afl 源码分析 ->>fuzz.c
最近面试面的有点自闭,发现很多东西都不太会。 面试官看中的几点加分的能力,要么脱壳到vmp,要么内核能力到过pg tp,要么就是漏洞能挖到cve,要么研究过fuzz的源码,说说fuzz和符号执行。。。。
最近正好想读一下这个源码,就来分析一波。 如果哪里不对 还希望大佬们能指点出来。
afl 的工作模式是二进制插桩,然后共享内存,然后用fork 的方式 来 fork server 和 run_target
fork server就是用来和 fuzzer 进行交互 然后fork server 一直fork 进行父子程序的交互。而run_target 是通过共享内存来和fuzzer 进行交互, 详情可以看参考链接里面的图片。
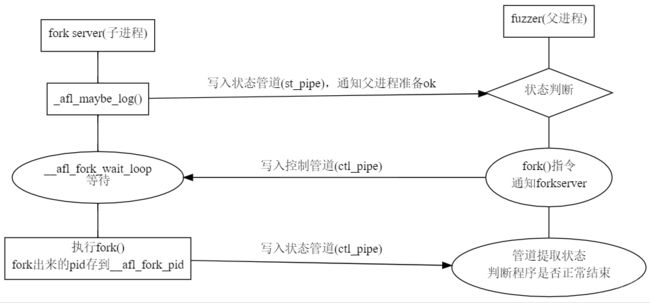
就重点说一下fuzz.c里面的重点函数
main 函数里面一开始就获取各种参数。
各种初始化

perform_dry_run
这个函数,就是对文件里面case进行一次运行,生成初始化的queue队列和bitmap(执行路径的映射)
里面还有调用另一个重要的函数
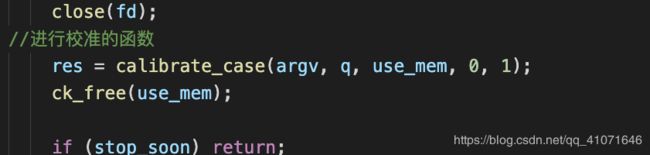
然后根据返回的错误信息,打印错误信息 退出函数
calibrate_case
函数前先判断了 判断是否是为队列中的和 刚恢复fuzz的时间延迟,然后还设置了q->cal_failed++;这代表了校正失败次数。 每调用一次 这个函数,就会让这个成员变量加一。在后面还会有这个校正失败次数,然后会判断这个成员是否小于三。。。

还会判断是否初始化了forkserver ,如果没有的话 会运行这个函数进行初始化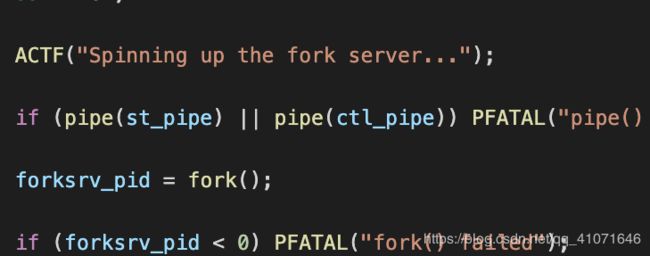
先fork 一个进程 检查输出输入管道 是否存在,然后 复制一个文件的描述符 然后
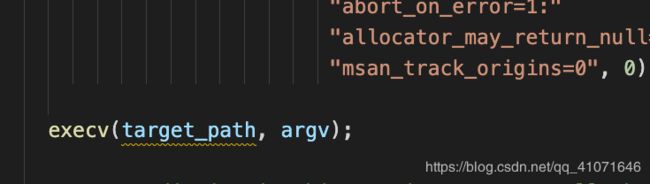
执行tatget 程序
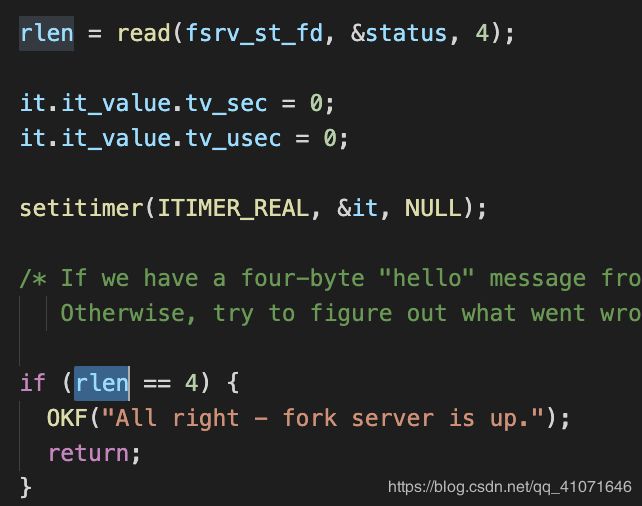
读取管道里面的数据,如果是len==4 就成功 这里是特地的验证是否server 是否可以 字符是 hello
这方面也是侧重fuzzer server run_target 之间的通信,也要去分析一下afl的插桩代码。等分析到他们的插桩代码,我再去分析一下。
然后就是write_to_testcase 就是将数据写到文件里。然后调用run_target 去运行
然后重点分析一下run_target
run_target
这个就是运行函数,通知运行
首先发现了
memset(trace_bits, 0, MAP_SIZE);
找到引用
trace_bits = shmat(shm_id, NULL, 0);
trace_bits 就是共享内存的地址。。。。
也就是说每次fuzz 前 都会把共享内存清空
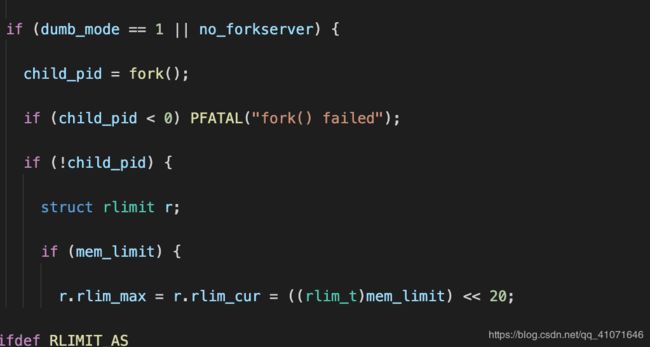
如果没有开启forkserver 或者 dumb_mode的话 就执行和init_forkserver 差不多的功能,
其中的dumb_mode 就是和固定变异,充满了随机色彩的mode,
如果开启了的话
就和forkserver 进行通信
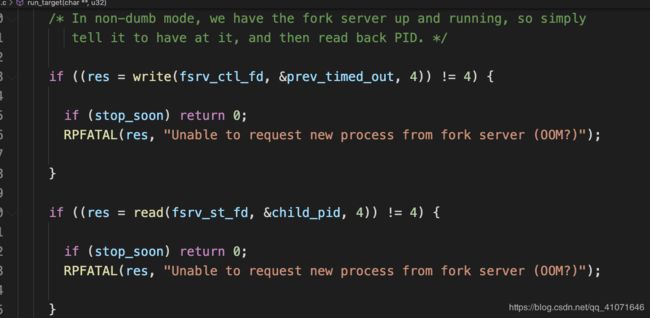
然后就设置 trace_bits mem 然后 fault 返回值。
设置空间这一块 还是挺有意思的。
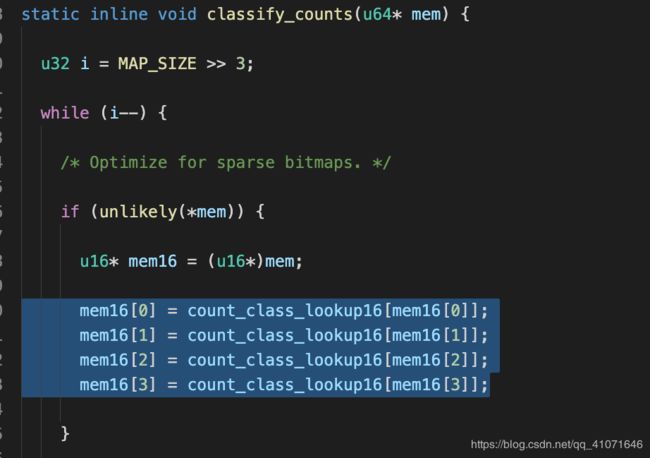
做了一个映射表
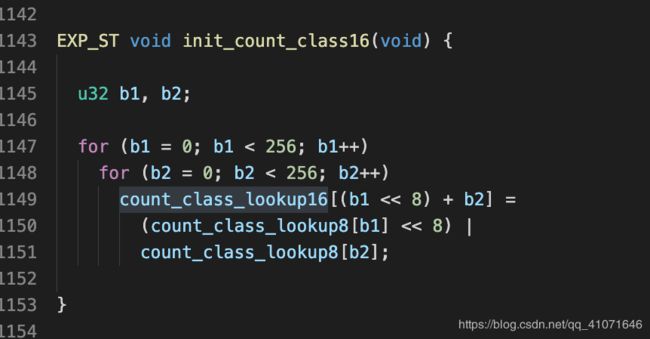
这里的映射表并不是说 1 2 3 4 5 这样连续的数列 详情可以参考
32 下的情况
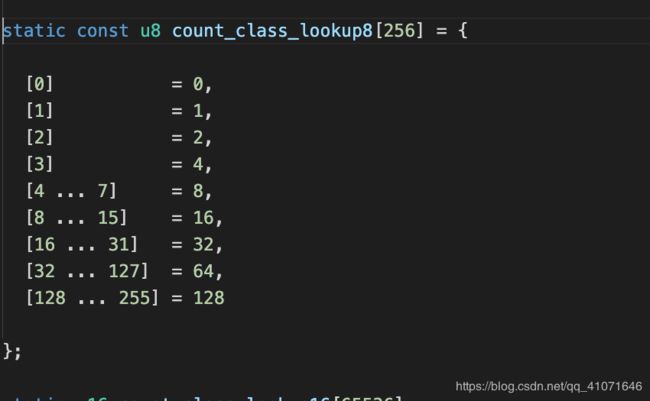
也就是说
target是将每个分支的执行次数用1个byte来储存,如果运行了5次和运行6次 都会掉入 8这个数字里面
然后就可以在 calibrate_case 里面就有对比hash 来判断是否有了新路径的出现
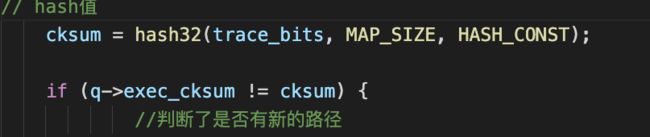
接下来就调用了has_new_bits ,这个has_new_bits 里面就是查看这个路径是否给表带来了新内容
然后用update_bitmap_score判断 这个路径是否更有利
update_bitmap_score

如果这条路径已经有了 那么会比较一下 time*len 如果竞争过了 就将原有的 tc_ref 减去一 并且free 掉
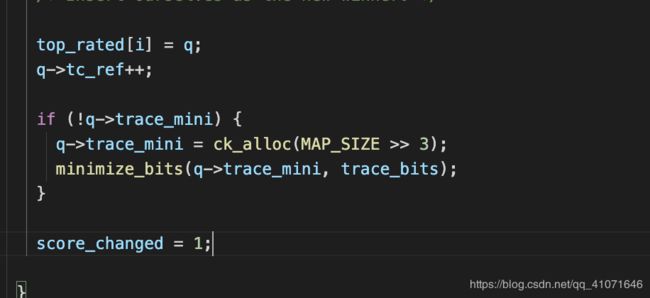
然后就重新设置 新的队列数据,trace_mini 每个bit对应了bit_map中的一个byte;如果这个queue访问了bit_map中的一个byte(即访问了一个edge),trace_mini中对应的bit位就置一。
解释起来就是 看这条路径是否我们这个队列数据更有价值,然后替换掉,然后队列里面的trace_mini记录这 都经过了那些边,记录下来置为1
cull_queue
这也是一个重点函数。
意思就为精简队列
这里可以参考看雪那个帖子的说法。
tuple t0,t1,t2,t3,t4;seed s0,s1,s2 初始化temp_v=[1,1,1,1,1]
s1可覆盖t2,t3 | s2覆盖t0,t1,t4,并且top_rated[0]=s2,top_rated[2]=s1
开始后判断temp_v[0]=1,说明t0没有被访问
top_rated[0]存在(s2) -> 判断s2可以覆盖的范围 -> trace_mini=[1,1,0,0,1]
更新temp_v=[0,0,1,1,0]
标记s2为favored
继续判断temp_v[1]=0,说明t1此时已经被访问过了,跳过
继续判断temp_v[2]=1,说明t2没有被访问
top_rated[2]存在(s1) -> 判断s1可以覆盖的范围 -> trace_mini=[0,0,1,1,0]
更新temp_v=[0,0,0,0,0]
标记s1为favored
此时所有tuple都被覆盖,favored为s1,s2
如果temp_v 已经全部为0 那么接下来的top_rated[i]->favored=0 那么

fuzz_one
主循环里面先精简队列,然后afl的重重重点函数 来了。
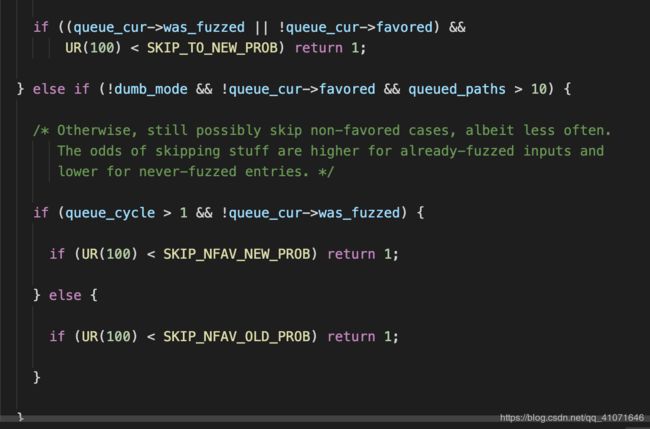
开头就是一堆ur(100)
这个就是 根据是否有pending_favored和queue_cur的情况按照概率进行跳过;有pending_favored, 对于fuzz过的或者non-favored的以概率99%跳过;无pending_favored,95%跳过fuzzed&non-favored,75%跳过not fuzzed&non-favored,不跳过favored。
然后就是 如果调用过 calibrate_case
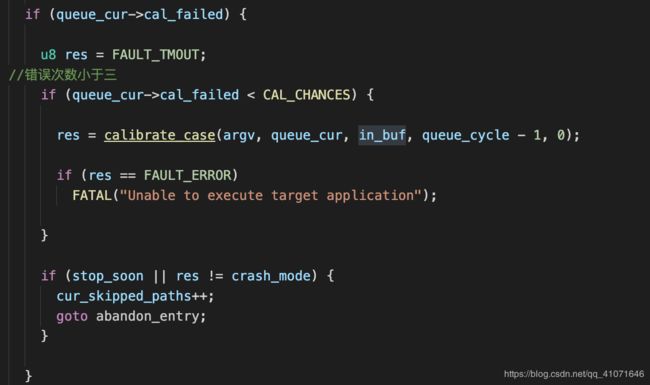
校正次数小于三,然后就去调用 calibrate_case。
如果没有校正过 那么就修建测试用例

trim_case
这里的修剪,也很有意思 两层while 循环
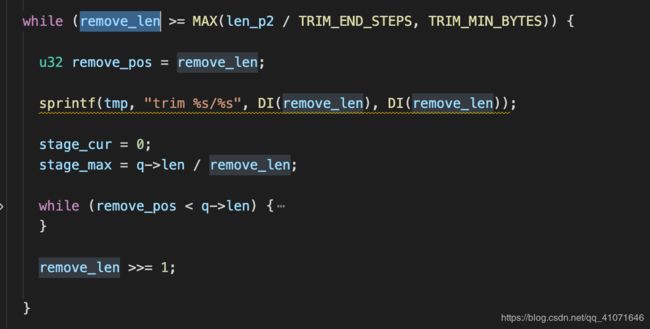
然后remove_len 每次都是减少一倍,初始化是 len/16 终止的话 就是小于 len/1024
然后里面的内容就是
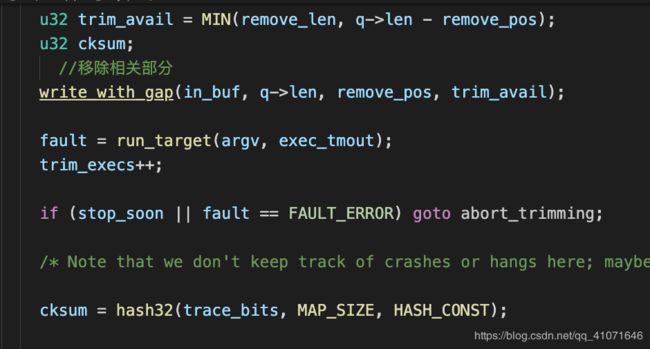
选定步长 移除相关部分
如果没有差别
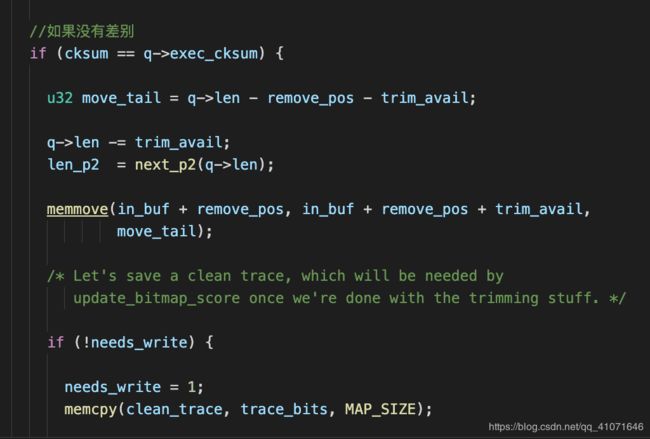
直接就移除掉。
calculate_score()
这是一个打分的函数
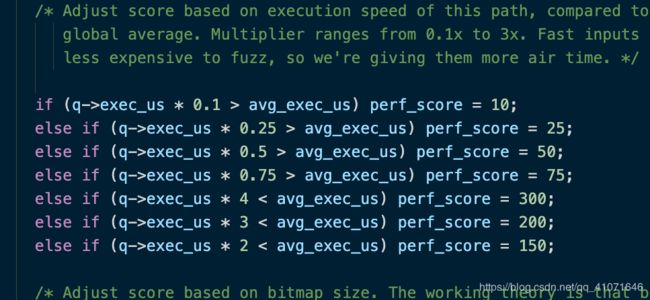
根据case的执行速度/bitmap的大小/case产生时间/路径深度等因素给case进行打分
接下来就是文件变异了
bitflip 阶段
拿到一个原始文件,打头阵的就是bitflip,而且还会根据翻转量/步长进行多种不同的翻转,按照顺序依次为:
bitflip 1/1,每次翻转1个bit,按照每1个bit的步长从头开始
bitflip 2/1,每次翻转相邻的2个bit,按照每1个bit的步长从头开始
bitflip 4/1,每次翻转相邻的4个bit,按照每1个bit的步长从头开始
bitflip 8/8,每次翻转相邻的8个bit,按照每8个bit的步长从头开始,即依次对每个byte做翻转
bitflip 16/8,每次翻转相邻的16个bit,按照每8个bit的步长从头开始,即依次对每个word做翻转
bitflip 32/8,每次翻转相邻的32个bit,按照每8个bit的步长从头开始,即依次对每个dword做翻转
作为精妙构思的fuzzer,AFL不会放过每一个获取文件信息的机会。这一点在bitflip过程中就体现的淋漓尽致。具体地,在上述过程中,AFL巧妙地嵌入了一些对文件格式的启发式判断。包括自动检测token和生成effector map。
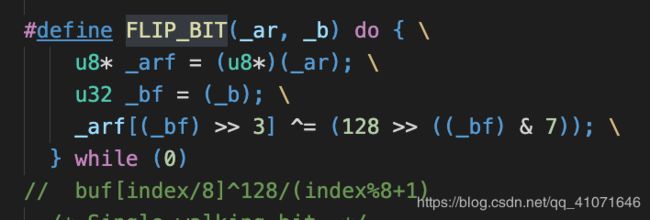
这里就是把bit 0变1 1变0

common_fuzz_stuff
这个函数就是进行了写入修改的数据 运行程序,处理结果 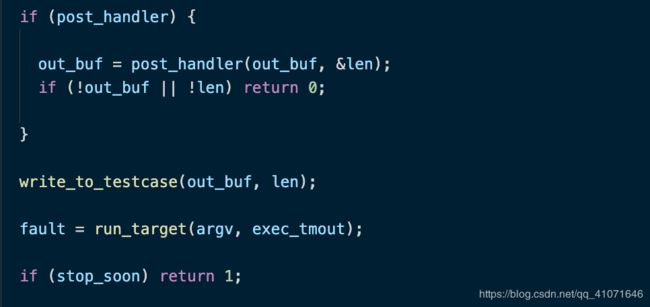
可以看到也是进行了写入testcase 文件,然后是运行,。
save_if_interesting 函数里面也是
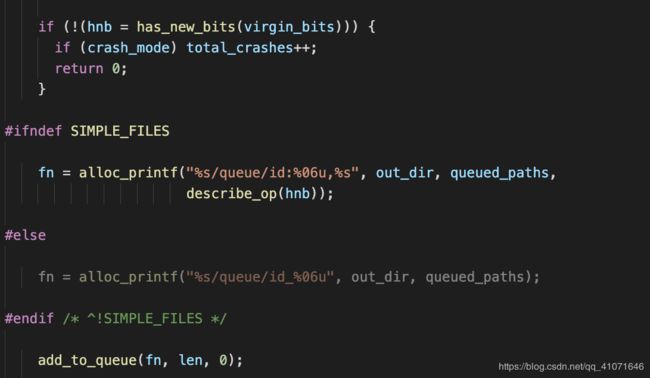
校检哈希,然后加入队列。 用calibrate_case 进行种子的重排
自动检测token
检测的方法也很简单,
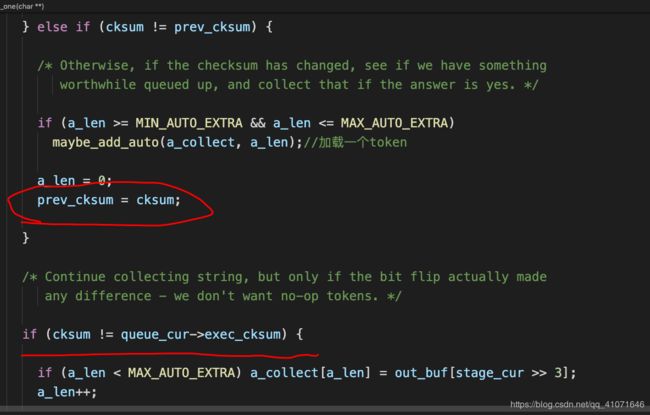
意思就是如果改变了某些连续的bit ,而且改变后他们的路径hash 一样,那么我们就认为他这个连续的是一个token
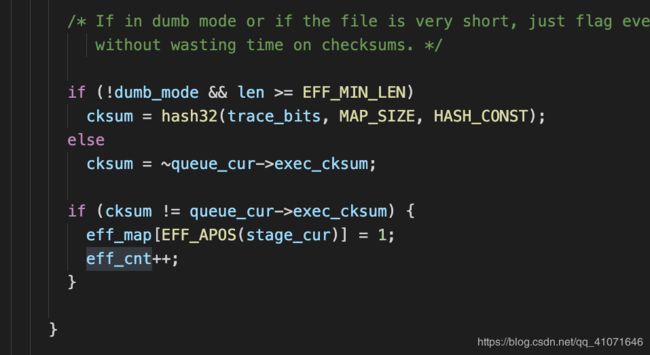
其中8/8 反转的时候,还有了effector map 这个也比较重要,
就是如果反转了一个bit,对执行结果没有什么改变,就标记为0 反之标记为1
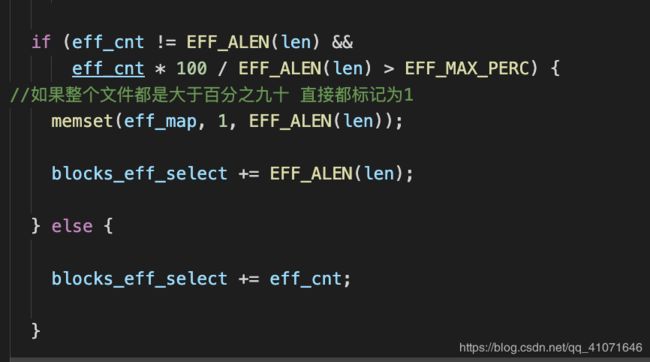
如果整个百分之九十都是的话 那么全部标记为1
arithmetic 阶段
这个阶段 就是对数据的加减进行变异

这里的ARITH_MAX =35 对目标整数会进行+1, +2, …, +35, -1, -2, …, -35的变异,这个阶段还会进行有目标的筛选。
第一种情况就是前面提到的effector map:如果一个整数的所有bytes都被判断为“无效”,那么就跳过对整数的变异。第二种情况是之前bitflip已经生成过的变异:如果加/减某个数后,其效果与之前的某种bitflip相同,那么这次变异肯定在上一个阶段已经执行过了,此次便不会再执行

interest 阶段
这个阶段就是 替换一些经常溢出的数据,然后替换写入到文件
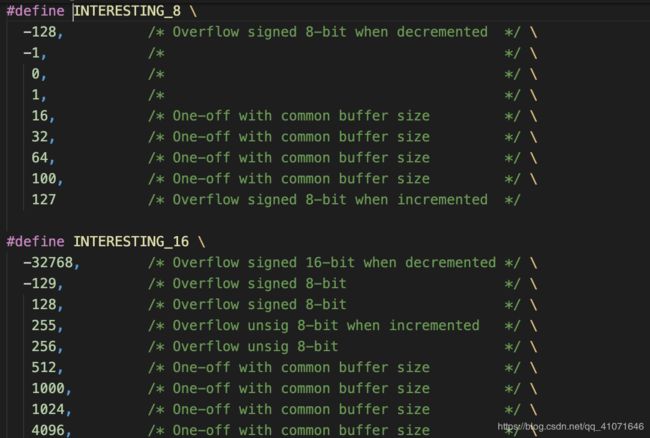
dictionary 阶段
user extras (over)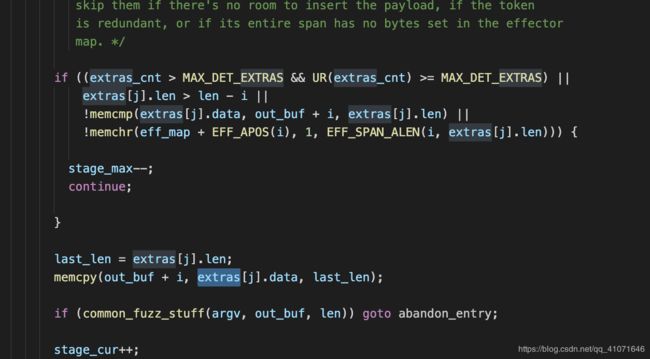
这个就是加载用户自己定义的token
user extras (insert)
插入用户自己定义的token

auto extras (over)
加载开始bitflip阶段自动生成的token。
havoc
这里直接引用了。
对于非dumb mode的主fuzzer来说,完成了上述deterministic fuzzing后,便进入了充满随机性的这一阶段;对于dumb mode或者从fuzzer来说,则是直接从这一阶段开始。
havoc,顾名思义,是充满了各种随机生成的变异,是对原文件的“大破坏”。具体来说,havoc包含了对原文件的多轮变异,每一轮都是将多种方式组合(stacked)而成:
随机选取某个bit进行翻转
随机选取某个byte,将其设置为随机的interesting value
随机选取某个word,并随机选取大、小端序,将其设置为随机的interesting value
随机选取某个dword,并随机选取大、小端序,将其设置为随机的interesting value
随机选取某个byte,对其减去一个随机数
随机选取某个byte,对其加上一个随机数
随机选取某个word,并随机选取大、小端序,对其减去一个随机数
随机选取某个word,并随机选取大、小端序,对其加上一个随机数
随机选取某个dword,并随机选取大、小端序,对其减去一个随机数
随机选取某个dword,并随机选取大、小端序,对其加上一个随机数
随机选取某个byte,将其设置为随机数
随机删除一段bytes
随机选取一个位置,插入一段随机长度的内容,其中75%的概率是插入原文中随机位置的内容,25%的概率是插入一段随机选取的数
随机选取一个位置,替换为一段随机长度的内容,其中75%的概率是替换成原文中随机位置的内容,25%的概率是替换成一段随机选取的数
随机选取一个位置,用随机选取的token(用户提供的或自动生成的)替换
随机选取一个位置,用随机选取的token(用户提供的或自动生成的)插入
怎么样,看完上面这么多的“随机”,有没有觉得晕?还没完,AFL会生成一个随机数,作为变异组合的数量,并根据这个数量,每次从上面那些方式中随机选取一个(可以参考高中数学的有放回摸球),依次作用到文件上。如此这般丧心病狂的变异,原文件就大概率面目全非了,而这么多的随机性,也就成了fuzzing过程中的不可控因素,即所谓的“看天吃饭”了。
充满未知的代码。。
splice
这个就是
splice是将两个seed文件拼接得到新的文件,并对这个新文件继续执行havoc变异
参考链接
https://bbs.pediy.com/thread-254705.htm
https://rk700.github.io/2017/12/28/afl-internals/