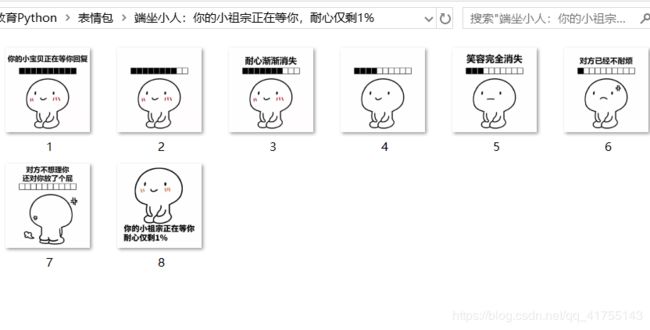
Python爬取 表情包爬取
Xpath Helper安装:http://chromecj.com/utilities/2019-01/1791.html
软件安装地址:https://blog.csdn.net/yhnobody/article/details/81030436
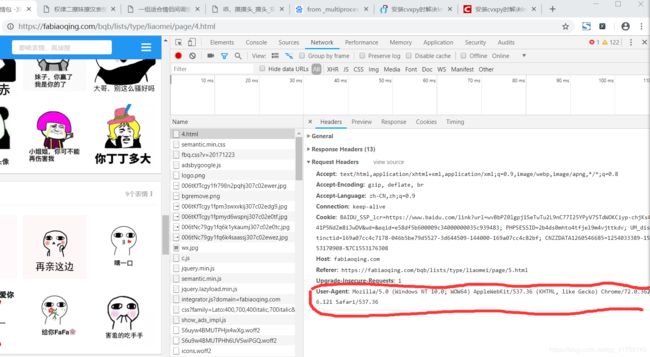
Q1,如何得到请求头headers:
Q2,如何在PyCharm安装库:

先讲解def Download_images(url):
1,利用xpath进行提取的基本格式:
(1),获取标题:
html = etree.HTML(response_images)
#标题也列表不能有特殊字符
images_title = html.xpath("//div/h1[@class='ui header']/text()")如何获取:
"//div/h1[@class='ui header']/text()"#最后的/text()代表查询得到的文本利用Chrome的Xpath Helper

根据步骤3写出步骤4,(需要xpath的知识,例如:‘//’代表 父节点,'/'代表子节点,[@class= '']代表属性)
(2),获取图片地址(同理):
#获取图片地址
images_Data=html.xpath("//img[@class='bqbppdetail lazy']/@data-original")
2,for循环中
(1),生成要存储的文件夹名称:
image_url=requests.get(i,headers=headers)#图片的数据
# image_url = requests.get(i, headers=headers).text # 图片的数据\
#产生乱码
save='表情包/' + n #新建名称为 标题 的文件加
address_save=str(save)(2), 下载到该文件夹下
# 判断文件夹是否存在,然后自己创建
if not os.path.exists(address_save):
os.makedirs('表情包/' + n)
else:
#with open(文件夹+'文件名')
with open(address_save + '/{}.gif'.format(count),'wb') as f:
f.write(image_url.content)
print('已经下载了{}张'.format(count))
count+=1讲解The_URL(page)
1,获取每组表情的地址
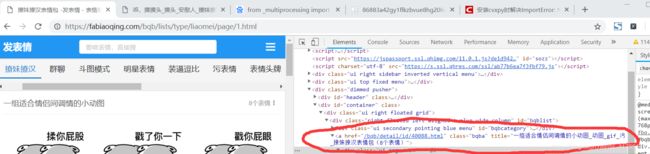
图中红色部分的href等于的链接就是一组表情包下的链接,所以要下载表情包,要进去这个链接
获取这组链接:
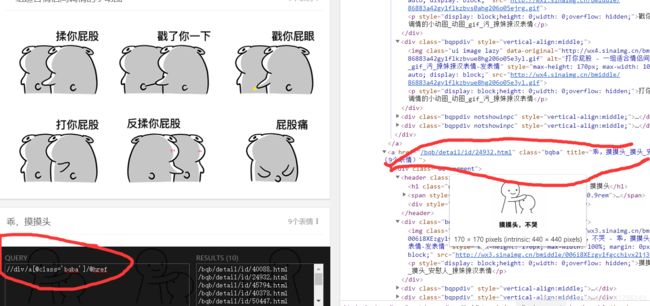
2,形成每组表情的网页链接,
#迭代的效果
for i in images_lazy:
#提取的url
url_images='https://fabiaoqing.com'+i
然后进入Download_images()下载图片.
多线程部分我也不清楚,代码直接复制就好(可以自己上网查)
完整代码:
'''
1,浏览器的url(路径)
2,提取url(页面跳转的url)
2.1 模拟用户请求浏览器(url,headers)
3,响应数据
4,提取数据
5,保存
'''
import requests
#Q2:如何安装requests
from lxml import etree
import os
#进程
from multiprocessing import Process
#请求头(request,headers)
#Q1:如何得到请求头
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
def Download_images(url):
'''对表情包进行下载'''
response_images=requests.get(url,headers=headers).text
count=1
html = etree.HTML(response_images)
#标题也列表不能有特殊字符
images_title = html.xpath("//div/h1[@class='ui header']/text()")
#获取图片地址
images_Data=html.xpath("//img[@class='bqbppdetail lazy']/@data-original")
#print(images_Data)
#一个列表不能进行网页请求的
n=None
for n in images_title:
print(n)
#jpg的后缀最后改一下
for i in images_Data:
image_url=requests.get(i,headers=headers)#图片的数据
# image_url = requests.get(i, headers=headers).text # 图片的数据\
#产生乱码
save='表情包/' + n #新建名称为 标题 的文件加
address_save=str(save)
# 判断文件夹是否存在,然后自己创建
if not os.path.exists(address_save):
os.makedirs('表情包/' + n)
else:
#with open(文件夹+'文件名')
with open(address_save + '/{}.gif'.format(count),'wb') as f:
f.write(image_url.content)
print('已经下载了{}张'.format(count))
count+=1
def The_URL(page):
# 1,浏览器的url(路径)
url = 'https://fabiaoqing.com/bqb/lists/type/liaomei/page/'+str(page)+'.html'
# 模拟用户请求浏览器(url,headers)
#text字符串文本
response_data=requests.get(url,headers=headers).text
#如何获取xpath,通过什么工具
html=etree.HTML(response_data)
images_lazy=html.xpath("//div/a[@class='bqba']/@href")
#迭代的效果
for i in images_lazy:
#提取的url
url_images='https://fabiaoqing.com'+i
#下载表情包
Download_images(url_images)
#https://fabiaoqing.com + /bqb/detail/id/40088.html
if __name__=='__main__':
#创建一个进程
#Process(指向->函数,函数的参数)
for i in range(10):
#后面这个参数是一个元祖
p1=Process(target=The_URL,args=(i,))
#运行进程
p1.start()
#等待进程结束
p1.join()效果