边学边敲边记之爬虫系列(七):分类爬取医疗信息网站图片

一、 前言
今天X先生带大家正真的实战:爬取医疗信息网站的图片及分类存储到本地和存储到MySql数据库。
读完本文,可能需要10到20分钟不等,你可以学到:Xpath语法再详解,实战,翻页、多页面爬取思想,数据存储三种方法:下载到本地、存储到Mysql数据库、存储到本地csv文件,开学前最后一批干货,满满的。
评论区置顶第一期赠书获奖名单(昨天已经在极简交流群里公布过啦!)
二、基本知识回顾
1.Xpath基本使用
1)安装方法
直接推荐方法:豆瓣源安装(其他安装方法自己可百度)
pip install -i https://pypi.douban.com/simple/ lxml2)基础语法及使用学习:
请点击这里仔细学习Xpath
该文章详细介绍了Xpath的基本使用方法,包括常用语法介绍。
2.数据库操作之Pymysql
1)安装方法
直接推荐方法:豆瓣源安装(其他安装方法自己可百度)
pip install -i https://pypi.douban.com/simple/ pymysql2)基本使用介绍
import pymysql
# 数据库连接
conn = pymysql.connect(host = "localhost",port = 3306,user = "你的数据库登录名",
password = "你的数据库登录名",charset="utf8",database = "你的数据库名称")
# 使用cursor()方法获取操作游标
cur = conn.cursor()
# 执行sql语句(可以是增删查改任意操作)
cur.execute(sql)
# 提交会话
conn.commit()
# 关闭数据库连接
三、看代码,边学边敲边记Xpath系统实战训练
1.图解我们要爬取的网站
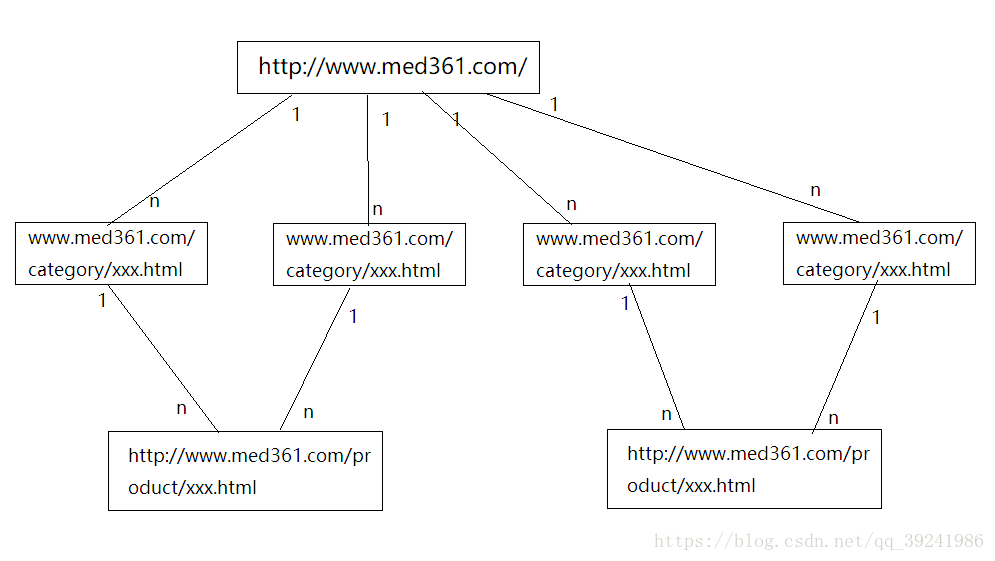
我们爬取的主页面是http://www.med361.com,它的下面有很多医疗商品类别(图中我们用1:n的形式给出),而每一个category(类别)下又有多个product(商品)(图中我们用1:n的形式给出),当然进入详细商品主页面后,还会有很多url,后面爬取时细说。
2.访问主页面,利用Xpath来获取所有商品类别url
(1)基础代码
'''
author : 极简XksA
data : 2018.8.31
goal : 爬取医疗网站图片
'''
import requests
from lxml import etree
def get_respones_data(branch_url):
# requests 发送请求
get_response = requests.get(branch_url)
# 将返回的响应码转换成文本(整个网页)
get_data = get_response.text
# 解析页面
a = etree.HTML(get_data)
return a
# 主页面
mian_url = "http://www.med361.com"
# 发送请求,获取Xpath格式页面
response_01 = get_respones_data(mian_url)
# 不同医疗商品类别url
# 上一页
branch_url_1 = response_01.xpath("/html/body/div[2]/div/div/div/div[1]/ul/li/a/@href")
# 下一页
branch_url_2 = response_01.xpath("/html/body/div[2]/div/div/div/div[2]/ul/li/a/@href")
print(branch_url_1)
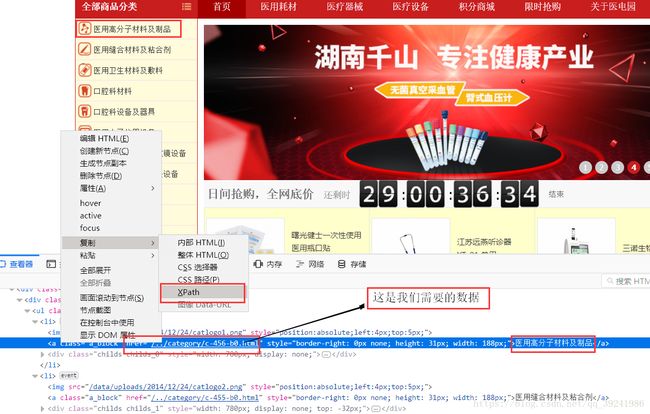
print(branch_url_2)(2)Xpath路径选择分析
- 图片分析:
- 文字解说:
# 上一页
"/html/body/div[2]/div/div/div/div[1]/ul/li[1]/a"
"/html/body/div[2]/div/div/div/div[1]/ul/li[4]/a"
"/html/body/div[2]/div/div/div/div[1]/ul/li[10]/a"
# 下一页
"/html/body/div[2]/div/div/div/div[2]/ul/li[1]/a"上面是我选取的几个不同类别的医疗商品的Xpath路径,可以发现规律,在改变的只有最后一个li标签,而我们要获取的是a标签的href属性(页面url在里面),而且上一页与下一页的区别为最后一个div序号不同,所以Xpath路径为:
"/html/body/div[2]/div/div/div/div[1]/ul/li/a/@href"
and
"/html/body/div[2]/div/div/div/div[2]/ul/li/a/@href"(3)运行结果为

(4)修正数据
通过结果我们易看出,我们所获取到的url和我们想象中还是有差别的,比如没有www或者http,嘿嘿,不过通过页面跳转分析我们知道我们现在获取到的是商品分类url的后面部分,而前面部分则为:http://www.med361.com,处理一下:
# 合并所有类别
branch_url = branch_url_1 + branch_url_2
# 将url处理成我们能直接访问的类型
for i in range(len(branch_url)):
branch_url[i] = mian_url + branch_url[i].replace('/..','')
print(branch_url)运行结果:

到目前为止,这一部分我们就完成了。
3.访问分页面,利用Xpath来获取所有商品详情url
(1)基础代码
# 某个医疗商品类别url
branch_url_01 = "http://www.med361.com/category/c-456-b0.html"
# 发送请求
response_02 = get_respones_data(branch_url_01)
# Xpath 获取所有单个商品url
url_list = response_02.xpath('//*[@id="ddbd"]/form/dl/dd[2]/a/@href')
# 将url处理成我们能直接访问的类型
for i in range(len(url_list)):
url_list[i] = mian_url + url_list[i]
print(url_list)(2)Xpath路径选择分析
- 图片分析:

- 文字解说:
"//*[@id="ddbd"]/form/dl[1]/dd[2]/a"
"//*[@id="ddbd"]/form/dl[3]/dd[2]/a"
"//*[@id="ddbd"]/form/dl[9]/dd[2]/a"上面是我选取的几个不同的医疗商品的Xpath路径,可以发现规律,在改变的只有最后一个dl标签,而我们要获取的是a标签的href属性(页面详情url在里面),所以Xpath路径为:
"//*[@id="ddbd"]/form/dl[9]/dd[2]/a/@href"(3)运行结果为

(4)补充:翻页
- 图片介绍
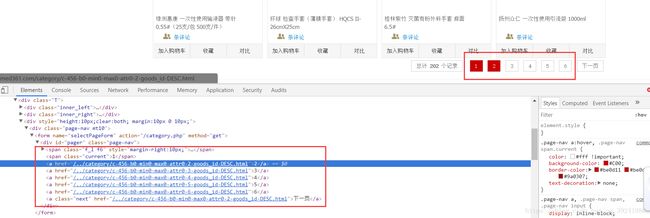
- 代码实现
# 某个医疗商品类别url
branch_url_01 = "http://www.med361.com/category/c-456-b0.html"
# 发送请求
response_02 = get_respones_data(branch_url_01)
# Xpath 获取所有单个商品url
url_list = response_02.xpath('//*[@id="ddbd"]/form/dl/dd[2]/a/@href')
# Xpath 获取所有翻页url
url_paging = response_02.xpath('//*[@id="pager"]/a/@href')
# 将翻页url处理成我们能直接访问的类型
for i in range(len(url_paging)):
url_paging[i] = mian_url + url_paging[i].replace('/..','')
# 将商品url处理成我们能直接访问的类型
for i in range(len(url_list)):
url_list[i] = mian_url + url_list[i]
print(url_list)
for i in range(len(url_paging)):
time.sleep(1)
# 发送请求
response_03 = get_respones_data(branch_url_01)
# Xpath 获取所有单个商品url
url_list = response_03.xpath('//*[@id="ddbd"]/form/dl/dd[2]/a/@href')
# 将商品url处理成我们能直接访问的类型
for i in range(len(url_list)):
url_list[i] = mian_url + url_list[i]
print(url_list)到目前为止,这一部分我们也完成了。
4.访问单个商品页面,利用Xpath来获取商品名称和介绍图片url
(1)基础代码
url_one = "http://www.med361.com/product/p-4357.html"
response_04 = get_respones_data(url_one)
# 1.医疗器材名称(Medical equipment name)
m_e_name = response_04.xpath('//*[@id="product-intro"]/ul/li[1]/h1/text()')[0].strip()
print("医疗器材名称:" + m_e_name)
# 2.图片介绍(Picture introduction)
picture_i = response_04.xpath('//*[@id="content"]/div/div[3]/div[2]/div/div/div[1]/div[2]/div/img/@src')
# 解决获取图片链接不完全问题
for i in range(len(picture_i)):
if mian_url not in picture_i[i]:
picture_i[i] = mian_url + picture_i[i]
print(picture_i)(2)Xpath路径选择分析
- 图片分析:
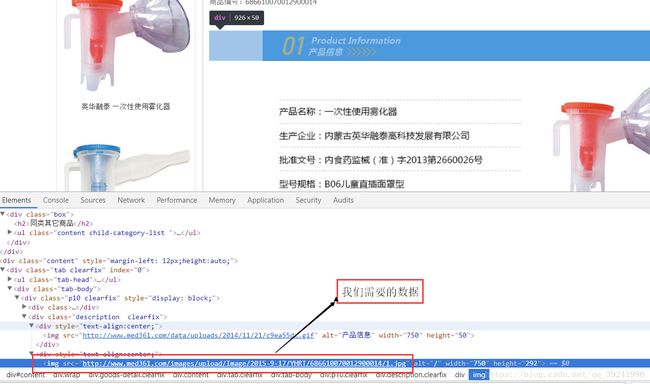
- 文字解说:
'//*[@id="content"]/div/div[3]/div[2]/div/div/div[1]/div[2]/div[4]/img'
'//*[@id="content"]/div/div[3]/div[2]/div/div/div[1]/div[2]/div[5]/img'
'//*[@id="content"]/div/div[3]/div[2]/div/div/div[1]/div[2]/div[6]/img'上面是我选取的几个不同的医疗商品的图片的Xpath路径,可以发现规律,在改变的只有最后一个div标签,而我们要获取的是img标签的src属性(页面详情url在里面),所以Xpath路径为:
"//*[@id="content"]/div/div[3]/div[2]/div/div/div[1]/div[2]/div/img/@src"(3)运行结果为

到目前为止,这一部分我们也完成了。
5.整合上面的2、3、4,系统爬取所有类别所有商品的所有名称和图片信息
(1)基础代码
import requests
from lxml import etree
import time,random
# 获取事先爬好、检测了的代理ip
with open("new_http.txt",encoding="utf-8") as file :
t0 = file.read()
s0 = t0.split(",")
def get_respones_data(branch_url):
# 获取代理ip
i = random.randint(0,len(s0)-2)
proxies = {
"http": s0[i]
}
# requests 发送请求
get_response = requests.get(branch_url)
# 将返回的响应码转换成文本(整个网页)
get_data = get_response.text
# 解析页面
a = etree.HTML(get_data)
return a
# 主页面
mian_url = "http://www.med361.com"
# 发送请求
response_01 = get_respones_data(mian_url)
# 不同医疗商品类别url
branch_url_1 = response_01.xpath("/html/body/div[2]/div/div/div/div[1]/ul/li/a/@href")
branch_url_2 = response_01.xpath("/html/body/div[2]/div/div/div/div[2]/ul/li/a/@href")
# 合并所有类别
branch_url = branch_url_1 + branch_url_2
# 将url处理成我们能直接访问的类型
for i in range(len(branch_url)):
branch_url[i] = mian_url + branch_url[i].replace('/..','')
print(branch_url) # 所有类别
# 商品名称集
commodity_name = []
# 商品介绍图片集
commodity_intr = []
for i in range(len(branch_url)): # 不同类别
time.sleep(random.randint(1,3))
response_02 = get_respones_data(branch_url[i])
url_list_all = []
# Xpath 获取所有单个商品url
url_list = response_02.xpath('//*[@id="ddbd"]/form/dl/dd[2]/a/@href')
# Xpath 获取所有翻页url
url_paging = response_02.xpath('//*[@id="pager"]/a/@href')
# 将翻页url处理成我们能直接访问的类型
for j in range(len(url_paging)):
url_paging[j] = mian_url + url_paging[j].replace('/..', '')
# 将商品url处理成我们能直接访问的类型
for j in range(len(url_list)):
url_list[j] = mian_url + url_list[j]
url_list_all = url_list
# 单个类别翻页
for n in range(len(url_paging)):
time.sleep(1)
# 发送请求
response_03 = get_respones_data(url_paging[n])
# Xpath 获取所有单个商品url
url_list = response_03.xpath('//*[@id="ddbd"]/form/dl/dd[2]/a/@href')
# 将商品url处理成我们能直接访问的类型
for j in range(len(url_list)):
url_list[j] = mian_url + url_list[j]
url_list_all = url_list_all + url_list # 获取了单个类别所有商品url
for m in range(len(url_list_all)):
time.sleep(1)
response_03 = get_respones_data(url_list_all[m])
# 1.医疗器材名称(Medical equipment name)
m_e_name = response_03.xpath('//*[@id="product-intro"]/ul/li[1]/h1/text()')[0].strip()
commodity_name.append(m_e_name) # 获得商品名称
# print("医疗器材名称:" + m_e_name)
# 2.图片介绍(Picture introduction)
picture_i = response_03.xpath('//*[@id="content"]/div/div[3]/div[2]/div/div/div[1]/div[2]/div/img/@src')
# 解决获取图片链接不完全问题
for i in range(len(picture_i)):
if mian_url not in picture_i[i]:
picture_i[i] = mian_url + picture_i[i]
commodity_intr.append(picture_i)
# print(picture_i) # 获得介绍图片(2)文件下载存储到本地
# 下载图片函数
'''
folder_name : 文件夹名称,按图片简介
picture_address : 一组图片的链接
'''
def download_pictures(folder_name, picture_address):
# 在G盘必须有 Medical这个文件夹
file_path = r'G:\Medical\{0}'.format(folder_name)
if not os.path.exists(file_path):
# 新建一个文件夹
os.mkdir(os.path.join(r'G:\Medical', folder_name))
# 下载图片保存到新建文件夹
for i in range(len(picture_address)):
# 下载文件(wb,以二进制格式写入)
with open(r'G:\Medical\{0}\0{1}.jpg'.format(folder_name,i+1), 'wb') as f:
time.sleep(1)
# 根据下载链接,发送请求,下载图片
response = requests.get(picture_address[i])
f.write(response.content)把代码加到正确位置,并调用该函数。
(3)存储到MySql数据库
- Mysql里的medical数据库中新建一个表:
CREATE TABLE `medical`.`data_med` (
`id` INT NOT NULL AUTO_INCREMENT,
`med_name` VARCHAR(200) NULL,
`url_01` VARCHAR(200) NULL,
`url_02` VARCHAR(200) NULL,
`url_03` VARCHAR(200) NULL,
`url_04` VARCHAR(200) NULL,
`url_05` VARCHAR(200) NULL,
`url_06` VARCHAR(200) NULL,
`url_07` VARCHAR(200) NULL,
`url_08` VARCHAR(200) NULL,
`url_09` VARCHAR(200) NULL,
`url_10` VARCHAR(200) NULL,
PRIMARY KEY (`id`),
UNIQUE INDEX `id_UNIQUE` (`id` ASC))
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8;- 数据保存到数据库:
# 数据库连接
conn = pymysql.connect(host = "localhost",port = 3306,user = "你的数据库登录名",
password = "你的数据库登录名",charset="utf8",database = "你的数据库名称")
def sql_insert(sql):
cur = conn.cursor()
cur.execute(sql)
conn.commit()把代码加到正确位置,并调用该函数。
(3)字段内容存储到csv文件
# 存储进CSV文件
'''
list_info : 存储内容列表
'''
def file_do(list_info):
# 获取文件大小(先新建一个csv文件)
file_size = os.path.getsize(r'G:\medical.csv')
if file_size == 0: # 只打印一次表头
# 表头
name = ['名称简介','url_01','url_02','url_03','url_04','url_05','url_06','url_07','url_08','url_09','url_10']
# 建立DataFrame对象
file_test = pd.DataFrame(columns=name, data=list_info)
# 数据写入
file_test.to_csv(r'G:\medical.csv', encoding='utf-8',index=False)
else:
with open(r'G:\medical.csv','a+',newline='') as file_test :
# 追加到文件后面
writer = csv.writer(file_test)
# 写入文件
writer.writerows(list_info)把代码加到正确位置,并调用该函数。
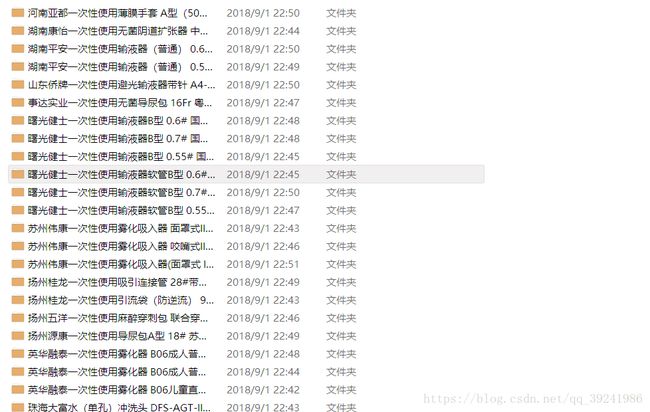
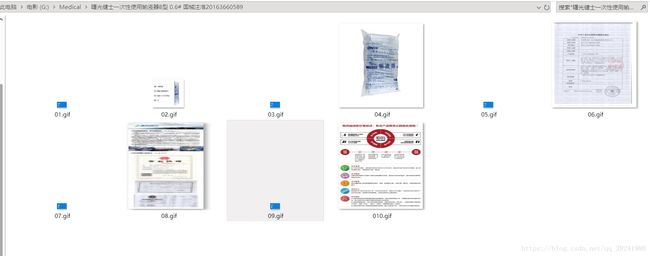
(4)运行效果简单展示

四、后言
以上代码可能需要调试,不过大概的思路是这样的,分享本文,主要想让大家学学我爬取我网页的一个思路,大家不必照着我的敲,如果需要源码加我微信:zs820553471,建议大家学习思想就好,哈哈哈,里面涉及到ip代理池的搭建以及维护,后面有时间再和大家细说。
祝大家开学快乐,工作顺利。哈哈哈。
加微信:zs820553471,进极简学习交流。
