python学习之第二十天(图表展示数据)
1.python数据分析库有哪些
2.python绘制图表库有哪些
3.echarts绘制饼状图 柱状图 折线图
4.pyecharts绘制饼状图 柱状图 折线图
5.动态生成sql语句
6.如何获取一个对象的类名
7.基于sql的数据分析
8.爬虫和反爬虫和反反爬虫
分布式爬虫(scrapy-redis)案例参考2019-8-21笔记
1.python数据分析库有哪些
# python的数据分析库
# pandas https://www.yiibai.com/pandas/python_pandas_quick_start.html
# numpy
# import pandas as pd
# import numpy as np
#
# pd.read_clipboard()
# pd.read_csv()
# pd.read_excel()
# pd.read_html()
# pd.read_json()
2.python绘制图表库有哪些
# python的图表绘制
# matplotlib https://morvanzhou.github.io/tutorials/data-manipulation/plt/1-1-why/
# echarts 属于百度公司 https://echarts.baidu.com/
# pyecharts 用python对echarts做了个封装 http://pyecharts.herokuapp.com/
# turtle https://www.cnblogs.com/zxysaigao/p/8465839.html
# seaborn http://seaborn.pydata.org/examples/many_facets.html
# snapshot
3.echarts绘制饼状图 柱状图 折线图
echarts官网
echarts使用步骤
第一步.
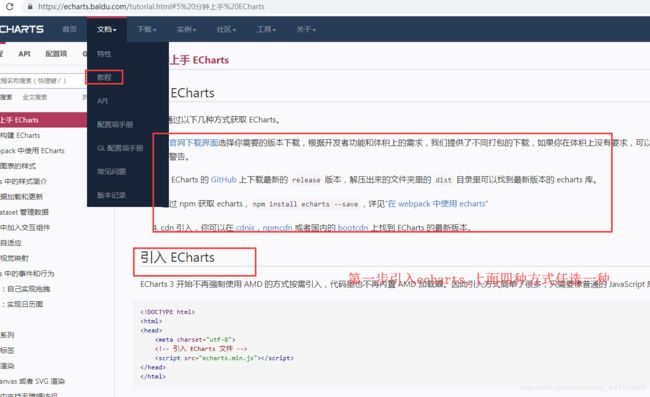
用第四种 进入cdnis
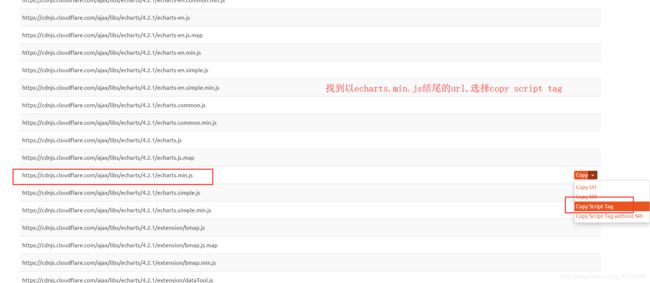
粘到head中

第二步:
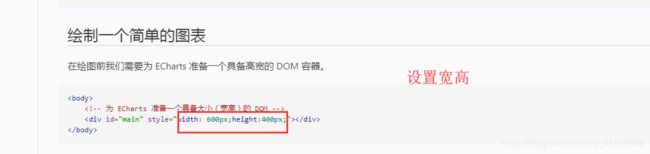
第三步
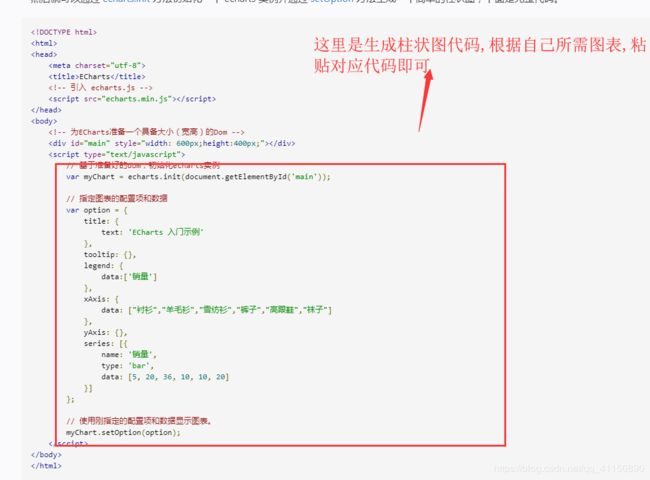
下面是两个实例
绘制柱状图:
Title
绘制折线图
Title
4.pyecharts绘制饼状图 柱状图 折线图
首先安装pyecharts
pip install pyecharts==0.5.5
以下是三个实例
柱状图:
from pyecharts import Bar
bar =Bar("工作数量对比", "python和php")
bar.add("python", ["1月", "2月", "3月"], [5, 20, 36])
bar.add("php", ["1月", "2月", "3月"], [5, 20, 36])
# bar.show_config()
bar.render("py柱状图.html")
折线图
from pyecharts import Line
attr = ["1月", "2月", "3月", "4月"]
v1 = [5, 20, 36, 10]
v2 = [55, 60, 16, 20]
v3 = [10, 50, 40, 90]
line = Line("折线图示例")
line.add("python", attr, v1)
line.add("php", attr, v2)
line.add("java", attr, v3)
line.render("py折线图.html")
饼状图
from pyecharts import Pie
attr =["python", "php", "java"]
v1 =[100, 120, 60]
pie = Pie("饼图示例")
pie.add("", attr, v1, is_label_show=True)
pie.render("py饼状图.html")
5.动态生成sql语句
import sqlite3
class SqlitePipeline(object):
def __init__(self, db_name):
if not db_name:
db_name = "db"
self.db = sqlite3.connect(f"{db_name}.sqlite")
self.cursor = self.db.cursor()
# 加载配置,获取custom_settings设置的字段,这里获取的是DB_NAME
@classmethod
def from_settings(cls, settings):
db_name = settings['DB_NAME']
return cls(db_name)
def close_spider(self, spider):
self.cursor.close()
self.cursor = None
self.db.close()
self.db = None
def process_item(self, item, spider):
create_table_last_part = ""
lie_list = []
value_list = []
for key, value in item.items():
if isinstance(value, int):
value_type = "INTEGER"
elif isinstance(value, str):
value_type = "VARCHAR(255)"
elif isinstance(value, float):
value_type = "FLOAT"
elif isinstance(value, list):
value_type = "VARCHAR(255)"
value = value[0]
if "url" in key:
value_type += " UNIQUE"
create_table_last_part += f"{key} {value_type},"
lie_list.append(key)
value_list.append(value)
sql1 = f"""
CREATE TABLE IF NOT EXISTS {type(item).__name__} (
id INTEGER PRIMARY KEY AUTOINCREMENT,
{create_table_last_part[:-1]}
)
"""
self.cursor.execute(sql1)
try:
sql1 = f"""INSERT INTO {type(item).__name__} ({",".join(lie_list)}) VALUES ({("?,"*len(lie_list))[:-1]})"""
self.cursor.execute(sql1, value_list)
self.db.commit()
except Exception as e:
print("插入失败!数据重复",e)
return item
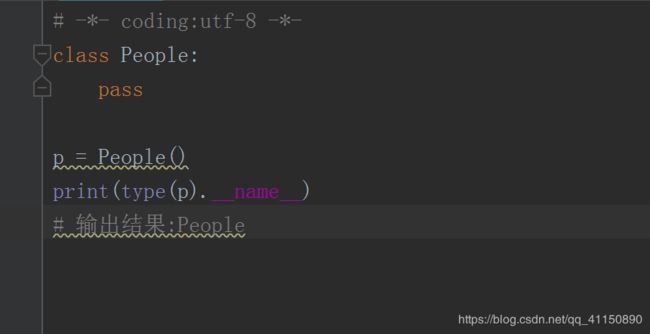
6.如何获取一个对象的类名
7.基于sql的数据分析
import sqlite3
db = sqlite3.connect("job51.sqlite")
cursor = db.cursor()
# 统计数据中有多少个城市
sql1 = """
SELECT job_city FROM Job51Item GROUP BY job_city;
"""
# 统计工作数量
sql1 = """
SELECT COUNT(*) FROM Job51Item;
"""
# 统计数据中每个城市有多少工作数量
sql1 = """
SELECT COUNT(*), job_city FROM Job51Item GROUP BY job_city;
"""
# 统计某个城市的工作种类和其对应的数量,以上海为例
sql1 = """
SELECT COUNT(*), job_city, job_type FROM Job51Item WHERE job_city='上海' GROUP BY job_type ;
"""
# 统计上海c++每天的岗位数量变化
sql1 = """
SELECT COUNT(*), job_city, job_type,job_date FROM Job51Item WHERE job_city='上海' AND job_type='c++' GROUP BY job_date ;
"""
# 用柱状图表示每个城市每个语言工作数量的对比情况
#
cursor.execute(sql1)
result = cursor.fetchall()
print(result)
cursor.close()
db.close()
cursor=None
db=None
8.爬虫和反爬虫和反反爬虫
# 爬虫:工程师写脚本去采集对方的数据的行为
# 反爬虫:对方想尽办法不让我用脚本采集的行为
# 反反爬虫:工程师想尽办法突破对方的设置采集了对方数据的行为
# 爬虫必将胜利,不过是时间关系
# 反爬虫技巧
# 1. 检测User-Agent是否为浏览器
# 2. 检测IP的访问频率
# 3. 检测Cookie中的字段
# Cookie由服务器生成,浏览器存储
# 4. 验证码(随机)
# 5. 参数进行js动态加密
# 6. 字体加密
# 反反爬虫技巧
# 1. 手动构造请求头,设置User-Agent
# 2. 设置Download_Delay=2
# 3. 禁用Cookie/手动粘贴Cookie访问
# 4. 捕获验证码的条件(云打码、OCR光学识别、手动验证、github搜索破解方式)
# 验证码类型
# 1) 图片滑动 2)数字字母混合 3)输入表达式结果
# 4) 点击对应图案 5) 类似12306的验证码
# 5. 分析网页,找到js文件,使用pyexecjs模拟js加密
# 6. 找到对应的ttf文件,研究编码
# 爬虫技巧
# 1. 爬取app 比 爬取web 要简单
# 2. 如果请求(http/https)看不到,则可能是基于socket的请求
# 3. 常用的抓包工具(charles/fiddler)只能抓取http/https
# wireshark可以抓取任意请求
# mitmproxy 抓取手机请求的框架
# 4. 模拟浏览器行为来抓取请求
# python:selenium
# nodejs: puppeteer
# 5. 可视化爬虫
# gerapy:分布式爬虫管理框架
# InfluxDb+Grafana
# 6. app安装包的反编译(安卓比苹果简单)
# 面试题
# 如果分布式爬虫中有两台电脑死机或没有爬虫,如何监控?
# 类似于点名,定时检索每台电脑是否存活
# 每台电脑定时通过redis发送特定消息证明电脑存活,否则报警
# 定时任务(time)