Centos 7 Hadoop3.x HA 高可用搭建教程
Centos7 Hadoop3.x HA 高可用搭建教程
什么是HDFS高可用?
1.NameNode存在单点失效问题,如果NameNode失效了,那么所有的客户端和mapreduce均无法读写文件,因为NameNode是唯一存储元数据与文件到数据块映射的地方。HDFS高可用是配置了一对活动-备用(active-standby) 的NameNode,当活动的NameNode挂掉时,备用NameNode就会接管它的任务并开始服务于来自客户端的请求,不会有任何明显的中断。
Hadoop3.x高可用架构图
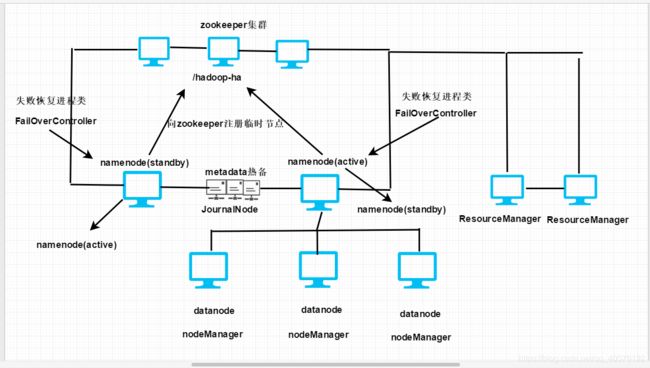
在这里解释一下每个角色:
1.NameNode:两个名称节点,有active和standby两种状态。
2.JournalNode:用于共享edits文件,不但会给standby主机发一份,自己也会存一份。借此来做元数据的实时热备,这里JN也是个集群。
3.Zookeeper:zookeeper究竟是怎么监控各个主机的状态的?答案是通过监测临时节点,当我们启动集群时,会向zookeeper中注射一个节点:hadoop-ha,每个namenode启动时都会向该节点下注射自己的临时节点信息,如果该节点信息消失,那么zookeepr就知道这台主机挂掉了。所以zookeeper在Hadoop HA环境下的主要任务是用来做主备切换。
4.失败恢复进程类(FailOverController):zookeeper一旦检测到有active主机挂掉,就会通知standby状态的主机中的该进程,把standby转换为active,继续进行服务。而已经挂掉的那台不能让它一直宕机,我们需要单独启动,启动后状态会由active转变为standby。
5.NodeManager:该进程为要启动的任务准备好运行环境,并且将启动命令写在一个脚本中来运行。NodeManager会通过心跳信息向ResourceManager汇报自己所在节点的资源使用情况。
6.ResourceManager:该进程完成整个集群的资源管理和调度。
7.从上可以看出,搭建一个完整的HA系统,最少要14台主机。
但是在这里我们使用三台虚拟机完成Hadoop HA的搭建
以下简单操作需自行完成:
1.这里默认你的三台虚拟机安装好jdk1.8配好环境变量并且可以使用。
2.要熟悉基本的linux操作。
3.安装好Hadoop-3.1.2配好环境变量。
4.安装好zookeeper-3.4.6。
5.给自己的三台主机host改名为master,slave1,slave2
(三台主机都要有环境)
Hadoop核心配置文件介绍
| 文件名称 | 描述 |
|---|---|
| hadoop-env.sh | 脚本中要用到的环境变量,以运行hadoop |
| mapred-env.sh | 脚本中要用到的环境变量,以运行mapreduce(覆盖hadoop-env.sh中设置的变量) |
| yarn-env.sh | 脚本中要用到的环境变量,以运行YARN(覆盖hadoop-env.sh中设置的变量) |
| core.site.xml | Hadoop Core的配置项,例如HDFS,MAPREDUCE,YARN中常用的I/O设置等 |
| hdfs-site.xml | Hadoop守护进程的配置项,包括namenode和datanode等 |
| mapred-site.xml | MapReduce守护进程的配置项,包括job历史服务器 |
| yarn-site.xml | Yarn守护进程的配置项,包括资源管理器和节点管理器 |
| workers | 具体运行datanode和节点管理器的主机名称 |
1.hadoop-env.sh配置
在文件结尾处添加:
export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
java_home配成你自己的路径即可。
2.core-site.xml配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/utils/hadoopdata</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
ns是集群的名称,hadoop.tmp.dir是存储临时数据的目录,ha.zookeeper.quorum下要配置zookeeper集群:主机名:2181,2181是zookeeper的默认端口,不要改。
3.hdfs-site.xml配置
<configuration>
<!-- 与前面配置的匹配-->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!--给两个namenode起别名nn1,nn2这个名字不固定,可以自己取 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!--nn1的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:8020</value>
</property>
<!-- nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:9870</value>
</property>
<!--nn2的rpc通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>slave1:8020</value>
</property>
<!--nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>slave1:9870</value>
</property>
<!--设置共享edits文件夹:告诉集群哪些机器要启动journalNode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/wen</value>
</property>
<!-- journalnode的edits文件存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/utils/journal</value>
</property>
<!--该配置开启高可用自动切换功能 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置切换的实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</value>
</property>
<!--配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--生成的秘钥所存储的目录 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置namenode存储元数据的目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/utils/namenode
</property>
<!-- 配置datanode存储数据块的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/utils/datanode
</property>
<!--指定block副本数为3,该数字不能超过主机数。 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置hdfs的操作权限,设置为false表示任何用户都可以在hdfs上操作并且可以使用插件 -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4.mapred-site.xml配置
<configuration>
<!---指定mapreduce运行在yarn上->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.yarn-site.xml配置
<configuration>
<!-- Site specific YARN configuration properties -->
<!--开启YARN HA-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--两个ResourceManager起个名字rm1和rm2-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--rm1的主机名称-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<!--rm2的主机名称-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave2</value>
</property>
<!--开启yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--执行rm恢复机制的实现类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--把zookeeper地址配置一下-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<!--指定yarn ha的名称-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
</property>
<!--指定yarn的老大,resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--NodeManager获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定rm1 web监听主机地址-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:8088</value>
</property>
<!--指定rm2 web监听主机地址-->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>slave2:8088</value>
</property>
<!--这个配置如果没有在使用MapReduce时会报错误: 找不到或无法加载主org.apache.hadoop.mapreduce.v2.app.MRAppMaster-->
<!--底下的路径要根据自己的情况改-->
<!--在命令行下输入如下命令 hadoop classpath,并将返回的地址复制到value中。-->
<property>
<name>yarn.application.classpath</name>
<value>/usr/utils/hadoop-3.1.2/etc/hadoop:/usr/utils/hadoop-3.1.2/share/hadoop/common/lib/*:/usr/utils/hadoop-3.1.2/share/hadoop/common/*:/usr/utils/hadoop-3.1.2/share/hadoop/hdfs:/usr/utils/hadoop-3.1.2/share/hadoop/hdfs/lib/*:/usr/utils/hadoop-3.1.2/share/hadoop/hdfs/*:/usr/utils/hadoop-3.1.2/share/hadoop/mapreduce/lib/*:/usr/utils/hadoop-3.1.2/share/hadoop/mapreduce/*:/usr/utils/hadoop-3.1.2/share/hadoop/yarn:/usr/utils/hadoop-3.1.2/share/hadoop/yarn/lib/*:/usr/utils/hadoop-3.1.2/share/hadoop/yarn/*
6.配置masters和slaves
masters文件里写上自己的主机名,在我这里是写 master
slaves文件中写上具体干活的节点,在我这里是写 master ,slave1,slave2
7.配置workers
在workers文件中写
master
slave1
slave2
至此配置文件全部完成,现在来尝试启动HA集群。
1.首先在三台电脑上启动zookeeper
sh zkServer.sh start
启动结果如下图:

我们使用命令:
sh zkServer.sh status
查看到底启动成功没有,三台机器上出现下图 Mode:xxx 字样则表示启动成功。

使用jps查看会有如下进程:
2.接下来我们一步步启动HA所需要的进程
a.使用命令
hdfs --daemon start journalnode
查看jps出现该进程表示启动成功:
b.使用命令对初次集群要对namenode进行格式化:
hdfs namenode -format
如果格式化成功,会在输出的信息上存在namenode has been successfully formatted字样,表示格式化成功。
c.使用命令启动namenode:
hdfs --daemon start namenode
出现下图进程表示启动成功:
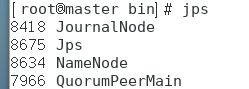
d.在第二台主机上输入命令:
hdfs namenode -bootstrapStandby
如果成功还是会有namenode has been successfully formatted字样存在。
e.在第二台使用命令:
hdfs --daemon start namenode
使用jps查看进程,出现以下表示第二台namenode启动成功:
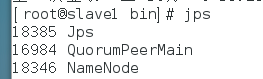
f.两个namenode启动完成后,接着给三台主机都启动datanode,使用命令:
hdfs --daemon start datanode
启动完毕后使用jps查看三台主机进程,都有DataNode进程表示成功启动
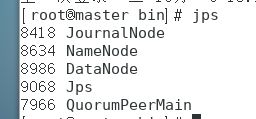
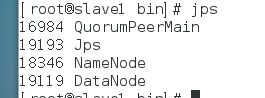
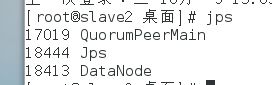
g.格式化ZKFC,使用命令:
hdfs zkfc -formatZK
h.启动ZKFC,使用命令:
hdfs --daemon start zkfc
注意,这个命令master和slave1主机上都要跑一边,确保两台可以看到DFSZKFailoverController如下进程才算启动成功:
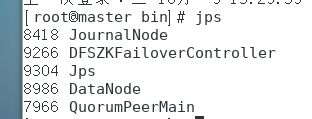

这时我们的HA已经搭建完成了,我们使用命令:
stop-all.sh
结束所有运行的进程。
使用
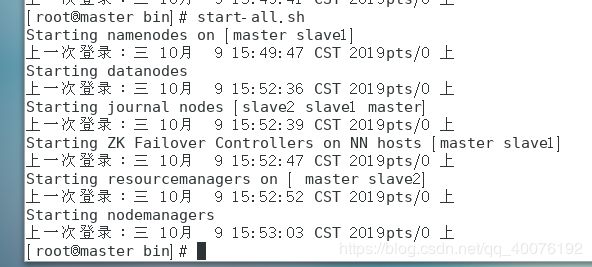
start-all.sh
启动所有的进程,如果启动成功,会输出如下信息:
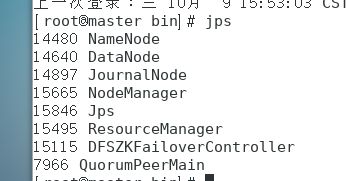
通过jps查看进程,如图master主机上一个都不能少:
slave1主机上如图:

slave2主机上如图:

至此Hadoop HA搭建完成
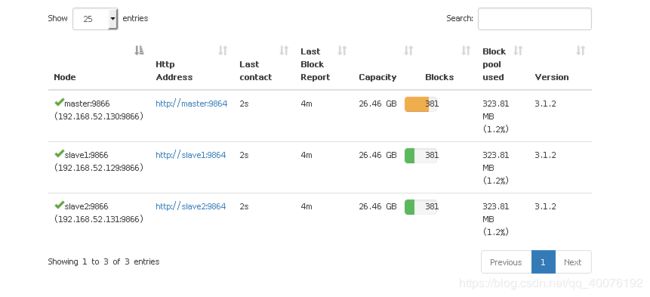
验证:打开浏览器访问master:9870 会有如下页面
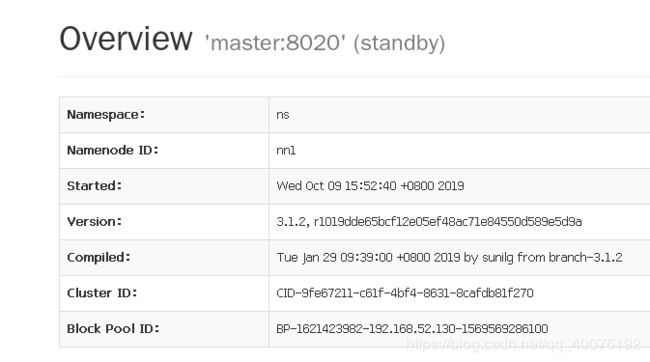
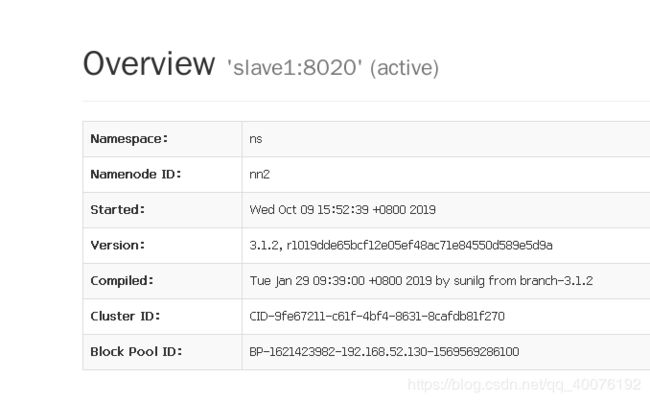
网页上选择datanodes选项可以看到: