ES来源
Elasticsearch 来源于作者 Shay Banon 的第一个开源项目Compass库,而这个库的最初目的只是为了给Shay当时正在学厨师的妻子做一个菜谱的搜索引擎。
马上联想到当年Pinterest的创意来源也是创始人Ben Silbermann为了方便他的女朋友寻找订婚戒指,可以图钉随手粘贴同一个页面进行对比。
ES基础
数据模型

数据模型
逻辑概念
ES本身是schema less的,有比较特殊的字段需要通过Mapping设置一下,每个数据点就是一行数据Document,ES数据分类通过Index这层完成的
Elassticsearch的基础概念-数据模型,如上图把ES数据模型概念和传统数据库做了对比。
index 对应db 库database库
type 对应db 表table表(废弃)
doc 对应db 行 row
field 对应db 字段 column
物理存储
首先分为两层,一个是ES,下面是Lucene,一个ES集群有多个node组成的。一个ES实例会承载一些Shard,多个shard会落到不同机器上面,P1和P2是两个不同的Shard,并且shard有主从的概念,对于ES每个Shard落地下来是一个Lucene Index。
节点(Node)
运行了单个实例的ES主机称为节点,它是集群的一个成员,可以存储数据、参与集群索引及搜索操作。类似于集群,节点靠其名称进行标识,默认为启动时自动生成的随机Marvel字符名称。用户可以按需要自定义任何希望使用的名称,但出于管理的目的,此名称应该尽可能有较好的识别性。节点通过为其配置的ES集群名称确定其所要加入的集群。
分片(Shard)和副本(Replica)
ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。
Shard有两种类型:primary和replica,即主shard及副本shard。Primary shard用于文档存储,每个新的索引会自动创建5个Primary(最新版改成1个了) shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其Primary shard的数量将不可更改。Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。每个Primary shard默认配置了一个Replica shard,但也可以配置多个,且其数量可动态更改。ES会根据需要自动增加或减少这些Replica shard的数量。
ES集群可由多个节点组成,各Shard分布式地存储于这些节点上。
ES可自动在节点间按需要移动shard,例如增加节点或节点故障时。简而言之,分片实现了集群的分布式存储,而副本实现了其分布式处理及冗余功能。
数据持久化

数据持久化.png
Lucence索引原理
新接到的数据写入新的索引文件里
动态更新索引时候,不修改已经生成的倒排索引,而是新生成一个段(segment)
每个段都是一个倒排索引,然后另外使用一个commit文件记录索引内所有的segment,而生成segment的数据来源则放在内存的buffer中
持久化主要有四个步骤,write->refresh->flush->merge
写入in-memory buffer和事务日志translog
定期refresh到段文件segment中 可以被检索到
定期flush segement落盘 清除translog
定期合并segment 优化流程
write
es每新增一条数据记录时,都会把数据双写到translog和in-memory buffer内存缓冲区中

写流程
这时候还不能会被检索到,而数据必须被refresh到segment后才能被检索到
refresh
默认情况下es每隔1s执行一次refresh,太耗性能,可以通过index.refresh_interval来修改这个刷新时间间隔。
整个refresh具体做了如下事情
所有在内存缓冲区的文档被写入到一个新的segment中,但是没有调用fsync,因此数据有可能丢失,此时segment首先被写到内核的文件系统中缓存
segment被打开是的里面的文档能够被见检索到
清空内存缓冲区in-memory buffer,清空后如下图
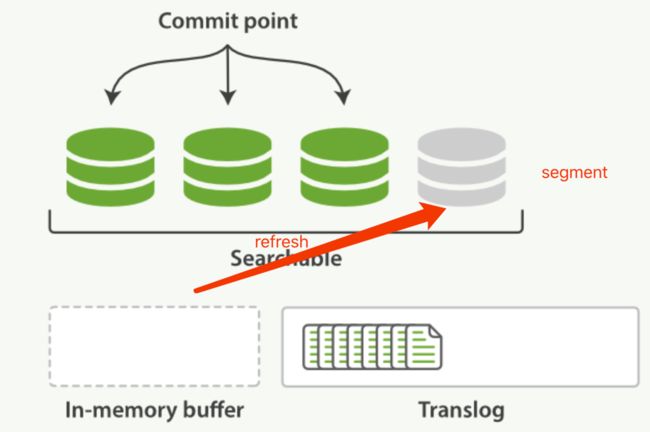
refresh操作
flush
随着translog文件越来越大时要考虑把内存中的数据刷新到磁盘中,这个过程叫flush
把所有在内存缓冲区中的文档写入到一个新的segment中
清空内存缓冲区
往磁盘里写入commit point信息
文件系统的page cache(segments) fsync到磁盘
删除旧的translog文件,因此此时内存中的segments已经写入到磁盘中,就不需要translog来保障数据安全了,flush后效果如下
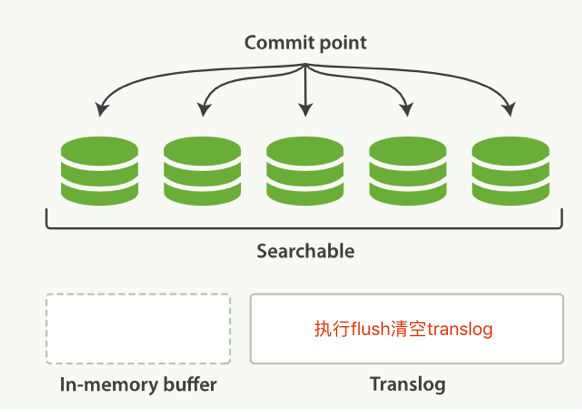
flush操作
flush和fsync的区别
flush是把内存中的数据(包括translog和segments)都刷到磁盘,而fsync只是把translog刷新的磁盘(确保数据不丢失)。
segment合并
通过每隔一秒的自动刷新机制会创建一个新的segment,用不了多久就会有很多的segment。segment会消耗系统的文件句柄,内存,CPU时钟。最重要的是,每一次请求都会依次检查所有的segment。segment越多,检索就会越慢。
ES通过在后台merge这些segment的方式解决这个问题。小的segment merge到大的
这个过程也是那些被”删除”的文档真正被清除出文件系统的过程,因为被标记为删除的文档不会被拷贝到大的segment中。

段合并
当在建立索引过程中,refresh进程会创建新的segments然后打开他们以供索引。
merge进程会选择一些小的segments然后merge到一个大的segment中。这个过程不会打断检索和创建索引。一旦merge完成,旧的segments将被删除。
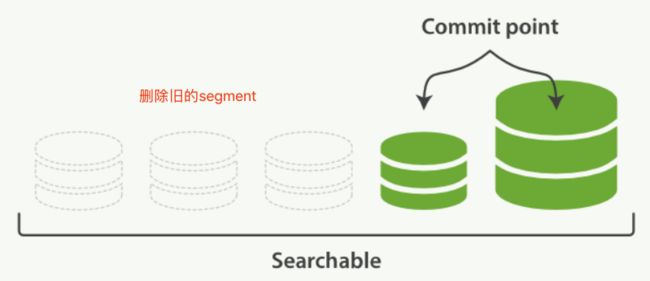
段合并后
新的segment被flush到磁盘
一个新的提交点被写入,包括新的segment,排除旧的小的segments
新的segment打开以供索引
旧的segments被删除
下面补充介绍下translog
Translog
Lucence基于节点宕机的考虑,每次写入都会落盘Translog,类似db binlog,不同的是db binlog 通过expire_logs_days=7 设定过期时间以天为单位 默认7天
而translog 是每次flush后会清除 可以通过几个维度的设定清除策略
index.translog.flush_threshold_ops,执行多少次操作后执行一次flush,默认无限制
index.translog.flush_threshold_size,translog的大小超过这个参数后flush,默认512mb
index.translog.flush_threshold_period,多长时间强制flush一次,默认30m
index.translog.interval,es多久去检测一次translog是否满足flush条件
translog日志提供了一个所有还未被flush到磁盘的操作的持久化记录。当ES启动的时候,它会使用最新的commit point从磁盘恢复所有已有的segments,然后将重现所有在translog里面的操作来添加更新,这些更新发生在最新的一次commit的记录之后还未被fsync。
translog日志也可以用来提供实时的CRUD。当你试图通过文档ID来读取、更新、删除一个文档时,它会首先检查translog日志看看有没有最新的更新,然后再从响应的segment中获得文档。这意味着它每次都会对最新版本的文档做操作,并且是实时的。
理论上设定好这个过期策略,在flush之前把translog拿到后做双机房同步或者进一步的消息通知处理,还可以有很大作为,可行性还有待尝试。
写操作
主分片+至少一个副分片全部写成功后才返回成功

写操作.png
具体流程:
客户端向node1发起写入文档请求
Node1根据文档ID(_id字段)计算出该文档属于分片shard0,然后将请求路由到Node3 的主分片P0上
路由公式 shard = hash(routing) % number_of_primary_shards
Node3在p0上执行了写入请求后,如果成功则将请求并行的路由至Node1 Node2它的副本分片R0上,且都成功后Node1再报告至client
wait_for_active_shards 来配置副本分配同步策略
- 设置为1 表示仅写完主分片就返回
- 设置为all 表示等所有副本分片都写完才能返回
- 设置为1-number_of_replicas+1之间的数值,比如2个副本分片,有1个写成功即可返回
timeout 控制集群异常副本同步分片不可用时候的等待时间
读操作
一个文档可以在任意主副分片上读取
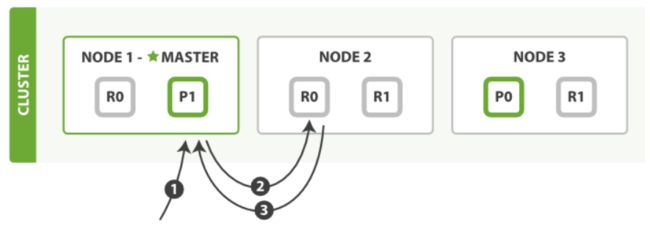
读操作.png
读取流程:
客户端发起读请求到Node1
Node1根据文档ID(_id字段)计算出该文档属于分片shard0,在所有节点上都有,这次它根据负载均衡将请求路由至Node2
Node2将文档返回给Node1,Node1将文档返回给client
更新操作
更新操作其实就是先读然后写

更新操作.png
更新流程:
客户端将更新请求发给Node1
Node1根据文档ID(_id字段)计算出该文档属于分片shard0,而其主分片在Node上,于是将请求路由到Node3
Node3从p0读取文档,改变source字段的json内容,然后将修改后的数据在P0重新做索引。如果此时该文档被其他进程修改,那么将重新执行3步骤,这个过程如果超过retryon_confilct设置的重试次数,就放弃。
如果Node3成功更新了文档,它将并行的将新版本的文档同步到Node1 Node2的副本分片上重新建立索引,一旦所有的副本报告成功,Node3向被请求的Node1节点返回成功,然后Node1向client返回成功
更新和删除
由于segments是不变的,所以文档不能从旧的segments中删除,也不能在旧的segments中更新来映射一个新的文档版本。取之的是,每一个提交点都会包含一个.del文件,列举了哪一个segment的哪一个文档已经被删除了。 当一个文档被”删除”了,它仅仅是在.del文件里被标记了一下。被”删除”的文档依旧可以被索引到,但是它将会在最终结果返回时被移除掉。
文档的更新同理:当文档更新时,旧版本的文档将会被标记为删除,新版本的文档在新的segment中建立索引。也许新旧版本的文档都会本检索到,但是旧版本的文档会在最终结果返回时被移除。
作者:maquewy
链接:https://www.jianshu.com/p/e8226138485d
来源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。