot_roc_curve(fpr_forest,tpr_forest,'Random Forest')
plt.legend(loc='best')
plt.show()
可以得出两个分类器的ROC_AUG曲线:
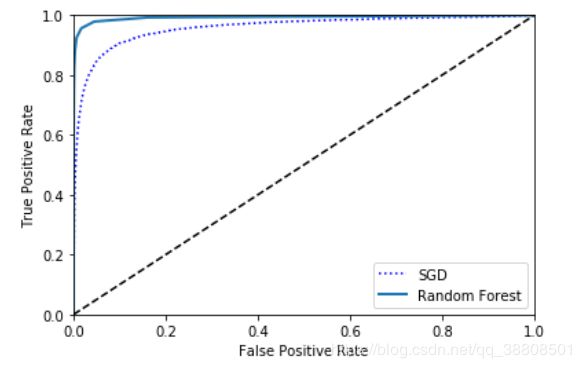
由上图可见Random Forest的性能比SGD好,同时看一下Random Forest分类器的ROC AUG 、精度和召回率的得分。
ROC_AUG = roc_auc_score(y_train_5,y_scores_forest)
print("ROC_AUG:",ROC_AUG)
![]()
forest_clf = RandomForestClassifier(random_state=42)
forest_clf.fit(X_train,y_train_5)
y_train_pred_forest = cross_val_predict(forest_clf,X_train,y_train_5,cv=3)
print('RandomForestClassifier对数据为5的预测类别:',y_train_pred_forest)
print(len(y_train_pred_forest))
precision_s = precision_score(y_train_5,y_train_pred_forest)
recall_s = recall_score(y_train_5,y_train_pred_forest)
print('\n精度:{}\n召回率:{}'.format(precision_s,recall_s))

3.5、性能考核总结
问题:两种性能评价曲线(ROC曲线和精度/召回率(PR曲线))该如何选择?
可以根据经验法则,当正类非常少见或者你更关注假正类而不是假负类,你应该选择PR曲线,反之则是ROC曲线。
四、多类别分类器
多类别分类器:随机森林分类器、朴素贝叶斯分类器。
对大多数二元分类器采用一对多(OvA)策略:对每种类别训练一个分类器,在进行检测时,获取每个分类器的决策分数,哪个分类器的分数高就是哪个类别。
对SVM分类器采用一对一(OvO)策略:为每一对数字训练一个二元分类器,在进行检测时,看哪个类别获胜最多。
4.1、用二元分类器进行多分类
多个二元分类器也可以实现多分类:还是利用SGDClassifier分类器做多分类(一对多策略)。
print('标签的训练集:',y_train)
sgd_clf.fit(X_train,y_train)
sgd_clf.predict([some_digit])
#在内部,实际sklearn训练了10个二元分类器,然后给出图片进行预测时,返回了分数最高的分类器对应的类别
some_digit_scores = sgd_clf.decision_function([some_digit])
print('10个二元分类器sgd_clf,在预测时每个分类器的得分:\n',some_digit_scores)
#选出最大的得分类别,np.argmax()返回沿轴axis最大值的索引.
max_clf_score_index = np.argmax(some_digit_scores)
print('分类器的最大得分的索引:',max_clf_score_index)
#查看分类器的目标类别列表classes_ 参数,并选出最大得分分类器的对应类别
sgd_clf.classes_[max_clf_score_index]
输出结果:

4.2、直接用多类别分类器
训练多分类器:RandomForestClassifier
forest_clf.fit(X_train,y_train)
forest_clf.predict([some_digit])
#看分类器在预测时所属每个类的概率,用prdict_proba()
forest_clf.predict_proba([some_digit])
看分类器在预测时所属每个类的概率,用prdict_proba()。
![]()
4.3、多个分类器的评估(交叉验证)
对随机梯度下降分类器和随机森林分类器进行评估:3折交叉验证
cross_val_score(sgd_clf,X_train,y_train,cv=3,scoring='accuracy')
![]()
cross_val_score(forest_clf,X_train,y_train,cv=3,scoring='accuracy')
![]()
对于随机梯度下降分类器,若对训练集进行简单的特诊缩放StandardScaler,可以在验证集上得到更高的准确率。这通常是我们在对模型训练前,进行数据预处理的一种方法。
#若对训练集进行简单的特诊缩放,可以在验证集上得到更高的准确率
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
#训练集的简单标准特征缩放
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
cross_val_score(sgd_clf,X_train_scaled,y_train,cv=3,scoring='accuracy')
![]()
五、错误分析
当你找到了一个不错的模型,希望对其做进一步的改进,可以用到错误分析。
以同样的方法看一下多分类的混淆矩阵,使用cross_val_predict()函数进行预测,然后调用confusion_matrix()函数。
#以同样的方法看一下多分类的混淆矩阵,使用cross_val_predict()函数进行预测,然后调用confusion_matrix()函数
y_train_pred = cross_val_predict(sgd_clf,X_train_scaled,y_train,cv=3)
conf_mx = confusion_matrix(y_train,y_train_pred)
conf_mx

为了方便,我们查看混淆矩阵的图像表示,用matplotlib中的matshow()函数。
#为了方便,我们查看混淆矩阵的图像表示,用matplotlib中的matshow()函数
plt.matshow(conf_mx,cmap = plt.cm.gray)
plt.show()

上图看到,对角线颜色亮,说明大多数图片都在主对角线上,但数字5的颜色较其他的暗一些,可能是数字5的图片较少,也可能是对5的分类效果不好。
上图的行代表实列类别,列代表预测类别。
将混淆矩阵中的每个值除以相应类别值的数量,从而比较错误率而不是错误的绝对值(后者对样本较多的类别不公平)。
norm_conf_mx = conf_mx/row_sums
print('混淆矩阵的错误率:\n',norm_conf_mx)
#用0填充对角线,只保留错误,画图展示
np.fill_diagonal(norm_conf_mx,0)
plt.matshow(norm_conf_mx,cmap=plt.cm.gray)
plt.show()
输出结果:


上图8、9列比较亮,说明许多图图片被错误的分类为数字8、9,因此我们可以将精力花在改进其他数字与8、9的混淆上。
可以写一个算法计算闭环的数量(8是两个闭环,9是一个闭环),或者对图片进行预处理,让某些模式更加突出。
至此,该分类任务的讲解已经结束了。如有不对,请多指正。