python数据分析之爬虫七:爬取豆瓣书籍排行榜Top250
豆瓣书籍Top250链接:https://book.douban.com/top250?icn=index-book250-all
知识点及实例部分参考:
python数据分析之爬虫五:实例
python数据分析之爬虫三:BeautifulSoup库爬虫实例
import re
import requests
from bs4 import BeautifulSoup
import pandas as pd
def getHTMLText(url):
try:
kw = {'user-agent': 'chrome/10.0'}
r = requests.get(url, params=kw)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('error')
def parseHTML(bookinfo, html):
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all('a', attrs={'class': 'nbg'})
titles = re.findall(r'title=\".+?\"', html)
for i in range(len(titles) - 25):
if 'title="可试读"' in titles:
titles.remove('title="可试读"')
peoples = soup.find_all('span', attrs={'class': 'pl'})[:-1]
scores = soup.find_all('span', attrs={'class': 'rating_nums'})
prices = soup.find_all('p', attrs={'class': 'pl'})
abstracts = soup.find_all('span', attrs={'class': 'inq'})
if len(abstracts) != 25:
for i in range(25 - len(abstracts)):
abstracts.append(' ')
for i in range(len(titles)):
people = re.findall(r'[0-9]+', peoples[i].text)[0]
title = titles[i][7:-1]
link = links[i]['href']
score = scores[i].text
price = prices[i].text.split('/')[-1]
author = prices[i].text.split('/')[0]
if abstracts[i] != ' ':
abstract = abstracts[i].text
else:
abstract = abstracts[i]
bookinfo.append([title, author, score, people, abstract, price, link])
def saveInfo(bookinfo, path):
a = pd.DataFrame(bookinfo, columns=['书籍名称', '作者', '豆瓣评分', '评价人数', '书籍概括', '书籍价格', '书籍豆瓣链接'])
a.to_excel(path, index=False)
def main():
bookinfo = []
path = r'C:\Users\LPH\Desktop\doubanbook.xlsx'
for i in range(10):
url = 'https://book.douban.com/top250?start='
url = url + str(i * 25)
print(url)
html = getHTMLText(url)
parseHTML(bookinfo, html)
saveInfo(bookinfo, path)
main()
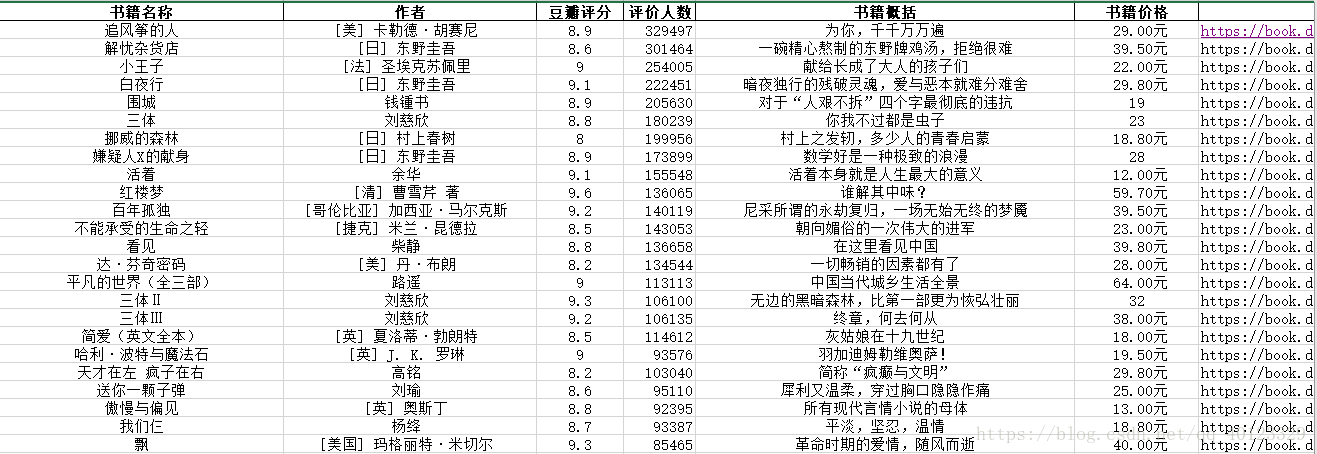
效果如下:
简化版本(更简洁)
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
def getHTMLText(url):
try:
kw={'user-agent':'chrome/10.0'}
r=requests.get(url,params=kw)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
print('error')
def parseHTML(bookinfo,html):
soup=BeautifulSoup(html,'html.parser')
tables = soup.findAll('table', {"width": "100%"})
for table in tables:
link=table.div.a['href']
title=table.div.a.text.strip().replace('\n','').replace(' ','')
people=table.find('span',{'class':'pl'}).text.strip()
people=re.findall(r'[0-9]+',people)[0]
score=table.find('span',{'class':'rating_nums'}).text.strip()
detail=table.find('p', {"class": "pl"}).text
if table.find('span',{"class": "inq"}):
abstract=table.find('span',{"class": "inq"}).text.strip()
else:
abstract='no abstract'
bookinfo.append([title,score,people,detail,abstract,link])
return bookinfo
def saveInfo(bookinfo,path):
a=pd.DataFrame(bookinfo,columns=['书籍名称','豆瓣评分','评价人数','书籍信息','书籍描述','书籍豆瓣链接'])
a.to_excel(path,index=False)
def main():
book=[]
path=r'C:\Users\LPH\Desktop\doubanbook2.xlsx'
for i in range(10):
bookinfo=[]
url = 'https://book.douban.com/top250?start='
url=url+str(i*25)
print(url)
html=getHTMLText(url)
books=parseHTML(bookinfo,html)
for i in range(len(books)):
book.append(books[i])
saveInfo(book,path)
main()效果:

Requests文档
BeautifulSoup文档(中文)