构建ELK+Zookeeper+Filebeat+Kafka大数据日志分析平台
架构解读
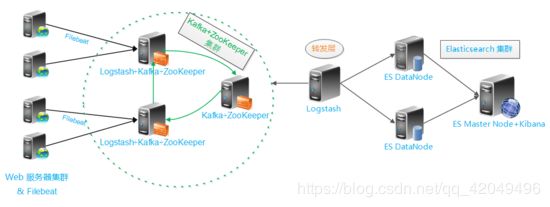
架构解读 : (整个架构从左到右,总共分为5层)
第一层:数据采集层
最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logstash服务
第二层:数据处理层,数据缓存层
logstash服务把接收到的日志经过格式处理,转存到本地的kafka broker+zookeeper集群中
第三层:数据转发层
单独的logstash节点会实时去kafka broker集群拉数据,转发至ES DataNode
第四层:数据持久化存储
ES DataNode会把收到的数据,写磁盘,建索引库
第五层:数据检索,数据展示
ES Master + Kibana主要协调ES集群,处理数据检索请求,数据展示
环境准备
(1)操作系统环境
CentOS Linux release 7.7.1908 (Core)
(2)服务器角色分配
| 主机IP | hostname | 角色 | 所属服务层 | 部署服务 |
|---|---|---|---|---|
| 192.168.213.128 | zookeeper01 | 日志生产 | 采集层 | filebeat |
| 192.168.213.128 | zookeeper01 | 日志缓存数据 | 处理层、缓存层 | zookeeper+kafka+logstash |
| 192.168.213.128 | zookeeper01 | 日志展示 | 持久、检索、展示层 | elasticsearch+logstash+kibana |
| 192.168.213.136 | zookeeper02 | zookeeper+kafka+elasticsearch | ||
| 192.168.213.135 | zookeeper03 | zookeeper+kafka+elasticsearch |
数据流向 filebeat---->logstash---->kafka---->logstash---->elasticsearch
(3)软件包版本
| 软件包版本 |
|---|
| elasticsearch-5.2.0 logstash-5.2.0 kibana-5.2.0-linux-x86_64 jdk-8u842-linux-x64 zookeeper-3.4.14 filebeat-6.6.1-linux-x86_64 kafka_2.13-2.4.1 |
部署安装
节点初始化
关闭防火墙,做时间同步(略)
部署ELK
ELK集群部署(略)
ELK集群配置
(1)配置logstash
[root@zookeeper01 ~]# cd /data/program/software/logstash
[root@zookeeper01 logstash]# cat conf.d/logstash_to_es.conf
input {
kafka {
bootstrap_servers => "192.168.213.128:9092,192.168.213.136:9092"
topics => ["test_logstash"]
}
}
output {
elasticsearch {
hosts => ["192.168.213.128:9200","192.168.213.136:9200"]
index => "dev-log-%{+YYYY.MM.dd}"
}
}
注: test_logstash字段是kafka的消息主题,后边在部署kafka后需要创建
(2)elasticsearch配置 (略)
(3)kibana配置 (略)
部署zookeeper+kafka+logstash
zookeeper集群配置(略)
kafka集群配置(略)
logstash配置
(1)服务部署(略)
(2)服务配置
[root@zookeeper01 logstash]# cat conf.d/logstash_to_filebeat.conf
input {
beats {
port => 5044
}
}
output {
kafka {
bootstrap_servers => "192.168.213.128:9092,192.168.213.136:9092"
topic_id => "test_logstash"
}
}
部署filebeat
[root@zookeeper01 filebeat]# pwd
/data/program/software/filebeat
[root@zookeeper01 filebeat]# cat nginx.yml #只列出了需要修改的部分
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
enabled: yes
paths:
- /var/log/nginx/*.log
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
注意: beat默认对接elasticsearch,需要修改为logstash
各环节服务启动与数据追踪
(1)启动zookeeper及kafka集群
[root@zookeeper01 ~]# cd /data/program/software/zookeeper
[root@zookeeper01 zookeeper]# bin/zkServer.sh start
[root@zookeeper01 ~]# cd /data/program/software/kafka
[root@zookeeper01 kafka]# nohup bin/kafka-server-start.sh config/server.properties >>/tmp/kafka.nohup &
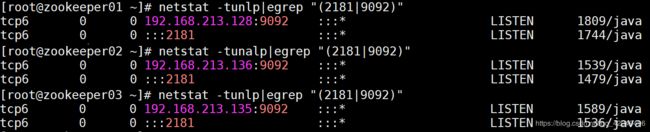
[root@zookeeper01 ~]# netstat -tunlp|egrep "(2181|9092)"
#在3个节点上执行
(2)启动elasticsearch
[root@zookeeper01 ~]su - elsearch -c "/data/program/software/elasticsearch/bin/elasticsearch -d"
#在3个节点上执行
http://192.168.213.128:9200
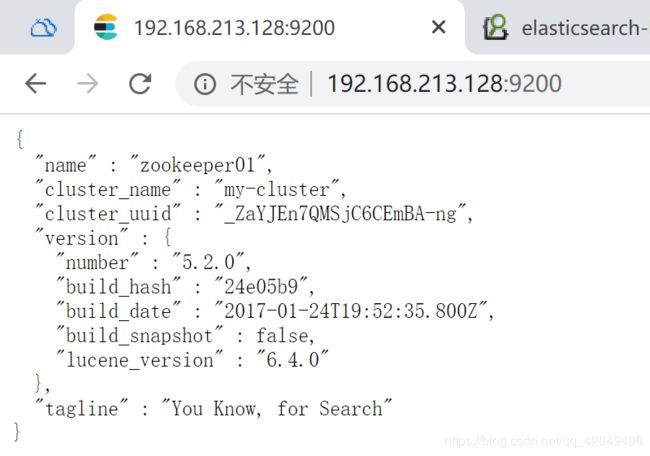 查看elasticsearch+zookeeper集群状态
查看elasticsearch+zookeeper集群状态
http://192.168.213.128:9200/_cat/nodes?pretty
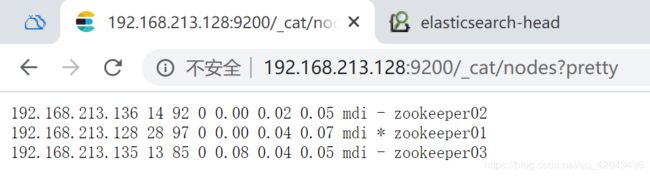
(3)启动nodejs
[root@zookeeper01 ~]# cd /data/program/software/elasticsearch/elasticsearch-head
[root@zookeeper01 elasticsearch-head]# grunt server &
http://192.168.213.128:9100

(4)启动kibana
[root@zookeeper01 ~]# cd /data/program/software/kibana
[root@zookeeper01 kibana]# nohup bin/kibana >>/tmp/kibana.nohup &
[root@zookeeper01 kibana]# netstat -tunlp|grep 5601
http://192.168.213.128:5601
(5)启动logstash
[root@zookeeper01 ~]# cd /data/program/software/logstash
[root@zookeeper01 logstash]# nohup bin/logstash -f conf.d/logstash_to_filebeat.conf >>/tmp/logstash.nohup &
(6)启动filebeat
[root@zookeeper01 ~]# cd /data/program/software/filebeat
[root@zookeeper01 filebeat]# nohup ./filebeat -e -c nginx.yml >>/tmp/filebeat.nohup &
[root@zookeeper01 filebeat]# ps -ef|grep filebeat
(7)在kafka终端上进行日志消费
[root@zookeeper03 ~]# cd /data/program/software/kafka
[root@zookeeper03 kafka]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.213.136:9092 --topic test_logstash
访问zookeeper01产生nginx日志,在kafka终端上会有实时日志消息,则filebeat---->logstash---->kafka 数据流转正常
[root@zookeeper02 ~]# curl -I 192.168.213.128
HTTP/1.1 200 OK
Server: nginx/1.16.1
Date: Tue, 14 Apr 2020 05:22:07 GMT
Content-Type: text/html
Content-Length: 4833
Last-Modified: Fri, 16 May 2014 15:12:48 GMT
Connection: keep-alive
ETag: "53762af0-12e1"
Accept-Ranges: bytes

(8)启动logstash转发
[root@zookeeper01 ~]# cd /data/program/software/logstash
[root@zookeeper01 logstash]# nohup bin/logstash -f conf.d/logstash_to_es.conf >>/tmp/logstash_to_es.nohup &
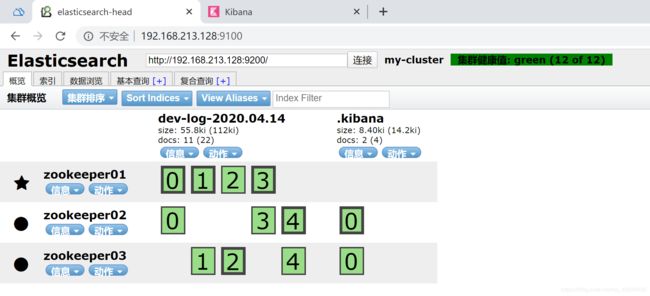
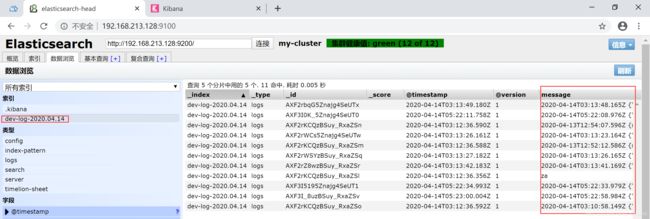
(9)elasticsearch数据展示
 (10)kibana数据展示
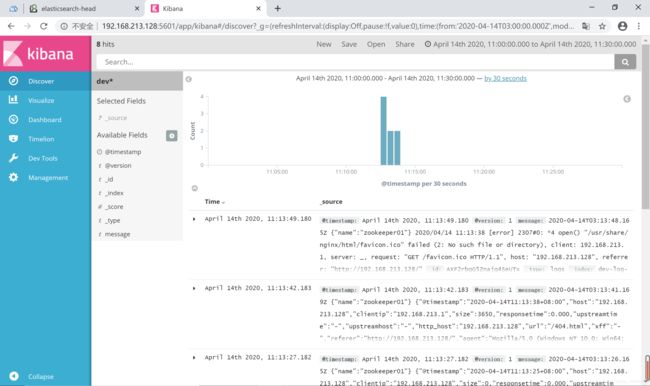
(10)kibana数据展示
踩坑记录
(1)logstash-6.6.1版本不支持同时运行多个实例
[FATAL] [logstash. runner] Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the “path.data” setting.
![]()
原因:logstash-6.6.1版本不支持同时运行多个实例,前一个运行的instance在path.data里面有.lock文件
网上大多数的解决办法是删除其data目录下的.lock文件,但这并不能解决问题,我们需要conf.d/logstash_to_filebeat.conf和conf.d/logstash_to_es.conf同时在线运行以保证实时日志统计展示,所以采用了百度出来的另一个方法,直接运行 nohup bin/logstash -f conf.d/ >>/tmp/logstash.nohup &,这样虽然运行没报错,但会使数据采集异常,疯狂输出没有用的数据
实测ELK(elasticsearch+logstash+kibana)6.6.1版本按本教程搭建的平台数据收集异常
单独测试filebeat---->logstash---->kafka数据流转正常;
单独测试kafka---->logstash---->elasticsearch数据流转正常;
整体测试数据流转异常,采集到的数据并非只是nginx的日志,且不停的输出,不及时暂停filebeat或logstash会导致无用数据占用磁盘空间庞大
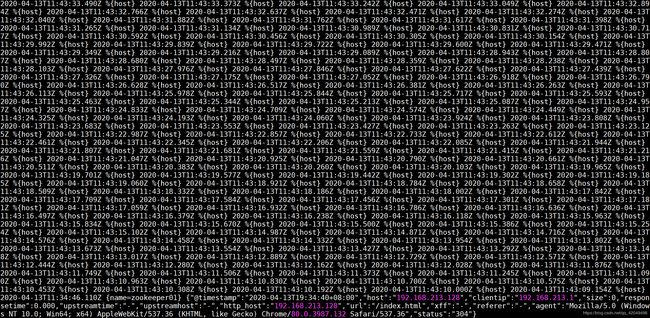
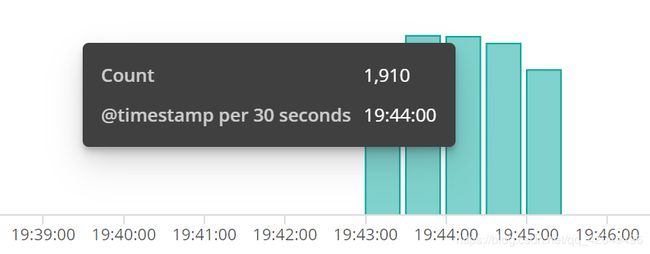 暂时没有找到此版本解决此问题的方法
暂时没有找到此版本解决此问题的方法
(2)将ELK版本回退部署后集群状态异常
http://192.168.213.128:9200/_cat/nodes?pretty
查看集群状态为503
{
"error" : {
"root_cause" : [ {
"type" : "master_not_discovered_exception",
"reason" : null
} ],
"type" : "master_not_discovered_exception",
"reason" : null
},
"status" : 503
}
查看日志,发现master没有选举成功,而且3个节点的"cluster_uuid" : "_na_"都相同(异常)
原因:把elasticsearch复制到其他节点时 ,elk_data下的运行数据也拷贝过去了
解决办法: 把elk_data目录下的内容删除,重启elasticsearch
后记
严禁按旧版本的教程用新版本的软件做实例,这无异于自己挖坑自己跳