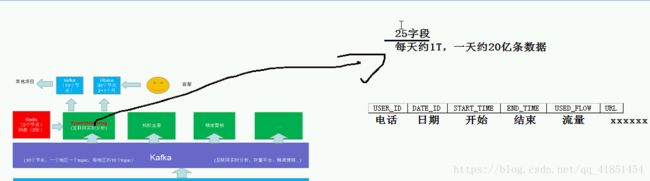
SparkStreaming项目(实时统计每个品类被点击的次数)
1、项目的流程:
每一个IP对应的名称:


2、需求
实时统计每个品类被点击的次数(用饼状图展示):
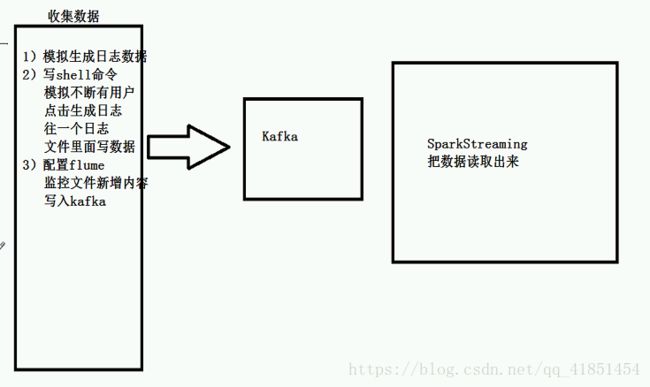
3、分析设计项目
新建一个Maven项目:
pom文件:
4.0.0
1711categorycount
1711categorycount
1.0-SNAPSHOT
org.apache.hadoop
hadoop-client
2.7.5
org.apache.spark
spark-streaming_2.11
2.2.0
org.apache.spark
spark-streaming-kafka-0-8_2.11
2.2.0
org.apache.hbase
hbase-client
0.98.6-hadoop2
org.apache.hbase
hbase-server
0.98.6-hadoop2
4、模拟实时数据
往data.txt文件里面写入数据(Java代码):
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Random;
public class SimulateData {
public static void main(String[] args) {
BufferedWriter bw = null;
try {
bw = new BufferedWriter(new FileWriter("G:\\Scala\\实时统计每日的品类的点击次数\\data.txt"));
int i = 0;
while (i < 20000){
long time = System.currentTimeMillis();
int categoryid = new Random().nextInt(23);
bw.write("ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time="+time+"&p_url=http://list.iqiyi.com/www/"+categoryid+"/---.html");
bw.newLine();
i++;
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}data.txt文件部分结果:
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174569&p_url=http://list.iqiyi.com/www/9/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/4/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/10/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/4/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/1/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/13/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/8/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/3/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/17/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/6/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/22/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/14/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/3/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/10/---.html
ver=1&en=e_pv&pl=website&sdk=js&b_rst=1920*1080&u_ud=12GH4079-223E-4A57-AC60-C1A04D8F7A2F&l=zh-CN&u_sd=8E9559B3-DA35-44E1-AC98-85EB37D1F263&c_time=1526975174570&p_url=http://list.iqiyi.com/www/14/---.html把data.txt数据放入Linux系统。
模拟数据实时读取数据:
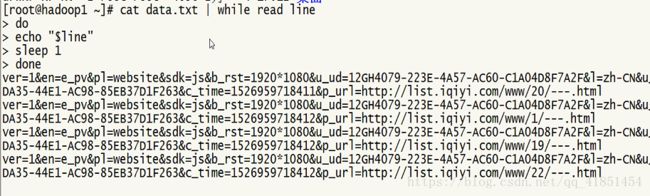
模拟数据实时的写入data.log:
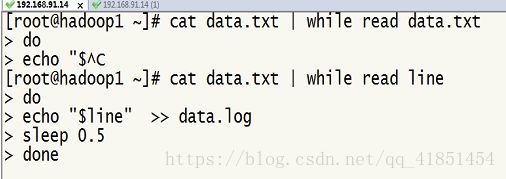
实时读取data.log里面的数据:
5、配置kafka,Flume集群
Kafka学习(四)Kafka的安装
Flume学习(三)Flume的配置方式
6、flume发送数据到kafka
从data.log文件中读取实时数据到kafka:
第一步:配置Flume文件:(file2kafka.properties)
a1.sources = r1
a1.sinks = k1
a1.channels =c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data.log
a1.channel.c1 = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = aura
a1.sinks.k1.brokerList = hodoop02:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 5
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动Flume的时候,需要一直实时的往data.log文件中写入数据。也就是说那个写入的脚本文件需要一直启动着。
第二步:需要一直启动着:
[hadoop@hadoop02 ~]$ cat data.txt | while read line
> do
> echo "$line" >> data.log
> sleep 0.5
> done第三步:启动kafka消费者
[hadoop@hadoop03 kafka_2.11-1.0.0]$ bin/kafka-console-consumer.sh --zookeeper hadoop02:2181 --from-beginning --topic aura第四步:启动Flume命令:Flume官网
[hadoop@hadoop02 apache-flume-1.8.0-bin]$ bin/flume-ng agent --conf conf --conf-file /home/hadoop/apps/apache-flume-1.8.0-bin/flumetest/file2kafka.properties --name a1 -Dflume.root.logger=INFO,console 
代码实现从kafka(2.11-1.0.0)读取数据(java):
package Category;
import kafka.serializer.StringDecoder;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.util.*;
public class CategoryRealCount {
public static void main(String[] args) {
//初始化程序入口
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("CategoryRealCount");
JavaStreamingContext ssc = new JavaStreamingContext(conf,Durations.seconds(3));
//读取数据
/*HashMap kafkaParams = new HashMap<>();
kafkaParams.put("metadata.broker.list","hadoop02:9092,hadoop03:9092,hadoop04:9092");*/
Map kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "192.168.123.102:9092,192.168.123.103:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "use_a_separate_group_id_for_each_stream");
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
/*HashSet topics = new HashSet<>();
topics.add("aura");*/
Collection topics = Arrays.asList("aura");
JavaDStream logDStream = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics, kafkaParams)
).map(new Function, String>() {
@Override
public String call(ConsumerRecord stringStringConsumerRecord) throws Exception {
return stringStringConsumerRecord.value();
}
});
logDStream.print();
/* JavaDStream logDStream;
logDStream = KafkaUtils.createDirectStream(
ssc,
String.class,
String.class,
StringDecoder.class,
topics,
StringDecoder.class,
kafkaParams
).map(new Function, String>() {
@Override
public String call(Tuple2 tuple2) throws Exception {
return tuple2._2;
}
});*/
//代码的逻辑
//启动应用程序
ssc.start();
try {
ssc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}
ssc.stop();
}
} 7、品类实时统计
实时统计每日的品类的点击次数,存储到HBase(HBase表示如何设计的,rowkey是怎样设计)
rowkey的设计是:时间+name
例:2018.05.22_电影。这样做为rowkey。
创建一个HBase表:(java代码)
package habase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import java.io.IOException;
public class CreatTableTest {
public static void main(String[] args) {
//设置Hbase数据库的连接配置参数
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","192.168.123.102");
conf.set("hbase.zookeeper.property.clientPort","2181");
String tablename = "aura";
String[] famliy = {"f"};
try {
HBaseAdmin hBaseAdmin = new HBaseAdmin(conf);
//创建表对象
HTableDescriptor tableDescriptor = new HTableDescriptor(tablename);
for (int i = 0;i < famliy.length;i++){
//设置表字段
tableDescriptor.addFamily(new HColumnDescriptor(famliy[i]));
}
//判断表是否存在,不存在则创建,存在则打印提示信息
if (hBaseAdmin.tableExists(tablename)){
System.out.println("表存在");
System.exit(0);
}else {
hBaseAdmin.createTable(tableDescriptor);
System.out.println("创建表成功");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}读取Hbase数据的代码主程序:(java代码)
package Catefory1.Category;
import dao.HBaseDao;
import dao.factory.HBaseFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapred.TableOutputFormat;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapred.JobConf;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.*;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.Time;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import utils.DateUtils;
import utils.Utils;
import java.util.*;
public class CategoryRealCount11 {
public static String ck = "G:\\Scala\\spark1711\\day25-项目实时统计\\资料\\新建文件夹";
public static void main(String[] args) {
//初始化程序入口
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("CategoryRealCount");
JavaStreamingContext ssc = new JavaStreamingContext(conf,Durations.seconds(3));
ssc.checkpoint(ck);
//读取数据
/*HashMap kafkaParams = new HashMap<>();
kafkaParams.put("metadata.broker.list","hadoop02:9092,hadoop03:9092,hadoop04:9092");*/
Map kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "192.168.123.102:9092,192.168.123.103:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "use_a_separate_group_id_for_each_stream");
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
/*HashSet topics = new HashSet<>();
topics.add("aura");*/
Collection topics = Arrays.asList("aura");
JavaDStream logDStream = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics, kafkaParams)
).map(new Function, String>() {
@Override
public String call(ConsumerRecord stringStringConsumerRecord) throws Exception {
return stringStringConsumerRecord.value();
}
});
logDStream.mapToPair(new PairFunction() {
@Override
public Tuple2 call(String line) throws Exception {
return new Tuple2(Utils.getKey(line),1L);
}
}).reduceByKey(new Function2() {
@Override
public Long call(Long aLong, Long aLong2) throws Exception {
return aLong + aLong2;
}
}).foreachRDD(new VoidFunction2, Time>() {
@Override
public void call(JavaPairRDD RDD, Time time) throws Exception {
RDD.foreachPartition(new VoidFunction>>() {
@Override
public void call(Iterator> partition) throws Exception {
HBaseDao hBaseDao = HBaseFactory.getHBaseDao();
while (partition.hasNext()){
Tuple2 tuple = partition.next();
hBaseDao.save("aura",tuple._1,"f","name",tuple._2);
System.out.println(tuple._1+" "+ tuple._2);
}
}
});
}
});
/* JavaDStream logDStream;
logDStream = KafkaUtils.createDirectStream(
ssc,
String.class,
String.class,
StringDecoder.class,
topics,
StringDecoder.class,
kafkaParams
).map(new Function, String>() {
@Override
public String call(Tuple2 tuple2) throws Exception {
return tuple2._2;
}
});*/
//代码的逻辑
//启动应用程序
ssc.start();
try {
ssc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}
ssc.stop();
}
} 辅助类:
(bean):
package bean;
import java.io.Serializable;
public class CategoryClickCount implements Serializable {
//点击的品类
private String name;
//点击的次数
private long count;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getCount() {
return count;
}
public void setCount(long count) {
this.count = count;
}
public CategoryClickCount(String name, long count) {
this.name = name;
this.count = count;
}
}
(Utils):
package utils;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
public class Utils {
public static String getKey(String line) {
HashMap map = new HashMap();
map.put("0", "其他");
map.put("1", "电视剧");
map.put("2", "电影");
map.put("3", "综艺");
map.put("4", "动漫");
map.put("5", "纪录片");
map.put("6", "游戏");
map.put("7", "资讯");
map.put("8", "娱乐");
map.put("9", "财经");
map.put("10", "网络电影");
map.put("11", "片花");
map.put("12", "音乐");
map.put("13", "军事");
map.put("14", "教育");
map.put("15", "体育");
map.put("16", "儿童");
map.put("17", "旅游");
map.put("18", "时尚");
map.put("19", "生活");
map.put("20", "汽车");
map.put("21", "搞笑");
map.put("22", "广告");
map.put("23", "原创");
//获取到品类ID
String categoryid = line.split("&")[9].split("/")[4];
//获取到品类的名称
String name = map.get(categoryid);
//获取用户访问数据的时间
String stringTime = line.split("&")[8].split("=")[1];
//获取日期
String date = getDay(Long.valueOf(stringTime));
return date + "_" + name;
}
public static String getDay(long time){
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
return simpleDateFormat.format(new Date());
}
}
(dao):
package dao;
import bean.CategoryClickCount;
import java.util.List;
public interface HBaseDao {
//往hbase里面插入一条数据
public void save (String tableName,String rowkey,
String family,String q ,long value);
//根据条件查询数据
public List count(String tableName, String rowkey);
}
(dao.impl):
package dao.impl;
import bean.CategoryClickCount;
import dao.HBaseDao;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class HBaseImpl implements HBaseDao {
HConnection hatablePool = null;
public HBaseImpl(){
Configuration conf = HBaseConfiguration.create();
//HBase自带的zookeeper
conf.set("hbase.zookeeper.quorum","hadoop02:2181");
try {
hatablePool = HConnectionManager.createConnection(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 根据表名获取表对象
* @param tableName 表名
* @return 表对象
*/
public HTableInterface getTable(String tableName){
HTableInterface table = null;
try {
table = hatablePool.getTable(tableName);
} catch (IOException e) {
e.printStackTrace();
}
return table;
}
/**
* 往hbase里面插入一条数据
* @param tableName 表名
* @param rowkey rowkey
* @param family 列族
* @param q 品类
* @param value 出现了的次数
* 2018-12-12_电影 f q 19
* updateStateBykey 对内存的要求高一点
* reduceBykey 对内存要求低一点
*/
@Override
public void save(String tableName, String rowkey, String family, String q, long value) {
HTableInterface table = getTable(tableName);
try {
table.incrementColumnValue(rowkey.getBytes(),family.getBytes(),q.getBytes(),value);
} catch (IOException e) {
e.printStackTrace();
}finally {
if (table != null){
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 根据rowkey 返回数据
* @param tableName 表名
* @param rowkey rowkey
* @return
*/
@Override
public List count(String tableName, String rowkey) {
ArrayList list = new ArrayList<>();
HTableInterface table = getTable(tableName);
PrefixFilter prefixFilter = new PrefixFilter(rowkey.getBytes());//用左查询进行rowkey查询
Scan scan = new Scan();
scan.setFilter(prefixFilter);
try {
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner){
for (Cell cell : result.rawCells()){
byte[] date_name = CellUtil.cloneRow(cell);
String name = new String(date_name).split("_")[1];
byte[] value = CellUtil.cloneValue(cell);
long count = Bytes.toLong(value);
CategoryClickCount categoryClickCount = new CategoryClickCount(name, count);
list.add(categoryClickCount);
}
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (table != null){
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return list;
}
}
(dao.factory):
package dao.factory;
import dao.HBaseDao;
import dao.impl.HBaseImpl;
public class HBaseFactory {
public static HBaseDao getHBaseDao(){
return new HBaseImpl();
}
}测试类:
(Test):
package test;
import bean.CategoryClickCount;
import dao.HBaseDao;
import dao.factory.HBaseFactory;
import java.util.List;
public class Test {
public static void main(String[] args) {
HBaseDao hBaseDao = HBaseFactory.getHBaseDao();
hBaseDao.save("aura",
"2018-05-23_电影","f","name",10L);
hBaseDao.save("aura",
"2018-05-23_电影","f","name",20L);
hBaseDao.save("aura",
"2018-05-21_电视剧","f","name",11L);
hBaseDao.save("aura",
"2018-05-21_电视剧","f","name",24L);
hBaseDao.save("aura",
"2018-05-23_电视剧","f","name",110L);
hBaseDao.save("aura",
"2018-05-23_电视剧","f","name",210L);
List list = hBaseDao.count("aura", "2018-05-21");
for (CategoryClickCount cc : list){
System.out.println(cc.getName() + " "+ cc.getCount());
}
}
} 8、流程


1、项目架构