超简单的centos7配置hadoop2.7.7+flume1.8.0(包含例子)
超简单的centos7配置hadoop2.7.7+flume1.8.0
flume配套介绍:https://blog.csdn.net/qq_40343117/article/details/100119574
1-下载安装包
下载地址:http://www.apache.org/dist/flume/
自己选择合适版本
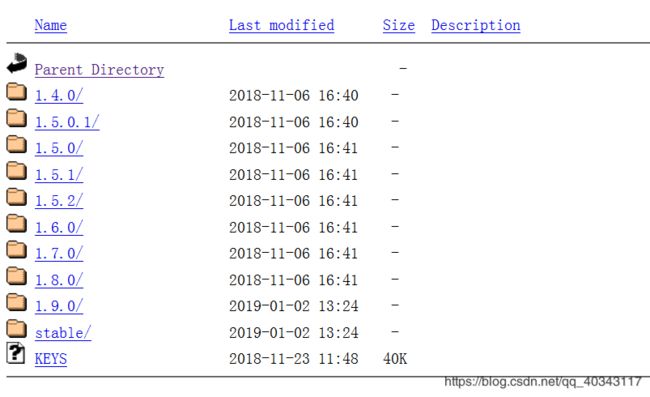
我选择的是1.8.0,安装之前也要自己多查一查自己的hadoop版本和flume是否兼容
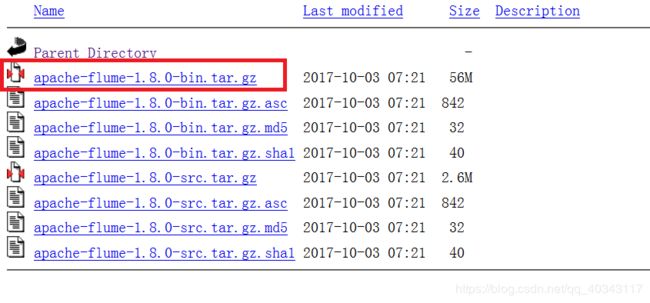
2-安装Flume
1、解压安装包
flume作为一个小组件,配置十分简单,首先我们使用解压命令
tar -zxvf 安装包存放路径 -C 你想要解压的路径
例如:
tar -zxvf /home/h01/桌面/apache-flume-1.8.0-bin.tar.gz -C /usr/local/
然后等待结束就解压成功了,为了操作方便我是解压完后都会删除掉版本和后缀,只留下一个名字,大家都随便,每个人习惯不一样,但是要注意下面的路径名字,一定换成自己的。-
2、导入jar包
为了让我们的flume和hadoop交互,所以我们进入/hadoop/share/hadoop/common和/hadoop/share/hadoop/hdfs两个文件夹找到下图的六个jar包导入到flume/lib/中即可。
 其中红框内是我们需要的,绿框是我在flume的lib下找到的一个重复jar包,如果大家安装安装的时候也有着总问题,先将原文件中的jar包复制出来,换上hadoop的jar包版本,尝试一下,如果出现错误货不兼容,及时更换回来。
其中红框内是我们需要的,绿框是我在flume的lib下找到的一个重复jar包,如果大家安装安装的时候也有着总问题,先将原文件中的jar包复制出来,换上hadoop的jar包版本,尝试一下,如果出现错误货不兼容,及时更换回来。
3、配置文件
flume的配置文件只需要更改一个就可以了,我们在命令行进入flume文件夹,输入
mv conf/flume-env.sh.template flume-env.sh
将配置文件改名,否则执行的时候系统不会识别.template文件,然后我们输入
vi conf/flume-env.sh
进入配置文件,只要在里面加入我们虚拟机的java路径(java_home)就可以了
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
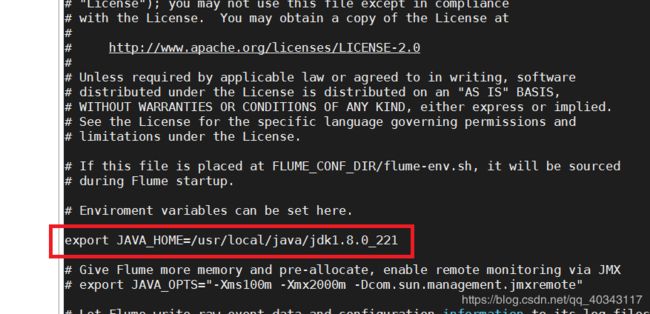
这样我们的flume就配置完成了,我们进入下面的小案例中试验一下就可以。
(!!!!配置成功后直接输入
scp -r flume路径 其他机器的名字:指定传递路径
例如:
scp -r /usr/local/flume h02:/usr/local
这样其他机器就不用从头解压也可以使用flume工具了
)
3-例题
在上一篇博客里我有介绍过一些flume的大体功能和结构,那么我们知道flume是为了采集数据、日志的,如何体现他呢,在这里我以hadoop为例子,介绍一些方法帮助大家理解掌握flume。
1、监控端口
这个例子是让我们先启动flume监听某个端口,然后通过telnet服务向端口发送消息,这样再监听下的端口接受什么信息都会被flume采集到并显示出来。
1.1 我们安装一下telnet服务
//检查是否安装过telnet
yum list | grep telnet-server
yum list | grep xinetd
//没有则进行安装
yum -y install telnet-server.x86_64
yum -y install telnet.x86_64
yum -y install xinetd.x86_64
设置开机启动
systemctl enable xinetd.service
systemctl enable telnet.socket
启动服务
systemctl start telnet.socket
systemctl start xinetd
1.2 判断端口是否被占用
sudo netstat -tunlp | grep 端口
1.3 新建一个文件运行我们的flume
首先这个文件随便建在哪,最好flume文件夹里有一个文件夹专门放这些东西,我偷懒放在了conf里,不可取的行为。
进入到你建好的文件夹(cd命令),输入(当然文件名也是随意的,只要运行的时候别写错了就行)
在文件夹下创建Flume Agent配置文件flume-telnet-logger.conf。
touch flume-telnet-logger.conf
在flume-telnet-logger.conf文件中添加内容。
vim flume-telnet-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
我画个图给大家解释一下:
 1.4 运行我们写好的文件
1.4 运行我们写好的文件
在命令行进入到解压flume的文件夹,输入
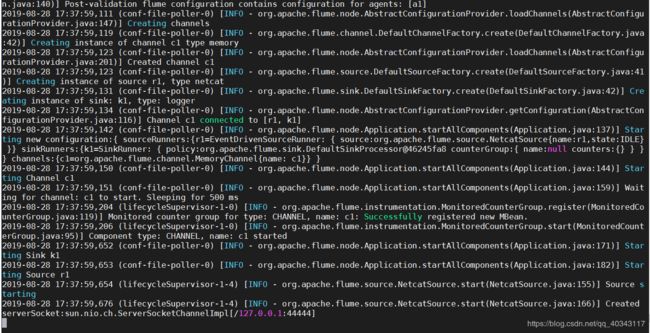
bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/flume-telnet-logger.conf -Dflume.root.logger=INFO,console
显示如下即成功
 同时我们新建一个终端,输入
同时我们新建一个终端,输入telnet localhost 44444
 同时我们的flume就会监听到这个端口
同时我们的flume就会监听到这个端口
 成功配置!
成功配置!
2、将本地文件读取到HDFS集群上
(一定记得按照上面的步骤导入JAR包)
2.1 创建文件
命令行进入到flume文件夹输入
touch flume-file-hdfs.conf
再输入
vim flume-file-hdfs.conf
添加如下内容
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /usr/local/hive/logs/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://h02:9000/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k2.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
把上面没有备注的给大家画图介绍一下
 2.2 运行文件
2.2 运行文件
输入bin/flume-ng agent --conf conf/ --name a2 --conf-file conf/flume-file-hdfs.conf
(注意和hadoop交互一定要先启动hadoop的服务)
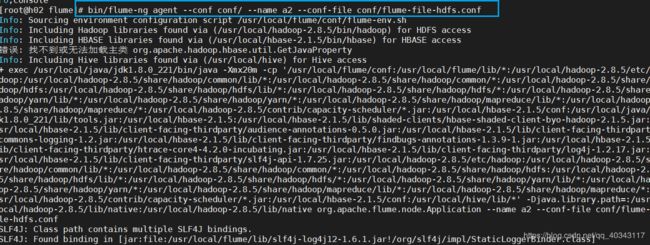 (这里运行完了就是没有反映的,不要奇怪)
(这里运行完了就是没有反映的,不要奇怪)
我们新建一个终端,运行hive
 启动hive之后就会自动上传我们的日志文件了
启动hive之后就会自动上传我们的日志文件了
 成功!
成功!
3、实时读取目录文件到HDFS
3.1编写文件
创建一个文件
touch flume-dir-hdfs.conf
打开文件
vim flume-dir-hdfs.conf
添加如下内容
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /usr/local/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://h02:9000/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = minute
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
#最小冗余数
a3.sinks.k3.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
 3.2 运行文件
3.2 运行文件
输入bin/flume-ng agent --conf conf/ --name a3 --conf-file conf/flume-dir-hdfs.conf
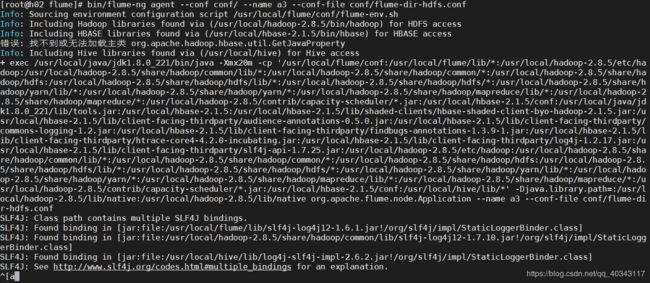
同时我们打开为我们代码中指定的文件目录upload
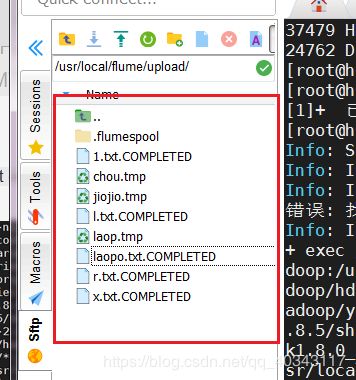
会发现已经按照我们设定规则执行了,打开HDFS集群
![]()
![]() 成功!
成功!