Kylin集群部署及基本架构简介
一、基本架构及原理
实现:利用hadoop中MapReduce框架对hive表中的数据进行预计算,将预计算结果缓存至Hbase中,解决TB级数据分析需求
原理架构参考:https://www.cnblogs.com/tgzhu/p/6113334.html
解决问题:解决海量数据上进行快速查询的难题
解决方案:对于超大数据集的复杂查询,由于现场计算需要花费较长时间,根据空间换时间的原理,提前将所有可能的计算结果计算并存储下来,从而实现超大数据集的秒级多维分析查询。
基本架构:
1、支持的数据源:来自kafka的流数据和hive离线数据
2、计算框架:Spark/MapReduce (Spark引擎Kylin2.0引进的)目前主要用MapReduce,因为两者性能差不多
3、结果储存:预计算结果主要存储在Hbase中(json字符串的形式)
4、对外提供:kylin对外提供标准SQL接口(jdbc/odbc,Rest API),所以Kylin提供与BI工具的整合能力,如Tableau,PowerBI/Excel,MSTR,QlikSense,Hue和SuperSet
参考:https://www.jianshu.com/p/9d4e7c8a53a9
https://blog.csdn.net/lvguichen88/article/details/53054745
https://www.cnblogs.com/sh425/p/5845241.html
https://blog.csdn.net/yu616568/article/details/48103415
Kylin系统架构:
包括: 数据源(source),执行引擎(engine),存储(storage)
执行引擎包括:查询引擎和cube构建

基本实现:
Model:根据业务查询,抽取hive中所需要的列字段,根据Model筛选出来需要参加业务处理的数据,而不参加的会被去除
Cube创建:就是一个Hive表的数据按照指定维度与指标计算出的所有组合结果。
Cuboid:每一种维度组合称为cuboid,一个cuboid包含一种具体维度组合下所有指标的值。
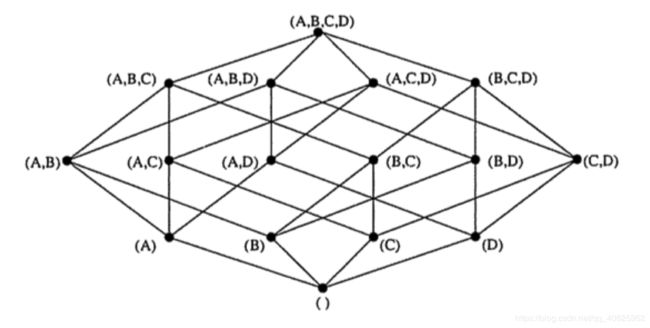
如图,整个立方体称为1个cube,立方体中每个网格点称为1个cuboid,图中每个点代表一个cuboid,(A,B,C,D)称为Base cuboid。cube的计算过程是逐层计算的,首先计算Base cuboid,然后计算维度数依次减少,逐层向下计算每层的cuboid。
二、Kylin集群部署
环境准备:
Hadoop: 2.7+, 3.1+ (since v2.5)
Hive: 0.13 - 1.2.1+
HBase: 1.1+, 2.0 (since v2.5)
Spark (可选) 2.3.0+
Kafka (可选) 1.0.0+ (since v2.5)
ZooKeeper 3.3.6 (可选)
JDK: 1.8+ (since v2.5)
1、解压安装
下载地址:https://archive.apache.org/dist/kylin/
2、修改环境变量 vim ~/.bashrc
添加:
export JAVA_HOME=/opt/module/jdk1.8
export HADOOP_HOME=/opt/module/hadoop-2.7/hadoop
export HADOOP_CONF_DIR=/opt/module/hadoop-2.7/hadoop/etc/hadoop
export YARN_CONF_DIR=/opt/module/hadoop-2.7/hadoop/etc/hadoop
export HBASE_HOME=/opt/module/hbase
export HBASE_CONF_DIR=/opt/module/hbase/conf
export HIVE_HOME=/opt/module/hive
export HIVE_CONF_DIR=/opt/module/hive/conf
export KYLIN_HOME=/opt/module/kylin
export HCAT_HOME=/opt/module/hive/hcatalog
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_CONF_DIR:$HBASE_HOME/bin:$HBASE_CONF_DIR:$HIVE_HOME/bin:$HIVE_HOME_DIR:$KYLIN_HOME:bin:$HCAT_HOME
3、修改配置kylin.properties
kylin.metadata.url=kylin_metadata@hbase 配置所有的 Kylin 节点使用同一个 HBase metastore 储存kylin元数据
kylin.server.mode=all 主从节点唯一不同的地方,kylin主节点模式,其它节点为query(job 模式代表该服务仅用于任务调度,不用于查询;query 模式代表该服务仅用于查询,不用于构建任务的调度;all 模式代表该服务同时用于任务调度和 SQL 查询)
kylin.server.cluster-servers=host01:7070,host02:7070,host03:7070 包括所有节点(包括当前节点)
kylin.web.timezone=GMT+8 设置为中国时间
4、配置完将kylin安装包传送至其他节点
scp -r /opt/module/kylin node01ip:/opt/module/
scp -r /opt/module/kylin node02ip:/opt/module/
5、启动集群
启动集群前先启动hadoop 、hbase 、hive 、zookeeper等服务
启动kylin,所有节点运行/bin/kylin.sh start
以上cube构建引擎为MR
更改cube构建引擎为spark:
kylin发行版本目前还使用的是基于hadoop2.x的Spark,若版本太高会产生jar包冲突
1、在kylin目录下新建hadoop_conf文件夹
2、(集群的配置文件关联到kylin的目录)配置文件,建立软连接
ln -s /etc/hadoop/conf/hdfs-site.xml $KYLIN_HOME/hadoop-conf/hdfs-site.xml
ln -s /etc/hadoop/conf/yarn-site.xml $KYLIN_HOME/hadoop-conf/yarn-site.xml
ln -s /etc/hadoop/conf/core-site.xml $KYLIN_HOME/hadoop-conf/core-site.xml
ln -s /etc/hbase/conf/hbase-site.xml $KYLIN_HOME/hadoop-conf/hbase-site.xml
ln -s /etc/hive/conf/hive-site.xml $KYLIN_HOME/hadoop-conf/hive-site.xml
3、修改kylin配置文件 kylin.properties:
kylin.env.hadoop-conf-dir=/usr/local/apache-kylin-2.1.0-bin-hbase1x/hadoop-conf
4、将spark依赖的jar添加到hdfs(不用每次执行都上传)
将$SPARK_HOME/jars/* 下spark运行依赖的jar上传到hdfs上
jar cv0f spark-libs.jar -C $KYLIN_HOME/spark/jars/ .
hadoop fs -mkdir -p /tmp/kylin/spark/
hadoop fs -put spark-libs.jar /tmp/kylin/spark/
5、修改配置文件 kylin.properties:
kylin.engine.spark-conf.spark.yarn.archive=hdfs://host:8020/tmp/kylin/spark/spark-libs.jar
kylin.engine.spark-conf.spark.driver.extraJavaOptions=-Dhdp.version=current
kylin.engine.spark-conf.spark.yarn.am.extraJavaOptions=-Dhdp.version=current
kylin.engine.spark-conf.spark.executor.extraJavaOptions=-Dhdp.version=current
其他kylin.properties配置文件中的spark引擎部分的配置自行配置
参照:http://kylin.apache.org/cn/docs/tutorial/cube_spark.html
https://www.cnblogs.com/double-kill/articles/8547400.html
6、将新增加的文件分发至各节点
7、web界面修改构建引擎(创建cube时修改)如下:
将MapReduce修改为spark

三、Cube构建
1、创建model
创建 cube 前,需定义一个数据模型。数据模型定义了一个星型(star schema)或雪花(snowflake schema)模型。一般抽取cube中所有可能用到的字段, 一个模型可以被多个 cube 使用
注:Skip snapshot for this lookup table 选项指的是是否跳过生成 snapshotTable,由于某些 Lookup 表特别大(大于 300M),如果某一个维度的基数比较大 ,可能会导致内存出现 OOM,所以在创建 snapshotTable 的时候会限制原始表的大小不能超过配置的一个上限值(kylin.snapshot.max-mb,默认值300)
2、新建cube
2.1 Derived columns和Normal columns的区别:
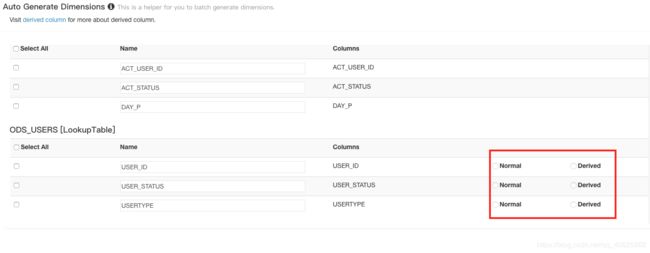
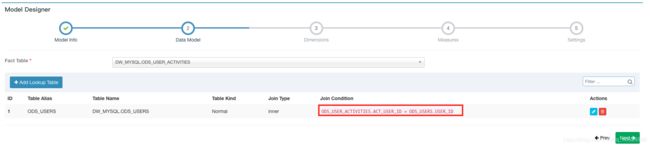
For example:创建model时,关联了事实表和维度表,采用act_user_id=user_id做关联,在创建cube时选择维度时如果选择了fact表中的act_user_id,那么对应lookup表中的user_id可以不用选,而通过act_user_id与user_id之间的特殊映射就可以得到lookup表中的其他维度,因此,可以将lookup表中的其他维度设置为derviced
反之:如果不选择关联键作为维度,则lookup表中维度应该设置为normal
参考:https://blog.csdn.net/jiangshouzhuang/article/details/51286150
http://kylin.apache.org/docs/howto/howto_optimize_cubes.html
2.2 增量构建需设置
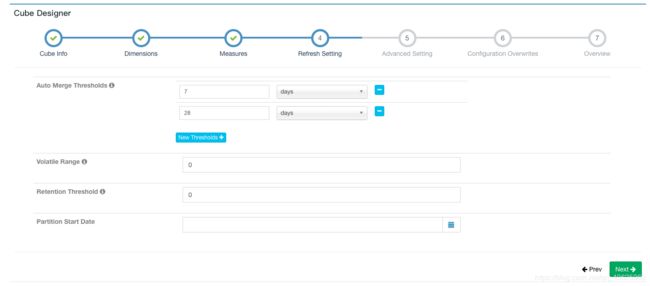
Auto Merge Thresholds: 自动合并小的 segments 到中等甚至更大的 segment。如果不想自动合并,删除默认2个选项。参考(https://m.aliyun.com/yunqi/articles/82784)
Volatile Range: 默认为0,会自动合并所有可能的 cube segments,或者用 ‘Auto Merge’ 将不会合并最新的 [Volatile Range] 天的 cube segments。
Retention Threshold: 只会保存 cube 过去几天的 segment,旧的 segment 将会自动从头部删除;0表示不启用这个功能。
Partition Start Date: cube 的开始日期(默认为1970-01-01)
2.3 cube构建优化设置(Advanced Setting)
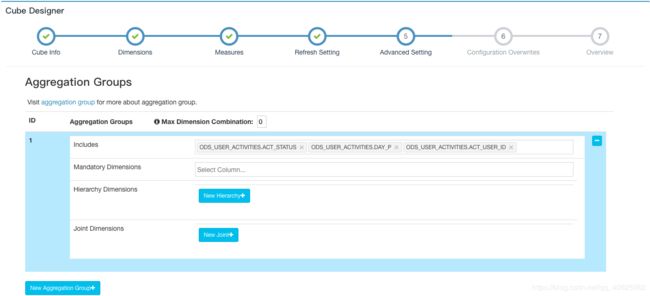
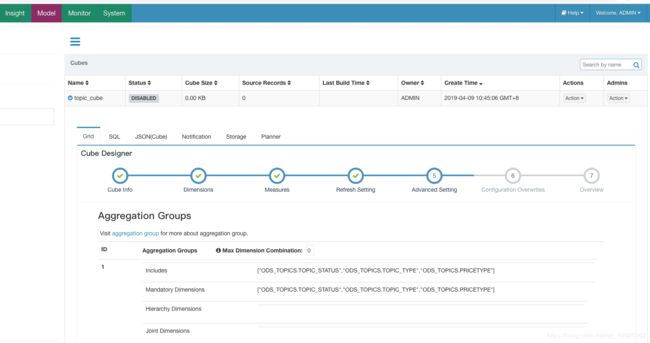
Aggregation Groups Max Dimension Combination 最大的维度组合数量
例如:维度A,B,C 那么Max Dimension Combination设置为2时,kylin只会构建AB,AC,BC,A,B,C这几种组合,ABC这种组合会被省略
Mandatory Dimensions: 必要维度,用于总是出现的维度(每个cuboid都必须包含的维度,这样一来,所有不包含此维度的cuboid都会被忽略)
Hierarchy Dimensions: 层级维度,例如 “国家” -> “省” -> “市” 是一个层级(省- 市-国这样的组合将被忽略)
Joint Dimensions:联合维度,有些维度往往一起出现,或者它们的基数非常接近(两个维度总是要一起出现)
2.4参数覆盖设置
Configuration Overwrites
Kylin 使用了很多配置参数以提高灵活性,用户可以根据具体的环境、场景等配置不同的参数进行调优;Kylin 全局的参数值可在 conf/kylin.properties 文件中进行配置;如果 Cube 需要覆盖全局设置的话,则需要在此页面中指定,这些配置项将覆盖项目级别和配置文件中的默认值。
一般需 添加属性 “kylin.engine.spark.rdd-partition-cut-mb” 其值为 "500"
2.5 cube构建操作说明
Drop:丢弃现有cube,条件:无Pending, Running, Error 状态的job.
Edit:编辑现有cube,条件:cube需处于disable状态。
Refresh:重建某已有时间段数据,针对于已build时间段的源数据发生了改变的情况。
Merge:手动触发merge操作。
Enable:使拥有至少一个有效segment的cube从disable变为enable状态。
Purge:清空所有该cube的数据。
Clone:克隆一个新的cube,可设置新的名字,其他相关配置与原cube相同。
Disable:使一个处于ready状态的cube变为Disable状态,查询不会从disable的cube中获取数据
3、cube构建过程
Cube运算的中间结果是以SequenceFile的格式存储在HDFS上
1、Create Intermediate Flat Hive Table(生成原始数据)
将数据从源Hive表提取出来(和所有join的表一起)并插入到一个中间平表,如果Cube是分区的,Kylin会加上一个时间条件以确保只有在时间范围内的数据才会被提取
2、Redistribute Flat Hive Table(重新分配中间表)
Hive在HDFS上的目录里生成了数据文件:有些是大文件,有些是小文件甚至空文件。这种不平衡的文件分布会导致之后的MR任务出现数据倾斜的问题。针对这个问题,Kylin增加了这一个步骤来“重新分发”数据
3、Extract Fact Table Distinct Columns(创建事实表distinct column文件)
4、Build Dimension Dictionary(创建维度词典)
5、Save Cuboid Statistics and create HTable(保存cuboid的统计数据和HTable)
6、Build Cube with Spark(构建cuboid)
7、Convert Cuboid Data to HFile(将cuboid数据转换为HFile)
8、Load HFile to HBase Table(将HFile导入HBase表)
9、Update Cube Info(更新cube信息)
10、Hive Cleanup(清理资源)
参考:http://kylin.apache.org/cn/docs/howto/howto_optimize_build.html
4、kafka流数据构建cube(1.5版本引入)
1、添加kafka环境变量
2、指定kafka消费主题,并输入流数据json数据样本
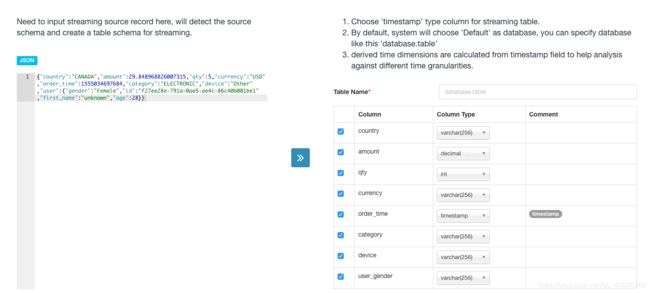
3、model以及cube的构建同hive数据源(区别在于必须对Streaming Cube进行分区)
参考:https://blog.csdn.net/a_drjiaoda/article/details/88290620
5、设置定时构建cube
5.1 通过curl方式定时调度
Kylin web 触发指令只能支持一次触发,在实际应用中,需要定时执行build任务,可以使用curl命令从后台触发cube的构建,可通过crontab 或者其他的调度工具实现
全量构建:
curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "buildType": "BUILD"}' http://host:30023/kylin/api/cubes/users_cube/build
增量构建:
curl -X PUT --user ADMIN:KYLIN -H "Content-Type: application/json;charset=utf-8" -d '{ "startTime": 1554892395, "endTime": 1554892480, "buildType": "BUILD"}' http://host:30023/kylin/api/cubes/users_cube/build
参考:RESTful API http://kylin.apache.org/cn/docs/howto/howto_use_restapi.html#authentication
5.2 通过java代码发送HTTP请求方式进行调度
代码实例:
//增量构建cube
package com.dlht.kylinDemo;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import org.apache.commons.codec.binary.Base64;
public class BuildTest {
static String ACCOUNT = "ADMIN";
static String PWD = "KYLIN";
static String PATH = "http://host:7070/kylin/api/cubes/KPI_Base_DataCppaCrcCount_test_Cube/rebuild";
public static void main(String[] args) {
System.out
.println(Put(
PATH,
"{\"startTime\": 1451750400000,\"endTime\": 1451836800000,\"buildType\": \"BUILD\"}"));
}
public static String Put(String addr, String params) {
String result = "";
try {
URL url = new URL(addr);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("PUT");
connection.setDoOutput(true);
String auth = ACCOUNT + ":" + PWD;
String code = new String(new Base64().encode(auth.getBytes()));
connection.setRequestProperty("Authorization", "Basic " + code);
connection.setRequestProperty("Content-Type",
"application/json;charset=UTF-8");
PrintWriter out = new PrintWriter(connection.getOutputStream());
out.write(params);
out.close();
BufferedReader in;
try {
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
} catch (FileNotFoundException exception) {
java.io.InputStream err = ((HttpURLConnection) connection)
.getErrorStream();
if (err == null)
throw exception;
in = new BufferedReader(new InputStreamReader(err));
}
StringBuffer response = new StringBuffer();
String line;
while ((line = in.readLine()) != null)
response.append(line + "\n");
in.close();
result = response.toString();
} catch (MalformedURLException e) {
System.err.println(e.toString());
} catch (IOException e) {
System.err.println(e.toString());
}
return result;
}
}
6、清理储存
Kylin 在构建 cube 期间会在 HDFS 上生成中间文件;除此之外,当清理/删除/合并 cube 时,一些 HBase 表可能被遗留在 HBase 却以后再也不会被查询;虽然 Kylin 已经开始做自动化的垃圾回收,但不一定能覆盖到所有的情况;可以通过定期做离线的存储清理
步骤:
1. 检查哪些资源可以清理,这一步不会删除任何东西:
export KYLIN_HOME=/path/to/kylin_home
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete false
2. 你可以抽查一两个资源来检查它们是否已经没有被引用了;然后加上“–delete true”选项进行清理。
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete true
完成后,Hive 里的中间表, HDFS 上的中间文件及 HBase 中的 HTables 都会被移除。
3. 如果您想要删除所有资源;可添加 “–force true” 选项:
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --force true --delete true
完成后,Hive 中所有的中间表, HDFS 上所有的中间文件及 HBase 中的 HTables 都会被移除。
参照:http://kylin.apache.org/cn/docs/howto/howto_cleanup_storage.html
四、用户角色分配
1、kylin定义了四种权限访问角色,ADMIN,MANAGEMENT,OPERATION和QUERY
具体角色具有的权限以及权限分配参照:http://kylin.apache.org/docs/tutorial/project_level_acl.html
2、添加用户及修改密码
修改文件: /opt/module/kylin/tomcat/webapps/kylin/WEB-INF/classes/kylinSecurity.xml
第一步:
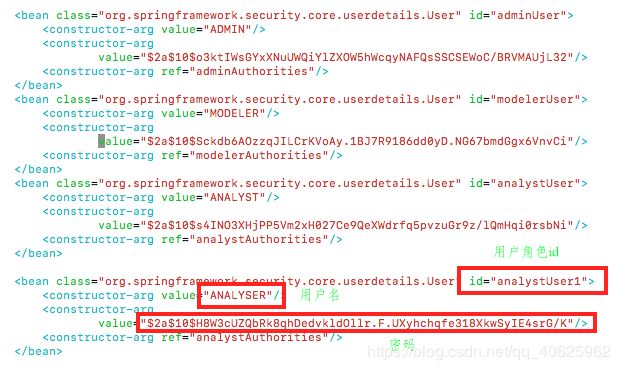
第二步:
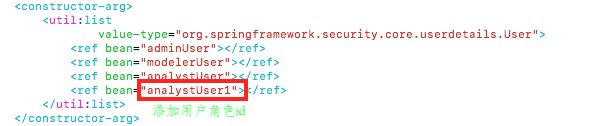
用户密码生成:
kylin密码采用spring加密:
org.springframework.security
spring-security-core
4.0.0.RELEASE
public class Authentication {
public static void main( String[] args ) {
PasswordEncoder encoder = new BCryptPasswordEncoder();
String ecode = "KYLIN";
try {
String encodedPassword = encoder.encode(ecode);
System.out.println("原始密码:");
System.out.println(ecode);
System.out.println("加密后:");
System.out.println(encodedPassword);
} catch (Exception e) {
e.printStackTrace();
} finally {
}
}
运行后生成加密后的密码,粘贴至配置文件处即可
参考:
https://blog.csdn.net/shtdayu/article/details/84579675
https://www.jianshu.com/p/39bc4cc45a87
https://www.cnblogs.com/en-heng/p/5170876.html