【信息检索】Java简易搜索引擎原理及实现(四)利用布尔模型和向量模型计算权值
上一篇文章 :【信息检索】Java简易搜索引擎原理及实现(三)B+树索引和轮排索引结构,我们在倒排索引的基础上,引入了B+树索引和轮排索引,以支持通配符的模糊查询方式。
本篇主要是掌握和测试布尔模型和向量模型在信息检索中应用的基本方法,计算出一些参数值,辅助搜索引擎去对最终各查询结果计算权值,排序。
首先介绍几个概念:
1. df(document frequency):总文档中包含每个 term 的文档数
2. tf(term frequency):每个 term 在每个文档中词频数
3. wf(weighting term frequency):根据 tf 计算 term 的权值
wf 计算公式:
![]()
4. tf × idf:综合df 和tf 的值,实际是利用此参数计算出的权值作为term项在一个文档中的权值
其中,idf:inverse document frequency
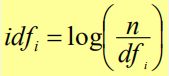
因此,由tf × idf计算出来的wf如下:

上述是利用tf来计算出的tf × idf值,其实还有一种是利用wf来计算的wf × idf值,它们的公式类似,只是把tf 的部分更换为 wf。wf × idf是归一化后的tf × idf值,wf × idf对于低出现次数和高出现次数的term在一个文档中的权值把控得更好。
5.余弦相似:利用两个向量之间的夹角的余弦值,来表示两个向量间的相似度。
因此,我们可扩展出两个文档j和k之间的相似度计算公式:
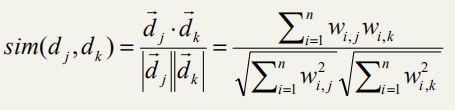
其中,wi,j 代表term项 i 在文档 j 中的tf × idf值或wf × idf值。
利用这个公式,我们可以搜索出和一个文档相似的其他文档。
同时,利用余弦相似的概念,也可扩展出查询向量q和文档j之间的相似度计算公式:

有了这个公式,我们就可以根据用户输入的查询词来计算出每个文档与之的相似度,然后根据相似度按从大到小的顺序来对查询出的文档排序了。
需要注意的是,为了提高计算的速度,我们在实际计算中,是不计算分母的值的,因此我们算出的相似度只由分子构成,它不是一个0~1之间的值,但可用其来衡量相似度。
下面我们就进入实验环节:
因为此部分数据量较大,我们算出的数据需存入数据库中,需要在本地连接mysql数据库。
1.统计文档总数 N
统计在总文档中包含每个 term 的文档数 df。如表 1 所示
Table 1:
| term | df |
|---|---|
| car | 18165 |
| auto | 6723 |
| insurance | 19241 |
| best | 25235 |
统计每个 term 在每个文档中词频数 tf。如表 2 所示
Table 2: (3 个文档中的 tf)
| term \tf\ | Doc1 | Doc2 | Doc3 |
|---|---|---|---|
| car | 27 | 4 | 24 |
| auto | 3 | 33 | 0 |
| insurance | 0 | 23 | 29 |
| best | 14 | 0 | 17 |
统计结果均存入数据库,输出格式按表格1或表格2形式。
统计在总文档中包含每个 term 的文档数 df,并执行插入sql语句(表结构就按上述表格的方式建立,此处假定已建好数据库表):
//统计在总文档中包含每个 term 的文档数 df,并执行插入sql语句
private void insertDf(LinkedList<Item> dictionary, Connection con) {
Statement statement = null;
String sql = "insert into term_df values (";
try {
statement = con.createStatement();
long startTime = System.currentTimeMillis(); //获取开始时间
for (Item item : dictionary) {
statement.addBatch(sql + "'" + item.term + "'," + item.docs + ");");
}
statement.executeBatch();
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("df统计及执行sql总时间:" + (double)(endTime - startTime)/1000 + "s"); //输出时间
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
//获取数据库连接
private static Connection getConnection() {
Connection con = null;
try {
Class.forName("com.mysql.jdbc.Driver");//加载数据库驱动类
System.out.println("数据库驱动加载成功");
} catch(ClassNotFoundException e) {
e.printStackTrace();
}
try {
con = DriverManager.getConnection("jdbc:mysql:"+"//127.0.0.1:3306/coseir","root","123456");//通过访问数据库的URL获取数据库连接对象
System.out.println("数据库连接成功");
} catch(SQLException e) {
e.printStackTrace();
}
return con;//按方法要求返回一个Connection对象
}
统计每个 term 在每个文档中词频数 tf,并执行插入sql语句:
private void insertTf(LinkedList<Item> dictionary, Connection con) {
Statement statement = null;
String sql = "insert into term_tf values (";
try {
statement = con.createStatement();
long startTime = System.currentTimeMillis(); //获取开始时间
for (Item item : dictionary) {
StringBuilder str = new StringBuilder(sql + "'" + item.term + "'");
int id = 1;
for (Item_ori item_ori : item.ori_item_list) {
while (id < item_ori.docId) {
str.append(",0");
id++;
}
str.append(",").append(item_ori.freq);
id = item_ori.docId + 1;
}
while (id <= N) {
str.append(",0");
id++;
}
str.append(");");
statement.addBatch(str.toString());
}
statement.executeBatch();
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("tf统计及执行sql总时间:" + (double)(endTime - startTime)/1000 + "s"); //输出时间
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
2.计算每个term项的idf、tf × idf:
每个term的idft值,计算结果存入数据库,输出格式按表格1形式。
每个term在每个文档中的wi,j权值,计算结果存入数据库,输出格式按表格2形式。
idf计算:
//统计在每个term的idf值,并执行插入sql语句
private void insertIdf(LinkedList<Item> dictionary, Connection con) {
Statement statement = null;
String sql = "insert into term_idf values (";
try {
statement = con.createStatement();
long startTime = System.currentTimeMillis(); //获取开始时间
for (Item item : dictionary) {
statement.addBatch(sql + "'" + item.term + "'," + Math.log(N / item.docs) / Math.log(10) + ");");
}
statement.executeBatch();
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("idf统计及执行sql总时间:" + (double)(endTime - startTime)/1000 + "s"); //输出时间
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
tf × idf 计算:
//统计每个term在每个文档中的wi,j权值(利用tf计算),并执行插入sql语句
private void insertWeight_tf(LinkedList<Item> dictionary, Connection con) {
Statement statement = null;
String sql = "insert into term_weight_tf values (";
try {
statement = con.createStatement();
long startTime = System.currentTimeMillis(); //获取开始时间
for (Item item : dictionary) {
StringBuilder str = new StringBuilder(sql + "'" + item.term + "'");
int df = item.docs;
int id = 1;
for (Item_ori item_ori : item.ori_item_list) {
while (id < item_ori.docId) {
str.append(",0");
id++;
}
str.append(",").append(item_ori.freq * Math.log(N / df) / Math.log(10));
id = item_ori.docId + 1;
}
while (id <= N) {
str.append(",0");
id++;
}
str.append(");");
statement.addBatch(str.toString());
}
statement.executeBatch();
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("Wi,j权值(利用tf)统计及执行sql总时间:" + (double)(endTime - startTime)/1000 + "s"); //输出时间
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
3.计算每个term的wf值。注意:wf值是对tf值进行归一化处理的一种方法之一。
利用wf值,重新计算每个term在每个文档中的Wi,j权值。 计算结果存入数据库,输出格式按表格2形式。
//统计每个 term 在每个文档中词频数 wf(归一化的tf),并执行插入sql语句
private void insertWf(LinkedList<Item> dictionary, Connection con) {
Statement statement = null;
String sql = "insert into term_wf values (";
try {
statement = con.createStatement();
long startTime = System.currentTimeMillis(); //获取开始时间
for (Item item : dictionary) {
StringBuilder str = new StringBuilder(sql + "'" + item.term + "'");
int id = 1;
for (Item_ori item_ori : item.ori_item_list) {
while (id < item_ori.docId) {
str.append(",1");
id++;
}
str.append(",").append(1 + Math.log(item_ori.freq) / Math.log(10));
id = item_ori.docId + 1;
}
while (id <= N) {
str.append(",1");
id++;
}
str.append(");");
statement.addBatch(str.toString());
}
statement.executeBatch();
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("wf统计及执行sql总时间:" + (double)(endTime - startTime)/1000 + "s"); //输出时间
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
//统计每个term在每个文档中的Wi,j权值(利用wf计算),并执行插入sql语句
private void insertWeight_wf(LinkedList<Item> dictionary, Connection con) {
Statement statement = null;
String sql = "insert into term_weight_wf values (";
try {
statement = con.createStatement();
long startTime = System.currentTimeMillis(); //获取开始时间
for (Item item : dictionary) {
StringBuilder str = new StringBuilder(sql + "'" + item.term + "'");
int df = item.docs;
int id = 1;
for (Item_ori item_ori : item.ori_item_list) {
while (id < item_ori.docId) {
str.append(",1");
id++;
}
str.append(",").append((1 + Math.log(item_ori.freq) / Math.log(10)) * Math.log(N / df) / Math.log(10));
id = item_ori.docId + 1;
}
while (id <= N) {
str.append(",1");
id++;
}
str.append(");");
statement.addBatch(str.toString());
}
statement.executeBatch();
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("Wi,j权值(利用wf)统计及执行sql总时间:" + (double)(endTime - startTime)/1000 + "s"); //输出时间
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
4.采用wi,j权值和Wi,j权值,利用余弦相似计算方法,分别计算任意两个文档向量之间的相似度。
注:wi,j是指由 tf 计算出的tf × idf值,Wi,j是由wf计算出的wf × idf值。
//利用余弦相似计算方法,计算任意两个文档向量之间的相似度
//mode==1表示利用wi,j计算,否则表示利用Wi,j计算
public static double calculateSim(int mode, int doc1, int doc2, Connection con) {
Statement statement = null;
try {
statement = con.createStatement();
String sql_1, sql_2;
if (mode == 1) {
sql_1 = "select doc" + doc1 + " from term_weight_tf";
sql_2 = "select doc" + doc2 + " from term_weight_tf";
} else {
sql_1 = "select doc" + doc1 + " from term_weight_wf";
sql_2 = "select doc" + doc2 + " from term_weight_wf";
}
ResultSet resultSet = statement.executeQuery(sql_1);
ArrayList<Double> list_1 = new ArrayList<>();
ArrayList<Double> list_2 = new ArrayList<>();
double d1 = 0, d2 = 0;
while (resultSet.next()) {
list_1.add(resultSet.getDouble(1));
d1 += resultSet.getDouble(1) * resultSet.getDouble(1);
}
resultSet = statement.executeQuery(sql_2);
while (resultSet.next()) {
list_2.add(resultSet.getDouble(1));
d2 += resultSet.getDouble(1) * resultSet.getDouble(1);
}
d1 = Math.sqrt(d1);
d2 = Math.sqrt(d2);
double sum = 0;
for (int i = 0; i < list_1.size(); i++) {
sum += list_1.get(i) * list_2.get(i);
}
sum = sum / (d1 * d2);
return sum;
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
return 0;
}
//查询两个文档的相似度
public static double querySim(int mode, int doc1, int doc2) {
if ((doc1 > 0 && doc1 <= N) && (doc2 > 0 && doc2 <= N)) {
return Double.valueOf(String.format("%.2f", calculateSim(mode, doc1, doc2, connection) * 100));
}
return 0;
}
根据我们前面的讲解,我们知道了文档与查询间相似度的计算公式,它涉及到了获取term_i 在文档 j 中词频数 wf(归一化的tf) ,因此我们需要从数据库中取出wf:
//获取 term_i 在文档 j 中词频数 wf(归一化的tf)
public static double getW_ij(String term, Integer docId) {
Statement statement = null;
String sql = "select doc" + docId + " from term_wf where term='" + term + "'";
try {
statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql);
if (resultSet.wasNull()) {
return 0;
}
resultSet.next();
return resultSet.getDouble(1);
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
if (statement != null) {
statement.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
return 0;
}
附上本次实验的函数执行调用部分的代码:
public class Experiment4 {
public static int N = 421; //文档总数
public void exp4() {
//获取到实验2得到的去除了停用词的倒排索引字典
Experiment2 exp2 = new Experiment2();
LinkedList<Item> dictionary = exp2.exp2();
//获取数据库连接
Connection con = getConnection();
//统计在总文档中包含每个 term 的文档数 df,并执行插入sql语句
insertDf(dictionary, con);
//统计每个 term 在每个文档中词频数 tf,并执行插入sql语句
insertTf(dictionary, con);
//统计在每个term的idf值,并执行插入sql语句
insertIdf(dictionary, con);
//统计每个term在每个文档中的wi,j权值(利用tf计算),并执行插入sql语句
insertWeight_tf(dictionary, con);
//统计每个 term 在每个文档中词频数 wf(归一化的tf),并执行插入sql语句
insertWf(dictionary, con);
//统计每个term在每个文档中的Wi,j权值(利用wf计算),并执行插入sql语句
insertWeight_wf(dictionary, con);
}
}
到此,我们完成了本次实验的内容。对于查询词的预处理,以及计算查询与文档间相似度的问题,我们将在下一篇文章中再继续。
下一篇文章,【信息检索】Java简易搜索引擎原理及实现(五)计算查询与文档相似度 + 搜索界面开发 + 服务器快速搭建,我们将完成整个搜索引擎的实现,包括web界面的设计开发,以及服务器的快速搭建。