python爬取快手app视频(fiddler抓json包实现)
fiddler工具的安装
fiddler 官网地址:https://www.telerik.com/fiddler
进入页面后,点击free download
进入这个页面后,用途的话,根据自己的需要选择就行的。
输入相关的信息,点击下载即可。
fiddler抓包原理
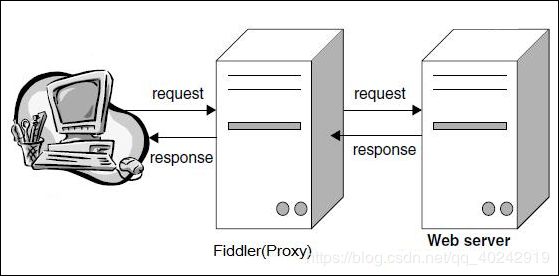
注意:Fiddler 是以代理web服务器的形式工作的,它使用代理地址:127.0.0.1,端口:8888。当Fiddler退出的时候它会自动注销,这样就不会影响别的 程序。不过如果Fiddler非正常退出,这时候因为Fiddler没有自动注销,会造成网页无法访问。解决的办法是重新启动下Fiddler。
配置
打开Fiddler Tool->Fiddler Options->HTTPS
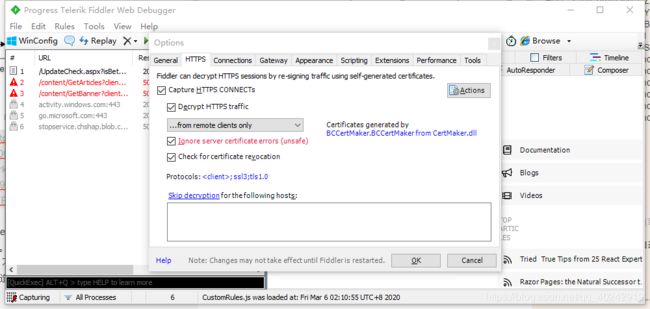
选中"Decrpt HTTPS traffic", Fiddler就可以截获HTTPS请求,第一次会弹出证书安装提示,若没有弹出提示,勾选Actions-> Trust Root Certificate
另外,如果你要监听的程序访问的 HTTPS 站点使用的是不可信的证书,则请接着把下面的 “Ignore servercertificate errors” 勾选上。
fiddler配置
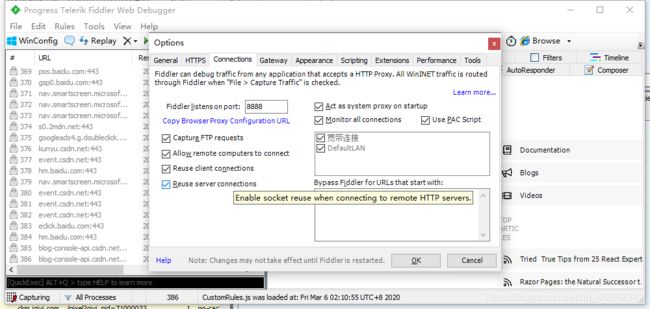
电脑设置
按这样设置好了之后会弹出一个对话框,点确定就好。端口选的8888,要确定该端口没有被占用,若被占用可换一个端口。
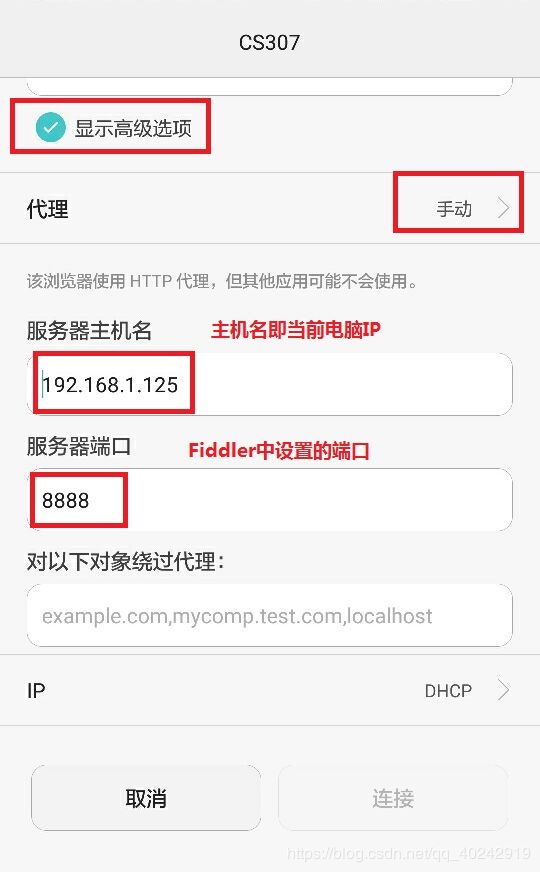
手机(模拟器)设置
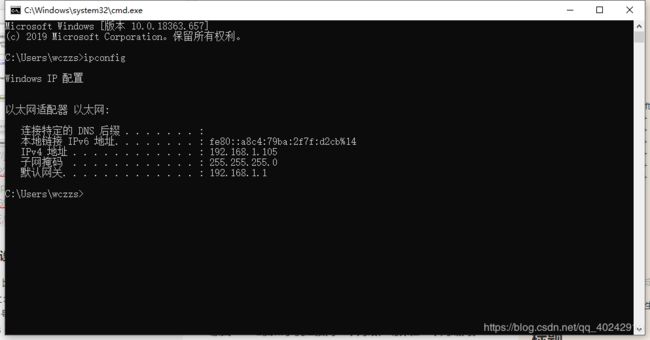
让手机和电脑处于同一网段,比如让手机和电脑连接同一个WiFi就行。在手机浏览器中输入网址: 电脑IP:端口号。电脑IP可通过cmd窗口查到,如下图,端口号就是上一步设置的8888。所以我的网址是:192.168.1.105:8888
输入网址后跳出如下页面:
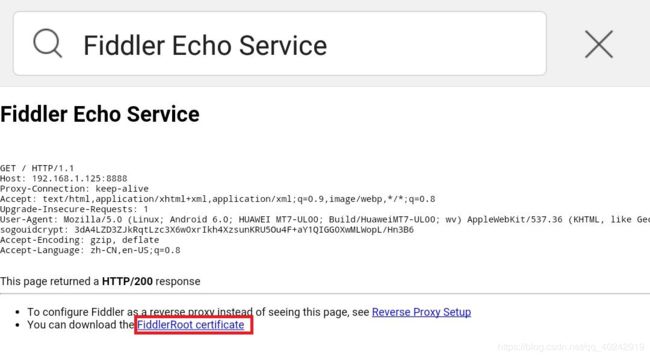
点击红框中的连接,会开始下载证书:
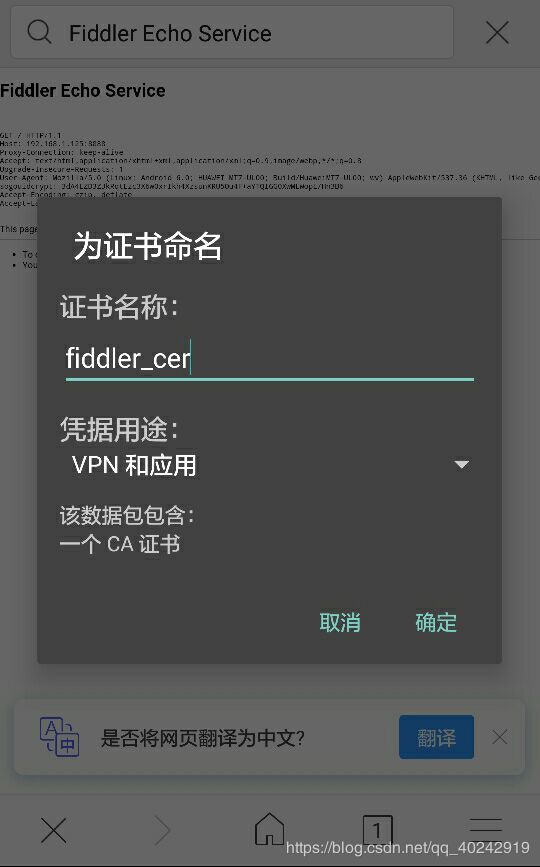
证书名称随便写,最后点击确定就好了。安装成功之后通知栏会显示受到不明第三方监控,这样就代表成功啦。
最后一步,到手机的WLAN设置里,点击当前所连接的wifi修改网络,如下图所示:
关于fiddler部分app抓包连不上网
原因一:电脑和手机连接同一个网络,确保在一个局域网。
电脑端查看电脑的ip地址:win+R键 输入cmd 弹出窗口后输入ipconfig
原因二:配置好fiddler后,要进行重启
原因三:关闭电脑的防火墙,杀毒软件
原因四:打开注册表(cmd-regedit),在HKEY_CURRENT_USER\Software\Microsoft\Fiddler2下创建一个DWORD,值置为80(十进制)
编写fiddlerScript rule,
在fiddler菜单栏,点击Rules->Customize Rules,用Ctrl+F查找Lavender方法添加一行代码
if (oSession.host.toLowerCase() == “webserver:8888”)
{
oSession.host = “webserver:80”;
}
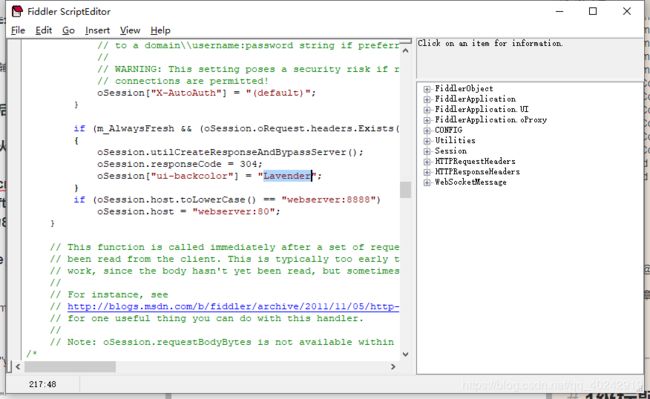
设置完之后重启Fiddler即可。
另外,Fiddler可以抓取支持http代理的任意程序的数据包,如果要抓取https会话,要先安装证书。
以上弄完之后就可以开始抓包了
首先确立下步骤
1.先确立抓取目标
2.开始抓包
打开快手APP,Fiddler会快速显示很多信息,这些都是手机传送或者接收到的信息。可以逐个包点开,以json形式查看是否是我们需要的内容,如下图所示:
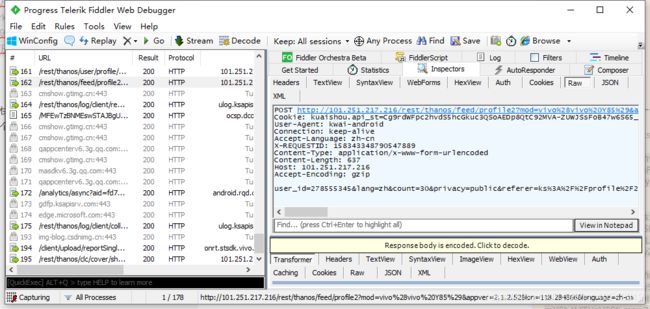
这时可以看到,有一个包里显示了很多信息,包括视频的标题,发布者,再往下拉,发现里面包含很多叫做“main_mv_url"的标签,复制其中一个标签后的url到浏览器,发现浏览器下载了一个mp4格式的视频,点开视频,就是我们需要的。为了让列表中只显示我们需要的包,让视图更清晰,可以用过滤器,只显示URL中含/rest/n/feed/的内容
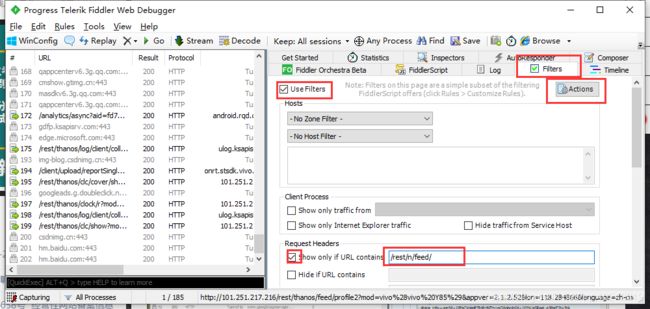
打开Actions选择第一个
回到Fiddler,看之前那个包的头(Fiddler右上窗口),上面有个url
在Inspectors中的第一行Post请求中也可以查看(关于Post与get的区别,设计html,这里不再赘述)
可以复制到浏览器会发现打开的不是和Fiddler右下角一样的json界面,而是显示服务器繁忙,因为这个url是不完整的。注意右上窗口最后一行有个user_id=…"这其实是完整url的后半部分,要把它拼接到第一行POST url的后面(HTTP/1.1之前),并且以&连接。把完整的url再复制到浏览器,得到和Fiddler右下窗口类似的内容
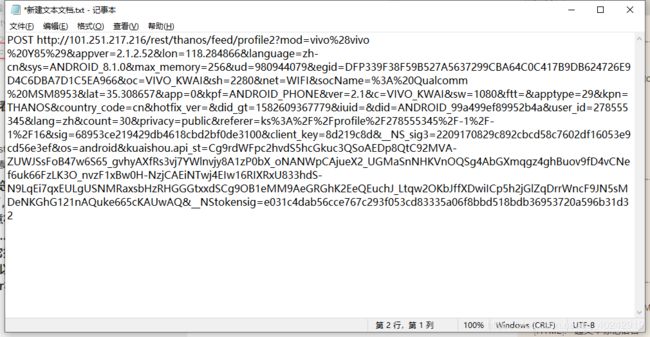
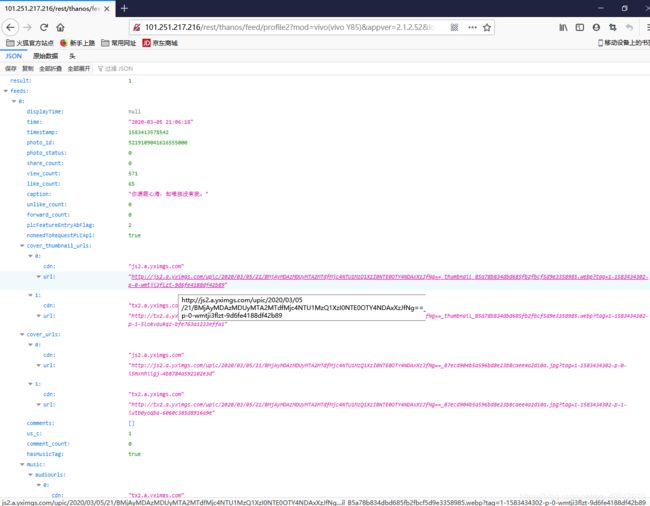
再观察“user_id=…”这串字符,可以多抓几个包对比一下,发现count后面跟着的数字是不一样的,即每个json里所含视频个数不一样。平均每个json中含有20个视频的下载链接。page后面的数字就代表页数,在快手界面不断的往下滑,隔一小段时间会有另一个包,可以发现page后的数字是递增的。__NStokensig和sig后跟的一串数字是没有规律可循的,要破解快手APP的代码才能知晓。所以无法掌握每个json的url变化规律,所以若是要抓取20个以上的视频,只能通过在快手app页面上往下滑动,抓包,copy完整的url到文本文件再用程序进行下载。
我一共是抓了1个包,因为这个作者又chou作品又shao
程序很简单,加了日志功能来记录每个视频的题目和url和下载进度。有时候可能遇到某个下载链接有问题,所以程序可能卡在那里,因为我没有做超时处理,所以这时需要停止程序并修改一下page和video_count的值继续下载。当然这种情况比较少,最后记得每个视频下载完毕用time.sleep()挂起几秒钟,不然访问太快可能会被封哦。
如何批量下载json
系好安全带
选中区域

点击save(保存)–>选择保存格式–>为文本
之后选择路径就可以了
我推荐你们把文件名字改为1.txt
1.txt
1.txt
重要的事情说三遍,这就为我们之后的bat程序打开了关键
OK,同学们划重点
保存之后有什么用呢,
首先
我们再文件的目录中新建一个bat文件
输入代码
可以把 POST http://101.251.217.216/rest/thanos/feed/profile2?
改为你fiddler中的url
但一定要分情况
直截取前半部分POST …/rest/rest/thanos/feed/profile2?
…部分可以更改为你的抓到的网址或者IP 地址
findstr /c:"POST http://101.251.217.216/rest/thanos/feed/profile2?" /c:"user_id=" 1.txt>all.txt
之后就会生成一个all.txt
里面就是
这里由于链接没有拼接
所以看好下面操作
这里推荐使用notepad++
打开后,选择替换
将 HTTP/1.1替换成&(HTTP/1.1前有一个空格)
我们替换之后
选择在&的后面按一下Delete键,向前删除
不是Baskspace
这样url就拼接好了
好的,我们已经批量获取了url的链接
接下来的批量下载,我就不赘述了
还是说一下吧,就怕有像我一样的人
这里还是推荐下载工具Internet Download Manager

按图片提示,就可以下载了
好的,下面重重重点来了
获取json文件后如何下载视频,图片,图集呢
如果下面看不懂,可以直接去下载源码(最下面),那个,你还是看完吧,人家好不容易写的,又没有污污的内容,你就看吗。
1
创建一个.gitattributes
(gitattributes老子前面有个.)
# Auto detect text files and perform LF normalization
* text=auto
2
在创建一个_config.yml
theme: jekyll-theme-architect
3
dll文件提供下载地址
gzip.dll.
4
命名为kuaishou.py
#! python3
# -*-coding:utf-8-*-
# author: muyangren907
import json,os,codecs,pprint,re,time,queue,urllib,socket,threading
from urllib.request import urlretrieve
itemnum = 0
havedownload = 0
vq = queue.Queue()
def download(vq):
while True:
# vq.put([caption, photo_id, mv_urls, atlas, cover_urls],path)
videomes = vq.get()
caption = videomes[0]
photo_id = videomes[1]
mv_urls = videomes[2]
atlas = videomes[3]
cover_urls = videomes[4]
path = videomes[5]
# itemnum = videomes[6]
global havedownload
if mv_urls!="None" :
downfile = os.path.join(path, str(photo_id)+"_"+caption + ".mp4") #filename = photo_id+caption
try:
urlretrieve(mv_urls,downfile)
except IOError:
downfile = os.path.join(path, "错误" + '%s.mp4') % photo_id
try:
urlretrieve(mv_urls, downfile)
except (socket.error, urllib.ContentTooShortError):
print("请求被断开,休眠2秒")
time.sleep(2)
urlretrieve(mv_urls,downfile)
havedownload+=1
print("(%d/%d)视频下载完成: %s_%s"% (havedownload,itemnum,photo_id,caption))
vq.task_done()
else:
if atlas[0]!="None" :
caption = caption.replace(".","。")
if os.path.exists(path+"/"+str(photo_id) + "_" + caption) == False:
os.mkdir(path+"/"+str(photo_id) + "_" + caption)
for atlasindex in range(len(atlas)):
atlas_url = atlas[atlasindex]
downfile = os.path.join(path+"/"+str(photo_id) + "_" + caption, str(atlasindex) + ".webp") # filename = atlasindex
try:
urlretrieve(atlas_url, downfile)
except IOError:
downfile = os.path.join(path+"/"+str(photo_id) + "_" + caption, "错误" + '%s%s.webp') %(photo_id,atlasindex)
try:
urlretrieve(atlas_url, downfile)
except (socket.error, urllib.ContentTooShortError):
print("请求被断开,休眠2秒")
time.sleep(2)
urlretrieve(atlas_url, downfile)
havedownload += 1
print("(%d/%d)图集下载完成: %s_%s" % (havedownload,itemnum,photo_id,caption))
vq.task_done()
else:
downfile = os.path.join(path, str(photo_id) + "_" + caption + ".mp4") # filename = photo_id+caption
try:
urlretrieve(cover_urls, downfile)
except IOError:
downfile = os.path.join(path, "错误" + '%s.mp4') % photo_id
try:
urlretrieve(cover_urls, downfile)
except (socket.error, urllib.ContentTooShortError):
print("请求被断开,休眠2秒")
time.sleep(2)
urlretrieve(cover_urls, downfile)
havedownload += 1
print("(%d/%d)图片下载完成: %s_%s" % (havedownload,itemnum,photo_id,caption))
vq.task_done()
def main():
user_name = ""
user_id = 0
localtime = time.asctime(time.localtime(time.time())) #get time
# count number
global itemnum
videonum = 0
atlasnum = 0
picturenum = 0
filelist = os.listdir("./") # get the file list
jsonfilename = []
for file_index in range(len(filelist)):
filestr = str(filelist[file_index])
if filestr.find(".json", 0, len(filestr)) != -1:
jsonfilename.append(filestr) # add json file name to jsonfilename list
print("json文件总数为: " + str(len(jsonfilename)))
for file_index in range(len(jsonfilename)):
jsonfile = open("./"+jsonfilename[file_index],"r",encoding="utf8") #open json file
jsonstr = jsonfile.read() #read file to jsonstr
jsonobj = json.loads(jsonstr)
user_name = jsonobj['feeds'][0]['user_name'].replace("/","") #get user_name
user_id = jsonobj['feeds'][0]['user_id'] #get user_id
# print(user_name+" "+str(user_id))
if os.path.exists("./"+user_name) == False:
os.mkdir("./"+user_name) #mkdir using user_name
mv_urls = "None"
atlas = ["None"]
cover_urls = "None"
for item in jsonobj['feeds']:
itemnum+=1
# pprint.pprint(itme)
caption = item['caption']
notchar = ["?", "*", "/", "\\", "<", ">", ":", "\"", "|", "\n","\r"," "] # These characters cannot appear in the file name
for chari in range(len(notchar)):
caption = caption.replace(notchar[chari], "")
caption = caption[0:29] #file name can't be too long
photo_id = item['photo_id']
if 'main_mv_urls' in item :
videonum+=1
mv_urls = item['main_mv_urls'][0]['url']
else :
mv_urls = "None"
# print(photo_id)
if 'atlas' in item["ext_params"] :
atlasnum+=1
atlas = item["ext_params"]['atlas']['list']
for atlas_index in range(len(atlas)):
atlas[atlas_index]="http://"+item["ext_params"]['atlas']['cdnList'][0]['cdn']+atlas[atlas_index] #url=cdn+relative_url
# print(atlas[atlas_index])
else :
picturenum+=1
atlas=["None"]
cover_urls = item['cover_urls'][0]['url']
# print(cover_urls)
# print(caption)
vq.put([caption,photo_id,mv_urls,atlas,cover_urls,"./"+user_name])
# fp =open("./"+user_name+"/"+caption+".txt","w")
# fp.close()
# print(user_name + str(user_id))
jsonfile.close() #close file
print("itemnum\t"+str(itemnum)+"\nvideonum\t"+str(videonum)+"\natlasnum\t"+str(atlasnum)+"\npicturenum\t"+str(picturenum))
if os.path.exists("./" + user_name + "/" + user_name + ".txt") == False:
user_mes_file = codecs.open("./" + user_name + "/" + user_name + ".txt", "w","utf-8")
user_mes_file.write("download_time\t"+localtime+"\n")
user_mes_file.write("user_name\t" + user_name + "\nuser_id\t" + str(user_id) + "\n")
user_mes_file.write("itemnum\t"+str(itemnum)+"\nvideonum\t"+str(videonum)+"\natlasnum\t"+str(atlasnum)+"\npicturenum\t"+str(picturenum))
user_mes_file.close()
threadnum = 32 # thread number
for thread_num in range(threadnum):
t = threading.Thread(target=download,args=(vq,))
t.setDaemon(True)
t.start()
vq.join()
# print(str(itemnum)+" "+str(videonum)+" "+str(atlasnum)+" "+str(picturenum))
main()
5
编写一个bat文件
你的python文件路径 kuaishou.py
pause
好的,看不懂的就直接下载吧,没有python知识真是看不懂
下面链接奉上
Github:https://github.com/wczzsmmb/CSDNKS.
码云(gitee): https://gitee.com/wczzsmmn/CSDNKS.