Bert和Albert、XLNet的前世今生
在之前的一篇题为NLP词向量模型总结:从Elmo到GPT,再到Bert的博文中,详细介绍了ELMO、GPT、Bert三者之间千丝万缕的关系,时代在发展,论文在更新,工具在进步,站在巨人(Bert)的肩膀上,出现了一系列的后Bert模型,一个比一个强大,本文着重讲解其中的佼佼者-Albert和XLNet。
Bert的减肥之路–AlBert
背景
ALBERT是19年由Google蓝振忠等人发表的一种轻量级BERT,是BERT众多变体中的一种。可谓是将原先的BRET进行了一次“大瘦身”。其最初的设计灵感来源于卷积视觉中的AlexNet(因为蓝振忠博士在研究生阶段就是做CV出身的),旨在通过将BERT中的模型参数大幅度减少,解决参数过多超出内存导致无法将网络加深、加宽的问题。
蓝振忠博士和其组内成员分析了BERT的参数组成,将模型参数分为两部分:
- Token Embedding-----------约占20%
- Attention Feed-forward-----约占80%
因此,蓝博决定从上面两个方向去对BERT参数进行改动。
基于Embedding的因式分解
下面的内容前,我们规定几个参数,词的embedding我们设置为E,encoder的层数我们设置为L,hidden size即encoder的输出值的维度我们设置为H,前馈神经网络的节点数设置为4H,attention的head个数设置为H/64。
在BERT中,词embedding与encoder输出的embedding维度是一样的都是768。但是ALBERT认为,词级别的embedding是没有上下文依赖的表述,而隐藏层的输出值不仅包括了词本生的意思还包括一些上下文信息,理论上来说隐藏层的表述包含的信息应该更多一些。所以,没有必要让E=H,而产生更多的参数,感觉有点得不偿失。因此应该让H>>E,所以ALBERT的词向量的维度是小于encoder输出值维度的。
在NLP任务中,通常词典都会很大,embedding matrix的大小是E×V,如果和BERT一样让H=E,那么embedding matrix的参数量会很大,并且反向传播的过程中,更新的内容也比较稀疏(比方说词表长度为3W,每次却只能更新一个)。
于是ALBERT采用了一种因式分解的方法来降低参数量。首先把one-hot向量映射到一个低维度的空间,大小为E,然后再映射到一个高维度的空间,说白了就是先经过一个维度很低的embedding matrix,然后再经过一个高维度matrix把维度变到隐藏层的空间内,从而把参数量从
O(V x H)降到O(V x E + E x H),当E<

可以看到实验结果表示,在模型性能基本不变的情况下(0.6%),Embedding层的参数减少了80%以上。
跨层的参数共享
只通过词向量的维度减少来降低参数量,是不够的,Albert提出了一种参数共享的方法,Transformer中共享参数有多种方案,只共享全连接层,只共享attention层,ALBERT结合了上述两种方案,全连接层与attention层都进行参数共享,也就是说共享encoder内的所有参数,同样量级下的Transformer采用该方案后实际上效果是有下降的,但是参数量减少了很多,训练速度也提升了很多。想法是怎么来的呢?看下面。
蓝博参考了论文“Efficient training of bert by progressively stacking”对 Attention&Feed-Forward 层可视化的结果,发现对于encoder的各层,其参数在结构上呈现一种相似性(下图中的第一列其实就是[CLS]标记,每一个encoder层除了参数大小不一样,分布结构上呈现很强的一致性):

如果能够把所有 Attention&Feed-Forward 层的参数进行共享,那么BERT模型的参数又将是下降一个数量级的,实验结果如下:

在模型深度保持不变的前提下,将 Attention&Feed-Forward 层的所有参数共享,使得参数从原先的108M降低到了31M,而精度并没有太大的降低(2.5%)
最终,ALBERT将Token Embedding 层参数从原先E=768降低到E=128,并将Attention&Feed-Forward层的所有参数进行共享。将BERT最开始108M的参数压缩到12M,同时精度仅掉了2.2%!
随后,兰博团队将压缩之后的网络进行了大规模的加宽、加深,并且进行了长时间的训练。最终的结果如下:

最终参数减少30%的情况下,还提升了ALBERT 3.5%的精度,这个结果可以说是非常不错的了。但是这样做的代价同样很昂贵,ALBERT花了BERT3倍的时间才将模型训练至收敛。(因为毕竟网络被加宽加深,模型变得比BERT还要复杂,而这些新增的参数还是需要被更新,更何况这些参数还都是被refine共享过的,所以在计算上没有地方可以偷懒。一种典型的以时间换空间的做法)
句间连贯(Inter-sentence coherence loss)
我们知道BERT的sentence-level实现的很重要的一点就是进行了NSP(Next Sentence Prediction)。其意图是为了训练模型对句子连续性的把握,但是对于负样本的采样,BERT的策略却是从整个语料库中随机抽取样本,这将会带来一个潜在的问题:网络很有可能学到句对间topic的判别,而不是句对连续性的把握。显然,前者的难度远低于后者,但是这并不是BERT的本意。这也就是为何在许多下游任务中,将NSP这个任务去掉,BERT产生的性能反而更好的原因。
ALBERT做出的一个很重要的改进就是强制让模型去辨别句对连续性,即SOP(Sentence Oder Prediction),而它采用的策略极其简单—负样本的获得,是通过正样本两个句对顺序的颠倒。看似简单的操作,却保障了负样本的两个句子是从属于同一个topic,而句序是明显错误的效果。
下图是SOP代替了NSP之后产生的效果:

可以看到SOP不管是在真正的SOP任务上,精度达到86.5%,同时对于真正的下游NSP任务,效果也不是很差,达到了78.9%(蓝色框)。但是NSP明显只能在NSP任务上取得high score(一方面也是因为这样的任务更简单)
去除MLM(masked LM)中的drop out
BERT的训练本就是基于大量的网络文本、书籍文献。从这个角度讲,BERT其实完全没有必要去担心over fitting.由于MLM本身就是一个非常有难度的任务(困难版完形),没必要再去添加噪声刁难它,只要拥有足够的算力,BERT理论上只会越学越好。
在去掉了drop out 之后,下游任务貌似只有轻微的提升:

以上就是Albert在基于Bert上的改进。
Bert的进阶之路–XLNet
XLNet 是一个类似 BERT 的模型,而不是完全不同的模型。但这是一个非常有前途和潜力的。总之,XLNet是一种通用的自回归预训练方法。在将XLNet之前,先要了解两个概念Autoregressive 和 Auto-encoding。
自回归模型和自编码模型
- Autoregressive(自回归模型):自回归是时间序列分析或者信号处理领域喜欢用的一个术语。可以直接理解成语言模型,即一种基于上文预测下文,或者基于下文预测上文的语言模型。典型的代表是GPT、ELMo.
- Auto-encoding(自编码模型):什么叫做自编码?说的通俗一点,其实就是一个自个儿和自个儿玩的模型(自己和自己下棋,自己和自己对唱…玩着玩着棋艺就变高了,玩着玩着唱功就变好了)。最开始自编码的提出是想要通过一个深度网络,对数据进行压缩成低纬,之后解压缩还原原始数据,目的为了获得输入数据的更加有效的表示。但是这样的一种模式非常适用于无监督的pre-training.
和CV不同,在NLP领域,我们不得不面对的一个问题就是我们有大量的数据,可是我们没有标注。正是由于这个原因,完全无监督预训练网络对于许多label稀少的下游任务来说十分重要,而Auto-encoding这种LM则正是NLP迁移学习的一个理想模型,就如本文开篇说的那样。而BERT就是Auto-encoding的一个典型代表。不仅如此,BERT采用了MLM,在输入层加入一定的噪音,是一种典型的DAE LM(Denoising Autoencoder)。
自回归模型和自编码模型的对比
自回归模型的一般形式可以用下面这幅图表示: 缺点是无法实现同时双向 自编码模型表示如下图: 当然,优点就是可以实现同时双向。 从这里可以发现,Autoregressive 和 Auto-encoding之间的优缺点刚好反一下,那么有没有一种模型,可以兼顾Autoregressive 和 Auto-encoding的优点呢?这也就是XLNet的诞生初衷。 在XLNet诞生之前,预训练方面存在着两大阵营,分别是以ELMo、GPT一众为代表的AR(Auto regressive) 和以BERT为首的 AE(Auto-encoding)。这两大阵营都存在着各自的优点和缺点,但是其优缺点大致上呈现一种互补关系。为了能够同时兼顾这两大范式的优点,19年Google brain结合了当时最先进的自回归模型Transformer-XL,提出了一种采用泛化自回归,克服BERT等自编码模型缺点的新模型—XLNet. XLNet采用的是自回归模型,同时运用了BERT引以为傲的MLM训练模式,即给定一个句子,将其中的一部分单词进行Mask,然后利用剩下的句子信息去还原被mask的单词。由于是采用自回归,BERT这种自编码模型的两个缺点:训练与下游不协调、独立性假设损失关联性, XLNet就可以很自然地避开。那么XLNet要解决的首要问题就是如何实现同时双向融合。 所谓排列组合,就是把输入的句子进行全排列,每一种排列方式进行一次Mask预测,最后取所有全排列下的期望值。比方说现在输入的句子是:boy next door,把’next‘用Mask替换掉,如果不采用全排列,直接将输入喂给AR,也就是"boy [Mask] door",那么模型只能单向地提取到"boy"的信息。 对于每一种排列,单向地计算[Mask]位置的原词概率,计算的公式就是之前讲过的AR的product rule. 在实现这个乱序采样的过程中,XLNet做的并不是真的将输入打乱顺序,而是采用了打乱order的方法。具体过程如下图: Z T Z_T ZT={【1,2,3】、【1,3,2】、【2,1,3】、【2,3,1】、【3,2,1】、【3,1,2】} 再详细一点,假如说现在输入有四个单词,被Mask的是3号位置的单词,我们可以看一下不同order下的不同处理。 到目前位置,我们可以看到,利用全排序的XLNet既解决了自编码模型的缺点,又能同时捕捉上下文信息。那么它是否已经是没有问题存在的了呢?答案是否定的,因为这样做,会导致导致位置信息的丢失。举个例子如下,比方说现在的输入是这样一个句子: 假设我们运气不好,Mask的时候"圆月"、"弯刀"两个字刚好都被遮住了。 随后我们按照XLNet的做法对order集合 ZT 进行抽样,我们运气又很差,抽到下面这个排列: 由于被预测的两个Mask都被排在最后两个字,因此在从左到右计算任何一个位置的Mask时,计算出来的"圆月"和"弯刀"概率结果是一模一样的,并且,如果现在问你这两个Mask哪个是"圆月",我也不知道了,这就是乱序带来的问题,以为缺失了位置信息。 到这里就讲的差不多了。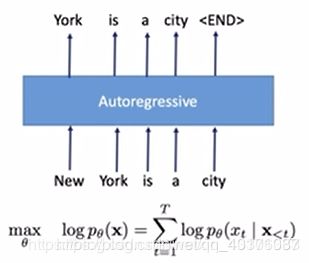
自回归模型旨在利用序列的单向迭代,通过已知的上文信息Pθ(Xt | X

由于是DAE LM,因此在目标函数中加了一个mt,取值为[0,1],作用相当于对被Mask掉的单词的开关。
有人可能会注意到,这里的目标函数和Autoregressive不一样,很重要的一点是Auto-encoding的目标函数中间用的是约等于符号。这是因为等号右边式子的值并不服从product rule(条件概率的乘法法则),所以Auto-encoding模型具有独立性假设。
比方说上图,把句字New York is a city的New York给mask了,目标是预测被遮住的New York,即求得 P(New York|is a city) 并将其最大化(先不考虑log)。这里先把“is a city”当作是一个整体,把它用C代替,“New"和“York“分别用A、B表示。所以我们的目标就是max P(AB|C)。
为了计算这个联合概率,假设事件A和事件B是条件独立的,即P(AB|C)≈P(A|C)*P(B|C)
放到上面这个句子,也就是P(New York|is a city)≈P(New|is a city)*P(York|is a city)。但是很明显,对于"New”、"York"来说,离开了其中任何一个,另一个剩下的也失去了原本含义,因为本身这两个token是属于一个单词的。在遇到这种情况时,Auto-encoding的条件独立假设就会存在比较严重的问题,因为它强行将token之间原本可能存在的关联性给打破了。
所以,总结起来其缺点就是:
XLNet的诞生
XLNet一出,BERT之前连战11项的巅峰记录被无情刷了下去。XLNet在20 个任务上超过了BERT的表现,并在18个任务上取得了当前最佳效果,其中包括了包括机器问答、自然语言推断、情感分析和文档排序。
那么XLNet到底是采用了什么方法进行AR与AE的融合的呢?Permutation!!!Permutation Language model
为了解决这个难题,XLNet想出了一个聪明的点子----Permutation Language model(排列组合模型)。
而Permutation Language model要做的就是将上述的句子产生3!种排列情况:boy [Mask] door
boy door [Mask]
[Mask] boy door
[Mask] door boy
door [Mask] boy
door boy [Mask]

最后将6种排列的结果取一个期望,由于所有的排列情况都被考虑进去,在预测过程中,Mask的位置就已经获得了上下文的全部信息。
XLNet就是通过这种将输入顺序打乱重排的方法,来实现基于AR的同时双向。
当然,在实际训练的过程中,由于输入的长度会很大,因此计算所有排列情况实际上是不可行的,这会产生巨大的时间消耗。因此XLNet每次只在全排列中取一部分。实现细节

Z T Z_T ZT 表示所有order组成的集合。拿之前那个例子来说就是:boy [Mask] door ---------【1,2,3】
boy door [Mask] --------【1,3,2】
[Mask] boy door----------【2,1,3】
[Mask] door boy-----------【2,3,1】
door [Mask] boy-----------【3,2,1】
door boy [Mask]---------【3,1,2】
而每次要做的,就是从ZT 中抽取一个order Z ,比方说 Z =【1,3,2】,然后用这个order去计算Mask位置的概率:P(boy door next)=P(boy)*P(door|boy)*P(next|boy door)
然后重复上述抽样过程。
如果现在随机抽到的order是【3,2,4,1】,那么这个过程就会像下图。由于现在的order里,3是第一个,所以它获取不到任何信息,因此计算 h 3 ( 1 ) h_3^{(1)} h3(1)只会用到一个默认的cell–mem。

假设order是【2,4,3,1】,那么计算 h 3 ( 1 ) h_3^{(1)} h3(1)将会需要2、4的信息:

所以可以看到,所谓的打乱并不会真的改变输入序列的顺序,只是将order随机打乱,再根据order去获得预测Mask需要考虑位置。
另外,XLNet在实现不同的order上采用的是 Attention Mask 矩阵,例如【3,2,4,1】,他的 Attention Mask 矩阵就是下面这幅图:

比方说现在要预测4,那么需要考虑的上文是3和2, Attention Mask 矩阵的第4行就只有2,3两列是1,其他地方是0;再比如要预测3,这个order下3前面没有任何信息,所以 Attention Mask 矩阵的第三行全为0.Two-Stream Self-Attention
圆月弯刀是古龙经典武侠小说
mask mask 是古龙经典武侠小说
是古龙经典武侠小说 mask mask
回顾一下Bert是如何做的?
Bert采用的做法十分简单粗暴,直接将position Embedding 和输入的Token Embedding直接拼接。那么是否在XLNet里也可以把位置信息(position Embedding)和内容信息(Token Embedding)直接结合呢?答案是XLNet提出了一个Two-Stream Self-Attention(双流注意力),它将每个Transformer cell分为两个部分:

在上图中,蓝色的路径表示位置信息的传播,红色的是全部信息,可以看到实现双流自注意力之后,XLNet可以做到不向模型透露内容的前提下,加入有关于预测位置的位置信息。
有关于这些前沿的模型,光看blog是不够的,只有摸过论文、代码才能正真get好多细节。