ELK +Kafka实现日志采集系统
传统系统日志收集的问题
传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常底下。
通常,日志被分散在储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
查询命令:
tail -n 300 myes.log | grep 'node-1'
tail -100f myes.log
ELK分布式日志收集系统介绍
ElasticSearch 是一个基于Lucene的开源分布式搜索服务器。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
Logstash 是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 是一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
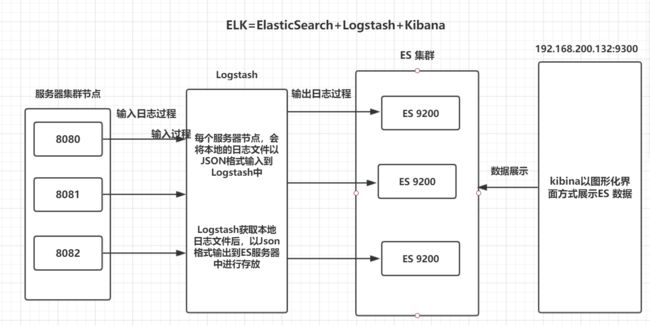
ELK分布式日志收集原理
1、每台服务器集群节点安装Logstash日志收集系统插件
2、每台服务器节点将日志输入到Logstash中
3、Logstash将该日志格式化为json格式,根据每天创建不同的索引,输出到ElasticSearch中
4、浏览器使用安装Kibana查询日志信息
环境安装
1、安装ElasticSearch
2、安装Logstash
3、安装Kibana
Logstash介绍
Logstash是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。 核心流程:Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
Logstash工作原理
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
logstash:输入(读取本地文件或者连接数据库)、输出Json 格式。
Input:输入数据到logstash,再由logstatsh输出(Json格式)数据到es服务器上。
一些常用的输入为:
file:从文件系统的文件中读取,类似于tail -f命令
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
redis:从redis service中读取
beats:从filebeat中读取
Filters:数据中间处理,对数据进行操作。
一些常用的过滤器为:
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。内置120多个解析语法。
mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
Outputs:outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。
一些常见的outputs为:
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
Codecs:codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。
一些常见的codecs:
json:使用json格式对数据进行编码/解码。
multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息。

Logstash环境安装
1、上传 logstash 安装包,我的目录为 /usr/local/es/
2、解压 tar –zxvf logstash-6.4.3.tar.gz
3、在config目录下放入test01.conf、test02.conf 读入并且读出日志信息
![]()
演示效果
1、启动./logstash -f ../config/test01.conf、./logstash -f ../config/test01.conf 分别指的是二个不同的配置文件,test01 是控制台输出 没有添加时间 输出,test02 是打印了时间。
2、启动./elasticsearch
3、启动./kibana Logstash 读取本地文件地址,实时存放在ES中,以每天格式创建不同的索引进行存放。
Kibana 平台查询
GET /es-2019.06.12/_search
test01.conf
input {
# 从文件读取日志信息 输送到控制台
file {
path => "/usr/local/es/elasticsearch-6.4.3/logs/myes.log"
codec => "json" ## 以JSON格式读取日志
type => "elasticsearch"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标准输出
# stdout {}
# 输出进行格式化,采用Ruby库来解析日志
stdout { codec => rubydebug }
}
test02.conf
input {
# 从文件读取日志信息 输送到控制台
file {
path => "/usr/local/es/elasticsearch-6.4.3/logs/myes.log"
codec => "json" ## 以JSON格式读取日志
type => "elasticsearch"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标准输出
# stdout {}
# 输出进行格式化,采用Ruby库来解析日志
stdout { codec => rubydebug }
elasticsearch {
hosts => ["192.168.200.135:9200"]
#### 创建索引 根据每天创建索引
index => "es-%{+YYYY.MM.dd}"
}
}
ES与Mysql保持数据一致性原理
logstash包含输入(读取本地文件或者连接数据库)与输出、过滤器。
如果数据新增或者修改了,ES 与 数据库如何保持一致性?
logstash做定时任务(每分钟查询一次),定时去mysql查询数据。
原理:根据updateTime字段作为条件进行查询。第一次发送Sqli请求的时候,修改时间参数值是为系统最开始的时间是1970年,可以查询到所有的数据。会将最后一条数据的updateTime记录下来,作为下一次修改时间的条件进行查询。
第一次查询 sql: SELECT * FROM user WHERE update_time >= '1970-01-01 08:00:00'; // updateTime 系统开始时间:1970-01-01 08:00:00
第二次查询 sql: SELECT * FROM user WHERE update_time >= '2019-07-13 11:15:23';// 2019-07-13 11:15:23 是 第一次查询的所有数据中,最后一条数据的 updateTime
如下图:可以看到定时任务查询的sql,还有定时为1分钟查一次。

新增数据或者修改数据的时候都会记录updateTime 时间。

本节课视频资料下载
该内容学习来源于蚂蚁课堂