分布式的Scrapy过于能打!十个resquests都顶不住! ๑乛◡乛๑ Scrapy框架使用方法
文章目录
- Scrapy简介
- 分布式Scrapy简介
- 准备工作
- scrapy-redis简介
- scrapy_redis设置(settings.py)
- 实战测试
- CrawlSpider
- RedisCrawlSpider
- RedisSpider
Scrapy简介
也许使用Scrapy和resquests对比是一件不太公平的事情,因为Scrapy作为一个框架和作为一个库的resquest功能偏向有所不同,Scrapy更加注重大而全。下图左边的文件管理器中为只安装resquest需要的库,右边为安装scrapy和scrapy-readis(做分布式使用)的库。从中我们可以看出scrapy相较于resquests庞大数倍。

虽然在体积上Scrapy显得更加庞大,但在实用性上Scrapy却比resquests有着更好的表现,无论是在代码量上还是在运行速度上,Scrapy都远胜于resquests。Scrapy的流程对于初学者来说初看可能会显得比较繁琐,但等使用过scrapy后,你会发现真个爬虫流程中,scrapy帮你已经完成了很多事情,你需要做的大部分事情就是告诉Scrapy要去哪里下载数据、那些数据对你来说需要保存和保存数据到哪里。
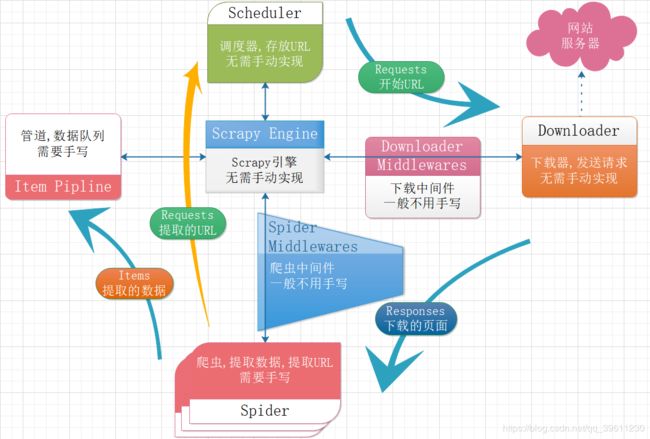
scrapy中还有一些非常实用,已经封装完成的方法,比如链接提取器、自动登录、图片(文件)下载器等。在我往期的scrapy博客中都有详细介绍,这里就不在过多赘述。千万别被Scrapy看似复杂的流程劝退,相信我等你真正了解的Scrapy,你会觉得真想!(王境泽定理警告!!!)
分布式Scrapy简介
分布式scrapy需要用到的redis这个非关系数据库进行存储,数据库种类那么多,我们为什么非要用redis呢?
这个问题就和redis数据库的性质有关了,redis虽然是数据库,但大多数时候他都是已一个类似于中间件的形式存在,因为redis数据库将数据存在了内存中,所以redis有着非常快的读写能力,除此之外redis还一个特效是会自动去重。而我们分布式爬虫需要做到数据的快速爬取和记录已经完成爬取的网站,保证不会二次爬取造成资源浪费!而redis的快速读写非常适合爬虫爬取记录数据使用,自动去重又可以拿来验证资源是否已经完成爬取。
准备工作
首先我们需要用pip安装scrapypip install scrapy和scrapy-redispip install scrapy-redis,然后你需要安装一个可以正常运行的redis,可以就在你本地安装redis,也可以在服务器上安装一个redis。
redis数据库安装
scrapy-redis简介
scrapy-redis是一个基于scrapy和redis的开源分布式项目,我们基于此项目可以快速搭建出我们自己的分布式爬虫,减少了重复造轮子带来的麻烦。
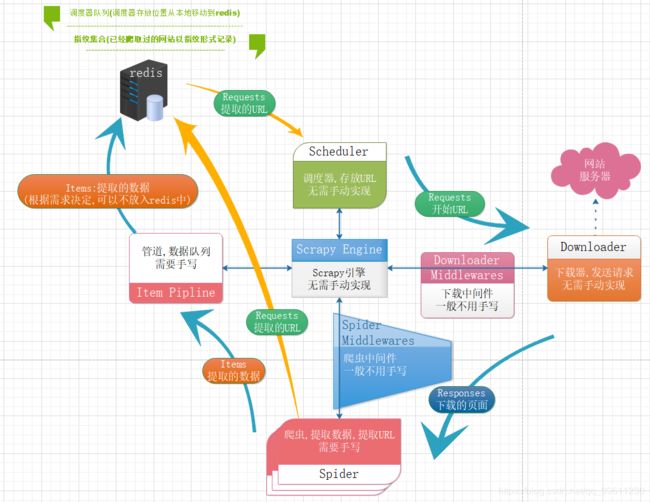
scrapy-redis最主要是将我们的调度器放入了redis数据库中,这样能做到多个爬虫共用一个调度器,还一个重要的作用就是存储了指纹集合,他的主要作用是记录已经爬取过得网页。
其中收集的数据,可以根据你的需求自行决定是否要放入到redis中。
当我们启动scrapy_redis后,在redis数据库中,我们最多会出现三个键
- 爬虫名:requests
request:存放代请求(request)对象,获取操作是pop形式,即获取的请求会从requests中去除。==使用了:zset(有序集合)的数据格式, ==使用zrange 键名 0 -1即可查看所有数据。 - 爬虫名:dupefilter
dupefilter: 存放所有已经爬取过页面的指纹,这里之所以说是指纹而不是简单的url,因为默认指纹包含,请求方法、url和请求体使用了:set(集合)的数据格式, 使用smembers 键名即可查看所有数据
- 爬虫名:items
这里存放的是我们提取的数据,需要开启管道'scrapy_redis.pipelines.RedisPipeline'此数据才会同步到scrapy中,使用了:list(列表)的数据格式, 使用LRANGE 键名 0 -1即可查看所有数据。(中文默认使用ASCII进行了转码)
scrapy_redis设置(settings.py)
# 在redis中启动调度器(Scheduler)存储队列
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 确保所有爬虫(spiders)共享相同的重复项数据集合,并通过redis进行过滤。
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Default requests serializer is pickle, but it can be changed to any module with loads and dumps functions. Note that pickle is not compatible between python versions.
# 默认的请求序列化器是pickle,但是可以更改为具有装入和转储功能的任何模块。 请注意,pickle在python版本之间不兼容。
# Caveat: In python 3.x, the serializer must return strings keys and support bytes as values. Because of this reason the json or msgpack module will not work by default. In python 2.x there is no such issue and you can use 'json' or 'msgpack' as serializers.
# 注意:在python 3.x中,序列化程序必须返回字符串键并支持字节作为值。 因此,默认情况下json或msgpack模块将无法正常工作。 在python 2.x中没有这样的问题,您可以使用'json'或'msgpack'作为序列化程序。
#SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"
# 不清理redis队列,允许暂停/恢复爬网。
#SCHEDULER_PERSIST = True
# 使用优先级队列调度请求。(默认为 PriorityQueue:优先队列)
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# 备用队列。(FifoQueue:先进先出队列,LifoQueue:进先出队列)
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
#SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue'
# 最大空闲时间,以防止爬虫(spiders)在分布式爬行时被关闭。
# 这只在队列类是SpiderQueue或SpiderStack时有效,也可能在蜘蛛第一次启动的同时阻塞(因为队列是空的)。
#SCHEDULER_IDLE_BEFORE_CLOSE = 10
# 将爬取下来的项目(items)存储在Redis中以进行后期处理。
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
# 项目(item)管道(pipeline)将项目序列化并存储在此redis键中。
#REDIS_ITEMS_KEY = '%(spider)s:items'
# The items serializer is by default ScrapyJSONEncoder. You can use any importable path to a callable object.
# 默认情况下,项序列化程序是ScrapyJSONEncoder。可以使用可调用对象的任何可导入路径。
#REDIS_ITEMS_SERIALIZER = 'json.dumps'
# 指定连接到Redis时要使用的主机和端口(默认为:127.0.0.1:6379)。
#REDIS_HOST = 'localhost'
#REDIS_PORT = 6379
# 指定用于连接的完整Redis URL(可选)。此设置优先于REDIS_HOST和REDIS_PORT设置。
#REDIS_URL = 'redis://user:pass@hostname:9001'
# 自定义redis客户端参数。即:密码, 套接字(socket)超时等
REDIS_PARAMS = {
'password': '连接密码'
}
# 使用自定义编辑客户端类。
#REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient'
# 如果为True,则使用redis``SPOP``操作。必须使用“SADD”命令向redis队列添加url。如果您希望避免在开始url列表中出现重复,并且处理顺序无关紧要,那么这可能非常有用。
#REDIS_START_URLS_AS_SET = False
# RedisSpider和rediscrawpsider的默认开始url键。
#REDIS_START_URLS_KEY = '%(name)s:start_urls'
# 对redis使用utf-8以外的编码。
#REDIS_ENCODING = 'latin1'
有三种爬虫模式可以使用分布式Scrapy,分别是CrawlSpider、RedisCrawlSpider、RedisSpider如果你只接触过Scrapy可能其中只有CrawlSpider是你听说过得,这种也就是我们常用的链接提取器形式,这三种我们会在下面的实战测试中详细演示其中的作用。
实战测试
我当前的设置redis部分和上图一致,常规部分启动了DOWNLOAD_DELAY = 1爬虫限制和LOG_LOVER = 'DEBUG'错误警告信息这两个
CrawlSpider
首先我们使用继承与CrawlSpider的爬虫,使用起来和使用链接提取器时候完全一致,链接提取器我在之前已经讲过如何使用,这里就不在赘述。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class A阳光问政Spider(CrawlSpider):
name = '阳光问政'
allowed_domains = ['wz.sun0769.com']
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']
rules = (
# 翻页链接提取(follow:用于重复提取,从提取的新页面中继续寻找符合当前要求的页面)
Rule(LinkExtractor(allow=r'wz.sun0769.com/political/index/politicsNewest\?id=1&page=\d+'), follow=True),
# 详情链接提取(callback:将提取到的详情页面传入parse_item方法进行处理)
Rule(LinkExtractor(allow=r'wz.sun0769.com/political/politics/index\?id=\d+'), callback='parse_item'),
)
def parse_item(self, response):
item = {}
item['标题'] = response.xpath('//p[@class="focus-details"]/text()').extract()
item['内容'] = response.xpath('//div[@class="details-box"]/pre/text()').extract()
item['配图'] = response.xpath('//div[@class="mr-three"]/div[3]/img/@src').extract()
return item
此爬虫跑起来后,在redis数据库中即会出现数据。
RedisCrawlSpider
接下来我们来看一看继承了RedisCrawlSpider方法的分布式爬虫,这个爬虫和CrawlSpider不同处在于初始URL也被放入了我们的redis中,项目启动后,会自动从reids中提取初始URL而非在项目中的start_urls。
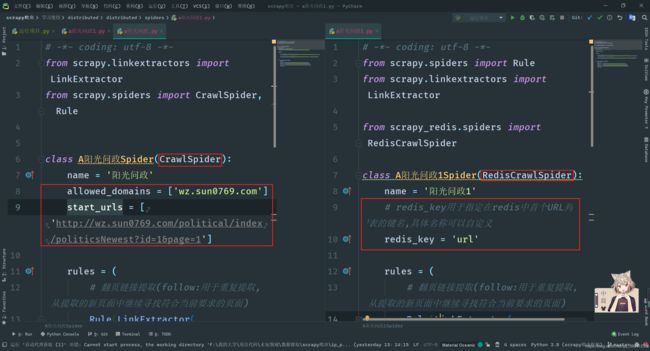
如上图所示,因为无需在从爬虫中获取首个URL地址,所以start_urls,我们就不在需要了,redis_key用于指定在redis中首个URL队列的键名,首个URL队列,我们在redis也需要一个列表。使用lpush 键名 url即可创建一个url列表。如果启动项目时没有添加首个URL队列,项目将会停止等待,一旦添加首个URL列表后,项目会自动开始抓取数据。
# -*- coding: utf-8 -*-
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from scrapy_redis.spiders import RedisCrawlSpider
class A阳光问政1Spider(RedisCrawlSpider):
name = '阳光问政1'
# redis_key用于指定在redis中首个URL列表的键名,具体名称可以自定义
redis_key = 'url'
rules = (
# 翻页链接提取(follow:用于重复提取,从提取的新页面中继续寻找符合当前要求的页面)
Rule(LinkExtractor(allow=r'wz.sun0769.com/political/index/politicsNewest\?id=1&page=\d+'), follow=True),
# 详情链接提取(callback:将提取到的详情页面传入parse_item方法进行处理)
Rule(LinkExtractor(allow=r'wz.sun0769.com/political/politics/index\?id=\d+'), callback='parse_item'),
)
def parse_item(self, response):
item = {}
item['标题'] = response.xpath('//p[@class="focus-details"]/text()').extract()
item['内容'] = response.xpath('//div[@class="details-box"]/pre/text()').extract()
item['配图'] = response.xpath('//div[@class="mr-three"]/div[3]/img/@src').extract()
return item
redis_key中的url同样使用pop形式获取,获得的数据会从队列中删除。
除了使用redis_key来指定url存放地址外,你还可以在设置中的REDIS_START_URLS_KEY指定初始url队列地址
如果你可能会在初始url队列中添加大量url可以使用REDIS_START_URLS_AS_SET,启动此设置后,队列会变成集合的形式,添加语句变为sadd 键名 url,集合的形式会自动去重,但集合是无序的!!!
RedisSpider
最后,我们介绍一下RedisSpider,和RedisCrawlSpider不同的是这种分布式爬虫没有了数据提取队列。也最接近我们写的普通爬虫,其中首个url队列和RedisCrawlSpider相同,都将其添加到了数据库中。
这里因为没有了便捷的链接提取器,我们需要自行提取连接,所以代码量比上述两种方式略大。
# -*- coding: utf-8 -*-
from scrapy_redis.spiders import RedisSpider
class A阳光问政2Spider(RedisSpider):
name = '阳光问政2'
redis_key = 'url'
def parse(self, response):
# print(SQL_HOST)
# print(self.settings.get('SQL_HOST'))
tr_data = response.xpath('//div[@class="width-12"]/ul[@class="title-state-ul"]/li/span[3]/a')
for tr in tr_data:
data = {}
data['标题'] = tr.xpath('./text()').extract_first()
data['详情URL'] = tr.xpath('./@href').extract_first()
data['详情URL'] = "http://wz.sun0769.com" + data['详情URL']
yield response.follow(
url=data['详情URL'],
callback=self.details_parse,
meta={'data': data}
)
next_url = "http://wz.sun0769.com" + response.xpath(
'//div[@class="width-12"]/div[3]/a[2]/@href').extract_first()
yield response.follow(
url=next_url,
callback=self.parse
)
def details_parse(self, response):
data = response.meta.get('data')
data['内容'] = response.xpath('//div[@class="details-box"]/pre/text()').extract()
img = response.xpath('//div[@class="mr-three"]/div[3]/img/@src').extract()
# 视频暂时无法加载出来
# video = supporting.xpath('//div[@class="mr-three"]/div[3]/div/div/div/video/@src').extract()
if img:
data['配图'] = img
# if video:
# data['视频'] = video
yield data