【原创】LeetCode刷题-Python版
文章目录
- LeetCode
- 1、两数之和*
- 2、两数相加
- 3、无重复字符的最长子串**
- 4、寻找两个正序数组的中位数**
- 5、最长回文子串**
- 动态规划思维导图
- 6、Z 字形变换
- 7、整数反转
- 8、字符串转换整数 (atoi)
- 9、回文数
- 10、正则表达式匹配*
- 11、盛最多水的容器*
- 12、整数转罗马数字
- 13、 罗马数字转整数*
- 14、最长公共前缀*
- 15、三数之和
- 16、最接近的三数之和
- 17、电话号码的字母组合*
- 18、四数之和
- 19、删除链表的倒数第N个节点
- 20、有效的括号
- 21、合并两个有序链表
- 22、括号生成**
- 23、合并K个排序链表
- 24、两两交换链表中的节点
- 25、K 个一组翻转链表
- 26、删除排序数组中的重复项
- 27、移除元素
- 28、实现 strStr()*
- 29、两数相除
- 30、串联所有单词的子串**
- 31、下一个排列
- 32、最长有效括号*
- 33、搜索旋转排序数组**
- 34、在排序数组中查找元素的第一个和最后一个位置
- 35、搜索插入位置
- 36、有效的数独
- 37、解数独**
- 38、外观数列
- 39、组合总和*
- 40、组合总和 II
- 41、缺失的第一个正数**
- 42、接雨水
- 43、字符串相乘
- 44、通配符匹配*
- 45、跳跃游戏 II
- 46、全排列
- 47、全排列 II
- 48、旋转图像
- 49、字母异位词分组*
- 50、Pow(x, n)
- 51、N皇后
- 52、N皇后 II
- 53、最大子序和*
- 54、螺旋矩阵
- 55、跳跃游戏
- 56、合并区间
- 57、插入区间
- 58、最后一个单词的长度
- 59、螺旋矩阵 II
- 60、第k个排列
- 61、旋转链表
- 62、不同路径
- 63、不同路径 II
- 64、最小路径和
- 65、有效数字
- 模板
- 模板
- 模板
- 模板
LeetCode
1、两数之和*
题目链接
题目:给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那两个整数,并返回他们的数组下标。不能使用重复元素
方法一:分治
用首尾递进查找做的,需要一次排序,时间复杂度是 O(nlogn)
方法二:字典*
把原先的数组转化成字典,通过字典去查询速度就会快很多,遍历数组,对于元素num1,若target-1存在于字典中直接返回,若不存在,则将其放入字典。时间复杂度是 O(n)
#方法一
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
start,end=0,len(nums)-1
if end<1:
return False
nums.sort()
sums=nums[start]+nums[end]
while (sums!=target):
if start==end:
return False
if sums<target:
start+=1
elif sums>target:
end-=1
sums=nums[start]+nums[end]
return [start,end]
#方法二
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
d={}
for index,num1 in enumerate(nums):
num2=target-num1
if num2 in d:
return [d[num2],index]
d[num1]=index
return None
2、两数相加
题目链接
题目: 给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序的方式存储的,并且它们的每个节点只能存储 一位数字。如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。您可以假设除了数字 0 之外,这两个数都不会以0 开头。465:(5 -> 6 -> 4)
方法:链表
- 这题比较直观,就是循环创建新的节点储存新的计算结果,同时使用变量carry储存进位信息,直到两个代表加数的链表都走到尽头
注意:
- 在循环中不能将计算结果保存在现有节点中,再创建新节点,应该直接将结果保留在新节点中,否则尾节点会有一个多余的0
class Solution:
def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
output=ListNode(0)
l3=output
carry=0
while l1 or l2:
num1=l1.val if l1 else 0
num2=l2.val if l2 else 0
l1=l1.next if l1 else None
l2=l2.next if l2 else None
#注意:计算中carry应该放在括号里面
l3.next=ListNode((num1+num2+carry)%10)
carry=(num1+num2+carry)//10
l3=l3.next
if carry==1:
l3.next=ListNode(1)
return output.next
3、无重复字符的最长子串**
题目链接
题目: 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
方法一:移动指针 + set**
- 使用滑动窗口,在每一步的操作中,将左指针向右移动一格,表示 我们开始枚举下一个字符作为起始位置,然后右指针不断地向右移动,直到两个指针对应的子串中出现重复的字符,我们记录下这个子串的长度
- 在上一步操作中,我们需要使用一种数据结构来判断是否有重复的字符,常用的数据结构为哈希集合——set
- 时间复杂度:O(N)
方法二:移动指针+字典(1+)
- 以字符为键,以字符所在的索引值为value(List),这样每次找到相同的字符时就能准确地知道左指针所需要移至的位置(方法一需要一步一步移动)。空间换时间。要注意左指针之前的字符也会保留在字典里,所以每次判断重复时要比较value[-1]和left的大小。
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
d = set()
#第一次right的初始值设置成了1,导致第一个值没有存入d报错。。。
right=1
maxstr,lenth=0,len(s)
for left in range(lenth):
if left!=0:
d.remove(s[left-1])
while right<lenth and s[right] not in d:
d.add(s[right])
right+=1
maxstr=max(maxstr,right-left)
return maxstr
4、寻找两个正序数组的中位数**
题目链接
题目: 给定两个大小为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出这两个正序数组的中位数,并且要求算法的时间复杂度为 O(log(m + n))。nums1 和 nums2 不会同时为空。
方法:二分法 + 递归**
- 实现在两个有序数组中找到第K个元素:首先使用两个变量i和j分别来标记数组nums1和nums2的起始位置,然后我们分别在nums1和nums2中查找第K/2个元素,若某个数组没有第K/2个数字,就赋值上一个整型最大值,这样在后面运用二分法时就会淘汰另一个数组的前K/2个元素
- 可以使用反证法证明第K个元素必不在较小的前K/2个元素里
- 最后使用二分法:比较这两个数组的第K/2小的数字midVal1和midVal2的大小,如果第一个数组的第K/2个数字小的话,那么说明我们要找的数字肯定不在nums1中的前K/2个数字,所以我们可以将其淘汰,将nums1的起始位置向后移动K/2个,并且此时的K也自减去K/2,调用递归。反之亦然
- 边界情况:
- 当某一个数组的起始位置>=其数组长度时,就等效于直接在另一个数组中找中位数
- 如果K=1的话,比较nums1和nums2的起始位置i和j上的数字就可以了。
注意:
- 找中位数的小技巧:分别找第 (m+n+1) // 2 个,和 (m+n+2) // 2 个,然后求其平均值即可,这对奇偶数均适用。
class Solution:
def findMedianSortedArrays(self, nums1: List[int], nums2: List[int]) -> float:
len1,len2=len(nums1),len(nums2)
def find(i,j,k):
'''实现在两个有序数组中找到第K个元素'''
if i>=len1: return nums2[j+k-1] #nums1走到尽头
if j>=len2: return nums1[i+k-1] #nums2走到尽头
if k==1: return min(nums1[i],nums2[j])
#分别在nums1和nums2中查找第K/2个元素
mid1=nums1[i+k//2-1] if (i+k//2-1)<len1 else float('inf')
mid2=nums2[j+k//2-1] if (j+k//2-1)<len2 else float('inf')
return find(i+k//2,j,k-k//2) if mid1<mid2 else find(i,j+k//2,k-k//2)
left,right=(len1+len2+1)//2,(len1+len2+2)//2
return (find(0,0,left) + find(0,0,right)) / 2
5、最长回文子串**
题目链接
题目: 给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。“bab” 和 “aba” 都是 “babad” 回文字符串,返回一个即可
方法一: DP
- 用 P(i,j)表示字符串 s 的第 i 到 j个字母组成的串是否为回文串,其状态转移方程:
- 动态规划的边界条件:
- 时间复杂度:O(n^2),空间复杂度 :O(n^2)
- 官方参考代码
方法二:中心扩展算法
- 我们枚举所有的「回文中心」并尝试「扩展」,直到无法扩展为止,此时的回文串长度即为此「回文中心」下的最长回文串长度。
- 时间复杂度:O(n^2),空间复杂度:O(1)。
方法三:Manacher 算法
- pass
- 时间复杂度:O(n),空间复杂度 :O(n)
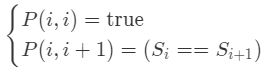
#方法二,参考官方代码的改进部分已在备注中说明
class Solution:
def longestPalindrome(self, s: str) -> str:
start, end = 0, 0 #此处不直接记录当前最长回文子串,而是记录首尾索引值,能节省内存和简化代码
lenth =len(s)
def expand(i,j):
'''以i,j为回文中心向两边扩展回文子串'''
while (i>-1 and j<lenth and s[i]==s[j]):
i-=1
j+=1
return i+1,j-1
for i in range(lenth-1): #i是回文子串的中间
'''DRY原则,需要分类讨论的构造函数进行统一'''
left1,right1 = expand(i,i) #子串为奇数
left2,right2 = expand(i,i+1) #子串为偶数
if right1 - left1 > end - start:
start, end = left1, right1
if right2 - left2 > end - start:
start, end = left2, right2
return s[start:end+1]
动态规划思维导图
转自LeetCode评论区:评论地址
- KMP算法是一种改进的字符串匹配算法
- Manacher 算法专门用于解决“最长回文子串”问题,它是基于“中心扩散法”,采用和 kmp 算法类似的思想,依然是“以空间换时间”。
6、Z 字形变换
题目链接
题目: 将一个给定字符串根据给定的行数,以从上往下、从左到右进行 Z 字形排列。之后,你的输出需要从左往右逐行读取,产生出一个新的字符串。示例:
方法一:找规律按行访问
- 首尾行字符间距为2*(numRows-1),中间行字符间距为2*(numRows-i),2*(i-1)
- 时间复杂度:O(n),空间复杂度:O(n)
方法二:多维数组存储

#方法一
class Solution:
def convert(self, s: str, numRows: int) -> str:
lenth=len(s)
out=''
if numRows==1 or lenth<numRows: return s
if numRows==2: return s[::2]+s[1::2]
for i in range(1,1+numRows): #i表示当前记录的排数
index=i-1 #i排第一列字符的位置
while (index<lenth):
out += s[index]
index+=2*(numRows-i)
#首尾行不执行此步骤
out += s[index] if index<lenth and i!=1 and i!=numRows else ''
index+=2*(i-1)
return out
7、整数反转
题目链接
题目: 给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转。
方法一:数字转字符串
- 时间复杂度:O(lg(n))44 ms,空间复杂度:O(lg(n))13.6 MB
方法二:通过求余模拟栈
- 时间复杂度:O(lg(n))40 ms,空间复杂度:O(1)13.7 M,可能数字太短看不出差异

#方法一
class Solution:
def reverse(self, x: int) -> int:
out=0 if x==0 else int(str(x)[::-1].strip('0')) if x>0 else -int(str(x)[-1:0:-1].strip('0'))
return out if -2**31<=out<=2**31-1 else 0
#方法二
class Solution:
def reverse(self, x: int) -> int:
out=0
sign=1 if x>=0 else -1
x=abs(x)
while (x!=0):
out=out*10+x%10
x=x//10
return sign*out if -2147483648<=out<=2147483647 else 0
8、字符串转换整数 (atoi)
题目链接
题目:
方法一: 正则表达式
- 执行用时 :32 ms;内存消耗 :13.4 MB
方法一: 一行正则表达式
- 技巧一:int(*list)可以将长度为1的列表转化为整数,列表为空返回0(绝了!)
- 技巧二:findall 配合起始符号 ^ 找到第一个目标字符
- 技巧三:使用max,min函数来起到限幅的作用
- 执行用时 :40 ms;内存消耗 :13.7 MB

#方法一
from re import *
class Solution:
def myAtoi(self, str: str) -> int:
m=match(r'([\+\-]?[0-9]+)',str.strip(' '))
if not m:
return 0
num=int(m.group(1))
return num if -2147483648<=num<=2147483647 else -2147483648 if num<0 else 2147483647
#方法二
from re import *
class Solution:
def myAtoi(self, str: str) -> int:
return max(min(int(*re.findall('^[\+\-]?\d+', str.lstrip())), 2**31 - 1), -2**31)
9、回文数
题目链接
题目: 判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。如:121TRUE,-121False,10False。
方法一:数字转字符串
- 将整个数字翻转后与原数字比较,76ms,13.7MB
方法二:数字转字符串
- 将后半段数字翻转后与前半段字比较,76ms,13.5MB(若不用字符,直接求余内存消耗会小些)
#方法一
class Solution:
def isPalindrome(self, x: int) -> bool:
return False if x<0 or (x%10 == 0 and x != 0) else x==int(str(x)[::-1])
#方法一
class Solution:
def isPalindrome(self, x: int) -> bool:
s=str(x)
lenth=len(s)
if x<0 or (x%10 == 0 and x != 0):
return False
elif lenth==1:
return True
else :
return s[:lenth//2:1]==s[:(lenth-1)//2:-1]
10、正则表达式匹配*
题目链接
题目: 给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 ‘.’ 和 ‘*’ 的正则表达式匹配。’.’ 匹配任意单个字符,’*’ 匹配零个或多个前面的那一个元素。
方法: DP(准确来说应该是记忆化的递归)*
- 注释应该够看懂了
注:
- 此题不能用递归,否则时间复杂度会将是指数级的。可以选择加装饰器记忆体化,但是在leetcode上不太方便(对,就是是懒得试)。
- 方法是按照官方改写的,官方解答分类情况比我原版代码要少很多,整体更简洁易懂。原版代码中首先按照第一个字符是否匹配分类;然后每个分类中再分别讨论了后一个字符是否为*,这就产生了四种分类。而且我在讨论边界情况时讨论了s、p的长度不同时大于1的各种情况,在递归中可以一定程度上简化时间,但在有数据存储的dp中就大可不必了。
class Solution:
def isMatch(self, s: str, p: str) -> bool:
memo={}
len1,len2=len(s),len(p)
def dp(i,j):
'''判断s[i:]和p[j:]的匹配情况,以下注释用s、p代替它们'''
if (i,j) not in memo:
#p为空:s为空时True,s不为空时False
if j==len2 :
memo[i,j]=(i==len1)
#p不为空
else:
first=i<len1 and (p[j]==s[i] or p[j]=='.')
#下一个字符为*
if j+1<len2 and p[j+1]=='*':
#‘*’一个都不匹配or暂时匹配一个(即匹配数量>=1)
memo[i,j]=dp(i,j+2) or (first and dp(i+1,j))
#下一个字符不为*
else:
#一个正则字符匹配一个普通字符
memo[i,j]=first and dp(i+1,j+1)
return memo[i,j]
return dp(0,0)
11、盛最多水的容器*
题目链接
题目: 给你 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。说明:你不能倾斜容器,且 n 的值至少为 2。
方法:双指针法*
- 指针初始位置位于两端,每次选较木板短对应的指针向内移动一格,直到左右指针相等。在过程中一直更新最大值。
- 向内收缩短板的证明:在状态 S(i, j)下向内移动短板至 S(i + 1, j)(假设 h[i] < h[j]),则相当于消去了 {S(i, j - 1), S(i, j - 2), … , S(i, i + 1)}S(i,j−1),S(i,j−2),…,S(i,i+1) 状态集合,而所有消去状态的面积一定 <= S(i, j)。因此我们每次向内移动短板,所有的消去状态都不会导致丢失面积最大值 。

class Solution:
def maxArea(self, height: List[int]) -> int:
Vmax,i,j=0,0,len(height)-1
while i<j:
minblock=min(height[i],height[j])
Vmax=max(Vmax,minblock*(j-i))
# 哪边短移动哪边,等长则都移动一格
i+=1 if minblock==height[i] else 0
j-=1 if minblock==height[j] else 0
return Vmax
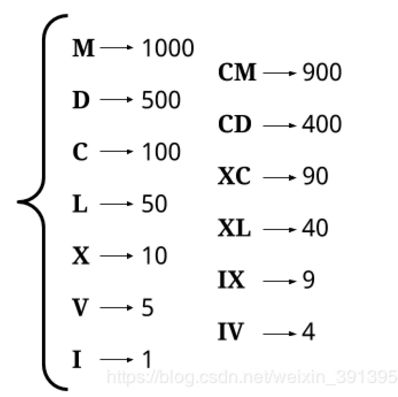
12、整数转罗马数字
题目链接
题目: 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
方法:贪心+DRP原则
- 使用两个数组将分别将阿拉伯数组和罗马数字一一对应着倒序储存,莫要憨憨地手动列举所有情况。

class Solution:
def intToRoman(self, num: int) -> str:
# 使用数组存储阿拉伯数字与罗马数字,且两表均为倒序(符合贪心算法)
nums = [1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1]
Rnums = ["M", "CM", "D", "CD", "C", "XC", "L", "XL", "X", "IX", "V", "IV", "I"]
index = 0
res = ''
while index < 13:
if num >= nums[index]:
res += Rnums[index]*(num//nums[index])
num = num % nums[index]
index += 1
return res
13、 罗马数字转整数*
题目链接
题目: 同12,只是输入输出反转
方法一:正则
- 按照题12中的对应表反推。132ms,忒慢了
方法二:哈希*
- 从左到右检测,如果当前字符代表的值不小于其右边,就加上该值;否则就减去该值。44ms
# 方法一
from re import *
class Solution:
def romanToInt(self, s: str) -> int:
# 使用数组存储阿拉伯数字与罗马数字,且两表均为倒序(符合贪心算法)
nums = [1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1]
Rnums = ["M", "CM", "D", "CD", "C", "XC", "L", "XL", "X", "IX", "V", "IV", "I"]
index = 0
res = 0
while index < 13 and s != '':
find = findall(r'^%s+'%Rnums[index], s)
match =find[0] if find!=[] else ''
lenth = len(match) / len(Rnums[index])
res += nums[index] * lenth
s = s[len(match):]
index += 1
return int(res)
# 方法二
class Solution:
def romanToInt(self, s):
a = {'I':1, 'V':5, 'X':10, 'L':50, 'C':100, 'D':500, 'M':1000}
ans=0
for i in range(len(s)):
if i<len(s)-1 and a[s[i]]<a[s[i+1]]:
ans-=a[s[i]]
else:
ans+=a[s[i]]
return ans
14、最长公共前缀*
题目链接
题目: 查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 “”。输入: [“flower”,“flow”,“flight”],输出: “fl”
方法一:垂直扫描法
- 依次判断所有字符串的每一列是否相同。
方法二:zip()+set()函数*
- 和方法一本质相同,但是使用封装函数后,代码更简洁。
#方法一
class Solution:
def longestCommonPrefix(self, strs) -> str:
res=''
strlen=len(strs)
if strlen==0:
return ''
i=0
while (i<len(strs[0])): #i:字符索引
a=strs[0][i]
for j in range(1,strlen): #j:字符串索引值
if i>=len(strs[j]) or strs[j][i]!=a:
return res
res+=a
i+=1
return res
#方法二
class Solution(object):
def longestCommonPrefix(self, strs):
ans = ''
for i in zip(*strs):
if len(set(i)) == 1:
ans += i[0]
else:
break
return ans
15、三数之和
题目链接
题目: 给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0?请你找出所有满足条件且不重复的三元组。注意:答案中不可以包含重复的三元组。
方法:排序+双指针法
注意:
- 避免重复三元组出现不能使用set,因为:TypeError: unhashable type: ‘list’;不能直接使用“in”检查,时间复杂度会过高;
- 直接在算法中跳过相同的数字可以起到剪枝和避免重复的作用。
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
res=[]
nums.sort()
for i in range(len(nums)-2): #从第一个数检查到倒数第三个数
if nums[i]>0: break #最小数字大于0后停止检测
if i>0 and nums[i]==nums[i-1]: continue #注意:这里不要直接i+=1,因为可能有多个连续重复数字
left,right=i+1,len(nums)-1
while (left<right):
sums=nums[i]+nums[left]+nums[right]
if sums==0:
newlist=[nums[i],nums[left],nums[right]]
res.append(newlist)
'''下面两条查重和上面一次查重,用来避免出现重复的三元组'''
while (left<right and nums[left]==nums[left+1]):
left+=1
while (left<right and nums[right]==nums[right-1]):
right-=1
left+=1
right-=1
elif sums>0:
right-=1
elif sums<0:
left+=1
return res
16、最接近的三数之和
题目链接
题目: 给定一个包括 n 个整数的数组 nums 和 一个目标值 target。找出 nums 中的三个整数,使得它们的和与 target 最接近。返回这三个数的和。假定每组输入只存在唯一答案。
方法:排序+双指针法
- 注意:剪枝操作略有不同,不能直接判断 nums[i] > target,还要加上 nums[i] > 0等条件。
class Solution:
def threeSumClosest(self, nums: List[int], target: int) -> int:
res=float('inf')
nums.sort()
for i in range(len(nums)-2): #从第一个数检查到倒数第三个数
if res!=float('inf') and nums[i]>0 and nums[i]>target: break #最小数字大于target后停止检测
if i>0 and nums[i]==nums[i-1]: continue #注意:这里不要直接i+=1,因为可能有多个连续重复数字
left,right=i+1,len(nums)-1
while (left<right):
sums=nums[i]+nums[left]+nums[right]
if abs(sums-target)<abs(res-target):
res=sums
if sums==target:
return res
elif sums>target:
right-=1
elif sums<target:
left+=1
return res
17、电话号码的字母组合*
题目链接
题目: 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
输入:“23”
输出:[“ad”, “ae”, “af”, “bd”, “be”, “bf”, “cd”, “ce”, “cf”].
方法一:递归
- 函数中每一步递归都复制了一个next_digits数组,空间消耗较大,其实可以直接用索引值访问digits。
方法二:循环*

#方法一
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
code={2:'abc',3:'def',4:'ghi',5:'jkl',6:'mno',7:'pqrs',8:'tuv',9:'wxyz'}
def backtrack(combination, next_digits):
if len(next_digits) == 0:
res.append(combination)
else:
for letter in code[int(next_digits[0])]:
backtrack(combination + letter, next_digits[1:])
res = []
if digits:
backtrack("", digits)
return res
#方法二
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
code={2:'abc',3:'def',4:'ghi',5:'jkl',6:'mno',7:'pqrs',8:'tuv',9:'wxyz'}
if len(digits)==0:
return []
product=['']
for k in digits:
product=[i+j for i in product for j in code[int(k)]] #如果把循环拆开来写,就需要注意product该变量对for循环的影响
return product
18、四数之和
题目链接
题目: 给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。注意:答案中不可以包含重复的四元组。
方法:两次for循环+双指针+剪枝
- 加入剪枝后,运行时间从740ms缩短到了420ms。具体参见 for 循环下的几个 if 函数——用来判断在此情况下,是否会出现最大值小于target或者最小值大于target的情况
class Solution:
def fourSum(self, nums: List[int], target: int) -> List[List[int]]:
res=[]
nums.sort()
for j in range(len(nums)-3): #从第一个数检查到倒数第四个数
if nums[j]>0 and 4*nums[j]>target: break #最小数字*4大于0且大于target后停止检测
if nums[j]+nums[-1]+nums[-2]+nums[-3]<target: continue
if j>0 and nums[j]==nums[j-1]: continue #剪枝连续重复数字
for i in range(j+1,len(nums)-2): #从第(j+1)个数检查到倒数第三个数
sum1=nums[i]+nums[j]
if nums[i]>0 and nums[i]*3+nums[j]>target: break #数二大于0且数一+数二*3大于target后停止检测
if nums[j]+nums[i]+nums[-2]+nums[-1]<target: continue
if i>j+1 and nums[i]==nums[i-1]: continue #注意:要从j+2开始剪枝
left,right=i+1,len(nums)-1
while (left<right):
sums=sum1+nums[left]+nums[right]
if sums==target:
newlist=[nums[j],nums[i],nums[left],nums[right]]
res.append(newlist)
'''下面两条查重和上面一次查重,用来避免出现重复的三元组'''
while (left<right and nums[left]==nums[left+1]):
left+=1
while (left<right and nums[right]==nums[right-1]):
right-=1
left+=1
right-=1
elif sums>target:
19、删除链表的倒数第N个节点
题目链接
题目: 给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。说明:给定的 n 保证是有效的。
方法:双指针

class Solution:
def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:
# 使用双节点,前一个节点总是比后一个节点慢
node1,node2=head,head
for i in range(n):
node2=node2.next
#当n等于链表长度时
if node2==None:
return head.next
#当n小于链表长度时
while (node2.next):
node1=node1.next
node2=node2.next
node1.next=node1.next.next
return head
20、有效的括号
题目链接
题目: 给定一个只包括 ‘(’,’)’,’{’,’}’,’[’,’]’ 的字符串,判断字符串是否有效。有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 空字符串可被认为是有效字符串。
方法:模拟栈+剪枝
- 当栈中元素数目大于s长度的一半时直接返回False
- 测试判断条件似乎有点不合乎逻辑,代码中不分辨左右括号的顺序似乎不会报错。
补充:若字符串只包含小括号
- 字符串有效的充要条件:任何索引位置以左的左括号数大于等于右括号数目
class Solution:
def isValid(self, s: str) -> bool:
sign={'(':1, ')':-1, '[':2, ']':-2, '{':3, '}':-3}
if s=='':
return True
if len(s)%2==1:
return False
res=[]
for m in s:
#新字符和栈顶字符匹配,则出栈
if res!=[] and sign[m]+sign[res[-1]]==0:
res.pop()
#不匹配且为右括号则报错
elif sign[m]<0:
return False
#不匹配且为左括号进栈
elif sign[m]>0:
res.append(m)
#进栈元素大于数目超过一半,直接返回False
if len(res)>len(s)//2:
return False
return res==[]
21、合并两个有序链表
题目链接
题目: 将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
方法一:迭代
方法二:递归

#方法一
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
head=ListNode(0)
l3=head
while (l1 and l2):
#交换链表头结点的方式能统一两种情况的代码
if l1.val<l2.val:
l1,l2=l2,l1
l3.next=l2
l3=l2
l2=l2.next
#将另外一个没有结束的链表直接接在后面
l3.next=l1 if l1!=None else l2
return head.next
#方法二
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
if l1 and l2 :
if l1.val>l2.val:
l1,l2=l2,l1
l1.next=self.mergeTwoLists(l1.next,l2)
return l1 or l2
22、括号生成**
题目链接
题目: 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
方法一:DP*
- 递推法则:dp[i] = “(” + dp[j] + “)” + dp[i- j - 1] , j = 0, 1, …, i - 1
- 可以理解为是枚举了与第一个左括号对应的右括号在不同位置(即改变j)的所有情况,所以不会出现重复的组合。
- defaultdict库函数:作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值
方法二:DFS*

- 转自评论区大佬题解
注:
- DFS差不多等同于回溯,此题由于字符串的特殊性,产生一次拼接都生成新的对象,因此无需"回溯”。(对于每个位置,都有把当前字符压进栈(字符串尾部更新)或者不选的操作,那么这里就有回溯了。)
- BFS不要求我们找出所有的解,但是要求解的特点符合最短性质,DFS恰恰相反。

#方法一:
from collections import defaultdict
class Solution:
def generateParenthesis(self, n: int) :
res = defaultdict(list)
res[0], res[1] = [''] ,['()']
#res={0:[''],1:['()']}此语句会覆盖掉defaultdict()方法
for i in range(2,n+1):
for j in range(i):
left =res[j]
right=res[i-j-1]
res[i]+=['('+m+')'+n for m in left for n in right]
return res[n]
#方法二:
class Solution:
def generateParenthesis(self, n: int) :
res = []
cur_str = ''
def dfs(cur_str, left, right):
"""
:param cur_str: 从根结点到叶子结点的路径字符串
:param left: 左括号还可以使用的个数
:param right: 右括号还可以使用的个数
"""
if left == 0 and right == 0:
res.append(cur_str)
return
if right < left:
return
if left > 0:
dfs(cur_str + '(', left - 1, right)
if right > 0:
dfs(cur_str + ')', left, right - 1)
dfs(cur_str, n, n)
return res
23、合并K个排序链表
题目链接
题目: 合并 k 个排序链表,返回合并后的排序链表。请分析和描述算法的复杂度。
方法一:循环找出各链表中的最小头结点
- 时间复杂度O(nk),250ms
方法二:heapq辅助排序
- 时间复杂度O(nlgk)? ,80ms
#方法一:
class Solution:
def mergeKLists(self, lists: List[ListNode]) -> ListNode:
res=ListNode(-1)
head=res
lenth=len(lists)
state=[1 for i in range(lenth)] #state用于记录空链表
while (sum(state)!=0):
new=ListNode(float('inf'))
index=[]
for i in range(lenth):
if lists[i]==None:
state[i]=0
continue
if new.val>lists[i].val:
new=lists[i]
index=[i]
elif new.val==lists[i].val:
index.append(i)
for i in index:
head.next=lists[i]
head=lists[i]
lists[i]=lists[i].next
return res.next
#方法二:
class Solution(object):
def mergeKLists(self, lists):
import heapq
head = point = ListNode(0)
heap = []
for l in lists:
while l:
heapq.heappush(heap, l.val)
l = l.next
while heap:
val = heappop(heap)
point.next = ListNode(val)
point = point.next
point.next = None
return head.next
24、两两交换链表中的节点
题目链接
题目: 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。给定 1->2->3->4, 你应该返回 2->1->4->3.
方法一:迭代
方法二:递归
#方法一:
class Solution:
def swapPairs(self, head: ListNode) -> ListNode:
res=ListNode(-1)
res.next=head
pre=res
while (head and head.next):
n1=head.next
# 修改链表指向
head.next=head.next.next
n1.next=head
pre.next=n1
# 更新pre和head的值
pre=head
head=head.next
return res.next
#方法二:
class Solution:
def swapPairs(self, head: ListNode) -> ListNode:
if not (head and head.next):
return head
n1=head
n2=head.next
n1.next=self.swapPairs(n2.next)
n2.next=n1
return n2
25、K 个一组翻转链表
题目链接
题目: 给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k> 的整数倍,那么请将最后剩余的节点保持原有顺序。给你这个链表:1->2->3->4->5;当 k = 2 时,应当返回:> 2->1->4->3->5;当 k = 3 时,应当返回: 3->2->1->4->5
方法:构造辅助函数
- 辅助函数1:判断从head节点开始的链表长度是否≥K
- 辅助函数2:将从head节点开始k个节点翻转,且返回翻转后的头尾节点,起承上启下的作用。注意翻转后的k节点(原head节点)必须指向k+1节点
class Solution:
def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
def isNone(head):
'''判断从head开始的k个节点是否全不为空。全不为空返回True,否则返回False'''
for i in range(k):
if head==None:
return False
head=head.next
return True
def reverseK(head):
'''翻转从head开始的k个节点(且原头结点->k+1节点),且返回翻转后的第1,k个节点'''
nodelist=[]
for i in range(k):
nodelist.append(head)
head=head.next #最终head将指向第k+1个节点
for j in range(1,k):
nodelist[-j].next=nodelist[-j-1]
nodelist[0].next=head #启下:翻转后k结点->k+1节点。
return [nodelist[-1],nodelist[0]]
res=ListNode(-1)
res.next=head
pre=res
while (isNone(head)):
nlist=reverseK(head)
pre.next=nlist[0] #承上:0+ik节点->翻转后的1+ik节点
pre=nlist[1] #0+ik节点更新为k+ik节点
head=nlist[1].next #1+ik节点更新为k+1+ik节点
return res.next
26、删除排序数组中的重复项
题目链接
题目: 给定一个排序数组,你需要在 原地 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
方法:双指针
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
j=0 #为nums[i-1]在新数组中的索引值
for i in range(1,len(nums)):
if nums[i]!=nums[i-1]:
j+=1
nums[j]=nums[i]
else:
pass
return j+1
27、移除元素
题目链接
题目: 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
方法:双指针
class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
j=0 #为nums[i]在新数组中的索引值
for i in range(len(nums)):
if nums[i]!=val:
nums[j]=nums[i]
j+=1
else:
pass
return j
28、实现 strStr()*
题目链接
题目: 给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。输入: haystack = “hello”, needle = “ll”,输出: 2。
方法一:暴力搜索
- 时间复杂度是O(m-n)*n,
方法二:KMP*
- 博客讲解
- 时间复杂度是O(m + n),但本题测试案例中字符可能较短,不能明显看出区别
#方法一:
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
len1=len(haystack)
len2=len(needle)
for i in range(len1-len2+1):
'''每次比较从当前索引值开始的len2长度字符串,不匹配索引值+1'''
if haystack[i:i+len2]==needle:
return i
return -1
#方法二:
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
def gen_next(s2):
'''构造并返回KMP中s2的next数组'''
#next[k]值为s2[0:k]中最长前后缀的长度
k = -1 #前后缀最大匹配长度
n = len(s2)
j = 0 #当前待匹配的后缀末尾索引值
next_list = [0 for i in range(n)]
next_list[0] = -1 #next[0]初始值为-1,可以实现s2[0]与s1下一位比较
while j < n-1:
if k == -1 or s2[k] == s2[j]:
k += 1
j += 1
next_list[j] = k #如果相等 则next[j+1] = k+1(k+1最大匹配长度)
else:
#下面注释中所有的k都是指s2[0:j]前后缀最大匹配长度,next(k)即s2[0:k]中最长匹配前后缀的长度
#已知s2[j] != s2[k]
#可知s2[0:next(k)]与s2[j-next(k):j]是匹配的
#若s2[j] == s2[next(k)]
#则next[j+1]=next(k)+1
#若s2[j] != s2[next(k)]
#可知s2[0:next(next(k))]与s2[j-next(next(k)):j]是匹配的……套娃即可
k = next_list[k] #如果不等,则将next[k]的值给k。
return next_list
def match(s1, s2, next_list):
'''判断是否s1中是否存在s2字符'''
ans = -1
i = 0 #s1索引值
j = 0 #s2索引值
while i < len(s1):
# 匹配或next[j]=-1则s1、s2都后移一位
# 由于关注的焦点是i,j的变化,而不是是否匹配,所以将两种情况放在一个if语句里
if s1[i] == s2[j] or j == -1:
i += 1
j += 1
# 否则j更新为next数组中的索引值
else:
j = next_list[j]
# 匹配完毕时退出循环
if j == len(s2):
ans = i - len(s2)
break
return ans
s1 = haystack
s2 = needle
return match(s1, s2, gen_next(s2)) if s2!='' else 0
29、两数相除
题目链接
**题目:**给定两个整数,被除数 dividend 和除数 divisor。将两数相除,要求不使用乘法、除法和 mod 运算符。返回被除数 dividend 除以除数 divisor 得到的商。整数除法的结果应当截去(truncate)其小数部分,例如:truncate(8.345) = 8 以及 truncate(-2.7335) = -2
方法:移位
- 当division在divisor x 2(k+1)~divisor x 2k之间时:division-divisor x 2k 一定在divisor x 2k~divisor x 2(k-1)之间……有数学归纳法可知此算法成立。其本质是二进制的除法运算。
- 如果题目规定不能使用移位操作,也可以将divisor和1循环自加,存储在数组里,可知每个数组长度最多只有33,不会太占内存
class Solution:
def divide(self, dividend: int, divisor: int) -> int:
sign=(dividend > 0) ^ (divisor > 0) #同号为False 异号为True
a, b=abs(dividend), abs(divisor)
count = 0
#把除数不断左移,直到它大于被除数
while a >= b:
count += 1
b <<= 1
result = 0
while count > 0:
count -= 1
b >>= 1
if b <= a:
result += 1 << count #这里的移位运算是把二进制(第count+1位上的1)转换为十进制
a -= b
if sign: result = -result
return result if -(1<<31) <= result <= (1<<31)-1 else (1<<31)-1
30、串联所有单词的子串**
题目链接
题目: 给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。 注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
方法一:暴力解法
- 每次右移一格,检查是否符合匹配条件
方法二:双哈希表**
- 大佬题解
- 若word中字符长度为3,则0、3、6……开头的字符串并论,1、4、7……并论,2、5、8并论。

#方法一:
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
from collections import Counter
if not s or not words:return []
word_lenth=len(words[0])
word_num=len(words)
all_lenth=word_lenth*word_num
harsh=Counter(words) #可以理解为一个简单的计数器,可以统计字符出现的个数
n=len(s)
index=[]
for i in range(0,n-all_lenth+1):
a=[]
for j in range(i,i+all_lenth,word_lenth):
a.append(s[j:j+word_lenth])
res=Counter(a)
if res==harsh:
index.append(i)
return index
31、下一个排列
题目链接
题目: 实现获取下一个排列的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。 必须原地修改,只允许使用额外常数空间。
方法:找规律
- 从后往前检查。对于nums[i],如果它大于num[i+1:],则检查更前的一位数字;否则,将它与num[i+1:]中大于它的最小数字调换之后,将num[i+1:]升序排列。
- 时间复杂度O(n),32ms
class Solution:
def nextPermutation(self, nums: List[int]) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
for i in range(1,len(nums)): #-1-i为当前讨论数的索引值,从后往前讨论
# 若大于等于之后的所有数字,前移一位
if nums[-1-i]>=nums[-i]:
continue
# 否则,和其后的一位大于它的最小数字交换位置之后,将其后的数组升序排列
else:
j=0
while (nums[-1-i]>=nums[-1-j]):
j+=1
nums[-1-j],nums[-1-i]=nums[-1-i],nums[-1-j]
j=0
while(j-i<-j-1):
nums[j-i],nums[-j-1]=nums[-j-1],nums[j-i]
j+=1
return
nums.reverse()
return
32、最长有效括号*
题目链接
题目: 给定一个只包含 ‘(’ 和 ‘)’ 的字符串,找出最长的包含有效括号的子串的长度。
方法一:模拟栈
- 用出栈入栈模拟括号的匹配过程,同时使用stack2记录栈中括号索引值,且索引值随着括号一起出栈入栈(注意stack2的首尾要分别添加一个-1和len(s) )。循环完毕后,找到stack2中相邻且差值最大的两个数,其差值减一便为有效括号的长度。
- 注意这里的有效括号长度是指连续的字符串。“())()()” 的有效长度为4而非6。
- 时间复杂度O(n),空间复杂度O(n)
方法二:找规律* 借鉴自此
字符串有效的充要条件:任何索引位置以左的左括号数大于等于右括号数目
从左到右扫描,用两个变量 left 和 right 保存的当前的左括号和右括号的个数,都初始化为 0 。
- 如果左括号个数等于右括号个数了,那么就更新合法序列的最长长度。
- 如果左括号个数大于右括号个数了,那么就接着向右边扫描。
- 如果左括号数目小于右括号个数了,那么后边无论是什么,此时都不可能是合法序列了,此时 left 和 right 归 0,然后接着扫描。
从左到右扫描完毕后,同样的方法从右到左再来一次。因为类似这样的情况 ( ( ( ) ) ,如果从左到右扫描期间不会出现 left == right。但从右往左扫描会出现left== right。
时间复杂度O(n),空间复杂度O(1)
#方法一:
class Solution:
def longestValidParentheses(self, s: str) -> int:
lenth=0
stack1=[] #储存括号
stack2=[-1] #储存栈中括号对应的索引值
a={'(':')',')':-1}
for i in range(len(s)):
if stack1==[] or a[stack1[-1]]!=s[i]:
stack1.append(s[i])
stack2.append(i)
else:
stack1.pop()
stack2.pop()
stack2.append(len(s))
for i in range(len(stack2)-1):
lenth=max(lenth,(stack2[i+1]-stack2[i]-1))
return lenth
#方法二
class Solution:
def longestValidParentheses(self, s: str) -> int:
lenth=0
for j in range(2):
left,right=0,0
for i in range(len(s)):
i=-1-i if j==1 else i
if s[i]=='(': left +=1
elif s[i]==')': right+=1
if left==right:
lenth=max(lenth,left*2)
elif (j==0 and left<right) or (j==1 and left>right):
left,right=0,0
return lenth
33、搜索旋转排序数组**
题目链接
题目: 假设按照升序排序的数组在预先未知的某个点上进行了旋转。( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。你可以假设数组中不存在重复的元素。你的算法时间复杂度必须是 O(log n) 级别。
方法一:先找到旋转点*
- 比较mid和end。当mid
end:最小点必在右边。 - 要通过分析来决定比较(end,mid,sta)中的哪两个点
方法二:假定数组为有序数组*
- 题目中的数组,其实是两段有序的数组。我们将target不在的那一段看作 inf 或 -inf ,这样整个数组就成了有序数组了,可以直接使用二分法。
- 我们只关心mid的值。只有当mid和target在同一段里的时候,mid才等于其本身,而不是 inf 或 -inf 。
- 把 mid 和 target 同时与 sta 比较,如果它俩都大于或者都小于 sta ,那么就代表它俩在同一段。否则不在同一段。
方法三:迭代
- 算法基于一个事实,数组从任意位置劈开后,至少有一半是有序的。通过比较端点判断哪一段是有序的,查看target是否在其中来判断需要舍弃哪一段。
- 注意,每次只查有序的数组
#方法三
class Solution:
def search(self, nums: List[int], target: int) -> int:
start, end=0, len(nums)-1
while (start<=end):
mid=(start+end)//2
if nums[mid]==target: return mid
#左半段有序
if nums[start]<=nums[mid]:
if nums[start]<=target<nums[mid]:
end=mid-1
else:
start=mid+1
#有半段有序
else:
if nums[mid]<target<=nums[end]:
start=mid+1
else:
end=mid-1
return -1
34、在排序数组中查找元素的第一个和最后一个位置
题目链接
题目: 给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。你的算法时间复杂度必须是 O(log n) 级别。如果数组中不存在目标值,返回 [-1, -1]。
方法:二分法*
- 首先找最左边的target。当mid 指向的值等于 target 时,如果其左边的存在数且等于target,则更新 end = mid - 1,否则直接令left=mid.
- 找右边的target同理
- 注意,不能在找到target之后,直接向左右线性查找直到不等于target为止,这个过程是O(n)的
class Solution:
def searchRange(self, nums: List[int], target: int) -> List[int]:
left,right=-1,-1
for i in range(2):
start, end=0, len(nums)-1
while (start<=end):
mid=(start+end)//2
if nums[mid]==target:
#找到最左边的target
if i==0:
if (mid==0 or nums[mid-1]<target):
left=mid
break
end=mid-1
#找到最右边的target
if i==1:
if (mid==len(nums)-1 or nums[mid+1]>target):
right=mid
break
start=mid+1
elif nums[start]<=target<nums[mid]:
end=mid-1
else:
start=mid+1
return [left,right]
35、搜索插入位置
题目链接
题目: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。你可以假设数组中无重复元素。
方法:二分法
class Solution:
def searchInsert(self, nums: List[int], target: int) -> int:
left,right=0,len(nums)-1
while (left<=right):
mid=(left+right)//2
a,b,c=nums[left],nums[mid],nums[right]
if target<=a:
return left
if target>=c:
return right+1 if target>c else right
if target<b:
right=mid-1
elif target==b:
return mid
elif target>b:
left=mid+1
return 0
36、有效的数独
题目链接
题目: 判断一个 9x9 的数独是否有效。只需要根据以下规则,验证已经填入的数字是否有效即可。数独部分空格内已填入了数字,空白格用 ‘.’ 表示。
- 数字 1-9 在每一行只能出现一次。
- 数字 1-9 在每一列只能出现一次。
- 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。
方法一:暴力解法+DRY
方法二:使用带标志的hash
- 和方法一一样,时间和空间复杂度都是O(n)。
- 整体只遍历一遍,存在空间换时间的思想。
#方法一:
class Solution:
def isValidSudoku(self, board: List[List[str]]) -> bool:
def check(x,y):
for i in range(9//x):
for j in range(9//y):
num=set()
for m in range(x*i,x*(i+1)):
for n in range(y*j,y*(j+1)):
if board[m][n]!='.':
if board[m][n] in num:
return False
else:
num.add(board[m][n])
return True
return check(1,9) and check(3,3) and check(9,1)
#方法二
class Solution:
def isValidSudoku(self, board: List[List[str]]) -> bool:
num=set()
for m in range(9):
for n in range(9):
a=board[m][n]
lenth=len(num)
if a!='.':
num.add('row'+a+str(m))
num.add('colume'+a+str(n))
num.add('block'+a+str(m//3)+str(n//3))
if len(num)!=lenth+3:
return False
return True
37、解数独**
题目链接
题目: 编写一个程序,通过已填充的空格来解决数独问题。空白格用 ‘.’ 表示。
方法:回溯**
- 评论地址
- 本来是用的候选数法(显式+隐式),结果不仅代码极长(多半是能力问题),而且还解不出部分数独题目。只能屈服于暴力的DFS了。。。
class Solution:
def solveSudoku(self, board: List[List[str]]) -> None:
row = [set(range(1, 10)) for _ in range(9)] # 行剩余可用数字
col = [set(range(1, 10)) for _ in range(9)] # 列剩余可用数字
block = [set(range(1, 10)) for _ in range(9)] # 块剩余可用数字
empty = [] # 收集需填数位置
for i in range(9):
for j in range(9):
if board[i][j] != '.': # 更新可用数字
val = int(board[i][j])
row[i].remove(val)
col[j].remove(val)
block[(i // 3)*3 + j // 3].remove(val)
else:
empty.append((i, j))
def backtrack(iter=0):
if iter == len(empty): # 处理完empty代表找到了答案
return True
i, j = empty[iter]
b = (i // 3)*3 + j // 3
for val in row[i] & col[j] & block[b]:
row[i].remove(val)
col[j].remove(val)
block[b].remove(val)
board[i][j] = str(val)
if backtrack(iter+1):
return True
row[i].add(val) # 回溯
col[j].add(val)
block[b].add(val)
return False
backtrack()
38、外观数列
题目链接
题目:
方法:DP

class Solution:
def countAndSay(self, n: int) -> str:
nums='1'
newnums=''
for i in range(n-1):
lenth=len(nums)
times=1#统计连续相同字符的个数
for j in range(lenth):
#末尾或与前一个字母不同,times归一,保存字符数据
if j==lenth-1 or nums[j]!=nums[j+1]:
newnums+=str(times)+str(nums[j])
times=1
#非末尾且与一个字母相同,times++
elif nums[j]==nums[j+1]:
times+=1
nums=newnums
newnums=''
return nums
39、组合总和*
题目链接
题目: 给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的数字可以无限制重复被选取。
方法一:BFS
- 不知为何,200ms+。明明也剪枝了而且按道理来说BFS应该要快一点的啊
方法二:DFS
- 60ms左右
方法三:DP*
- 评论地址
#方法一
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
times=[]
for num in candidates:
times.append(target//num)
output=[]
def bfs(index,case,sums):
if sums==target:
output.append(case[:])
return
if sums>target or index>=len(times):
return
for i in range(times[index]+1):
num=candidates[index]
bfs(index+1,case[:]+[num]*i,sums+num*i)
bfs(0,[],0)
return output
#方法二
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
size = len(candidates)
if size == 0: return []
candidates.sort()
path = []
res = []
def dfs(begin,target):
'''找到candidates[begin:]中的组合使和为target,使用的数字存入path'''
if target == 0:
res.append(path[:])
return
for index in range(begin, size):
residue = target - candidates[index]
if residue < 0:
break
path.append(candidates[index])
# 因为下一层不能比上一层还小,起始索引还从 index 开始
dfs(index,residue)
path.pop()
dfs(0,target)
return res
#方法三
class Solution:
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
dict = {}
for i in range(1,target+1):
dict[i]=[]
for i in range(1,target+1):
for j in candidates:
if i==j:
dict[i].append([i])
elif i>j:
for k in dict[i-j]:
x = k[:]
x.append(j)
x.sort() # 升序,便于后续去重
if x not in dict[i]:
dict[i].append(x)
return dict[target]
40、组合总和 II
题目链接
题目: 给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。candidates 中的每个数字在每个组合中只能使用一次。
方法:DFS
- 防重复:第一个在dfs中调用dfs时,index变为index+1,同一索引值便不会被重复调用了。第二个见评论,或者直接在存入res前判断res中是否已经存在改数组(path必为有序数组),但耗时会长一些
- BFS运行时间惨不忍睹
class Solution:
def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:
size = len(candidates)
if size == 0: return []
candidates.sort()
path = []
res = []
def dfs(begin,target):
if target == 0:
res.append(path[:])
return
for index in range(begin, size):
if index > begin and candidates[index-1] == candidates[index]: #数组常见去重复的方法
continue
residue = target - candidates[index]
if residue < 0:
break
path.append(candidates[index])
# 因为下一层不能比上一层还小,起始索引还从 index 开始
dfs(index+1,residue)
path.pop()
dfs(0,target)
return res
41、缺失的第一个正数**
题目链接
题目: 给你一个未排序的整数数组,请你找出其中没有出现的最小的正整数。
方法:哈希**
- 评论地址
- 考虑这种是否出现的问题,我们很直观的想到哈希表,使用一个标记,记录是否出现
- 但是直接建立哈希表占用了额外的空间,容易分析,时间、空间复杂度都是O(n)
- 我们可以直接在原来的数组上建立哈希表。把一个值移到哈希表中对应的位置——数字-1的下标处,如果此位置原来就有数字,就把这两个数字交换,然后继续移动。显然,我们需要交换的次数最多是n次,比较的次数最多是2n次,所以这样时间复杂度就是O(n) ,因为在原数组上修改,空间复杂度是常数级别,所以就是O(1) 。
class Solution:
def firstMissingPositive(self, nums: List[int]) -> int:
j, n = 0, len(nums)
while j < n:
i = nums[j]
if i > 0 and i <= n and j + 1 != i and nums[i - 1] != i:
nums[i - 1], nums[j] = nums[j], nums[i - 1]
continue
j += 1
for i in range(n+1):
#返回第一个不符合索引值+1=数字所对应的数字
if i==n or i+1!=nums[i]:
return i+1
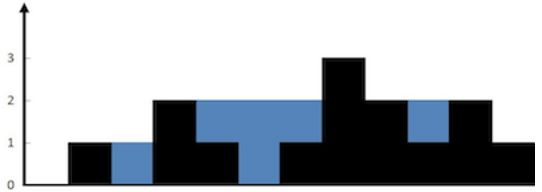
42、接雨水
题目链接
题目:给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
方法一:规律(划分区域后单指针)
- 按列划区域求:先找到最高柱的长度和它的极左、极右位置,并算出这一区间的储水量;然后分别计算从最左到最高柱极左、最右到最高柱极右的储水面积。
- 为了方便,可以先把柱子的面积也算进去,最后用总储水面积减去柱子面积
- 时间复杂度O(n)
方法二:规律(双指针)
- 按行求:对于第h层,双指针分别从左右向中间移动,找到高度不小于h的柱子后停止,即找到了h层的最左、最右柱;h+1,继续找下一层的最左、最右柱,直到找到最高层。
- 为了方便,可以先把柱子的面积也算进去,最后用总储水面积减去柱子面积
- 时间复杂度O(n)
#方法一
class Solution:
def trap(self, height: List[int]) -> int:
#计算最左和最右的最高柱之间储存的水,将左右柱本身的面积也算进去
lenth=len(height)
if lenth<=2: return 0
tallest=max(height)
left=height.index(tallest)
right=lenth-1-height[::-1].index(tallest)
water=tallest*(right-left+1)
def AreaOfSide(first,last,sequence):
'''计算从first柱左侧到last柱左侧的储水面积'''
width=1
firstwall=height[first]
nonlocal water
for i in range(first+sequence,last+sequence,sequence):
if height[i]<=firstwall:
width+=1
elif height[i]>firstwall:
water=water+firstwall*width
firstwall=height[i]
width=1
AreaOfSide(0,left,1)
AreaOfSide(lenth-1,right,-1)
return water-sum(height)
#方法二
class Solution:
def trap(self, height: List[int]) -> int:
water=0
left,right=0,len(height)-1
h=1 #当前层数
#双指针分别从左右向中间移动,找到高度不小于h的柱子后停止,直到找到最高层
while (left<=right):
while(left<=right and height[left]<h):
left+=1
while(left<=right and height[right]<h):
right-=1
#当出现left>right,说明没有高度为h的柱子,直接退出
if left>right: break
#记录此层的储水数(千万不要乘h)
water+=right-left+1
h+=1
return water-sum(height)
43、字符串相乘
题目链接
题目: 给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。输入: num1 = “123”, num2 = “456”;输出: “56088”
方法一:Python
- Python的整数本身就类似Java的BigInteger,可以扩展到无限大位。所以就懒得多写了。
方法二:优化版竖式计算
- 乘数 num1 位数为 MM,被乘数 num2 位数为 NN, num1 x num2 结果 res 最大总位数为 M+N,num1[i] x num2[j] 的结果为 tmp(位数为两位,“0x”,"xy"的形式),其第一位位于 res[i+j],第二位位于 res[i+j+1]。
class Solution:
def multiply(self, num1: str, num2: str) -> str:
return str(int(num1) * int(num2))
44、通配符匹配*
题目链接
题目: 给定一个字符串 (s) 和一个字符模式 § ,实现一个支持 ‘?’ 和 ‘’ 的通配符匹配。’?’ 可以匹配任何单个字符。’’ 可以匹配任意字符串(包括空字符串)。
方法一:DP
- 直接按照第10题改的,不得不说,官方的代码真的简洁漂亮!
- 时间复杂度:O(SP) 716ms,空间复杂度:O(SP)
方法二:回溯*
- 官方注释应该够清楚了。
- 需要补充的是:本来我在纠结如果出现了第二个 ‘*’ 覆盖掉了第一个 ‘*’ 的回溯信息怎么办?但仔细一想,其实这是不影响的:回溯一次意味着 ‘*’ 的匹配字符数+1,那么在不影响s[0:i]的匹配前提下,无论是哪一个星号多匹配一个都是一样的,甚至让最后一个星号多匹配一个还更好,因为这样对匹配情况的影响最小。
- 时间复杂度:最好的情况下是O(min(S,P)) 56ms快如闪电!,平均情况下是 O(SlogP),空间复杂度:O(1)。(画了10秒打开官方提供的证明过程链接,看了两秒我就退出了……)
#方法一
class Solution:
def isMatch(self, s: str, p: str) -> bool:
memo={}
len1,len2=len(s),len(p)
def dp(i,j):
'''判断s[i:]和p[j:]的匹配情况,以下注释用s、p代替它们'''
if (i,j) not in memo:
#p为空:s为空时True,s不为空时False
if j==len2 :
memo[i,j]=(i==len1)
#p不为空
else:
#下一个字符为*
if p[j]=='*':
#‘*’一个都不匹配or暂时匹配一个(即匹配数量>=1)
memo[i,j]=dp(i,j+1) or (i<len1 and dp(i+1,j))
#下一个字符不为*
else:
#一个正则字符匹配一个普通字符
memo[i,j]=i<len1 and (p[j]==s[i] or p[j]=='?') and dp(i+1,j+1)
return memo[i,j]
return dp(0,0)
#方法二
class Solution:
def isMatch(self, s, p):
"""
:type s: str
:type p: str
:rtype: bool
"""
s_len, p_len = len(s), len(p)
s_idx = p_idx = 0
star_idx = s_tmp_idx = -1
while s_idx < s_len:
# If the pattern caracter = string character
# or pattern character = '?'
if p_idx < p_len and p[p_idx] in ['?', s[s_idx]]:
s_idx += 1
p_idx += 1
# If pattern character = '*'
elif p_idx < p_len and p[p_idx] == '*':
# Check the situation
# when '*' matches no characters
star_idx = p_idx
s_tmp_idx = s_idx
p_idx += 1
# If pattern character != string character
# or pattern is used up
# and there was no '*' character in pattern
elif star_idx == -1:
return False
# If pattern character != string character
# or pattern is used up
# and there was '*' character in pattern before
else:
# Backtrack: check the situation
# when '*' matches one more character
p_idx = star_idx + 1
s_idx = s_tmp_idx + 1
s_tmp_idx = s_idx
# The remaining characters in the pattern should all be '*' characters
return all(x == '*' for x in p[p_idx:])
45、跳跃游戏 II
题目链接
题目: 给定一个非负整数数组,你最初位于数组的第一个位置。数组中的每个元素代表你在该位置可以跳跃的最大长度。你的目标是使用最少的跳跃次数到达数组的最后一个位置。
方法一:正向查找+剪枝
- 对于当前所在的位置,遍历它能达到的每一个下一步,找到下一步中能使下下步最长的 “黄金下一步” ,选取 “黄金下一步” 作为下一步,重复上述查找。
- 剪枝:对于上一点的描述:“遍历它能达到的每一个下一步” 。这个过程中其实会有重复的查找。比如从3(4)出发,能到达5(5)、6(1)、7(1)、8(1),经过对比后,5(5)是 “黄金下一步” ;然后再以5(5)作为当前位置查找 “黄金下一步” 时就没有必要分析6(1)、7(1)、8(1),可以直接从9(?)开始分析(即只用比较9(?)、10(?))。这样就达到了剪枝的目的。
- 时间复杂度O(n),很奇怪的是加入了剪枝之后运行时间反而增长了一丢丢,50ms+变成60ms+
方法二:官方正向查找
评论地址

#方法一:
class Solution:
def jump(self, nums: List[int]) -> int:
times=0
index=0
lenth=len(nums)
while (index<lenth-1):
nextindex=1 if index==0 else nextfirst #挑选的第一个下一步
maxstep=nums[index+1]+nextindex #最远下下步对应的索引值
for i in range(nextindex+1,nums[index]+1+index):
'''找到使下下步最远的下一步'''
#下一步位置到达末尾直接返回
if i>=lenth-1:
return times+1
#选取最远的下下步
if i+nums[i]>maxstep:
maxstep=i+nums[i]
nextindex=i
nextfirst=nums[index]+1+index #剪枝,避免重复比较索引值
index=nextindex
times+=1
return times
#方法二:
class Solution:
def jump(self, nums: List[int]) -> int:
n = len(nums)
maxPos, end, step = 0, 0, 0
for i in range(n - 1):
if maxPos >= i:
maxPos = max(maxPos, i + nums[i])
if i == end:
end = maxPos
step += 1
return step
46、全排列
题目链接
题目: 给定一个 没有重复 数字的序列,返回其所有可能的全排列。
方法:回溯+位掩码。
注:
- 为了区分回溯中的不同阶段不同阶段,我们需要使用 “状态变量” 来记录哪些数字已经被使用。常用:位掩码、bool列表、哈希表
- 位掩码,即使用一个整数表示布尔数组。此时可以将空间复杂度降到 O(1)(不包括 path 变量和 res 变量和递归栈空间消耗)
- 回溯的优点:搜索问题的状态空间一般很大,如果每一个状态都去创建新的变量,时间复杂度是 O(N)(如在叶子结点执行拷贝)。在候选数比较多的时候,在非叶子结点上创建新的状态变量的性能消耗就很严重。路径变量 在深度优先遍历 的时候,实现了全局使用一份状态变量 的效果,结点之间的转换只需要 O(1) 。
- 回溯算法可以大量应用 “剪枝”技巧 达到以加快搜索速度。
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
def backtrack(path=[], depth=0, used=0): # 整个回溯函数只包含两个参数,一个是path(记录选择结果),depth(记录还剩多少没有选择)。也可以不用depth,只传递path。通过比较len(path)和len(nums),判断是否完成寻找。
if depth == length: # 终止条件是寻找深度达到目标深度
res.append(path[:]) # 由于list是可变对象,因此,这里要用[:]取到具体的值,再append进res中。
return
for index in range(length): # 遍历所有待添加数
# d = nums[index]
if (used >> index) & 1 == 0: # 如果当前数字没有使用,即该位置的二进制值为0
used ^= (1 << index) # 将该位置的二进制值从0改成1
path.append(nums[index]) # 添加到path 经大佬提醒,放进来。
backtrack(path, depth+1, used)
used ^= (1 << index) # 将该位置的二进制值从0改成1
path.pop()
res = []
length = len(nums)
backtrack()
return res
47、全排列 II
题目链接
题目: 给定一个可包含重复数字的序列,返回所有不重复的全排列。
方法一:题46+集合去重
- 本题重点就是去掉重复的可能性。我们可以首先将数组nums转化为集合,这样在每一轮选择的时候就不会使用到重复的数字,但是这样索引值就会发生混乱,怎么办?那我们就不要用位掩码的作为状态变量了,而是使用字典储存各。数字的剩余使用次数。这样数字的使用次数就不会出错。
- 注意:使用set(nums)的时候就相当于完成剪枝了。
方法二:剪枝去重
- 有点类似题40的思路,而且此代码和题46的相似度更高。我一开始想尝试这种剪枝方法,但是没想出来。
#方法一
from collections import defaultdict
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
lenth,res=len(nums),[]
unused=defaultdict(int)
for num in nums:
unused[num]+=1
nums_set=set(nums)
def backtrace(path,depth,dicts):
if depth==lenth:
res.append(path[:])
return
for num in nums_set: #遍历所有待添加数
if dicts[num]>0: #待使用次数大于0
dicts[num]-=1
path.append(num)
backtrace(path,depth+1,dicts)
path.pop()
dicts[num]+=1
backtrace([],0,unused)
return res
#方法二
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
def dfs(nums, size, depth, path, used, res):
if depth == size:
res.append(path.copy())
return
for i in range(size):
if not used[i]:
if i > 0 and nums[i] == nums[i - 1] and not used[i - 1]:
continue
used[i] = True
path.append(nums[i])
dfs(nums, size, depth + 1, path, used, res)
used[i] = False
path.pop()
size = len(nums)
if size == 0:
return []
nums.sort()
used = [False] * len(nums)
res = []
dfs(nums, size, 0, [], used, res)
return res
48、旋转图像
题目链接
题目: 给定一个 n × n 的二维矩阵表示一个图像。将图像顺时针旋转 90 度。必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。
方法一:转置加上下翻转
- 像素点的坐标由 [x ,y] 变为 [y ,-x] ,等效于先将矩阵转置得到 [y ,x] ,再上下翻转得到 [y ,-x] 。
方法二:zip()
- 这个方法真的妙!太简洁美丽了!评论地址
#方法一
class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
#取中心为原点,建立x-y直角坐标系
#先将数组关于x轴对称,再关于y+x=0对称,即可得到结果
#关于x轴对称:
lenth=len(matrix)
for i in range(lenth//2):
matrix[i],matrix[lenth-1-i]=matrix[lenth-1-i],matrix[i]
#关于y+x=0对称:
for i in range(lenth):
for j in range(i):
matrix[j][i],matrix[i][j]=matrix[i][j],matrix[j][i]
#方法二
class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
matrix[:] = [nums[::-1] for nums in zip(*matrix)]
49、字母异位词分组*
题目链接
题目: 给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
方法一:哈希+排序数组分类
- 维护一个映射 d : {String -> List}。其中每个键 key 是一个排序字符串,每个值 value 是初始输入的字符串列表,排序后等于 key 。
- 时间复杂度:O(NKlogK),空间复杂度:O(NK)
- 官方写的真的简洁,我对一些基本函数的掌握还是不足啊!
方法二:哈希+按计数分类*
- 将每个字符串s 转换为字符数 count,由26个非负整数组成。省去了排序过程。但在字符较少的时候没有明显优势。
- 时间复杂度:O(NK),空间复杂度:O(NK)

#方法一
from collections import defaultdict
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
d=defaultdict(list)#key:排序后的字符串,value:此字符串对应的原字符串列表
for s in strs:
d[tuple(sorted(s))].append(s)
return list(d.values())
#方法二
from collections import defaultdict
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
d=defaultdict(list)#key:字符对应的计数表,value:此列表对应的原字符串列表
for s in strs:
count=[0]*26
for c in s:
count[ord(c)-ord('a')]+=1
d[tuple(count)].append(s)
return list(d.values())
50、Pow(x, n)
题目链接
题目: 实现 pow(x, n) ,即计算 x 的 n 次幂函数。
方法:快速幂
- 借助第29题 “两数相除” 的经验,很容易想到借助二进制实现时间复杂度为O(logn)算法。
- 但是第一遍思维还是有些固化,傻傻地用列表存储了 x**2i 所有的中间值。
class Solution:
def myPow(self, x: float, n: int) -> float:
if n==0: return 1
sign ,n = n/abs(n) ,abs(n)
ans=1
while (n!=0):
if n%2==1: ans*=x
n=n>>1
x=x*x
return ans if sign==1 else 1/ans
51、N皇后
题目链接
题目: n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 ‘Q’ 和 ‘.’ 分别代表了皇后和空位。
方法:回溯
注意:
- 不能使用[[’.’]*n]*n的方式创建多维数组,因为使用乘号创建数组时是直接复制数组的引用值,所以会导致创建的n个list同步变化。写题的时候一时忘了,把自己坑了一道……
class Solution:
def solveNQueens(self, n: int) :
#使用一个函数判断是否此处放子是否合理
res=[]
path=[['.']*n for i in range(n)]
column=set()
left_slash=set() #(n-1-column)+row
right_slash=set() #column+row
def dfs(row):
if row==n:
res.append([''.join(s) for s in path[:]])
return
for i in range(n):
if i in column or (i+row) in right_slash or (n-1-i+row) in left_slash:
continue
column.add(i)
left_slash.add(n-1-i+row)
right_slash.add(i+row)
path[row][i]='Q'
dfs(row+1)
column.remove(i)
left_slash.remove(n-1-i+row)
right_slash.remove(i+row)
path[row][i]='.'
dfs(0)
return res
52、N皇后 II
题目链接
题目: n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。给定一个整数 n,返回 n 皇后不同的解决方案的数量。
方法:回溯
- 抄一抄51题的代码就好了
注:
- 在子函数中调用函数中的对象时:列表是可变的对象,故使用len()、append()函数没有问题;但是对数字、字符串、元组等不可变类型来说,只能读取,不能更新,这时候就需要使用nonlocal声明——它的作用是把变量标记为自由变量。
class Solution:
def totalNQueens(self, n: int) -> int:
#使用一个函数判断是否此处放子是否合理
res=0
path=[['.']*n for i in range(n)]
column=set()
left_slash=set() #(n-1-column)+row
right_slash=set() #column+row
def dfs(row):
if row==n:
nonlocal res
res+=1
return
for i in range(n):
if i in column or (i+row) in right_slash or (n-1-i+row) in left_slash:
continue
column.add(i)
left_slash.add(n-1-i+row)
right_slash.add(i+row)
path[row][i]='Q'
dfs(row+1)
column.remove(i)
left_slash.remove(n-1-i+row)
right_slash.remove(i+row)
path[row][i]='.'
dfs(0)
return res
53、最大子序和*
题目链接
题目: 给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
方法一:双指针
- 两个指针分别指向所选区间的首尾索引值,然后在过程中不断更新最大的和、当前的和。
- 每次右指针右移一位;且当当前的和小于等于零时,摒弃所有数字,即左、右指针都指向下一个数字。
方法二:分治*
- 可由主定理推导得时间复杂度为O(n)
注:
- 看了题解之后才发现方法一原来就用到了 DP 的思想:
- 而且从DP的角度思考似乎更好理解。


#方法一
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
if len(nums)==0: return None
maxsums,sums=nums[0],nums[0]
left,right=0,0
while (right<=len(nums)-2):
right+=1
if sums>0:
sums+=nums[right]
elif sums<=0:
left=right
sums=nums[right]
maxsums=max(maxsums,sums)
return maxsums
#方法一结合DP思想
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
if len(nums)==0: return None
maxsums,ans=nums[0],nums[0]
for i in range(1,len(nums)):
maxsums=max(maxsums+nums[i],nums[i])
ans=max(ans,maxsums)
return ans
from typing import List
54、螺旋矩阵
题目链接
题目: 给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素。
方法:按层模拟
- 将矩阵看成若干层,首先输出最外层的元素,其次输出次外层的元素,直到输出最内层的元素。
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
top,bottom=0,len(matrix)-1 #first and last elements in columns
if bottom==-1: return []
left,right=0,len(matrix[0])-1 #first and last elements in rows
res=[]
while (left+1<=right and top+1<=bottom):
'''按照上、右、下、左的顺序依次存入res中'''
'''此存入方式只适用于剩余排、列数均不小于2的情况'''
res+=matrix[top][left:right]
res+=[matrix[i][right] for i in range(top,bottom)]
res+=matrix[bottom][right:left:-1]
res+=[matrix[i][left] for i in range(bottom,top,-1)]
left+=1;right-=1;top+=1;bottom-=1
'''只剩一排或者一列的处理方式'''
if left==right: res+=[matrix[i][right] for i in range(top,bottom+1)]
elif top==bottom: res+=matrix[top][left:right+1] #这里不能用if,否则排、列数均为1时,会重复存入
return res
55、跳跃游戏
题目链接
题目: 给定一个非负整数数组,你最初位于数组的第一个位置。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个位置。
方法一:菜鸡贪心
- 本来想借用45题的代码改写一下就可以了。可能那个代码写得太烂了,也可能是我不小心绕进去了,结果就是代码贼长,而且我自己还画了半天找bug。
方法二:官方贪心
- 不断右移更新最远距离,且右移的最大位置不能超过当前最远距离
#方法一
class Solution:
def canJump(self, nums: List[int]) -> bool:
index=0
lenth=len(nums)
nextfirst,nextindex=1,1 #第一个下一步,暂时使下下步最远的下一步
while (index<lenth-1):
if nextfirst>=nums[index]+1+index:#nums[index]==0 or
return False
maxstep=nums[index+1]+nextfirst if index==0 else maxstep #最远下下步对应的索引值
for i in range(nextfirst,nums[index]+1+index):
'''找到使下下步最远的下一步'''
#下一步位置到达末尾直接返回
if i>=lenth-1:
return True
#更新使下下步最远的下一步
if i+nums[i]>maxstep:
maxstep=i+nums[i]
if maxstep>=lenth-1:
return True
nextindex=i
nextfirst=nums[index]+index+1 #剪枝,避免重复比较索引值
index=nextindex #选择使下下步最远的下一步
return True
#方法二
class Solution:
def canJump(self, nums: List[int]) -> bool:
n, rightmost = len(nums), 0
for i in range(n):
if i <= rightmost:
rightmost = max(rightmost, i + nums[i])
if rightmost >= n - 1:
return True
return False
56、合并区间
题目链接
题目: 给出一个区间的集合,请合并所有重叠的区间。
方法:hash
- 首先对数组排序,然后使用字典对数组中所有区间进行标记,默认value=1。
- 如果当前区间与下一个区间有重叠,则此区间对应的value改为0,同时将下一个区间改为两个区间组合并后的新区间。
- 结果输出value=1的所有区间(最后一个区间没有被纳入字典,但是也要输出)

from collections import defaultdict
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
a=intervals
a.sort()
res=defaultdict(list)
for i in range(len(a)-1):
res[i]=1
if a[i][1]>=a[i+1][0]:
res[i]=0
a[i+1][0]=min(a[i+1][0],a[i][0])
a[i+1][1]=max(a[i+1][1],a[i][1])
return [a[i] for i in range(len(a)) if res[i]==1 or res[i]==[]]
57、插入区间
题目链接
题目: 给出一个无重叠的 ,按照区间起始端点排序的区间列表。在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
方法一:二分+分治
- a,b=intervals,newInterval。分别找到b[0]、b[1]在a对应列中将要插入的位置left、right。
- 如果a[left-1]和b有交集(对应第一个if),就把两者合并得到新的b,并且left–;同理如果a[right]和b有交集(对应第二个if),也将两者合并,并且right–。
- 可知a[left: right]的区间默认被b合并了 。最后结果输出a[:left]+[b]+a[right:]。
- 如果使用二分法查找left,right,耗时会更短,此代码中查找left中有for循环,所以查找的时间复杂度为O(n)。
- 时间复杂度为O(logn),空间复杂度为O(1)。非常牛逼!
方法一plus:
- 如果将left 定义为b[0]在a中第二列的插入位置,right 定义为b[1]在a中第一列的插入位置。
- 一切变得更简单了,都不需要判断是否需要合并临界区间了。
#方法一
from bisect import *
class Solution:
def insert(self, intervals: List[List[int]], newInterval: List[int]) -> List[List[int]]:
a,b=intervals,newInterval
if a==[] or b==[]: return a or [b] #输出a、b中非空的那一个
left=bisect([s[0] for s in a],b[0])
right=bisect([s[1] for s in a],b[1])
# b和前一个区间有交集,就把前一个区间融入b中
if left>0 and b[0]<=a[left-1][1]:
b[0] =a[left-1][0]
left-=1
# b和后一个区间有交集,就把后一个区间融入b中
if right<len(a) and b[1]>=a[right][0]:
b[1]=a[right][1]
right+=1
return a[:left]+[b]+a[right:]
#方法一改进
from bisect import *
class Solution:
def insert(self, intervals: List[List[int]], newInterval: List[int]) -> List[List[int]]:
a,b=intervals,newInterval
if a==[] or b==[]: return a or [b] #输出a、b中非空的那一个
left=bisect_left([s[1] for s in a],b[0])
right=bisect([s[0] for s in a],b[1])
b[0]=min(b[0],a[left][0]) if left<len(a) else b[0]
b[1]=max(b[1],a[right-1][1]) if right>0 else b[1]
return a[:left]+[b]+a[right:]
58、最后一个单词的长度
题目链接
题目: 给定一个仅包含大小写字母和空格 ’ ’ 的字符串> s,返回其最后一个单词的长度。如果字符串从左向右滚动显示,那么最后一个单词就是最后出现的单词。 如果不存在最后一个单词,请返回 0 。 说明:一个单词是指仅由字母组成、不包含任何空格字符的 最大子字符串。
方法:
- 使用 split() 函数,即用空格分割字符串,且会自动忽略首尾空格
class Solution:
def lengthOfLastWord(self, s: str) -> int:
return len(s.split()[-1]) if s.strip()!='' else 0
59、螺旋矩阵 II
题目链接
题目: 给定一个正整数 n,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵。
方法:模拟法
- 当n为奇数时,首先装填中心的数字n^2,然后就可以等同于整数的处理方式了:每次分别依次装填:上、右、下、左的数字。
class Solution:
def generateMatrix(self, n: int) -> List[List[int]]:
res=[[0]*n for i in range(n)]
if n%2==1: res[n//2][n//2]=n**2
top,bottom=0,n-1 #first and last elements in columns
left,right=0,n-1 #first and last elements in rows
num=1
while (left<right and top<bottom):
'''按照上、右、下、左的顺序依次存入res中'''
for i in range(left,right):
res[top][i]=num
num+=1
for i in range(top,bottom):
res[i][right]=num
num+=1
for i in range(right,left,-1):
res[bottom][i]=num
num+=1
for i in range(bottom,top,-1):
res[i][left]=num
num+=1
left+=1;right-=1;top+=1;bottom-=1
return res
60、第k个排列
题目: 给出集合 [1,2,3,…,n],其所有元素共有 n! 种排列。按大小顺序列出所有排列情况,并一一标记。给定 n 和 k,返回第 k 个排列。
方法:康托展开
- X就是 n 的全排列产生的第几个序列号。范围为 [0, n!-1 ]。
- ai表示在此时剩余的数字中比此位置上数字小的个数。例如对于排列:1236……,6之后比6小的数字只有4、5两个数字,则an-3=2。
- (n-i-1)! 代表以 an-an-i 开头的排列情况的总数
注:
- math库中的factorial 方法可用于求阶乘
import math
class Solution:
def getPermutation(self, n: int, k: int) -> str:
res=''
nums=[str(i) for i in range(1,1+n)]
for i in range(1,1+n):
a=math.factorial(n-i)
index=(k-1)//a
res+=nums[index]
nums.pop(index)
k=k%a
return res
61、旋转链表
题目链接
**题目:**给定一个链表,旋转链表,将链表每个节点向右移动 k 个位置,其中 k 是非负数。
方法:链表
- 第一步获取链表长度lenth和尾节点tail,然后使尾节点指向头结点,然后查找第(lenth-k%lenth)个节点,并储存下一个节点作为要返回的新头结点,并将此节点指向None
class Solution:
def rotateRight(self, head: ListNode, k: int) -> ListNode:
tail=head
if head==None :return None
lenth=1
while(tail.next!=None):
lenth+=1
tail=tail.next
k=lenth-k%lenth
tail.next=head
for i in range(k-1):
head=head.next
res=head.next
head.next=None
return res
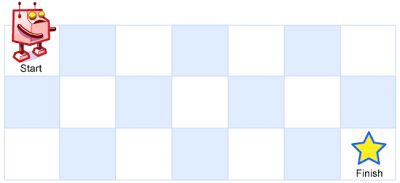
62、不同路径
题目链接
题目: 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。问总共有多少条不同的路径?
方法一:排列组合
- 对于m*n的方格,只要向下走(m-1)步,向右走(n-1)步就一定能到达终点。即总共有 C m + n − 2 m − 1 C^{m-1}_{m+n-2} Cm+n−2m−1 条路径。
方法一:DP
- 设f(m,n)为到达(m,n)格的路径数,则动态方程:f(m,n)=f(m-1,n)+f(m,n-1).
- 本代码空间复杂度为O(nm),可以改进。首先第 j 排复制第 j-1 排的数据(代码中不需要操作,只是数据意义改变了),然后cur[j] = cur[j] + cur[j-1]。其效果等同于原冬天方程,此时空间复杂度为O(n)
#方法一:
class Solution:
def uniquePaths(self, m: int, n: int) -> int:
return int(math.factorial(m+n-2)/math.factorial(m-1)/math.factorial(n-1))
#方法二:
class Solution:
def uniquePaths(self, m: int, n: int) -> int:
res=[[1]*n for i in range(m)]
for i in range(1,m):
for j in range(1,n):
res[i][j]=res[i][j-1]+res[i-1][j]
return res[m-1][n-1]
63、不同路径 II
题目链接
题目: 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?网格中的障碍物和空位置分别用 1 和 0 来表示。
方法:DP
- 方法同题62,只是对于有障碍的网格,将对应的路径数设置为0
- 直接使用提供的 obstacleGrid 数组当做 dp 数组,可以使空间复杂度为O(1)
class Solution:
def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:
res=obstacleGrid
if res[0][0]==1:return 0
m,n=len(res),len(res[0])
for i in range(0,m):
for j in range(0,n):
res[i][j]=1-res[i][j]
#当前网格有障碍,直接跳过
if res[i][j]==0:
pass
#第一排网格,每个网格路径数等于其左侧的网格路径数
elif i==0 and j!=0:
res[i][j]=res[i][j-1]
#第一列网格,每个网格路径数等于其上侧的网格路径数
elif i!=0 and j==0:
res[i][j]=res[i-1][j]
#动态方程
elif i*j!=0:
res[i][j]=res[i][j-1]+res[i-1][j]
return res[m-1][n-1]
64、最小路径和
题目链接
题目: 给定一个包含非负整数的 m x n 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。说明:每次只能向下或者向右移动一步。
方法:DP
- 设f(m,n)为到达(m,n)格的路径数,设g(m,n)为(m,n)网格的路径长度,则动态方程:f(m,n) = g(m,n) + min( f(m-1,n), f(m,n-1) )。对于第一排和第一列 的网格,则需要作相应的分类处理。
class Solution:
def minPathSum(self, grid: List[List[int]]) -> int:
res=grid
m,n=len(res),len(res[0])
for i in range(0,m):
for j in range(0,n):
#当前网格有障碍,直接跳过
if i==0 and j==0:
pass
#第一排网格,每个网格路径数等于其左侧的网格路径数+此格数字
elif i==0 and j!=0:
res[i][j]+=res[i][j-1]
#第一列网格,每个网格路径数等于其上侧的网格路径数+此格数字
elif i!=0 and j==0:
res[i][j]+=res[i-1][j]
#动态方程
elif i*j!=0:
res[i][j]+=min(res[i][j-1],res[i-1][j])
return res[m-1][n-1]
65、有效数字
题目链接
题目: 验证给定的字符串是否可以解释为十进制数字。
方法一:正则
- 题目中 “.1” 和 “3.” 也算作有效数字了,这个是我没想到的。
方法二:表驱动法
#方法一
from re import *
class Solution:
def isNumber(self, s: str) -> bool:
return True if match(r'^[\+\-]?((\d+\.?(\d+)?)|(\.\d+))(e[\+\-]?\d+)?$',s.strip()) else False
模板
题目链接
题目:
方法:
- a
代码
模板
题目链接
题目:
方法:
- a
代码
模板
题目链接
题目:
方法:
- a
代码
模板
题目链接
题目:
方法:
- a
代码
1-40题(28、30)