如何使用HDFS高可用性设置Hadoop集群
HDFS 2.x高可用性群集体系结构
在这个博客中,我将讨论HDFS 2.x高可用性群集体系结构以及设置HDFS高可用性群集的过程。 这个博客中的主题的顺序如下:
- HDFS HA体系结构
- 介绍
- NameNode可用性
- 医管局的架构
- HA(JournalNode和Shared Storage)的实施
- 如何在Hadoop集群中设置HA(Quorum Journal Nodes)?
介绍:
Hadoop 2中引入了高可用性集群的概念。x解决Hadoop 1.x中的单点故障问题。正如你在我之前的博客中所说的那样,HDFS体系结构 遵循主/从拓扑结构,其中NameNode作为主守护进程,负责管理其他从属节点(称为DataNode)。这个单一的主守护进程或NameNode成为一个瓶颈。虽然Secondary NameNode的引入确实避免了我们的数据丢失和卸载NameNode的一些负担,但是它并没有解决NameNode的可用性问题。
NameNode可用性:
如果考虑HDFS集群的标准配置,则NameNode将成为单点故障。发生这种情况是因为NameNode变得不可用的时候,整个集群都变得不可用,直到有人重新启动NameNode或者引起新的NameNode。
NameNode不可用的原因可以是:
- 像维护工作这样的计划事件具有软件或硬件的升级。
- 也可能是由于某种原因导致NameNode崩溃的意外事件。
在上述任何一种情况下,我们都有一个停机时间,我们无法使用HDFS集群,这成为一个挑战。
HDFS HA架构:
让我们了解一下,HDFS HA Architecture如何解决了NameNode可用性的这个关键问题:
HA架构通过允许我们在主动/被动配置中具有两个NameNode来解决NameNode可用性的这个问题。因此,我们在高可用性集群中同时运行两个NameNode:
- Active NameNode
- Standby/Passive NameNode.

如果一个NameNode发生故障,另一个NameNode可以接管责任,并因此减少集群停机时间。备用NameNode服务于备用NameNode(与Secondary NameNode不同),它将故障转移功能集成到Hadoop群集中。因此,使用StandbyNode,每当NameNode崩溃(计划外的事件)时,我们都可以进行自动故障转移,或者在维护期间可以进行优雅的(手动启动的)故障转移。
在维护HDFS高可用性集群中的一致性时有两个问题:
- 活动和备用NameNode应始终保持同步,即它们应具有相同的元数据。这将使我们能够将Hadoop集群恢复到崩溃的同一个命名空间状态,因此,将为我们提供快速故障切换。
- 一次只能有一个active NameNode,因为两个active NameNode会导致数据损坏。这种情况被称为裂脑情景,其中一个集群被分成较小的集群,每个集群相信它是唯一的活动集群。为了避免这种情况,可以进行防护。击剑是确保在特定时间只有一个NameNode保持active的。
HA体系结构的实现:
现在,您知道在HDFS HA体系结构中,我们有两个NameNode同时运行。所以,我们可以通过以下两种方式来实现Active和Standby NameNode配置:
- 使用仲裁日记节点
- 使用NFS的共享存储
让我们一次一个地理解这两种实施方式:
1.使用Quorum Journal Nodes:
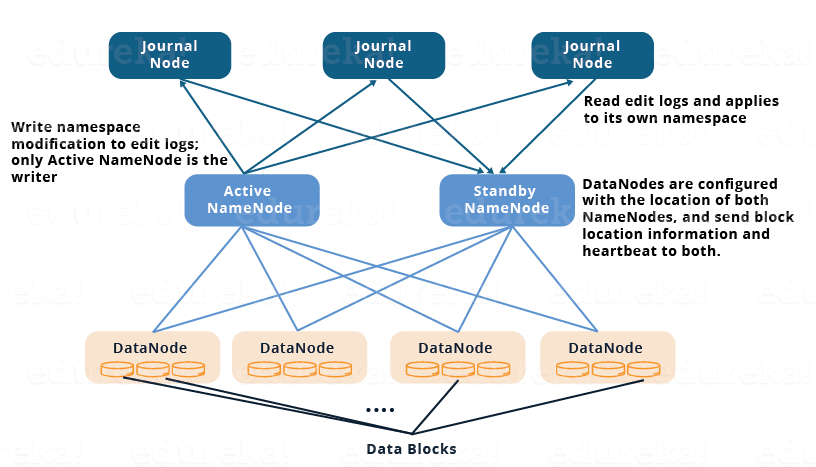
- Standby NameNode和Active NameNode通过独立的一组节点或守护进程(称为JournalNodes)保持相互同步 。 JournalNodes遵循环形拓扑,其中节点彼此连接以形成环。 JournalNode服务于请求,并将信息复制到环中的其他节点。这在JournalNode失败的情况下提供容错。
- Active NameNode负责更新JournalNodes中的EditLogs(元数据信息)。
- StandbyNode读取对JournalNode中的EditLogs所做的更改,并以固定的方式将其应用于其自己的名称空间。
- 在故障转移期间,备用节点在成为新的Active NameNode之前确保已经从JournalNodes更新了它的元数据信息。这使当前命名空间状态与故障转移之前的状态同步。
- 两个NameNode的IP地址都可用于所有DataNode,并将它们的心跳和块位置信息发送给NameNode。这提供了快速故障转移(更少的停机时间),因为备用节点具有关于集群中的块位置的更新信息。
Fencing of NameNode:
现在,如前所述,确保一次只有一个Active NameNode是非常重要的。因此,fencing是一个确保集群中这种属性的过程。
- JournalNodes通过一次只允许一个NameNode成为作者来执行此隔离。
- Standby NameNode接管写入JournalNodes的责任,并禁止任何其他NameNode保持active状态。
- 最后,新的Active NameNode可以安全地执行其活动。
2.使用共享存储:
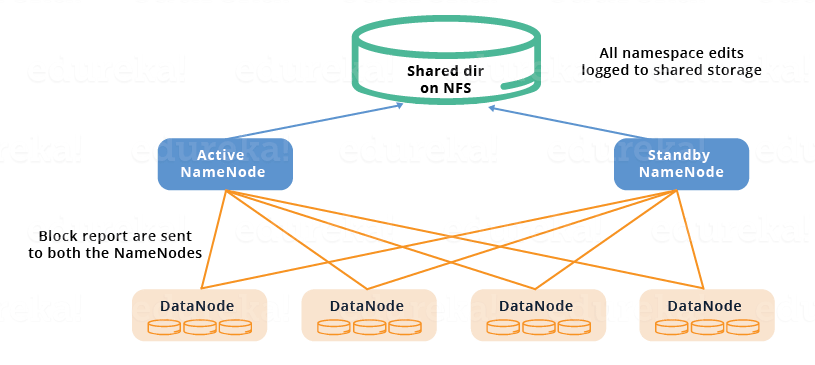
- StandbyNode和Active NameNode通过使用共享存储设备保持同步。 Active NameNode将在其名称空间中完成的任何修改的记录记录到存在于此共享存储中的EditLog。 备用节点读取对此共享存储器中EditLogs所做的更改,并将其应用于其自己的名称空间。
- 现在,在故障转移的情况下,StandbyNode首先使用共享存储器中的EditLog来更新其元数据信息。然后,它承担Active NameNode的责任。这使当前命名空间状态与故障转移之前的状态同步。
- 管理员必须至少配置一种防护方法以避免出现裂脑情况。
- 该系统可以采用一系列的栅栏机制。它可能包括杀死NameNode的进程并撤销对共享存储目录的访问。
- 作为最后的手段,我们可以使用一种叫做STONITH的技术来隔离以前Active NameNode,或者“在头部拍摄另一个节点”。STONITH使用专门的配电单元强制关闭NameNode机器。
自动故障转移:
故障切换是系统在检测到故障或故障时自动将控制权转移给辅助系统的过程。有两种类型的故障转移:
优雅的故障切换: 在这种情况下,我们手动启动故障切换进行日常维护。
自动故障转移: 在这种情况下,如果发生NameNode故障(意外事件),故障转移将自动启动。
Apache Zookeeper是一种在HDFS高可用性群集中提供自动故障转移功能的服务。它维护少量的协调数据,通知客户端数据的变化,并监视客户端的失败。Zookeeper与NameNodes保持一个会话。如果失败,会话将过期,Zookeeper将通知其他NameNode启动故障转移过程。在NameNode失败的情况下,其他被动NameNode可以在Zookeeper中锁定,表明它想成为下一个Active NameNode。
ZookeerFailoverController(ZKFC)是一个Zookeeper客户端,它也监视和管理NameNode状态。每个NameNode也运行一个ZKFC。ZKFC负责定期监控NameNode的健康状况。
既然您已经理解了Hadoop集群中的高可用性,那么现在就可以进行设置了。要在Hadoop集群中设置高可用性,您必须在所有节点中使用Zookeeper。
Active NameNode中的守护进程是:
- Zookeeper
- Zookeeper Fail Over controller
- JournalNode
- NameNode
Standby NameNode中的守护进程是:
- Zookeeper
- Zookeeper Fail Over controller
- JournalNode
- NameNode
DataNode中的守护进程是:
- Zookeeper
- JournalNode
- DataNode
在Hadoop中设置和配置高可用性群集:
您必须首先设置每个节点的Java和主机名。
| Virtual machine | IP address | Host name |
| Active NameNode/Active RM/NM | 192.168.1.81 | nn1.cluster.com or nn1 |
| Standby NameNode/Standby RM/NM | 192.168.1.58 | nn2.cluster.com or nn2 |
| DataNode/NM | 192.168.1.82 | dn1.cluster.com or dn1 |
命令: wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
解压zookeeper-3.4.6.tar.gz
命令:tar -xvf zookeeper-3.4.6.tar.gz

从Apache Hadoop站点下载稳定的Hadoop二进制tar。
命令:wget https://archive.apache.org/dist/hadoop/core/hadoop-2.6.0/hadoop-2.6.0.tar.gz

解压hadoop-2.6.0.tar.gz
命令:tar -xvf hadoop-2.6.0.tar.gz

Untar hadoop二进制。
将Hadoop,Zookeeper和路径添加到.bashrc文件。
打开.bashrc文件。
命令:sudo gedit〜/ .bashrc
添加以下路径:
export HADOOP_HOME=< Path to your Hadoop-2.6.0 directory>
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_HOME=
export HBASE_HOME=
export ZOOKEEPER_HOME =
export PATH=$PATH: $JAVA_HOME/bin: $HADOOP_HOME/bin:
$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HBASE_HOME/bin
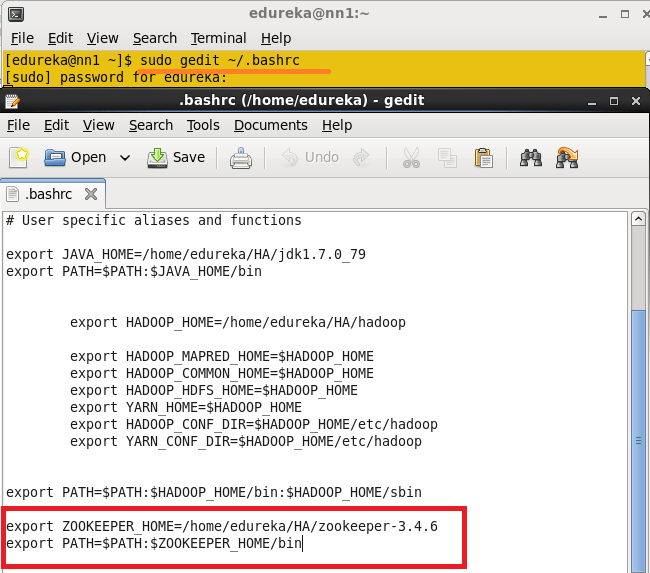
编辑.bashrc文件。
在所有节点上启用SSH。
在所有节点中生成SSH密钥。
命令:ssh-keygen -t rsa(在所有节点中的这一步)
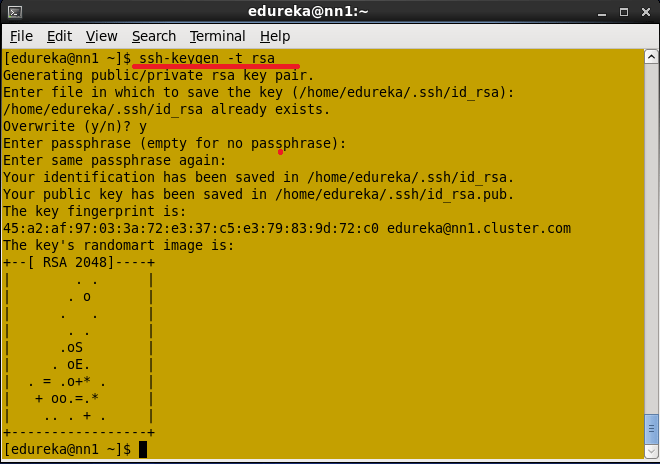
在所有节点中设置SSH密钥。
不要给Enter文件保存密钥的路径,也不要给任何密码。按回车键。
在所有节点中生成ssh密钥进程。
一旦生成ssh密钥,您将获得公钥和私钥。
.ssh密钥目录应包含权限700,.ssh目录内的所有密钥应包含权限600。

更改SSH目录权限。
将目录更改为.ssh并将文件的权限更改为600

更改公钥和私钥的权限。
您必须将名称节点ssh公钥复制到所有节点。
在Active Namenode中,使用cat命令复制id_rsa.pub。
命令:cat〜/ .ssh / id_rsa.pub >>〜/ .ssh / authorized_keys

将Namenode ssh密钥复制到授权密钥。
使用ssh-copy-id命令将NameNode公钥复制到所有节点。
命令:ssh-copy-id -i .ssh / id_rsa.pub [email protected]

将namenode密钥复制到Standby NameNode。
将NameNode公钥复制到数据节点。
命令:ssh-copy-id -i .ssh / id_rsa.pub [email protected]

将Namenode公钥复制到数据节点。
重新启动所有节点中的sshd服务。
命令:sudo service sshd restart(在所有节点中执行)
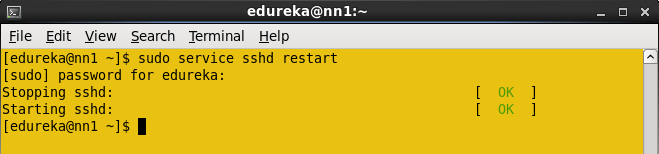
重新启动SSH服务。
现在,您可以在没有任何身份验证的情况下从Namenode登录到任何节点。
从Active Name节点打开core-site.xml文件并添加下面的属性。
从Active namenode编辑core-site.xml
fs.default.name
hdfs://ha-cluster
hadoop.tmp.dir
/software/hadoop/tmp
ha.zookeeper.quorum
nn1.cluster.com:2181,nn2.cluster.com:2181,dn1.cluster.com:2181
在Active Namenode中打开hdfs-site.xml文件。添加下面的属性。
dfs.namenode.name.dir
/software/tmp/dfs/name
dfs.datanode.data.dir
/software/tmp/dfs/data
dfs.nameservices
ha-cluster
dfs.ha.namenodes.ha-cluster
nn1,nn2
dfs.namenode.rpc-address.ha-cluster.nn1
nn1.cluster.com:9000
dfs.namenode.http-address.ha-cluster.nn1
nn1.cluster.com:50070
dfs.namenode.rpc-address.ha-cluster.nn2
nn2.cluster.com:9000
dfs.namenode.http-address.ha-cluster.nn2
nn2.cluster.com:50070
dfs.namenode.shared.edits.dir
qjournal://nn1.cluster.com:8485;nn2.cluster.com:8485;dn1.cluster.com:8485/ha-cluster
dfs.journalnode.edits.dir
/software/hadoop/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.hadoop001
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
在Active Namenode中打开mapred-site.xml文件。添加下面的属性。
mapreduce.framework.name
yarn
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
ha-cluster
yarn.resourcemanager.hostname.rm2
ha-cluster2
yarn.resourcemanager.ha.id
rm1
yarn.resourcemanager.zk-address
nn1.cluster.com:2181,nn2.cluster.com:2181,dn1.cluster.com:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
将目录更改为zookeeper的conf目录。
命令:cd zookeeper-3.4.6 / conf

Zookeeper Conf目录。
在conf目录中有zoo_sample.cfg文件,使用zoo_sample.cfg文件创建zoo.cfg文件。
命令:cp zoo_sample.cfg zoo.cfg

创建zoo.cfg文件。
在任何位置创建目录,并使用该目录存储动物园管理员数据。
命令:mkdir <路径,您要存储zookeeper文件的位置>

创建一个目录来存储zookeeper数据。
打开zoo.cfg文件。
命令:gedit zoo.cfg
将在上面的步骤中创建的目录路径添加到dataDir属性,并在zoo.cfg文件中添加有关剩余节点的以下详细信息。
Server.1 = nn1.cluster.com:2888:3888
Server.2 = nn2.cluster.com:2888:3888
Server.3 = dn1.cluster.com:2888:3888
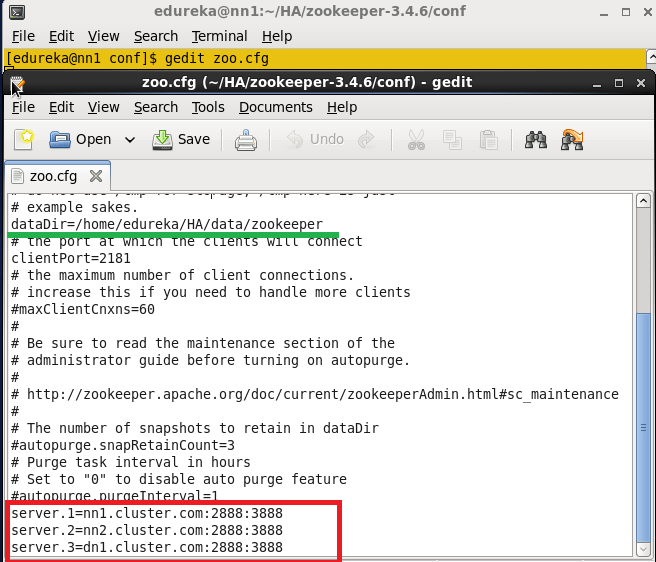
另在dataDir属性下添加zookeeper的日志目录:
dataLogDir=/home/edureka/HA/dataLog/zookeeperLog(创建在zookeeper安装目录下即可,这里不是)
编辑zoo.cfg文件。
现在使用scp命令将Java和Hadoop-2.6.0,zookeeper-3.4.6目录和.bashrc文件复制到所有节点(备用名称节点,数据节点)。
命令:scp -r <目录路径> edureka @

将Hadoop,Zookeeper和.bashrc文件复制到所有节点。
同样,将.bashrc文件和zookeeper目录复制到所有节点,并根据相应节点更改每个节点中的环境变量。
在数据节点中,创建需要存储HDFS块的任何目录。
在数据节点中,您必须添加dfs.datanode.data.dir属性。
在我的情况下,我创建datanode目录来存储块。

创建Datanode目录。
将权限更改为数据节点目录。

更改Datanode目录权限。
打开HDFS-site.xml文件,在dfs.datanode.data.dir属性中添加这个Datanode目录路径,在dfs.namenode.name.dir属性中添加这个Namenode目录路径。(上面配置中已配置)
注意:保留从活动名称节点复制的所有属性; 在namenode中添加一个提取属性dfs.datanode.data.dir和dfs.namenode.name.dir。
dfs.namenode.name.dir
/home/edureka/HA/name/namenode
dfs.datanode.data.dir
/home/edureka/HA/data/datanode
在Active namenode中,更改要存储zookeeper配置文件(dataDir属性路径)的目录。
在目录中创建myid文件并将数字1添加到该文件并保存该文件。
命令:vi myid
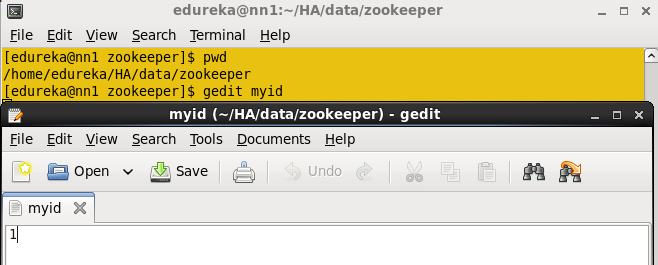
创建myid文件。
在备用名称节点中,更改要存储zookeeper配置文件(dataDir属性路径)的目录。
在该目录内创建myid文件并将数字2添加到该文件并保存该文件。
在数据节点中,更改要存储zookeeper配置文件(dataDir属性路径)的目录。
在目录中创建myid文件,并将数字3添加到该文件并保存该文件。
在所有三个节点中启动Journalnode。
命令:hadoop-daemon.sh start journalnode
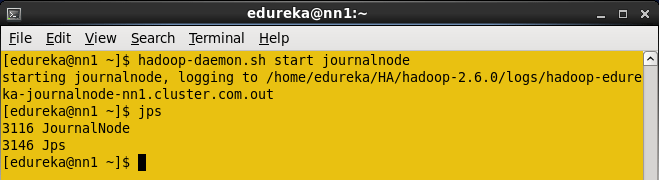
启动Journalnode。
当您输入jps命令时,您将在所有节点中看到JournalNode守护进程。
格式化活动名称节点。
命令:hdfs namenode -format

格式化活动NameNode。
在Active namenode中启动Namenode守护进程。
命令:hadoop-daemon.sh start namenode
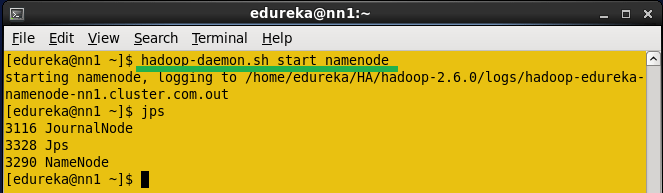
启动Namenode。
将HDFS元数据从活动名称节点复制到备用名称节点(在Standby Namenode上执行)。
命令:hdfs namenode -bootstrapStandby
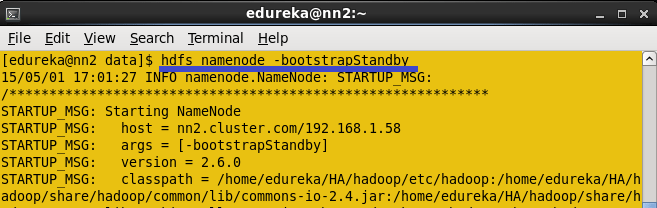
将HDFS元数据从Active name节点复制到Standby Namenode。
一旦你运行这个命令,你将得到元数据从哪个节点和位置复制的信息以及它是否成功复制。
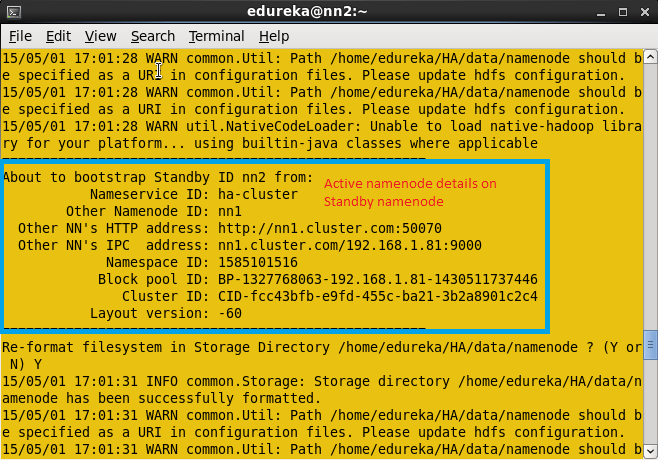
活动名称节点详细信息。
一旦元数据从活动名称节点复制到备用名称节点,您将在屏幕截图中看到如下所示的消息。
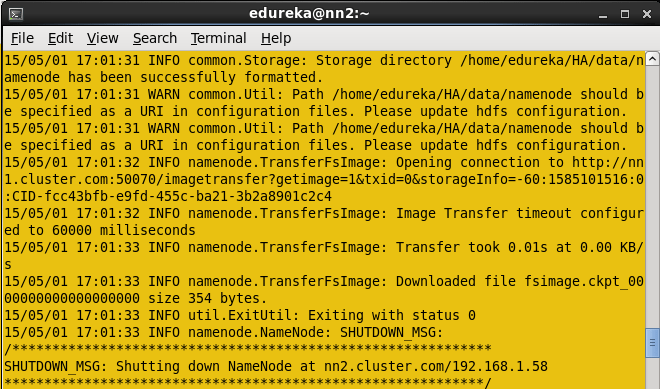
有关备用Namenode中HDFS的信息。
在Standby namenode机器上启动namenode守护进程。
命令:hadoop-daemon.sh启动namenode
现在在所有三个节点中启动Zookeeper服务。
命令:zkServer.sh start(在所有节点中运行此命令)
在活动Namenode中:

在Active NameNode中启动zookeeper。
在备用Namenode中:

在备用NameNode中启动zookeeper。
在数据节点中:

在DataNode中启动zookeeper。
运行Zookeeper服务器后,输入JPS命令。在所有节点中,您将看到QuorumPeerMain服务。
在Data node机器上启动Data node守护进程。
命令:hadoop-daemon.sh start datanode
在Active name node 和standby name node中启动Zookeeper故障切换控制器。
在Active namenode中设置zookeeper failover控制器的格式。
命令: hdfs zkfc -formatZK
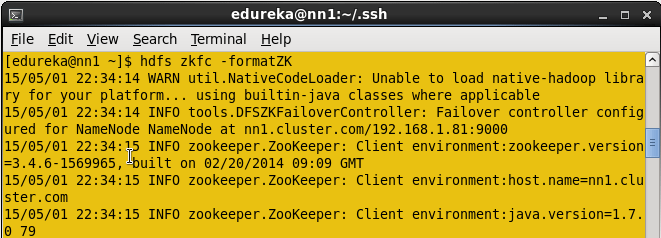
格式ZKFC。
在Standby namenode中设置zookeeper故障切换控制器。
命令:hdfs zkfc -formatZK
在Active namenode中启动ZKFC。
命令:hadoop-daemon.sh start zkfc
输入jps命令来检查DFSZkFailoverController守护进程。

开始ZKFC。
在Standby namenode中启动ZKFC。
命令:hadoop-daemon.sh start zkfc
输入jps命令来检查DFSZkFailoverController守护进程。
现在使用以下命令检查每个Namenode的状态,哪个节点处于活动状态或哪个节点处于待机状态。
命令:hdfs haadmin -getServiceState nn1
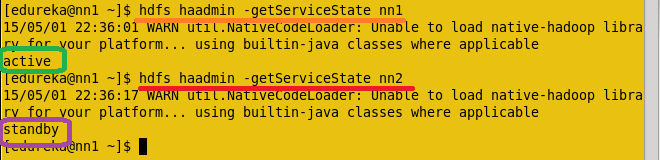
检查每个NameNode的状态。
在Active namenode中启动yarn。
命令:sbin/start-yarn.sh
在Standby namenode中启动yarn的ResourceManager进程(手动启动namenode2上的ResourceManager完成与namenode1的互备作用,不然namenode2不会自动启动ResourceManager)
命令:sbin/yarn-daemon.sh start resourcemanager
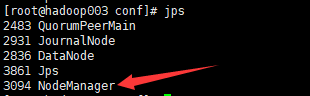
输入jps命令来检查ResourceManager和NodeManager守护进程
Active namenode上运行的进程(HMaster和另一个HRegionServer为HBase的进程,这里HRegionServer没有启动,另hadoop001对应上面的Active namenode的主机名ha-cluster,hadoop002对应Standby namenode的主机名ha-cluster2,这个是我自己配的,上面的是转博主的,不要纠结):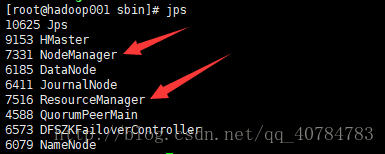
Standby namenode上运行的进程:
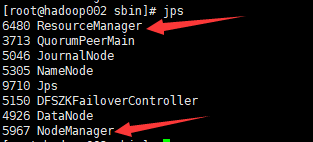
datanode上运行的进程:
现在使用网络浏览器检查每个Namenode的状态。
打开Web浏览器并输入下面的URL。
<活动Namenode的IP地址>:50070
它将显示名称节点是活动还是待命。
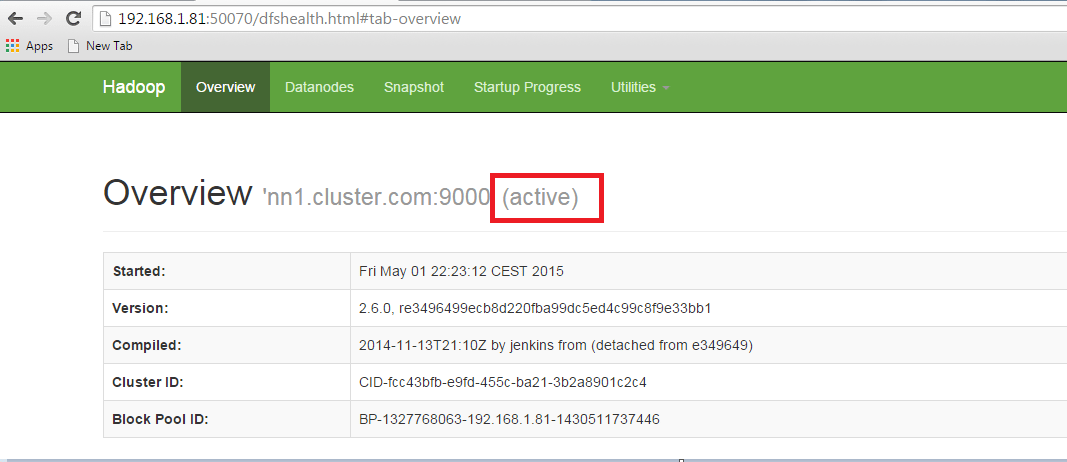
Active NameNode.
使用网络浏览器打开另一个名称节点详细信息
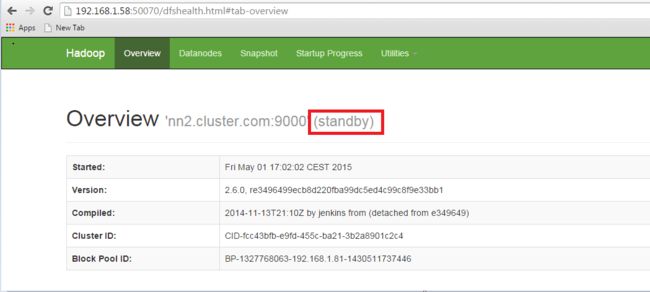
Standby NameNode.
在Active namenode中,终止namenode守护程序,将Standby name node更改为 active namenode。
在Active namenode中输入jps并杀死守护进程。
命令: sudo kill -9
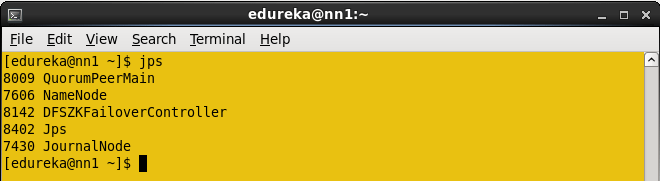
守护进程进程ID。
Namenode进程ID是7606,杀掉namenode。
命令 :Sudo kill -9 7606

杀死Name Node进程
通过网页浏览器打开这两个节点并检查状态。
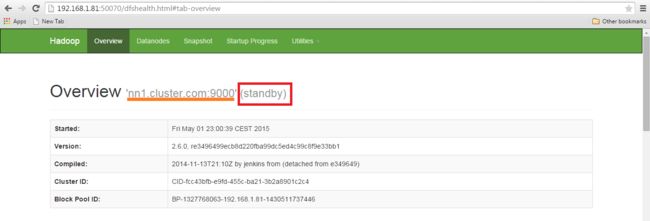
Namenode的细节。
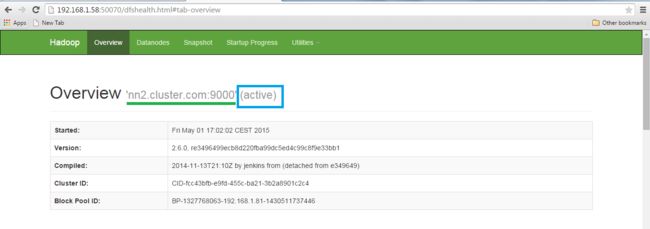
NameNode状态。
现在使用网络浏览器检查每个ResourceManager的状态。
打开Web浏览器并输入下面的URL。
<活动ResourceManager的IP地址>:8088
它将显示名称节点是活动还是待命。
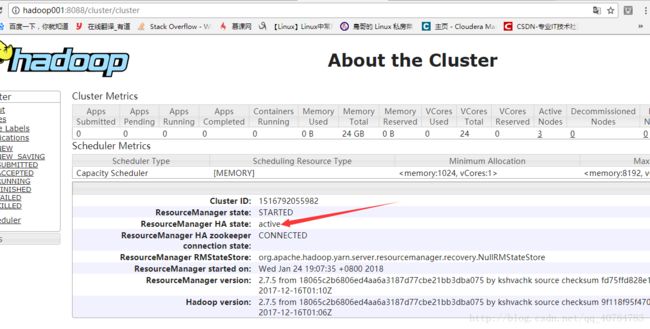
active ResourceManager。
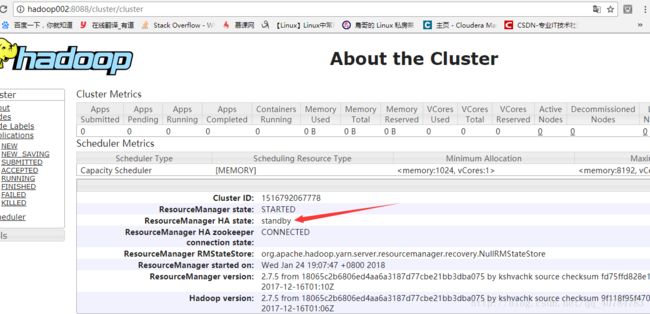
standby ResourceManager。
然后可以手动杀死active ResourceManager的进程,查看standby ResourceManager是否会改变为Active状态,会变则配置成功。
恭喜,您已经成功在Hadoop中设置了HDFS高可用性群集,不要着急,让我们一通到底,接下来是Hbase配置,加油:
在官网下载:hbase-1.2.6-bin.tar.gz,并解压在:/software目录下,改名:hbase。
配置环境变量(在文章的开头)。
这里由于资源有限,我将HBase的RegionServer部署在3个DN节点上,HBase的HMaster服务部署在NNA和NNS节点,部署2个HMaster保证集群的高可用性,防止单点问题。下面我们开始配置HBase的相关配置,这里我使用的是独立的ZK,未使用HBase自带的ZK。
- hbase-env.sh
# The java implementation to use. Java 1.7+ required. export JAVA_HOME=/software/jdk export HBASE_MANAGES_ZK=false # Extra Java CLASSPATH elements. Optional.
- hbase-site.xml
hbase.rootdir hdfs://hadoop001/hbase hbase.tmp.dir /software/hbase/tmp hbase.master 60000 hbase.cluster.distributed true hbase.zookeeper.quorum hadoop001:2181,hadoop002:2181,hadoop003:2181 hbase.zookeeper.property.dataDir /software/zookeeper/data hbase.zookeeper.property.clientPort 2181 zookeeper.session.timeout 120000 hbase.master.info.port 60010 hbase.regionserver.info.port 60030
hbase.regionserver.restart.on.zk.expire true
- regionservers
had00p001
hadoop002
hadoop003
单点问题验证
在配置完成集群后,我们开始启动集群,需要注意的时,在启动集群之前确保各个节点之间的时间是同步的,或者时间差不能太大,若时间差太大,会导致HBase启动失败。下面我们在hadoop001节点输入启动命令,命令内容如下所示:
[root@hadoop001 conf]# cd /software/hbase/bin/
[root@hadoop001 bin]# ./start-hbase.sh
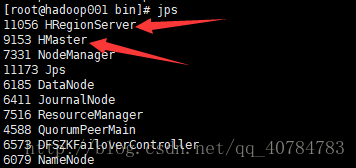
HBase的Web管理界面,配置的端口是60010,这里我先启动的是hadoop001的HMaster,所提hadoop001节点HMaster对外提供服务,截图如下所示:
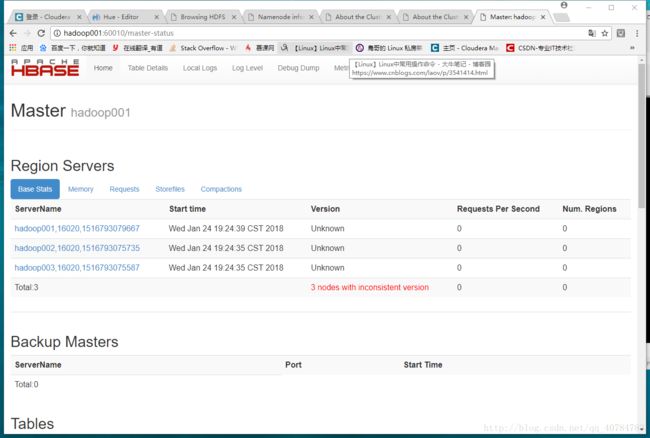
接着kill掉hadoop001节点的HMaster进程,然后,我们在查看相应的服务,由于我们使用了ZK,它会选择一个主服务出来,即hadoop002节点对外提供HMaster服务
通过验证,HBase的高可用性正常,避免存在单点问题。
这里需要注意的是,在搭建HBase集群的时候需要保证Hadoop平台运行正常,各个节点的时间差不能相差太大,最后时间能够同步。否则会导致HBase的启动失败。另外,如果在启动HBase集群时,提示不能解析HDFS路径,这里将Hadoop的core-site.xml和hdfs-site.xml文件复制到HBase的conf文件目录下即可。