sql学习
SQL学习
- 推荐学习网址
- 关系数据库
- 索引
- 将数据放入自己的mysql数据库中做练习用
- 查询语句
- and和or
- order by
- limit
- 聚合函数
- group by
- 笛卡尔积
- join
- inner join
- right outer join
- 起别名
推荐学习网址
廖雪峰老师:
https://www.liaoxuefeng.com/wiki/1177760294764384
关系数据库
我觉得,关系和数据库应该好好理解。
在关系数据库中,关系是通过主键和外键来维护的
一个库中有很多表,表与表的关系有 一对一,一对多和多对多
(一对多反过来就是多对一,不必纠结)
数据库中的每个数据表都是独立的,他们要想发生关系,就得通过外键。
外键:
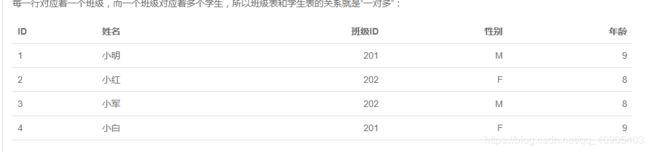
班级表:

学生表: 学生表中有班级表的id,班级id这就叫做学生表的外键。
索引
索引就像是字典目录,可以提高查询效率。但要知道他的优缺点。
-
索引的效率取决于索引列的值是否散列,即该列的值如果越互不相同,那么索引效率越高。
-
可以对一张表创建多个索引。索引的优点是提高了查询效率,缺点是在插入、更新和删除记录时,需要同时修改索引,因此,索引越多,插入、更新和删除记录的速度就越慢。
-
对于主键,关系数据库会自动对其创建主键索引。使用主键索引的效率是最高的,因为主键会保证绝对唯一。
对一个字段加索引

对多个字段加索引

唯一索引: 是查询效率最快的

将数据放入自己的mysql数据库中做练习用
-- 如果test数据库不存在,就创建test数据库:
CREATE DATABASE IF NOT EXISTS test;
-- 切换到test数据库
USE test;
-- 删除classes表和students表(如果存在):
DROP TABLE IF EXISTS classes;
DROP TABLE IF EXISTS students;
-- 创建classes表:
CREATE TABLE classes (
id BIGINT NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 创建students表:
CREATE TABLE students (
id BIGINT NOT NULL AUTO_INCREMENT,
class_id BIGINT NOT NULL,
name VARCHAR(100) NOT NULL,
gender VARCHAR(1) NOT NULL,
score INT NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 插入classes记录:
INSERT INTO classes(id, name) VALUES (1, '一班');
INSERT INTO classes(id, name) VALUES (2, '二班');
INSERT INTO classes(id, name) VALUES (3, '三班');
INSERT INTO classes(id, name) VALUES (4, '四班');
-- 插入students记录:
INSERT INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'M', 90);
INSERT INTO students (id, class_id, name, gender, score) VALUES (2, 1, '小红', 'F', 95);
INSERT INTO students (id, class_id, name, gender, score) VALUES (3, 1, '小军', 'M', 88);
INSERT INTO students (id, class_id, name, gender, score) VALUES (4, 1, '小米', 'F', 73);
INSERT INTO students (id, class_id, name, gender, score) VALUES (5, 2, '小白', 'F', 81);
INSERT INTO students (id, class_id, name, gender, score) VALUES (6, 2, '小兵', 'M', 55);
INSERT INTO students (id, class_id, name, gender, score) VALUES (7, 2, '小林', 'M', 85);
INSERT INTO students (id, class_id, name, gender, score) VALUES (8, 3, '小新', 'F', 91);
INSERT INTO students (id, class_id, name, gender, score) VALUES (9, 3, '小王', 'M', 89);
INSERT INTO students (id, class_id, name, gender, score) VALUES (10, 3, '小丽', 'F', 85);
-- OK:
SELECT 'ok' as 'result:';
查询语句
and和or
// 查询90-100的学生数据 and用来缩小查询数据范围,or用来扩大查询数据范围
SELECT
*
FROM
students
WHERE
score >= 90
AND
score <= 100
order by
SELECT
id,
NAME,
gender,
score
FROM
students
WHERE
class_id = 1
ORDER BY
score DESC;
排序可以根据多个字段排序, order by score desc,gender asc 啥意思呢?
就是 先按照分数降序排,拍完后,如果分数一样,则按照性别升序排。
limit
limit 跳过的条数,每页显示的条数
SELECT
id,
NAME,
gender,
score
FROM
students
ORDER BY
id
limit 3,3; 每页3条,跳过前三条
数据量大的时候需要分页显示,需要传入每页的数量,和页数。就可以查询相应页的数据了。
查询第一页: 3*(1-1), 3
查询第二页: 3*(2-1),3
查询第三页: 3*(3-1), 3
总结公式:
limit pageSize*(pageIndex-1), pageSize
聚合函数
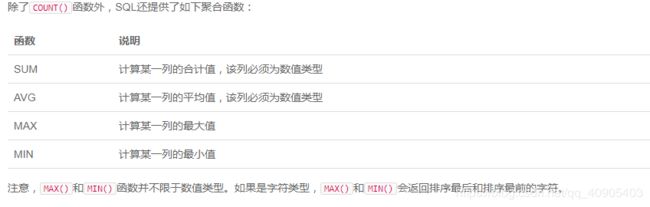
要特别注意:如果聚合查询的WHERE条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MAX()和MIN()会返回NULL:
group by
SELECT
NAME,
class_id,
COUNT(*) num
FROM
students
GROUP BY
class_id;
![]()
SELECT
class_id,
gender,
COUNT(*) num
FROM
students
GROUP BY
class_id,
gender;
having num >= 1
group by 后面不能跟where

笛卡尔积
SELECT * FROM students, classes;
这种多表查询又称笛卡尔查询,使用笛卡尔查询时要非常小心,由于结果集是目标表的行数乘积,对两个各自有100行记录的表进行笛卡尔查询将返回1万条记录,对两个各自有1万行记录的表进行笛卡尔查询将返回1亿条记录。
join
连接查询对多个表进行JOIN运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。
inner join
SELECT
s.id,
s. NAME,
s.class_id,
c. NAME class_name,
s.gender,
s.score
FROM
students s
INNER JOIN
classes c
ON
s.class_id = c.id;
INNER JOIN只返回同时存在于两张表的行数据,由于students表的class_id包含1,2,3,classes表的id包含1,2,3,4,所以,INNER JOIN根据条件s.class_id = c.id返回的结果集仅包含1,2,3。
right outer join
SELECT
s.id,
s. NAME,
s.class_id,
c. NAME class_name,
s.gender,
s.score
FROM
students s
RIGHT OUTER JOIN
classes c
ON
s.class_id = c.id;
RIGHT OUTER JOIN返回右表都存在的行。如果某一行仅在右表存在,那么结果集就会将左表用NULL填充剩下的字段。left outer join也是同样。
FULL OUTER JOIN,它会把两张表的所有记录全部选择出来,并且,自动把对方不存在的列填充为NULL:



起别名
使用别名不是必须的,但可以更好地简化查询语句。