CDH6.3.0 报错汇总
文章目录
- - Cloudera 建议将 /proc/sys/vm/swappiness 设置为最大值 10
- - 已启用透明大页面压缩,可能会导致重大性能问题。
- - JDBC driver cannot be found. Unable to find the JDBC database jar on host
- - 存在隐患 : 9 DataNodes are required for the erasure coding policies: RS-6-3-1024k.
- - 不良 : 该主机与 Cloudera Manager Server 失去联系的时间过长。
- - Redaction rules file doesn't exist
- - 不良 : 群集中有 1,972 个 副本不足的块 块。群集中共有 1,977 个块。百分比 副本不足的块: 99.75%。 临界阈值:40.00%。
- - 不良 : 此 DataNode 未连接到其一个或多个 NameNode。
- - not enough live tablet servers to create a table with the requested replication factor 3; 1 tablet servers are alive
- - impala-shell -f 脚本失败
- - impala并发执行查询SQL报错
- Cloudera 建议将 /proc/sys/vm/swappiness 设置为最大值 10
- Cloudera 建议将 /proc/sys/vm/swappiness 设置为最大值 10。当前设置为 30。使用 sysctl 命令在运行时更改该设置并编辑 /etc/sysctl.conf,以在重启后保存该设置。您可以继续进行安装,但 Cloudera Manager 可能会报告您的主机由于交换而运行状况不良。

临时生效:
sysctl vm.swappiness=10 && cat /proc/sys/vm/swappiness
永久生效:
echo 'vm.swappiness=10'>> /etc/sysctl.conf
- 已启用透明大页面压缩,可能会导致重大性能问题。
- 已启用透明大页面压缩,可能会导致重大性能问题。请运行“echo never > /sys/kernel/mm/transparent_hugepage/defrag”和“echo never > /sys/kernel/mm/transparent_hugepage/enabled”以禁用此设置,然后将同一命令添加到 /etc/rc.local 等初始化脚本中,以便在系统重启时予以设置。

临时生效:
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
永久生效:
echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' >> /etc/rc.local
echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local
- JDBC driver cannot be found. Unable to find the JDBC database jar on host
- JDBC driver cannot be found. Unable to find the JDBC database jar on host : gateway.cdh.
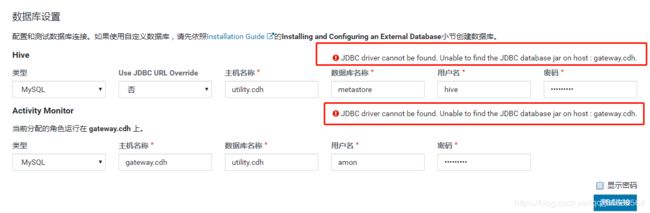
解决方案
给这台主机安装MySQL JDBC驱动
mkdir -p /usr/share/java/ \
&& wget -O /usr/share/java/mysql-connector-java-5.1.48.tar.gz \
https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.48.tar.gz \
&& cd /usr/share/java/;tar -zxvf mysql-connector-java-5.1.48.tar.gz \
&& cp /usr/share/java/mysql-connector-java-5.1.48/mysql-connector-java-5.1.48-bin.jar /usr/share/java/mysql-connector-java.jar \
&& rm -rf /usr/share/java/mysql-connector-java-5.1.48/ \
&& rm -rf /usr/share/java/mysql-connector-java-5.1.48.tar.gz \
&& ls /usr/share/java/
- 存在隐患 : 9 DataNodes are required for the erasure coding policies: RS-6-3-1024k.
- 存在隐患 : 9 DataNodes are required for the erasure coding policies: RS-6-3-1024k. The number of DataNodes is only 3.
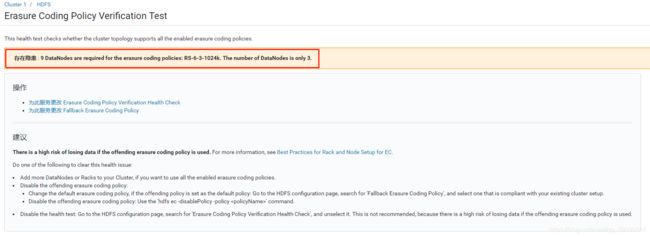
解决方案
使用RS-6-3-1024k编码纠删码策略至少需要9个DataNodes,当前只安装了3个,所以再增加6个DataNodes节点即可解决该问题。
修改编码纠删码策略同样也可以解决,不过会比较麻烦
- 不良 : 该主机与 Cloudera Manager Server 失去联系的时间过长。
解决方案
主机的NTP服务未开启,导致时间未同步,开启并重新同步服务器时间即可
systemctl start ntpd # 开启
systemctl status ntpd # 查看状态
systemctl enable ntpd # 设置开机自启
ntpdate -u 0.cn.pool.ntp.org #同步时间
同步时间后还是报错,可以考虑重启下服务器。
- Redaction rules file doesn’t exist
报错详情:
启动Cloudera Management Service服务时,各角色日志报错
[14/Nov/2019 10:17:16 +0000] 23674 MainThread redactor ERROR Redaction rules file doesn't exist, not redacting logs. file: redaction-rules.json, directory: /run/cloudera-scm-agent/process/342-cloudera-mgmt-SERVICEMONITOR
进入服务器查看/var/log/cloudera-scm-firehose/mgmt-cmf-mgmt-SERVICEMONITOR-tools.cdh.log.out日志时,发现详细报错
2019-11-14 10:48:29,931 ERROR com.cloudera.cmon.tstore.leveldb.LDBPartitionManager: Failed to open or create partition
com.cloudera.cmon.tstore.leveldb.LDBPartitionManager$LDBPartitionException: Unable to open DB in directory /var/lib/cloudera-service-monitor/ts/type/partitions/type_2019-11-08T18:14:12.168Z for partition LDBPartitionMetadataWrapper{tableName=type, partitionName=type_2019-11-08T18:14:12.168Z, startTime=2019-11-08T18:14:12.168Z, endTime=null, version=2, state=CLOSED}
解决方案
将/var/lib/cloudera-service-monitor目录改个名字,或者删掉,然后重启Cloudera Management Service即可。
- 不良 : 群集中有 1,972 个 副本不足的块 块。群集中共有 1,977 个块。百分比 副本不足的块: 99.75%。 临界阈值:40.00%。
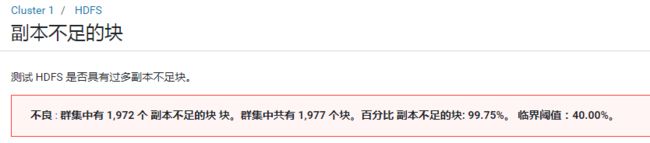
原因
原因是设置的副本备份数与DataNode的个数不匹配。dfs.replication属性默认是3,也就是说副本数—块的备份数默认为3份。
DataNode不足三个会提示这个错误。
解决方案
步骤一:找到dfs.replication属性,设置为与DataNode安装的数量一致。
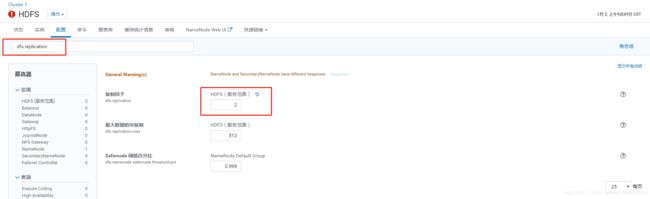
步骤二:通过命令更改备份数
在master主机上
sudo -u hdfs hadoop fs -setrep -R 2 /
- 不良 : 此 DataNode 未连接到其一个或多个 NameNode。
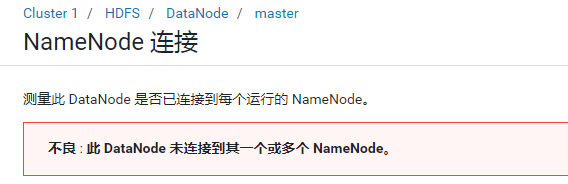
原因
详细的报错日志:
下午2点37:11.217分 ERROR DataNode
Initialization failed for Block pool BP-1320069028-192.168.1.31-1578636727309 (Datanode Uuid 0cf6e7cb-5bd8-4f97-92dc-74ee979a9b16) service to master.cdh/192.168.1.31:8022 Datanode denied communication with namenode because the host is not in the include-list: DatanodeRegistration(192.168.1.248:9866, datanodeUuid=0cf6e7cb-5bd8-4f97-92dc-74ee979a9b16, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=cluster10;nsid=124835555;c=1578636727309)
at org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager.registerDatanode(DatanodeManager.java:1035)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.registerDatanode(BlockManager.java:2315)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.registerDatanode(FSNamesystem.java:3777)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.registerDatanode(NameNodeRpcServer.java:1467)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolServerSideTranslatorPB.registerDatanode(DatanodeProtocolServerSideTranslatorPB.java:101)
at org.apache.hadoop.hdfs.protocol.proto.DatanodeProtocolProtos$DatanodeProtocolService$2.callBlockingMethod(DatanodeProtocolProtos.java:31658)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675)
看日志的意思是IP为192.168.1.31的master.cdh主机不在主机解析列表中。导致集群通讯失败。
解决方案
查看master.cdh主机的IP
[root@master ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:f6:d3:7a brd ff:ff:ff:ff:ff:ff
inet 192.168.1.248/24 brd 192.168.1.255 scope global noprefixroute dynamic ens192
valid_lft 1776sec preferred_lft 1776sec
inet 192.168.1.31/24 brd 192.168.1.255 scope global secondary noprefixroute ens192
valid_lft forever preferred_lft forever
inet6 fe80::e605:e475:3112:21d9/64 scope link noprefixroute
valid_lft forever preferred_lft forever
发现有两个IP,192.168.1.31是我之前设置的静态IP,192.168.1.248是系统自动生成的动态IP
修改网卡配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens192
将BOOTPROTO参数改为none
BOOTPROTO="none"
重启网卡
systemctl restart network
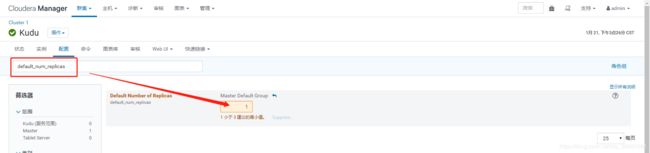
- not enough live tablet servers to create a table with the requested replication factor 3; 1 tablet servers are alive
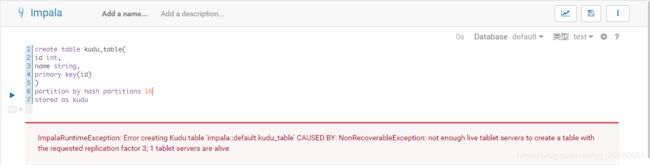
原因
Kudu的默认存储副本是3,而我只安装了一个tablet服务
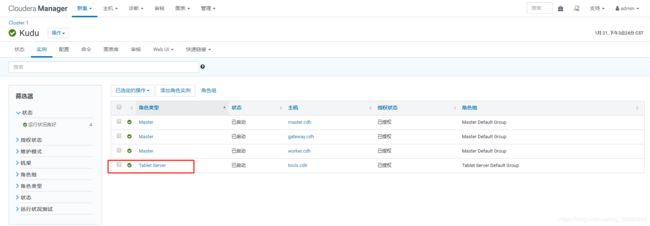
解决方案
所以修改Kudu的默认存储策略default_num_replicas为1,重启即可
注意修改为1之后,数据备份只会有一份,建议安装三个以上的tablet服务,备份策略为3,且个数只能是奇数
- impala-shell -f 脚本失败
报错详情
使用impala-shell -f 执行一个脚本向kudu表中插入数据,该脚本的内容是一百万条insert语句、大小是90M左右,执行了一会儿就报错了。
报错日志
ERROR: Memory limit exceeded: Could not allocate memory for KuduTableSink
KuduTableSink could not allocate 20.00 MB without exceeding limit.
Error occurred on backend gateway.cdh:22000 by fragment 2e4e42b84912de87:925e6af800000000
Memory left in process limit: 13.97 MB
解决方案
字面意思猜测是impala的KuduTableSink组件,使用的文件大小有限制为20M,所以修改impala的Maximum Cached File Handles配置多加几个0,保证大于读取的sql脚本文件大小。

也有人说修改这个配置,不过我没试。不知道行不行的通。
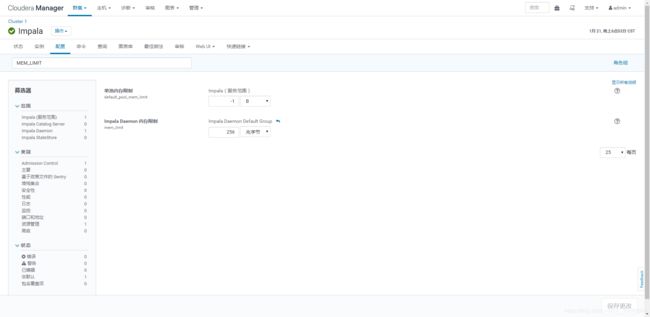
- impala并发执行查询SQL报错
报错详情
写了一个死循环脚本,并发执行impala的查询功能,运行了三分钟报错停止
报错日志
Could not execute command: select * from kudu_big_data_test t where t.name='test4' and t.age=14
Starting Impala Shell without Kerberos authentication
Opened TCP connection to gateway.cdh:21000
Connected to gateway.cdh:21000
Server version: impalad version 3.2.0-cdh6.3.0 RELEASE (build 495397101e5807c701df71ea288f4815d69c2c8a)
Query: select * from kudu_big_data_test t where t.name='test4' and t.age=14
Query submitted at: 2020-01-22 09:30:16 (Coordinator: http://gateway.cdh:25000)
Query progress can be monitored at: http://gateway.cdh:25000/query_plan?query_id=314d3442ff4461af:2e2c186500000000
ERROR: ExecQueryFInstances rpc query_id=314d3442ff4461af:2e2c186500000000 failed: Memory limit exceeded: Query 314d3442ff4461af:2e2c186500000000 could not start because the backend Impala daemon is over its memory limit
Error occurred on backend master.cdh:22000
Memory left in process limit: -104.70 MB
Process: memory limit exceeded. Limit=256.00 MB Total=360.70 MB Peak=760.13 MB
Buffer Pool: Free Buffers: Total=0
Buffer Pool: Clean Pages: Total=0
Buffer Pool: Unused Reservation: Total=0
Control Service Queue: Limit=50.00 MB Total=0 Peak=160.00 B
Data Stream Service Queue: Limit=12.80 MB Total=0 Peak=0
Data Stream Manager Early RPCs: Total=0 Peak=0
TCMalloc Overhead: Total=39.69 MB
RequestPool=root.admin: Total=0 Peak=18.30 MB
RequestPool=root.root: Total=0 Peak=570.23 KB
解决方案
又是impala的内存限制,修改impala的配置,提高限制大小