Theano入门神经网络(一)
Theano是一个Python库,专门用于定义、优化、求值数学表达式,效率高,适用于多维数组。特别适合做机器学习。一般来说,使用时需要安装python和numpy.
首先回顾一下机器学习的东西,定义一个模型(函数)f(x;w) x为输入,w为模型参数,然后定义一个损失函数c(f),通过数据驱动在一堆模型函数中选择最优的函数就是训练training的过程,在机器学习中训练一般采用梯度下降法gradient descent.
使用theano来搭建机器学习(深度学习)框架,有以下优点:
1、 theano能够自动计算梯度
2、只需要两步骤就能搭建框架,定义函数和计算梯度。
一、 定义函数
步骤 0 宣告使用theano import theano
步骤 1 定义输入 x=theano.tensor.scalar()
步骤 2 定义输出 y=2*x
步骤3 定义fuction f = theano.function([x],y)
步骤 4 调用函数 print f(-2)步骤1 定义输入变量
a = theano.tensor.scalar()
b =theano.tensor.matrix()
简化 import theano.tensor as T步骤2 定义输出变量 需要和输入变量的关系
x1=T.matrix()
x2=T.matrix()
y1=x1*x2
y2=T.dot(x1,x2) #矩阵乘法
步骤3 申明函数
f= theano.function([x],y)
函数输入必须是list 带[]
example:
import theano
import theano.tensor as T
a= T.matrix()
b= T.matrix()
c = a*b # 这里的两个矩阵必须完全相同,对应位置元素分别相乘
d = T.dot(a,b) # 这里的两个矩阵不必完全相同,a的列数目必须与b的行数目相同
F1= theano.function([a,b],c)
F2= theano.function([a,b],d)
A=[[1,2],[3,4]]
B=[[2,4],[6,8]] #2*2矩阵
C=[[1,2],[3,4],[5,6]] #3*2矩阵
print(F1(A,B))
print(F2(C,B))结果:
[[ 2. 8.]
[18. 32.]]
[[14. 20.]
[30. 44.]
[46. 68.]]若在batch上进行矩阵乘法运算,需要这样做,见下面的例子:
import theano
import theano.tensor as T
import numpy as np
a= T.tensor3(dtype=theano.config.floatX)
b= T.tensor3(dtype=theano.config.floatX)
tdot = T.batched_dot(a, b)
F= theano.function([a,b],tdot)
A=np.asarray([[[2,4,4],[6,8,3]],[[2,4,4],[6,8,3]],[[2,4,4],[6,8,3]],[[2,4,4],[6,8,3]]], dtype=np.float32) #2*3矩阵
B=np.asarray([[[1,2],[3,4],[5,6]],[[1,2],[3,4],[5,6]],[[1,2],[3,4],[5,6]],[[1,2],[3,4],[5,6]]], dtype=np.float32) #3*2矩阵
print('A.shape=%s' % (list(A.shape)))
print('B.shape=%s' % (list(B.shape)))
print('dot(A,B).shape=%s' % (list(F(A,B).shape)))结果:
A.shape=[4, 2, 3]
B.shape=[4, 3, 2]
dot(A,B).shape=[4, 2, 2]二、计算梯度
计算 dy/dx ,直接调用g=T.grad(y,x) y必须是一个标量 scalar
和梯度有关的三个例子:
example1 :标量对标量的导数
x= T.scalar('x')
y = x**2
g = T.grad(y,x)
f= theano.function([x],y)
f_prime=theano.function([x],g)
print(f(-2))
print(f_prime(-2))结果:
4.0
-4.0example2 : 标量对向量的导数
x1= T.scalar()
x2= T.scalar()
y = x1*x2
g = T.grad(y,[x1,x2])
f= theano.function([x1,x2],y)
f_prime=theano.function([x1,x2],g)
print(f(2,4))
print(f_prime(2,4))结果:
8.0
[array(4., dtype=float32), array(2., dtype=float32)]example3 : 标量对矩阵的导数
A= T.matrix()
B= T.matrix()
C=A*B #不是矩阵乘法,是对于位置相乘
D=T.sum(C)
g=T.grad(D,A) #注意D是求和 所以肯定是一个标量 但g是一个矩阵
y_1=theano.function([A,B],C)
y_2=theano.function([A,B],D)
y_prime=theano.function([A,B],g)
A=[[1,2],[3,4]]
B=[[2,4],[6,8]]
print(y_1(A,B))
print(y_2(A,B))
print(y_prime(A,B))结果:
[[ 2. 8.]
[18. 32.]]
60.0
[[2. 4.]
[6. 8.]]搭建神经网络
1 单个神经元
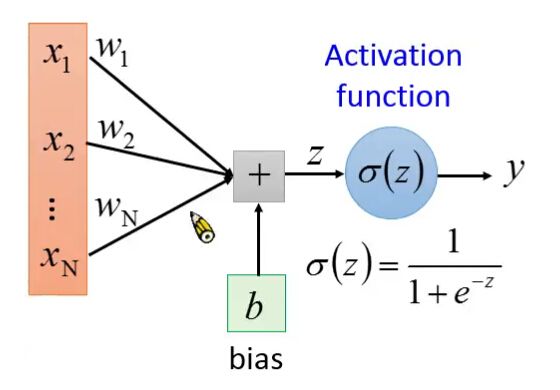
假设w b 已知。y=neuron(x;w,b)
import theano
import theano.tensor as T
import random
import numpy as np
x = T.vector(dtype=theano.config.floatX)
w = T.vector(dtype=theano.config.floatX)
b = T.scalar(dtype=theano.config.floatX)
z= T.dot(w,x)+b
y= 1/(1+T.exp(-z))
neuron =theano.function(
inputs=[x,w,b],
outputs=[y]
)
w = [-1,1]
b=0
prng = np.random.RandomState(123456789) # 定义局部种子
for i in range(5):
x = prng.rand(2,)
x = x.astype(np.float32)
print(x)
print(neuron(x,w,b))
# x=np.asarray([random.random(),random.random()], dtype = np.float32)
结果:
[0.53283304 0.5341366 ] [array(0.50032586, dtype=float32)] [0.509553 0.71356404] [array(0.5508266, dtype=float32)] [0.25699896 0.7526936 ] [array(0.621447, dtype=float32)] [0.8838792 0.15489908] [array(0.32541856, dtype=float32)] [0.6705464 0.64344513] [array(0.4932251, dtype=float32)]
w,b应该也是参数 ,上述函数改为neuron(x),model 参数 wb 应该用shared variables,改进的代码import theano
import theano.tensor as T
import random
import numpy as np
x = T.vector()
# share variables 参数!有值
w = theano.shared(np.array([1.,1.]))
b = theano.shared(0.)
z= T.dot(w,x)+b
y= 1/(1+T.exp(-z))
neuron =theano.function(
inputs=[x], # x 作为输入
outputs=y
)
w.set_value([0.1, 0.1]) #修改值
for i in range(5):
#x = [random.random(),random.random()]
x=np.asarray([random.random(),random.random()], dtype = np.float32)
print(x)
print(w.get_value()) #得到值
print(neuron(x))2 训练 training
定义一个损失函数C 计算C对每一个wi的偏导数 和b的偏导数
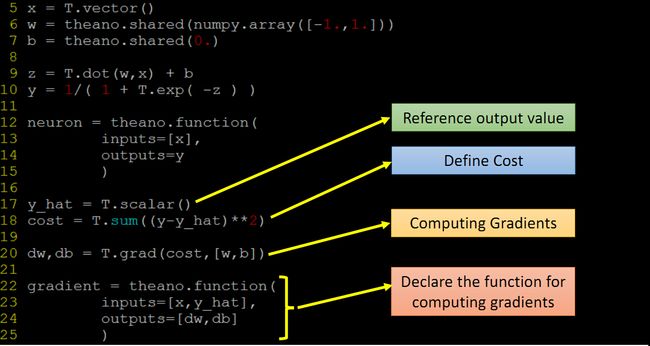
梯度下降 w1 = w1 -n*dc/dw1
常规:
dw, db =gradient(x,y_hat)
w.set_value(w.get_value()-0.1*dw)
b.set_value(b.get_value()-0.1*db)
改进:gradient = theano.function(
inputs=[x,y_hat],
updates=[(w,w-0.1*dw),(b,b-0.1*db)]