读那些大牛的代码我们能得到什么?
读那些大牛的代码我们能得到什么?
之前在学STL的map容器,map容器的底层实现就是变种红黑树.有些好奇标准库是怎么写的,就去追根溯源了一下,然后找到了map和xtree里面,开始就看到了一个很奇怪的代码:
// map standard header
#pragma once
#ifndef _MAP_
#define _MAP_
#ifndef RC_INVOKED
#include 就是这里面的_STD_BEGIN,我的VS有提示,这个是个宏,单独放个宏占一行就有点奇怪,然后我看了一下它的替换
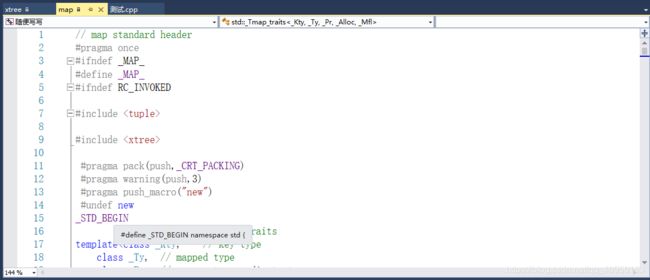
竟然是个命名空间的声明(少个右大括号),然后翻到底下,果不其然,有个_STD_END,但是我当时没懂这样做的意义何在,跟直接写是一样的,难道是为了高逼格吗?
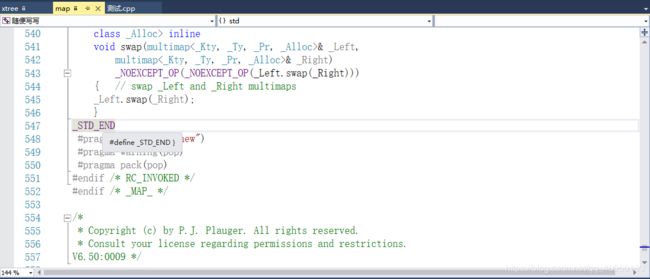
后面我想起了自己准备写的小型类库,也是需要声明命名空间把所有的代码包起来.但是我特别讨厌这个操作,因为这样一来里面的代码天然就有一层缩进了,并且随着里面的代码渐渐复杂,缩进会越来越多.可能在某个地方,百分之八九十都是缩进,读代码的人不得不频繁拖动左右进度条来浏览.
早就听过一些大牛利用宏写自己的新特性,这可能就是新特性吧,我给它取名为无缩进特性.库中不少地方都用了这个特性.
void _Construct()
{ // construct head node, proxy
_Myhead() = _Buyheadnode();
_TRY_BEGIN//宏定义:#define _TRY_BEGIN try{
_Alloc_proxy();
_CATCH_ALL//宏定义:#define _CATCH_ALL }catch(...){
_Freeheadnode(_Myhead());
_RERAISE;//宏定义:#define _RERAISE throw
_CATCH_END//宏定义:#define _CATCH_END }
}
比如利用宏把C++异常处理的代码取消缩进.
特性不止一种,我把下面的特性称为删减特性.这个_DEBUG_RANGE(_First, _Last);也就是常说的宏函数,我在由Nginx源码写双向循环链表一文中就写了宏函数,它可以实现一些小型的功能并且可以不用像普通函数一样占太多行,通过宏的名字即可知道它的功能,读者可以不必(强行)了解其实现就可使用其功能.
template<class _Iter>
void insert(_Iter _First, _Iter _Last)
{ // insert [_First, _Last) one at a time
_DEBUG_RANGE(_First, _Last);
for (; _First != _Last; ++_First)
emplace_hint(end(), *_First);
}
这一行_DEBUG_RANGE_PTR(_First, _Last, _Dest);,我把它称为组合特性.
template<class _InIt,
class _FwdIt> inline
_FwdIt uninitialized_copy(_InIt _First, _InIt _Last,
_FwdIt _Dest)
{ // copy [_First, _Last) to raw [_Dest, ...)
_DEPRECATE_UNCHECKED(uninitialized_copy, _Dest);
_DEBUG_RANGE_PTR(_First, _Last, _Dest);
return (_Uninitialized_copy1(_Unchecked(_First), _Unchecked(_Last),
_Dest, _Iter_cat_t<_InIt>(), _Iter_cat_t<_FwdIt>()));
}
宏定义跳转:
#define _DEBUG_RANGE_PTR(first, last, ptr) \
_DEBUG_RANGE_PTR_IMPL(first, last, ptr, _FILENAME, __LINE__)//增加的两个参数也是宏
组合特性通过宏的组合,让调用者只关心传入的参数而不必关注也不必写固定的参数.库中不少这样的用法都是用来DEBUG,一层层追溯下去我也看不懂了,只能讲解到这了.
最后来看看他们的代码风格,所有的命名都是见名知义的,比如模板定义template这一看就知道第一个是存放的值的类型,第二个是一个指针类型.
template<class _Value_type,
class _Voidptr>
struct _Tree_node
{ // tree node
_Voidptr _Left; // left subtree, or smallest element if head
_Voidptr _Parent; // parent, or root of tree if head
_Voidptr _Right; // right subtree, or largest element if head
char _Color; // _Red or _Black, _Black if head
char _Isnil; // true only if head (also nil) node
_Value_type _Myval; // the stored value, unused if head
private:
_Tree_node& operator=(const _Tree_node&);
};
什么地方写注释,注释除了让代码易读外其实还有一个功能:在代码复杂的时候可以快速定位代码,注释里加一些特殊的标记,这样你就可以通过Ctrl+F快速查找到你的标记从而定位代码.
一行代码不要太长,不换行代码的总行数是减少了,但是代码变得难读,比如一个if语句里有很多条件,把它们一行排开不仅可能出现左右进度条,而且读代码的人的思路会中断.因为人们的大脑总是认为独立一行的内容有相关性,且瞬时记忆的量没有那么大,这就导致试图把所有条件一起记忆并寻找关联,最终反复阅读才能理解.
功能不相关的用空行分开,比如上面的代码,private上面空行把属性和方法,public和private分开来(结构体默认成员权限是public),所有代码挤在一起看的真的难受!
最后
本篇内容纯属本人自己的感悟,没有任何参考,所以难免有理解不到位的情况,如果各位看官们有更好的理解请大胆分享在在评论区.
那些极其巧妙的思路,绝妙的代码需要花时间细品,有时间我会多看看标准库的源码的.