【Python】基于sklearn构建并评价聚类模型( KMeans、TSNE降维、可视化、FMI评价法等)
本博客内容来源于:
《Python数据分析与应用》第6章使用sklearn构建模型,
【 黄红梅、张良均主编 中国工信出版集团和人民邮电出版社,侵请删】
相关网站链接
一、K-Means聚类函数初步学习与使用
kmeans算法理解及代码实现
k均值聚类算法(k-means clustering algorithm)
其算法思想大致为:先从样本集中随机选取 k 个样本作为簇中心,并计算所有样本与这 k 个“簇中心”的距离,对于每一个样本,将其划分到与其距离最近的“簇中心”所在的簇中,对于新的簇计算各个簇的新的“簇中心”。
# 代码 6-10
from sklearn.datasets import load_iris
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
iris = load_iris()
iris_data = iris['data'] ##提取数据集中的特征
iris_target = iris['target'] ## 提取数据集中的标签
iris_names = iris['feature_names'] ### 提取特征名
scale = MinMaxScaler().fit(iris_data)## 训练规则
iris_dataScale = scale.transform(iris_data) ## 应用规则
kmeans = KMeans(n_clusters = 3,
random_state=12).fit(iris_dataScale) ##构建并训练模型
print('构建的K-Means模型为:\n',kmeans)
result = kmeans.predict([[1.5,1.5,1.5,1.5]])
print('花瓣花萼长度宽度全为1.5的鸢尾花预测类别为:', result[0])


可见,根据随机值random_state的不同,所划分的数据集测试集会不同,从而导致预测结果的差异
二、TSNE降维并可视化
1、稍微介绍下,暂时不深究
比PCA降维更高级——(R/Python)t-SNE聚类算法实践指南
(t-SNE)t分布随机邻域嵌入 是一种用于探索高维数据的非线性降维算法。它将多维数据映射到适合于人类观察的两个或多个维度。
2、一个非常值得好好学习的小技巧:
##提取不同标签的数据
print(df[df['labels']==0])
3、TSNE函数中random_state值设置的不同,会导致最后呈现图片变化较大
random_state=66: plt.figure(figsize=(6,4))

random_state=1: plt.figure(figsize=(6,4))

random_state=177 plt.figure(figsize=(8,6))
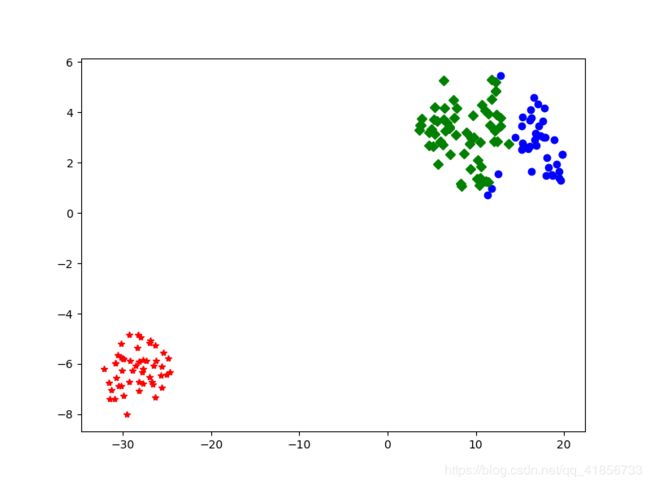
4、代码:
# 代码 6-11
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
##使用TSNE进行数据降维,降成两维
tsne = TSNE(n_components=2,init='random',
random_state=177).fit(iris_data)
df=pd.DataFrame(tsne.embedding_) ##将原始数据转换为DataFrame
#print(tsne.embedding_.shape)
df['labels'] = kmeans.labels_ ##将聚类结果存储进df数据表
#print(df['labels'].shape)
#print(df)
##提取不同标签的数据
#print(df[df['labels']==0])
df1 = df[df['labels']==0]
df2 = df[df['labels']==1]
df3 = df[df['labels']==2]
## 绘制图形
fig = plt.figure(figsize=(8,6)) ##设定空白画布,并制定大小
##用不同的颜色表示不同数据
plt.plot(df1[0],df1[1],'bo',df2[0],df2[1],'r*',
df3[0],df3[1],'gD')
plt.savefig('../tmp/聚类结果.png')
plt.show() ##显示图片
三、评价聚类模型
1、FMI评价法
2、轮廓系数评价法
3、calinski_harabaz指数评价法
# 代码 6-12
from sklearn.metrics import fowlkes_mallows_score
for i in range(2,7):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=123).fit(iris_data)
score = fowlkes_mallows_score(iris_target,kmeans.labels_)
print('iris数据聚%d类FMI评价分值为:%f' %(i,score))
# 代码 6-13
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
silhouettteScore = []
for i in range(2,15):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=123).fit(iris_data)
score = silhouette_score(iris_data,kmeans.labels_)
silhouettteScore.append(score)
plt.figure(figsize=(10,6))
plt.plot(range(2,15),silhouettteScore,linewidth=1.5, linestyle="-")
plt.show()
# 代码 6-14
from sklearn.metrics import calinski_harabaz_score
for i in range(2,7):
##构建并训练模型
kmeans = KMeans(n_clusters = i,random_state=123).fit(iris_data)
score = calinski_harabaz_score(iris_data,kmeans.labels_)
print('iris数据聚%d类calinski_harabaz指数为:%f'%(i,score))


