图像检索传统算法学习笔记
-
图像检索领域传统算法学习笔记
(与组内同学一起找到的一些图像检索传统算法,作一小结,以防忘记)
性能统计:
| 传统图像检索算法 |
CIFAR-10数据集mAP值(编码数不同) |
| LSH局部敏感哈希 |
0.116-0.131 |
| SH谱哈希 |
0.124-0.126 |
| ITQ迭代量化 |
0.162-0.175 |
| SDH监督离散哈希 |
0.255-0.360 |
| BRE |
0.343-0.421 |
| KSH |
0.382-0.439 |
| VLAD局部聚合向量 |
- |
| PQ乘积量化 |
- |
| SIFT |
- |
| K-D树 |
- |
| 深度图像检索算法 |
CIFAR-10数据集mAP值(编码数不同) |
| DBH深度二进制哈希 |
0.891-0.894 |
| DSH深度监督哈希 |
0.615-0.676 |
传统算法原理介绍:
- LSH局部敏感哈希:
LSH(Locality Sensitive Hashing)翻译成中文,叫做“局部敏感哈希”,它是一种针对海量高维数据的快速最近邻查找算法。
在信息检索,数据挖掘以及推荐系统等应用中,我们经常会遇到的一个问题就是面临着海量的高维数据,查找最近邻。如果使用线性查找,那么对于低维数据效率尚可,而对于高维数据,就显得非常耗时了。为了解决这样的问题,人们设计了一种特殊的hash函数,使得2个相似度很高的数据以较高的概率映射成同一个hash值,而令2个相似度很低的数据以极低的概率映射成同一个hash值。我们把这样的函数,叫做LSH(局部敏感哈希)。LSH最根本的作用,就是能高效处理海量高维数据的最近邻问题。
定义如下:
我们将这样的一族hash函数 H={h:S→U}称为是(r1,r2,p1,p2)敏感的,如果对于任意H中的函数h,满足以下2个条件:
如果d(O1,O2) 如果d(O1,O2)>r2,d(O1,O2)>r2,那么Pr[h(O1)=h(O2)]≤p2,Pr[h(O1)=h(O2)]≤p2 其中,O1,O2∈S表示两个具有多维属性的数据对象,d(O1,O2)为2个对象的相异程度,也就是1 - 相似度。其实上面的这两个条件说得直白一点,就是当足够相似时,映射为同一hash值的概率足够大;而足够不相似时,映射为同hash值的概率足够小。 谱哈希将编码过程视为图分割过程,对高维数据集进行谱分析,将问题转化成拉普拉斯特征图的降维问题,从而求解得到图像数据的哈希编码。首先对高维数据样本集进行谱分析,在数据集服从高维平均分布的前提下给出哈希函数。通过主成分分析法对高维数据进行降维,得到各个维度互不相关的低维数据,进而对结果直接进行二元索引结果计算。 (1)采用主成分分析(PCA)算法获取图像数据的各个主成分方向; (2)在每个主成分方向计算特征值,并选取前r个最小的值,总共得到r * d个特征值,再将其按从小到大的顺序排序,取前r个最小的特征值,计算其对应的特征函数值; (3)将特征函数值在零点进行二元量化(sign函数)得到哈希编码。 主成分分析(PCA)算法中每个主成分方向上的方差是不同的,方差较大的主成分方向包含更多的信息,因此谱哈希为方差大的主成分方向分配更多的比特。 ITQ迭代量化的算法步骤为: (1)降维:在上述推导的指导下,先将数据从d维降到c维,然后使用随机旋转方法找个旋转矩阵R,大小为c*c(实际中可以先随机生成一个矩阵,然后做SVD分解,用S作为旋转矩阵),右乘到降维后的数据V,最小化目标式(2)求得一个粗糙解。下面开始应用ITQ算法迭代新R,使得目标式(2)的值减少。 (2)固定R,更新B: 因为矩阵V=XW是固定的,最小化(3)等价于最大化: (3)固定B,更新R:当B固定时先对矩阵做SVD分解为,更新R使得 (4)分支判断:迭代次数是否达到50次,如果没有,则回到第2步;如果达到了,就结束循环。计算最后得到的编码就是sgn(XWR),大小为n*c。 SDH监督离散哈希算法主要思想是主要思想有两点:首先通过将哈希码映射到label标签信息上,从而不需要通过计算相似性矩阵来将标签信息嵌入到哈希码生成过程当中;其次不对离散约束进行松弛,直接使用DCC算法在离散约束下按位求解哈希码。具体算法步骤如下: (1)输入:训练集 (2)随机从训练集中挑选出m个样本,计算出RBF核映射 (3)随机初始化B (4)循环以下过程直到收敛或者达到最大迭代次数: a.通过下式计算W: b.计算P,并构造出F(x): c.使用DCC方法求解 (5)输出:二进制码 KSH算法是一种基于监督学习和核的Hash算法。利用kernel主要是为了解决线性不可分问题,监督学习则是为了学习到更有区分度的hash值,使得我们可以直接使用hash后的value作为特征,大大降低特征维数。 (1) hash函数的生成 该算法首先随机选取了M个样本(anchor),之后构造了如下式的prediction函数: 上式中,k代表核函数(论文选择了高斯径向基kernel),得到f(x)后,哈希函数h(x) = sgn(f(x)) 。上式中参数主要是a(b可以化解掉),也是监督学习的目标。注意,上式只生成了一个bit的hash value,若生成r bit 特征,那么就需要训练r次,生成r组a参数(论文中逐bit生成参数a)。 (2) 目标函数 在训练中,文章选择的目标函数是在汉明空间,最大化类间距离、最小化类内距离。但是在实现方式上,由于汉明距离数学表达上的不方便,采用了code inner products的方式来计算汉明距离: (3)优化算法 由于不同bit hash函数是相互独立的,且总得代价函数值是有每一bit代价函数值相加得来的,因此如果我们使每一bit的代价函数取得最小值,那么就可以得到总得最优解;论文中采用贪婪算法,逐位采用梯度下降求解最优解 即局部聚合向量。是一种利用图像的局部描述子如:SIFT、SURF、ORB等,做一些聚合的操作,然后用一个长向量来表征一幅图像的过程。把图像表征成向量,是图像检索的先决条件。因为,图像检索的思想是对查询图像和检索库中的图像做相似性度量,然后输出相似性最大的值,数学本质是向量间的相似性度量。 当然也可以用两幅图像直接进行相似度量,比如像素值做差或者是计算颜色直方图的分布的相似性,这样的操作对于小数据可以,但是对于大型数据,首先是存储图像需要很大的空间,其次是这样做的检索速度太慢。 VLAD算法流程: (1)提取图像的SIFT描述子; (2)利用提取到的SIFT描述子(是所有训练图像的SIFT)训练一本码书,训练方法是K-means; (3)把一幅图像所有的SIFT描述子按照最近邻原则分配到码数上(也就是分配到k个聚类中心); (4)对每个聚类中心做残差和(即属于当前聚类中心的所有SIFT减去聚类中心然后求和); (5)对这个残差和做L2归一化,然后拼接成一个K*128的长向量。128是单条SIFT的长度. 即乘积量化,是一种编码方法。当图像数据库过于庞大的时候,直接存储所有的数据并且做相似性度量检索是不现实的。为了能减少存储资源的开销,并且提高检索的效率,必须对原始数据做一些瘦身操作。其中包括提取图像的特征向量和对提取出的特征向量进行编码。 我们可能并不需要图像中的所有信息就可以判断它是否是我们的目标图像。比如,要想知道一幅图中是否有猫,只需要在图中找到猫的特征就可以证明猫的存在。提取图像中的特征向量有很多成熟的算法,如SIFT、SURF、ORB等。传统的图像检索方法,如VLAD、BOF等都是针对小数据集的,而为了能够实现海量数据的检索,PQ是一个很理想的方法。哈希算法也是一个很不错的算法,但是空间复杂度过高,它只能产生少量的明确距离。 SIFT算法即尺度不变特征变换是一种广泛应用的传统图像特征提取算法,其特点有: 算法具体步骤: (1)尺度空间的极值检测 搜索所有尺度空间上的图像,通过高斯微分函数来识别潜在的对尺度和选择不变的兴趣点。 (2)删除不稳定的极值点:主要删除两类:低对比度的极值点以及不稳定的边缘响应点。 (3)确定特征点的主方向:以特征点的为中心、计算一定的半径领域内各个像素点的梯度的幅角和幅值,然后使用直方图对梯度的幅角进行统计。直方图的横轴是梯度的方向,纵轴为梯度方向对应梯度幅值的累加值,直方图中最高峰所对应的方向即为特征点的方向。 (4)生成特征点的描述子:首先将坐标轴旋转为特征点的方向,以特征点为中心的16×16的窗口的像素的梯度幅值和方向,将窗口内的像素分成16块,每块是其像素内8个方向的直方图统计,共可形成128维的特征向量。 在图像检索任务中,当我们构造了多个特征时,可用K-D树检索方法来进行快速匹配。K-D树算法通过每次寻找所有数据方差最大的维度作为判别标准进行树的构造,中位数作为节点,小于节点的在左子树,大于在右子树,之后对每个子树也相同。 查找过程:将查询数据Q从根节点开始,按照Q与各个节点的比较结果向下遍历,直到到达叶子节点为止。到达叶子节点时,计算Q与叶子节点上保存的所有数据之间的距离,记录最小距离对应的数据点,假设当前最邻近点为p_cur,最小距离记为d_cur。进行回溯操作,该操作的目的是找离Q更近的数据点,即在未访问过的分支里,是否还有离Q更近的点,它们的距离小于d_cur。
基本算法流程是:
最终的图像检索就是通过二进制编码的汉明距离来进行匹配。

![]()
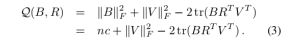
![]()
![]() 。
。
![]() ,编码长度L,锚点数量m,最大迭代次数t,参数λ和v。
,编码长度L,锚点数量m,最大迭代次数t,参数λ和v。![]()
![]()
![]()
![]() ,和哈希函数H(x)=sgn(F(x))。
,和哈希函数H(x)=sgn(F(x))。



