中文文本分类_预处理
中文文本分类之数据预处理
- 0 前期准备
- 语料库
- 停用词
- 其他
- 1 正则匹配
- * 针对搜狗语料的xml
- 正则匹配出内容和类别
- 2 分训练集和测试集
- 3 合并训练集
- 4 jieba分词
- 收尾
0 前期准备
语料库
我做的是中文新闻分类,新闻分类现有的较流行的语料库包括搜狗新闻语料库、T大的数据、复旦的数据等等。论文看得不算多,找数据的话随便看几篇就知道啦。链接不放了,随便一搜就找得到。
对了,吐槽一下搜狗新闻的语料。如果你搜教程的话,会发现很多博主都用的是搜狗语料,然而你也会发现,人家用的数据集跟你现在在搜狗实验室下下来的数据集不一样——前几年比较好用的数据集没了,现在的数据集处理起来非常之麻烦。。我吐了
这里说一下较理想的标准数据集地样子吧:
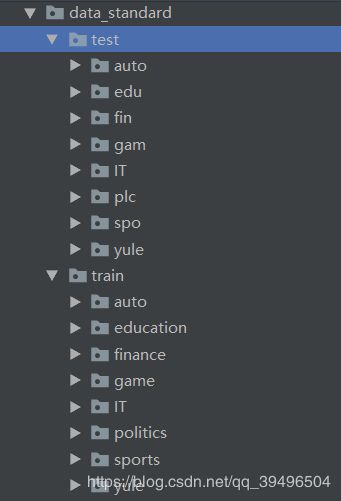

如果你拿到的是这样的数据集,那么恭喜你,你的工作量至少减少了一半多
跑数据一分钟,数据处理两小时可不是说说而已。
这份数据是我结合搜狗新闻和T大新闻数据整理自用的,8个类别,每类5000条文本,其中1000测试,4000训练。数据量比较适合做毕业论文这种小课题。已上传至CSDN资源,希望能帮后来者入门快一些。
停用词
停用词较常用的是哈工大停用词表,这里放一个github连接,作者总结了四份中文停用词表,挺全的。
其他
愉快的心情。
1 正则匹配
* 针对搜狗语料的xml
如果你不幸要用搜狗新闻语料库,还要多一步,这里放一个转送门,有博主做了详细解释,不想看就直接看代码学习。
code
'''数据中为上述doc标签的集合,并不是标准的xml文件,首先将数据开头和结尾分别加上''和根标签。'''
# 修复xml格式
filePath = 'news_sohusite_xml.dat' #语料路径
#fileSeqWordDonePath = 'data/sougou.xml.parse.txt'# 分词后生成路径
#
fw=open(fileSeqWordDonePath, 'w', encoding='utf-8')
fw.write('')
with open(filePath, 'r', encoding='gb18030' ) as fileTrainRaw: #python3
for line in fileTrainRaw:
fw.write(line.replace('&','&')) #去除非法字符
fw.write('')
fw.close()
正则匹配出内容和类别
如果你的语料格式还保留了爬虫爬取是网页风格,那么就需先从url里提取出类别,content中取出文本内容。不难理解。
code
# -*- coding: utf-8 -*-
'''
该脚本用于将语料库新闻语料
转化为按照URL作为类别名、
content作为内容的txt文件存储
'''
'''生成原始语料文件夹下文件列表'''
def listdir(path, list_name):
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
else:
list_name.append(file_path)
'''字符数小于这个数目的content将不被保存'''
threh = 50
'''获取所有语料'''
list_name = []
listdir('data2/',list_name)
'''对每个语料'''
for path in list_name:
print(path)
file = open(path, 'rb').read().decode("utf8")
'''
正则匹配出url和content
'''
patternURL = re.compile(r'(.*?).sohu.com ', re.S)
patternCtt = re.compile(r'(.*?) ', re.S)
classes = patternURL.findall(file)
contents = patternCtt.findall(file)
'''
# 把所有内容小于30字符的文本全部过滤掉
'''
for i in range(contents.__len__())[::-1]:
if len(contents[i]) < threh:
contents.pop(i)
classes.pop(i)
'''
把URL进一步提取出来,只提取出一级url作为类别
'''
for i in range(classes.__len__()):
patternClass = re.compile(r'http://(.*?)/',re.S)
classi = patternClass.findall(classes[i])
classes[i] = classi[0]
#print(classes[i])
'''
按照RUL作为类别保存到samples文件夹中
'''
for i in range(classes.__len__()):
file = 'data/' + classes[i] + '.txt'
f = open(file,'a+',encoding='utf-8')
f.write(contents[i]+'\n') #加\n换行显示
这时你的数据应该是每一类在一个txt中了。
这么做有利有弊,
利在于一步到胃,你可以直接分词然后就上特征选择、分类器了
弊在于,如果你此时你还处于没有分训练集合测试集的境地。。那你就尴尬了,因为一般的方法(train_test_splite)无法在一个分完词的txt里操作
我当时真的醉了,辛辛苦苦大半天,一棍子砸在裆中间。蛋疼。
所以我这里其实是断了一环的,即如何在一个txt中分出训练测试集。
不过我查不到方法时,就换了思路。因为当时找数据集时就有两种情况,一种是这种每个类别一个大txt的,另一种是每个类别一个文档,每个文档中数千个小txt的,即我最终选择的版本,也是T大数据集的样子。
2 分训练集和测试集
一般来讲为追求类别平衡,每个类别中的文本数量是相同的。
如果是低数量级的数据,训练集测试集比取37、28均可;如果是百万级别乃至更多时,其实取19乃至1:99效果会更好。
咱就做个毕设,4万条数据,取28就蛮好。
至于怎么分的?我能想到的一个是直接在循环里把一定数量的txt移到新文件夹里,一个是用上文提到的splite应该也行(我不太了解也没试过,有晓得的读者可以说说)
因为我得东拼西凑把5000条数据搞齐,所以我是用最笨的方法,即手工剪切粘贴。。你们别学我。
3 合并训练集
为方便后续分词和统计特征,把训练集中每个类别下的小txt合成一个大txt
这个咱会。
code
import os
import os.path
import time
time1 = time.time() # tik_tok_计时器
def MergeTxt(filepath, outfile): # 合并同一个文件夹下多个txt
'''
os.walk()可以得到一个三元tupple(parent, dirnames, filenames)
parent:起始路径
dirnames:起始路径下的文件夹
filenames:第三个是起始路径下的文件
函数从给定的rootdir进行遍历,此时parent = rootdir
将rootdir中的所有文件夹名,放入dirnames中,所有的文件名放入filenames中
从dirnames中选择第一个文件夹进行遍历,此时parent = rootdir / 1,接下来便是不断地进行迭代
'''
for parent, dirnames, filenames in os.walk(filepath):
k = open(parent + outfile, 'a+', encoding='utf-8') # 此时应该到了第2级目录,parent已变为二级
for filepath in filenames: # 遍历二级中的文件集
txtPath = os.path.join(parent, filepath) # txtpath就是所有文件夹的路径
f = open(txtPath, encoding='utf-8')
k.write(f.read() + "\n") # 换行写入
k.close()
print("finished")
if __name__ == '__main__':
filepath = "data_merge/train/"
outfile = ".txt"
MergeTxt(filepath, outfile)
time2 = time.time()
print(u'总共耗时:' + str(time2 - time1) + 's')
4 jieba分词
终于到了这一步,很关键但复杂的一步,但有了结巴,一切便索然无味了起来hhhh
果然科技的发展是为了让人变懒呢。懒是人类之光。
code
import jieba as jb
from os import path
import os
import time
tik=time.time()
d = path.dirname(__file__)
stopwords='data_standard/stopwords_all.txt' # 停用词表
filepath="data_merge/train/" # 待处理文本路径
outfile = 'data_merge/train_splited/' # 输出文件路径
# 如果是多级目录,请千万千万 记得 在最后加上 /
def jiebaClearText(text):
mywordlist= []
seg_list=jb.cut(text, cut_all=False) #jieba分词,默认模式
liststr = "/".join(seg_list) #先进行分词操作了,以 / 隔开
f_stop = open(stopwords, encoding='utf-8') #在这里加编码 utf-8
try:
f_stop_text = f_stop.read()
#f_stop_text = f_stop_text.decode('utf-8')#unicode(f_stop_text, 'utf-8')
finally:
f_stop.close()
f_stop_seg_list = f_stop_text.split('\n') #以\n为分隔的txt停用词表,将每个词保存为list中的元素
for myword in liststr.split('/'):
if not (myword.strip() in f_stop_seg_list) and len(myword.strip()) > 1:
mywordlist.append(myword)
return ' '.join(mywordlist)
for parent, dirnames, filenames in os.walk(filepath):
for filepath in filenames: # 遍历二级中的文件集
k = open(outfile + filepath, 'a+', encoding='utf-8') # 此时应该到了第2级目录,parent已变为二级
txtPath = os.path.join(parent, filepath) # txtpath就是所有文件夹的路径
f=open(txtPath,'r', encoding='utf-8').read()
k.write(jiebaClearText(f))
tok=time.time()
print(u'总共耗时:' + str(tok - tik) + 's')
收尾
如果用的是本文的数据集,只做最后一步就可了。
分完词之后就没了。你的数据就已经可以拿去给算法糟蹋了。
我的课题是特征选择算法研究,但没想到难点居然在数据预处理hhhh
当然,后面的我虽然已有思路,但还没做,只是觉得比预处理简单,也许却是望山跑死马呢。
但愿顺利,明天再更。