论文解读: | (CVPR2019)《Feature Denoising for Improving Adversarial Robustness》
论文解读: | (CVPR2019)《Feature Denoising for Improving Adversarial Robustness》
首先,奉上论文和代码:
论文链接: Feature Denoising for Improving Adversarial Robustness
代码链接: https://github.com/facebookresearch/ImageNet-Adversarial-Training
研究方向:Adversarial attack
发表会议:CVPR 2019

[如有任何错误,还请大家指正,以免误人子弟!]
\quad 最近,由于课题组论文分享汇报需要,接触了AI Security 这一领域(隶属于 Universal Adversarial Attack)。
\quad 找了下最近几年顶会发表的相关论文,也读了下最新的 综述(Survey),其中不乏新颖的idea和研究方向,这里,先从这篇由 Facebook AI Research 发表的 Feature Denoising for Improving Adversarial Robustness 开始。
\quad ps:这里说下,选这篇论文作为开篇的原因: 因为,在作者列表里看见了 Kaiming He,虽然只是二作,但既然有恺神,那么这篇paper的质量绝对不会差,而且实验结果一定有保障。
首先,介绍下 对抗攻击 (Universal Adversarial Attack) 的一些概念吧。
0. Basic Conception
首先说下,对抗攻击 的概念:
1. 对抗攻击(Adversarial Attack)
针对图像分类系统 (classification system) 进行对抗攻击,其攻击方式是通过对原始图像加入微小的扰动(perturbation)而使系统做出错误的预测(prediction)。
由 攻击背景 对 对抗攻击(Adversarial Attack) 的种类进行划分:
2. 白盒攻击(White-box Attack)
神经网络攻击者对要攻击的模型的网络架构,网络权重,防御方法等信息了如指掌。
\quad 这里说明下,攻击者掌握模型信息的途径:1. 间谍泄露信息。2. 该模型外包给MLaaS公司进行训练,由外包公司泄露。2. 该模型从零开始训练,攻击者对数据集进行篡改,进行了数据投毒。
\quad 有关对DNN的攻击方式划分,我已整理并发布到了 CSDN资源: AI攻防种类整理 ,大家如果感兴趣,可以下载查看。
3. 黑盒攻击(Black-box Attack)
黑盒攻击与白盒攻击正好相反,攻击者对模型一无所知,只能通过模型的输入 / 输出反馈有限的获取到模型的内部信息,并利用有限的信息进行攻击。
4. 灰盒攻击(Gray-box Attack)
攻击者只掌握模型的部分信息,如,只知道模型的网络架构,但并不知道网络权重。
由 攻击目的 对 对抗攻击(Adversarial Attack) 的种类进行划分,
5. 有目标攻击
攻击者对模型进行定向攻击,使模型进行定向错误预测。如,对原始图像植入攻击扰动(Attack Perturbation),使模型对任何植入扰动的图像都预测为 飞机(plane).
6. 无目标攻击
攻击者对模型进行不定向攻击,攻击者只能使模型进行错误预测,而无法使模型进行定向错误预测。
从 扰动强度(Perturbation Intensity) 对 对抗攻击(Adversarial Attack) 的种类进行划分,可分为:
1. 无穷范数( L ∞ L_{\infty} L∞)攻击;
2. 二范数( L 2 L_{2} L2)攻击;
3. 零范数( L 0 L_{0} L0)攻击;
从 攻击实现方式 ,对 对抗攻击(Adversarial Attack) 的种类进行划分,可分为:
1. 基于 梯度 的攻击:如,PGD(Project Gradient Descent);
2. 基于 优化 的攻击
3. 基于 决策面 的攻击
等等;
了解了对抗攻击的基本概念之后,我们进入本文的正题,开始表演!
1. Idea的由来
现象:
图像上的对抗性扰动(adversarial perturbation)将会在网络构造的特征(feature)中产生噪声(noise)。
在对 对抗性图像(adversarial image) 的 特征图(Feature Map) 和 原始图像(clean image) 的特征图进行可视化对比之后,我们可以发现它们之间的巨大差异:
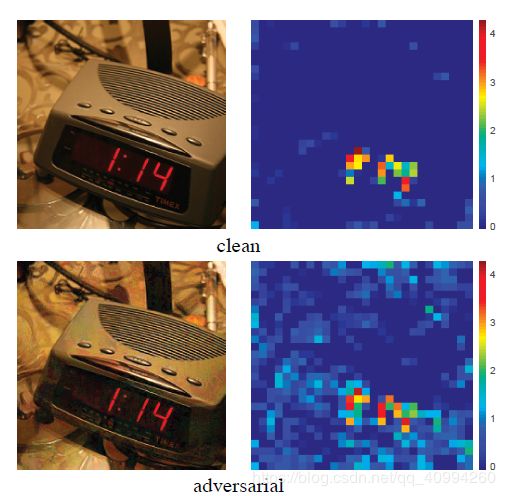
\quad 由图我们可以看到,对抗性图像的特征图较原始图像相比,存在着非常多的无关噪声,即使在图像中没有相关 语义信息(semantic information) 的的区域依旧存在 激活(activation)—— 噪声(noise),也正因因此,网络才会产生 误判(incorrect prediction)!
\quad 在做实验的过程中,发现了有趣的实验现象(问题),从而探究产生这种现象的原因,再到,想出相应的 idea,然后生成相应的解决方案,实验验证idea work,发表paper!
这篇论文充分阐述了论文 idea 的产生过程:
\quad 做实验 → \rightarrow → 发现问题 → \rightarrow → 探究原因 → \rightarrow → 产生idea → \rightarrow → 实验验证 → \rightarrow → idea work! → \rightarrow → 发表paper.
\quad 在阐述论文的解决方案之前,先对 网络攻击(network attack) 的具体细节以及现有的 相关工作(related work) 进行梳理和说明。
- 扰动(perturbation): 图像中人眼不易察觉的小噪声或微小变化。

\quad 大家可以肉眼感受下,在没有文字标注的情况下,是否能够感受到加入了扰动的 Adversarial image 与 clean image 的差别。
\quad 这种 扰动(perturbation) 被攻击者广泛采用的原因是,即便是 像素空间(pixel space) 内很小的对抗性 扰动(perturbation),在经网络层层传播后,会在 特征图(feature map) 中产生大量的 噪声(noise) 并且,即使是目前最为成功的CNN,这种对抗性 扰动(perturbation) 攻击依然很有效。
\quad 而且,对抗攻击会对现实世界中的CNN应用构成安全威胁。(ps: 大家可以试想下,攻击者定向攻击金库的人脸识别系统,导致任意一张脸都可以被识别成功,从而打开金库,其后果。。。)
然而,最重要的是,这证明了深度神经网络DNN与人脑的计算方法完全不同。尤其视觉系统的计算方法与CNN完全不同,因此,针对对抗攻击的研究,可以促进 深度学习可解释性 工作的推进!
这里对特征图上的像素信息做下说明: (下图是一张 clean image)
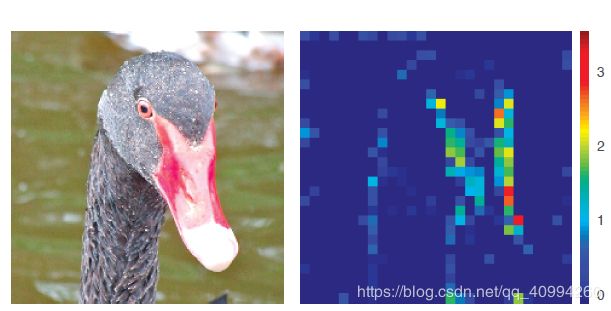
我们可以看到,clean image 的 特征(feature) 主要集中在图像中的 语义信息(semantic information) 内容上。
这里,说明下语义信息的概念:
语义信息(semantic information): 即图像中每个像素所属的对象类别,这个对象类别所代表的含义即为语义信息。

我们再看 adversarial image 对应的 特征图(feature map):
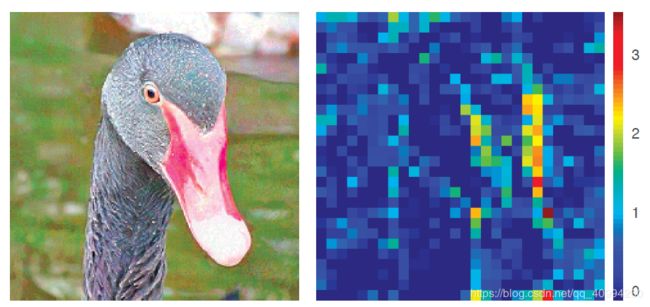
我们可以看到,对抗性图像(adversarial image) 的特征图在语义无关的区域也被 激活(activated) ,这正是网络产生误判的原因;而其根本原因是,对抗性扰动产生了大量噪声,甚至影响到了 clean image 原有的 feature map 中所含有的像素信息,从而导致了错误预测的发生!
几个提高 对抗鲁棒性(Adversarial robustness) 的模型:
-
ALP(Adversarial Logit Pairing): 由于该模型具有争议性,后期还被撤稿,此处不再详述。
-
pixel denoising: 应用 高级特征(high-level feature) 指导像素去噪。
-
不可微分(non-differentiable) 的图像处理: 通过 image quilting, total variance minimization, quantization 等图像处理方法来提高对抗鲁棒性。
以上各方法一般只能提高针对**黑盒攻击(black-box attack)**的鲁棒性,但对于 白盒攻击(white-box attack) 则无能为力,因为攻击者可以近似出它们 不可微分(non-differentiable) 的 梯度(gradient)。
- our model:
- 直接 在特征上去噪 (而非在 高级特征(high-level) 上去噪);
- 可微分(攻击无法近似梯度);
- 在很强的 白盒攻击(white-box attack) 下,依然提高模型的 对抗鲁棒性(Adversarial robustness);
3. Core Solution
3.1 Feature Noise
对抗性图像(Adversarial Image) 是通过对 Clean Image 加入 扰动(perturbation) 产生的。
扰动(perturbation) 程度由 范数(norm) 以及 ϵ \epsilon ϵ 的大小共同决定。
随着图像在 神经网络(neural network) 中传播,对抗性图像引起的 特征扰动(feature perturbation) 会逐渐增加。
ps: 这里着重说明下 特征扰动(feature perturbation) 的含义:
\quad 此处的 特征扰动(feature perturbation) 指,由于对抗性图像的噪声,神经网络学习到的 “特征(feature)” 会被干扰,导致神经网络学习到一些在clean image 上根本不存在的 “特征(feature)”。
再解释的直白些就是,数据(Data) 决定了 神经网络(Neural Network) 学习到的东西!
下图为CNN学习到的特征各个层学习到的特征示例,我们可以看到,随着网络的层层传播,越到后面,网络就愈会学习到一些更加 高级的特征(high-level feature)。
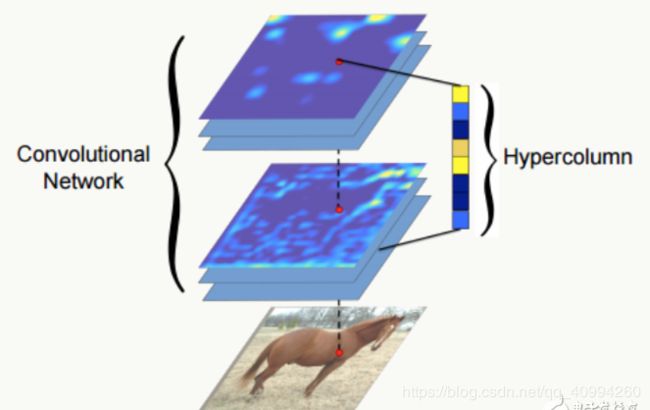
将CNN的第1、4、7层的feature map以及第1, 4, 7, 10, 11, 14, 17层的feature map分别做平均,可视化结果如下:

通过对上述图像的观察,我们可以知道,神经网络所学习到的 特征(feature) 到底是什么!
另外,对抗性图像(adversarial image) 经过神经网络的层层传播后会恶化原本微小的 扰动(perturbation) .
并且,adversarial image 会在 clean image 的 特征图(Feature Map) 上增加原本不存在的 激活(activation),从而导致神经网络产生 “幻觉”, 这种产生幻觉的 激活(activation) 会压制原始clean image 特征图中由真实信号 (true signal) 产生的激活 激活(activation);从而造成神经网络的错误预测(incorrect prediction)。
ps:
此处, 说明下 true signal 和 activation 的含义:
-
真实信号(true signal):可以理解为原始图像(clean image)上具有的有意义的像素信息。 -
激活(activation):如果 特征图(Feature Map) 中明显存在的 激活(activation) ,则意味着,在图像的相应位置存在 语义信息(semantic information)。
下图圈定的内容中,左图表示 true signal,右图表示 activation.

下图所示为,Adversarial Image对应在特征图上产生的原本clean image并不存在的 激活(activation).
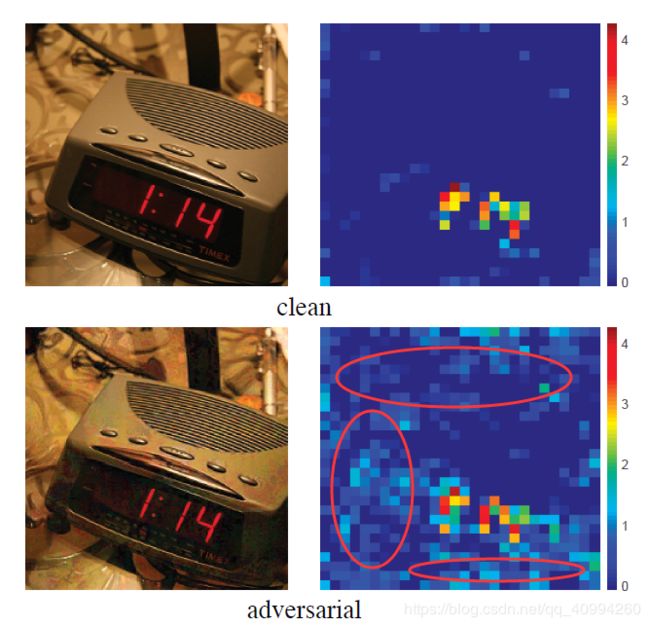
正因为实验现象的出现,才会思考解决问题的方案;feature denoising应运而生。
feature denoising 的作用是:抑制 特征图(Feature Map) 上的大量多余噪声,并且使 响应(response) 集中在视觉上有意义的内容上。(ps:笔者认为,此处的 响应(response) 可以理解为 激活(activation).)
而且,无论是在主观上,还是在paper的实验部分,都可以发现,feature denoising会是提高模型鲁棒性的一个很好的研究方向。
在进入下一部分前,还需要阐述 feature noise 的一些问题:
- 纵然特征图可以很容易地被定性地 观察(observed) 到,但很难定性地 度量(measure) 特征图上的噪声。
- 很难比较不同模型间的特征噪声级别,尤其是当网络结构以及训练方法改变时, 度量变得异常艰难。
但不可否认的是,可观察到的 特征噪声(feature noise) 的出现会反映出与对抗性图像有关的真实现象。
3.2 Denoising Feature Maps
\quad 上一部分的结尾,我们提到了feature denoising,这是本文的核心思想,而 消除特征图上的噪声 ,将会成为feature denoising的最主要工作、目标。
主要方式如下:
- 在卷积网络的中间层加入去噪模块以增强对抗的鲁棒性。
- 将去噪模块与其他网络层联合性的使用对抗性训练以端到端的方式进行训练。
- 端到端(End-to-End) 的对抗训练网络,从而实现部分消除依赖于数据的特征图噪声。
- 通过考虑前面层的变化如何影响后面的“特征 / 噪声分布”,去噪模块可以自然的处理通过多个网络层的噪声。(ps: 这解决了微小噪声会被层层放大的问题)
\quad 下面将对 Denoising Feature Maps 进行详述:
3.2.1 Denoising Block
首先阐述,Denoising Feature Maps 操作的核心模块 —— Denoising Block:
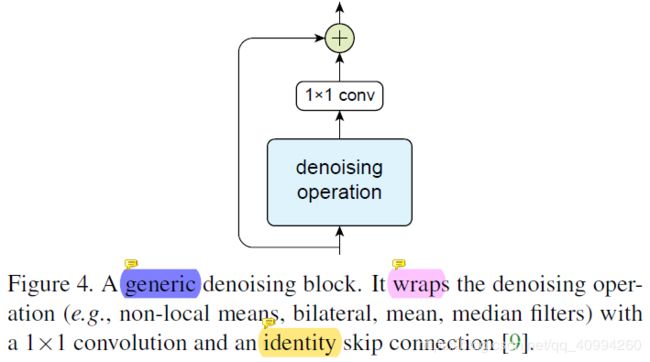
上图为 Denoising Block的模块结构,包括 残差链接(skip connection)、denoising operation以及 1x1 conv.
具体处理流程是:
- denoising operation 首先使用 非局部均值(non-local mean) 对输出特征进行处理.
- 去噪后的特征再被1x1的卷积处理.
- 然后通过残差连接加入到块的输入中.
这种模块结构是受到Transformer的self-attention机制,以及no-local network的non-local mean操作启发设计的。
实际上,去噪模块中,只有非局部均值(non-local)操作实现了去噪功能。1x1 conv. 和残差连接主要用于特征合并;
并且,当去噪操作压制噪声时,同时也会影响图像的真实信号(signal), 残差操作的使用可以帮助保留信号(signal).
到了这里,其实不禁会有个疑问:
Q1: “即使残差操作可以保留信号(signal),那么去噪模块是如何判断哪些是噪声(noise),哪些是真实信号(true signal)的呢?会不会在去噪的时候将削弱真实信号的存在?”
ans: paper中对于模块如何权衡是进行移除噪声(noise)还是保留信号(signal)是这样阐述的:
由 1x1卷积 判断进行 移除噪声(noise) 操作还是 保留信号(signal) 操作. (卷积由端到端的完整网络学习)。
此处不过多阐述1x1卷积的作用,后文会有总结。
不过可以确定的是,残差连接(residual connection) 与 1x1 conv. 都有助于提高去噪模块的有效性。
并且由于去噪模块各个部分是模块化的,因此,我们可以探索更多去噪操作。尝试更多种类的filter,试试看能不能得到更好的结果。
3.2.2 Denoising Operations
这一部分,我们将尝试在 Feature Denoising 的 denoising operation 模块中尝试几种不同的去噪过滤器(denoising filter),并根据最后实验结果的优劣进行判断具体选择哪一个filter。
-
Non-local means(非局部均值):
非局部均值(Non-local means) 通过采集 特征图(Feature Map) 中的所有空间坐标点 L \mathcal{L} L 的特征加权均值,来计算输入特征图 x x x 的 去噪(Denoised) 特征图 y y y。
Non-local means 的计算方法如下:
y i = 1 C ( x ) ∑ ∀ j ∈ L f ( x i , x j ) ⋅ x j y_{i}=\frac{1}{\mathcal{C}(x)} \sum_{\forall j \in \mathcal{L}} f\left(x_{i}, x_{j}\right) \cdot x_{j} yi=C(x)1∀j∈L∑f(xi,xj)⋅xj
L : 特 征 空 间 坐 标 点 C ( x ) : 正 则 化 ( n o r m a l i z a t i o n ) 函 数 f ( x i , x j ) : 特 征 依 赖 加 权 ( f e a t u r e − d e p e n d e n t w e i g h t i n g ) 函 数 . \quad \mathcal{L}: 特征空间坐标点 \\ \mathcal{C}(x): 正则化(normalization) 函数 \\ f\left(x_{i}, x_{j}\right): 特征依赖加权(feature-dependent weighting) 函数. L:特征空间坐标点C(x):正则化(normalization)函数f(xi,xj):特征依赖加权(feature−dependentweighting)函数.
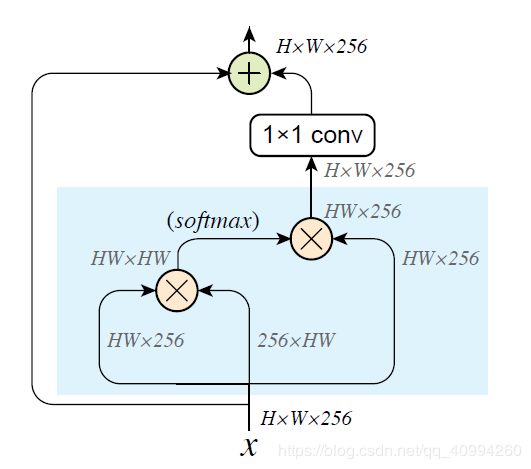
\quad 不同于 Transformer 和 No-local Network,Non-local means 会直接在输入特征 x x x 上进行去噪(denosing),并且对应的介于输入 x x x 与输出 y y y 之间的 特征信道(Feature Channels) 将会被保留。
\quad 由于 Non-local Network 取得了非常好的效果,因此,论文结合了 Non-local Network 中阐述的方法,考虑了两种 f ( x i , x j ) f\left(x_{i}, x_{j}\right) f(xi,xj) 和 C ( x ) \mathcal{C}(x) C(x) 的结构组合:
1.
Gaussian (softmax) sets f ( x i , x j ) = e 1 d θ ( x i ) T ϕ ( x j ) , C = ∑ ∀ j ∈ L f ( x i , x j ) \text {Gaussian (softmax) sets } f\left(x_{i}, x_{j}\right)=e^{\frac{1}{\sqrt{d}} \theta\left(x_{i}\right)^{\mathrm{T}} \phi\left(x_{j}\right)}, \\ \mathcal{C}=\sum_{\forall j \in \mathcal{L}} f\left(x_{i}, x_{j}\right) Gaussian (softmax) sets f(xi,xj)=ed1θ(xi)Tϕ(xj),C=∀j∈L∑f(xi,xj)
2.
Dot product sets f ( x i , x j ) = x i T x j , C ( x ) = N \text { Dot product sets } f\left(x_{i}, x_{j}\right)=x_{i}^{\mathrm{T}} x_{j},\\ \mathcal{C}(x)=N Dot product sets f(xi,xj)=xiTxj,C(x)=N
其中N为 x x x 中的像素个数。
下图为基于 non-local means 的去噪模块的实现,其由Non-local Network进行改编得到:
-
Bilateral filter(双侧过滤器):
Bilateral filter 是1998 在 ICCV 上提出的方法,虽然已经提出了很久,但是对于一些应用依然非常有效,尤其适用于 边缘保护去噪(edge-preserving denoising).Bilateral Filter 定义如下:
y i = 1 C ( x ) ∑ ∀ j ∈ Ω ( i ) f ( x i , x j ) ⋅ x j y_{i}=\frac{1}{\mathcal{C}(x)} \sum_{\forall j \in \Omega(i)} f\left(x_{i}, x_{j}\right) \cdot x_{j} yi=C(x)1∀j∈Ω(i)∑f(xi,xj)⋅xj -
Mean filter(均值过滤器):
均值滤波器亦即 步幅(stride) = 1 的平均池化(average pooling)。

虽然 平均池化(average-pooling) 可以消除 噪声(noise) ,但同时也会使结构变 平滑(smoothly);因此,可能相较于 加权(weighted) 滤波器,它的 效果(effect) 要差很多.但,实验结果证明,均值过滤器依旧可以提高 对抗鲁棒性(adversarial robustness) .
-
Median filter(中值过滤器):
中值过滤器善于移除 椒盐噪声(salt-and-pepper noise) 和同类异常值;
但在深度学习中,中值滤波器很少被使用;但通过实验证明,使用中值滤波器作为去噪操作也可以提高 对抗鲁棒性(adversarial robustness) .Median Filter 定义如下:
y i = median { ∀ j ∈ Ω ( i ) : x j } y_{i}=\operatorname{median}\left\{\forall j \in \Omega(i): x_{j}\right\} yi=median{∀j∈Ω(i):xj}
3.3 Adversarial Training
这篇paper达到了全新的SOTA,并且取得了非常好的结果;其中的很大一部分原因是因为采用了 对抗性训练(Adversarial Training) 对基线模型和特征去噪模型进行 训练(training)。
- 对抗性训练(Adversarial Training) 的基本 思想(idea) ,即在对抗性扰动图像(adversarially perturbed image) 上训练网络(对抗性扰动图像(adversarially perturbed image)由给定的白盒攻击者基于当前模型的参数来生成).
此处,使用 PGD(Projected Gradient Descent) 作为 白盒攻击者(white-box attack).
1. PGD attack的超参数:
\quad 1. maximum perturbation
\quad 2. attack step size
\quad 3. number of attack iterations
2. 通过clean image得到adversarial image,或者在允许的 ϵ \epsilon ϵ 内随机初始化。
在对抗训练过程中,随机选择这两种初始化方法: 20% 使用1,80% 使用2.
- Distributed training with adversarial images: 分布式训练对抗性图像
基本技巧如下:- 对于每个mini-batch, 使用PGD来生成对抗性图片.
- 在扰动图像上执行单步SGD,并更新模型权重.
- mini-batch不包含clean image,SGD更新专门基于对抗性图片.
- SGD更新之前是n步PGD.
- 在128个GPU上使用同步SGD执行分布式训练。
4. Experiment Analysis
这篇paper中的 对抗性扰动(adversarial perturbation) 采用的是 L ∞ L_{\infty} L∞ 范式(每个像素的最大差值)下的对抗性扰动 ϵ \epsilon ϵ 的允许最大值, ϵ \epsilon ϵ 的值是相当于像素强度缩放256倍。
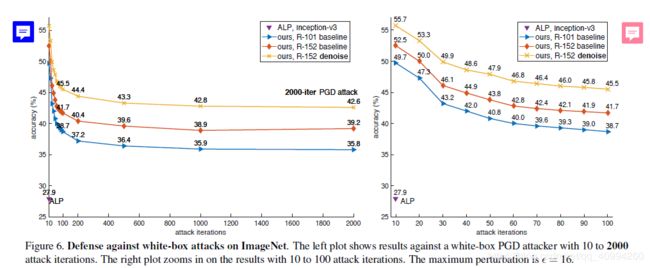
1. Against White-box Attacks
白盒攻击实验结果如下:
2. Against Black-box Attacks
黑盒攻击结果如下:

由于最近比较忙,所以,实验部分以及一些附加的概念之后再做详述,之后会出一篇分析paper源码的博客,大家可以点点关注。
3. Denoising Blocks in Non-Adversarial Settings
这一部分主要阐述两点:
- 去噪模块在需要对抗鲁棒性的设定中具有特殊的优势。
- 对抗性训练(adversarial training)与 clean训练(clean training)之间的 权衡(tradeoff) 将是未来研究的主题。
Improvement points
说了这么多,最后总结下论文的改进点吧:
- idea: 对抗性图片的特征图的噪声现象。
- 一些网络结构(去噪模块)对于对抗鲁棒性的提高是很有用的(即便没有提高准确率)。
- 当clean model与对抗训练相结合时,特有的架构设计对于模拟潜在的对抗图片的分布是更恰当的。
- 未来的研究方向:设计具有“特有的”的对抗鲁棒性的网络架构。
CSDN资源
博主在阅读论文的时候,对论文做了标注,同时也加入了一些论文中提到的知识概念的补充;其中也有我对论文中某一部分的理解,大家如果感兴趣的话,可以下载我的CSDN资源Feature Denoising for Improving Adversarial Robustness_注解版。
6. References
[1]. https://www.zhihu.com/question/301444801/answer/527999348
[2]. https://arxiv.org/pdf/1812.03411.pdf
[3]. http://openaccess.thecvf.com/content_cvpr_2018/papers/Wang_Non-Local_Neural_Networks_CVPR_2018_paper.pdf
[4]. https://towardsdatascience.com/face-generator-generating-artificial-faces-with-machine-learning-9e8c3d6c1ead
[5]. https://www.pianshen.com/article/8872986988/
[6]. http://m.elecfans.com/article/676420.html