Selenium实现交互式模拟浏览器行为
前面介绍了网络爬虫对静态页面的抓取,但是在爬取网页的时候会遇到各种各样的情况,比如下拉选项和表单提交,这些都是用之前的方法解决不了的。在Python爬虫中处理这种需要模拟用户操作的情况最好的方法之一就是使用Selenium。
1.Selenium介绍
Selenium是ThoughtWorks公司的一个强大的开源Web功能测试工具系列,采用Javascript来管理整个测试过程,包括读入测试套件、执行测试和记录测试结果。它采用Javascript单元测试工具JSUnit为核心,模拟真实用户操作,包括浏览页面、点击链接、输入文字、提交表单、触发鼠标事件等等,并且能够对页面结果进行种种验证。也就是说,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件。
当然,我们使用的是Selenium的2.0版本,也叫webdriver。
安装pip install selenium
先写一个简单的小程序,让webdriver运作起来
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
browser = webdriver.Chrome()
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def start_requests(self):
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
def parse(self, response):
pass这就是一个简单的模拟打开百度的程序,输入scrapy crawl baidu让爬虫跑起来

如果程序执行错误,浏览器没有打开,那么应该是没有装 Chrome 浏览器或者 Chrome 驱动没有配置在环境变量里。下载驱动,然后将驱动文件放在Python的路径下就可以了。
Chrom驱动下载

2.交互界面的实现
1.触发按钮点击事件
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def start_requests(self):
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
elem = browser.find_element_by_xpath('//*[@id="kw"]')
elem.send_keys("网络爬虫") # 在输入框输入网络爬虫
button = browser.find_element_by_xpath('//*[@id="su"]')
button.click() # 触发按钮
def parse(self, response):
pass
这样浏览器就会帮我们自动搜索想要的内容
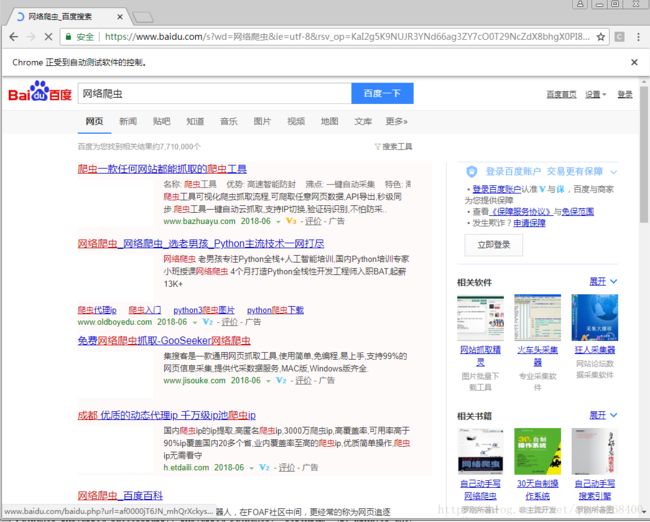
2.webdriver查找元素
单个元素:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first,input_second,input_third)
browser.close()常用的查找方法:
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector3.触发拖拽事件
以runoob上一个网页作为例子

现在我们要做的事情就是把右边的框拖到相应区域去
from selenium import webdriver
from selenium.webdriver import ActionChains # 引入动作链
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['www.runoob.com']
def start_requests(self):
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult') # 切换到iframeResult框架
source = browser.find_element_by_css_selector('#draggable') # 找到被拖拽对象
target = browser.find_element_by_css_selector('#droppable') # 找到目标
actions = ActionChains(browser) # 声明actions对象
actions.drag_and_drop(source, target)
actions.perform() # 执行动作执行结果:

4.触发下拉框
我们通常会遇到两种下拉框,一种使用的是html的标签select,另一种是使用input标签做的假下拉框。
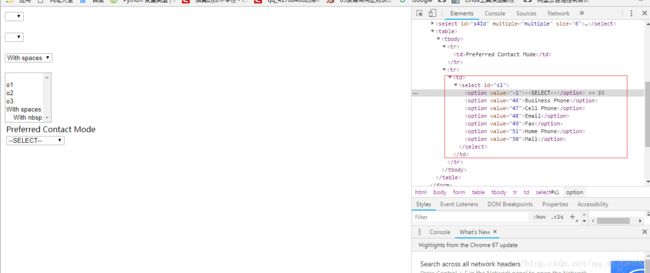
这是一个select的下拉选项,现在我们要做的事就是选中其中一个值
def start_requests(self):
browser = webdriver.Chrome()
url = 'http://sahitest.com/demo/selectTest.htm'
browser.get(url)
s1 = Select(browser.find_element_by_id('s1')) # 实例化Select
s1.select_by_value("50") #选取vlue为50的选项
sleep(5)
browser.quit()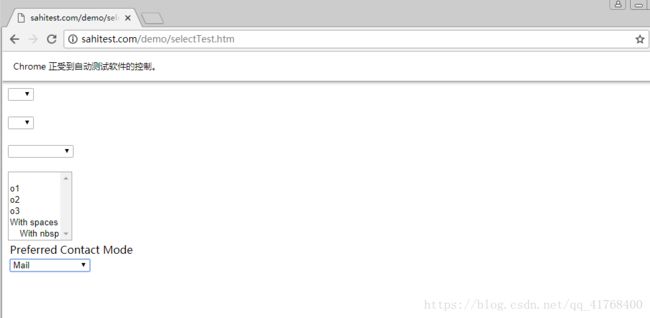
5.页面的前进后退
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back() # 后退
time.sleep(1)
browser.forward() # 前进
browser.close()6.添加访问cooike
'''
前面部分代码用于填写登录信息并登录
'''
# 获取cookie并通过json模块将dict转化成str
dictCookies = self.browser.get_cookies()
jsonCookies = json.dumps(dictCookies)
# 登录完成后,将cookie保存到本地文件
with open('cookies.json', 'w') as f:
f.write(jsonCookies)# 初次建立连接,随后方可修改cookie
self.browser.get('http://xxxx.com')
# 删除第一次建立连接时的cookie
self.browser.delete_all_cookies()
# 读取登录时存储到本地的cookie
with open('cookies.json', 'r', encoding='utf-8') as f:
listCookies = json.loads(f.read())
for cookie in listCookies:
self.browser.add_cookie({
'domain': '.xxxx.com', # 此处xxx.com前,需要带点
'name': cookie['name'],
'value': cookie['value'],
'path': '/',
'expires': None
})
# 再次访问页面,便可实现免登陆访问
self.browser.get('http://xxx.com')
7.等待
有时候网络不给力,我们就需要设置一个等待时间让浏览器停一会儿,而Selenium的等待又分为隐式等待和显示等待。
隐式等待
当使用了隐式等待执行测试的时候,如果 WebDriver没有在 DOM中找到元素,将继续等待,超出设定时间后则抛出找不到元素的异常,
换句话说,当查找元素或元素并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是0
browser = webdriver.Chrome()
browser.implicitly_wait(10)#等待十秒加载不出来就会抛出异常,10秒内加载出来正常返回
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)显式等待
指定一个等待条件,和一个最长等待时间,程序会判断在等待时间内条件是否满足,如果满足则返回,如果不满足会继续等待,超过时间就会抛出异常
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
wait = WebDriverWait(browser, 5)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)