python招聘信息与岗位分析数据可视化大屏展示(flask+fexible+rem+mysql)
python招聘信息与岗位分析数据可视化
- 第一部分(数据获取)
- 1.数据库表创建
- 2.数据爬取入库
- 3.数据存储与查询
- 第二部分(前端展示)
- 第三部分(flask web应用)
首先查看目录树
第一部分(数据获取)
1.数据库表创建
首先通过python的sqlalchemy模块,来新建一个表。
creat_lagou_tables.py
from sqlalchemy import create_engine, Integer,String,Float
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column
#创建数据库的连接
engine = create_engine("mysql+pymysql://root:[email protected]:3306/lagou?charset=utf8")
#操作数据库,需要我们创建一个session
Session = sessionmaker(bind=engine)
#声明一个基类
Base = declarative_base()
class Lagoutables(Base):
#表名称
__tablename__ = 'lagou_data'
#id,设置为主键和自动增长
id = Column(Integer,primary_key=True,autoincrement=True)
#岗位ID,非空字段
positionID = Column(Integer,nullable=True)
# 经度
longitude = Column(Float, nullable=False)
# 纬度
latitude = Column(Float, nullable=False)
# 岗位名称
positionName = Column(String(length=50), nullable=False)
# 工作年限
workYear = Column(String(length=20), nullable=False)
# 学历
education = Column(String(length=20), nullable=False)
# 岗位性质
jobNature = Column(String(length=20), nullable=True)
# 公司类型
financeStage = Column(String(length=30), nullable=True)
# 公司规模
companySize = Column(String(length=30), nullable=True)
# 业务方向
industryField = Column(String(length=30), nullable=True)
# 所在城市
city = Column(String(length=10), nullable=False)
# 岗位标签
positionAdvantage = Column(String(length=200), nullable=True)
# 公司简称
companyShortName = Column(String(length=50), nullable=True)
# 公司全称
companyFullName = Column(String(length=200), nullable=True)
# 公司所在区
district = Column(String(length=20), nullable=True)
# 公司福利标签
companyLabelList = Column(String(length=200), nullable=True)
# 工资
salary = Column(String(length=20), nullable=False)
# 抓取日期
crawl_date = Column(String(length=20), nullable=False)
if __name__ == '__main__':
#创建数据表
Lagoutables.metadata.create_all(engine)
首先在mysql里面新建lagou数据库,然后运行查看查看已经创建好的字段

2.数据爬取入库
通过python中的request模块接口的形式调取数据。
思路:
(1)先获取所有城市信息:需要用request模块中的requests.session(),session对象保存访问接口需要用到的信息:例如cookies等信息。
(2)通过城市分组,再用正则表达式筛选来获取python的岗位信息。其中多次用到列表生成器,以后要多注意这方面的冷知识;不然会有莫名的错误。
代码思路:只要保证可复用即可,其实很简单,毕竟Python是一门”干净“的语言。
(1)先把请求方法抽集到一个方法中:session.get(url(地址),headers(头信息),,timeout(时间),proxies(代理信息))
(2)先获取所有城市,利用列表生成器生成一个list把数据装进去。
(3)利用循环以城市分组拉去Python岗位信息。for city in lagou.city_list:调用拉取岗位信息的方法。
(4)导入multiprocessing模块,设置多线程加速抓取:multiprocessing.Pool(自定 int or long),在useragent 里面设置伪用户登录,这里有一个度量,当我爬取数据出现失败的时候,这里要暂停10秒,如果不暂停继续的话,有极大几率ip被封。需要注意的是:必须使用多线程拉取。由于拉勾网近几年反扒措施加强,不加多线程和伪用户登录,以及访问时间的设置,效率会低下,可能导致信息不全,时间太慢
handle_crawl_lagou.py
import json
import re
import time
import requests
import random
import multiprocessing
from fake_useragent import UserAgent
from lagou_spider.handle_insert_data import lagou_mysql
ua = UserAgent()
class HandleLaGou(object):
def __init__(self):
#使用session保存cookies信息
self.lagou_session = requests.session()
self.header = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Connection": "keep-alive",
"Host": "www.lagou.com",
"Referer": 'https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput=',
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
'User-Agent': 'ua.random'}
self.city_list = ""
#获取全国所有城市列表的方法
def handle_city(self):
city_search = re.compile(r'zhaopin/">(.*?)')
city_url = "https://www.lagou.com/jobs/allCity.html"
city_result = self.handle_request(method="GET",url=city_url)
#使用正则表达式获取城市列表
self.city_list = city_search.findall(city_result)
self.lagou_session.cookies.clear()
def handle_city_job(self,city):
first_request_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput="%city
first_response = self.handle_request(method="GET",url=first_request_url)
total_page_search = re.compile(r'class="span\stotalNum">(\d+)')
try:
total_page = total_page_search.search(first_response).group(1)
print(total_page)
#由于没有岗位信息造成的exception
except:
return
else:
for i in range(1,int(total_page)+1):
data = {
"pn":i,
"kd":"python"
}
page_url = "https://www.lagou.com/jobs/positionAjax.json?city=%s&needAddtionalResult=false"%city
referer_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput="%city
#referer的URL需要进行encode
self.header['Referer'] = referer_url.encode()
response = self.handle_request(method="POST",url=page_url,data=data,info=city)
lagou_data = json.loads(response)
job_list = lagou_data['content']['positionResult']['result']
for job in job_list:
lagou_mysql.insert_item(job)
def handle_request(self,method,url,data=None,info=None):
while True:
try:
if method == "GET":
# response = self.lagou_session.get(url=url,headers=self.header,proxies=proxy,timeout=6)
response = self.lagou_session.get(url=url,headers=self.header,timeout=6)
elif method == "POST":
# response = self.lagou_session.post(url=url,headers=self.header,data=data,proxies=proxy,timeout=6)
response = self.lagou_session.post(url=url,headers=self.header,data=data,timeout=6)
except:
# 需要先清除cookies信息
self.lagou_session.cookies.clear()
# 重新获取cookies信息
first_request_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput=" % info
self.handle_request(method="GET", url=first_request_url)
time.sleep(20)
continue
response.encoding = 'utf-8'
if '频繁' in response.text:
print(response.text)
#需要先清除cookies信息
self.lagou_session.cookies.clear()
# 重新获取cookies信息
first_request_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput="%info
self.handle_request(method="GET",url=first_request_url)
time.sleep(20)
continue
return response.text
if __name__ == '__main__':
lagou = HandleLaGou()
# 所有城市的方法
lagou.handle_city()
print(lagou.city_list)
# # 引入多进程加速抓取
pool = multiprocessing.Pool(2)
for city in lagou.city_list:
pool.apply_async(lagou.handle_city_job,args=(city,))
pool.close()
pool.join()
while True:
city_list = ['北京','上海','广州','深圳','大连','成都','哈尔滨','重庆','无锡','西安','天津','石家庄','青岛','宁波']
for city in city_list:
lagou.handle_city_job(city)
time.sleep(10)
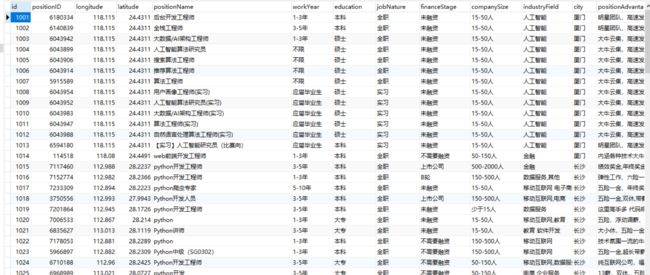
查看数据库
3.数据存储与查询
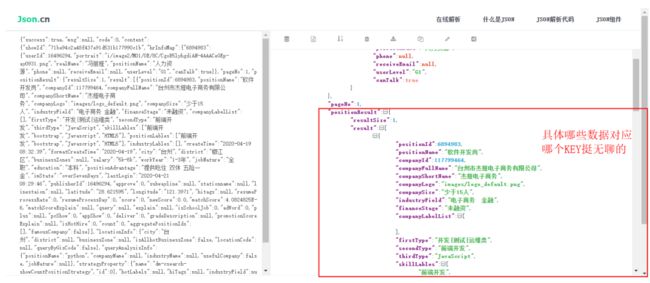
思路:(1)由于拉取的是JSON格式,所以解读JSON格式,也是很繁琐的,需要把要的数据一条一条对应到固定的Key里,如图:
(2)利用session对象的query方法,可以过滤查询想要的数据。
session.query(Lagoutables.workYear).filter(Lagoutables.crawl_date==self.date).all()
handle_insert_data.py
#-*- coding:utf-8 -*-
from collections import Counter
from sqlalchemy import func
from lagou_spider.create_lagou_tables import Lagoutables
from lagou_spider.create_lagou_tables import Session
import time
class HandleLagouData(object):
def __init__(self):
#实例化session信息
self.mysql_session = Session()
self.date = time.strftime("%Y-%m-%d",time.localtime())
#数据的存储方法
def insert_item(self,item):
#今天
date = time.strftime("%Y-%m-%d",time.localtime())
#存储的数据结构
data = Lagoutables(
#岗位ID
positionID = item['positionId'],
# 经度
longitude=item['longitude'],
# 纬度
latitude=item['latitude'],
# 岗位名称
positionName=item['positionName'],
# 工作年限
workYear=item['workYear'],
# 学历
education=item['education'],
# 岗位性质
jobNature=item['jobNature'],
# 公司类型
financeStage=item['financeStage'],
# 公司规模
companySize=item['companySize'],
# 业务方向
industryField=item['industryField'],
# 所在城市
city=item['city'],
# 岗位标签
positionAdvantage=item['positionAdvantage'],
# 公司简称
companyShortName=item['companyShortName'],
# 公司全称
companyFullName=item['companyFullName'],
# 公司所在区
district=item['district'],
# 公司福利标签
companyLabelList=','.join(item['companyLabelList']),
salary=item['salary'],
# 抓取日期
crawl_date=date
)
#在存储数据之前,先来查询一下表里是否有这条岗位信息
query_result = self.mysql_session.query(Lagoutables).filter(Lagoutables.crawl_date==date,
Lagoutables.positionID==item['positionId']).first()
if query_result:
print('该岗位信息已存在%s:%s:%s'%(item['positionId'],item['city'],item['positionName']))
else:
#插入数据
self.mysql_session.add(data)
#提交数据到数据库
self.mysql_session.commit()
print('新增岗位信息%s'%item['positionId'])
#行业信息
def query_industryfield_result(self):
info = {}
# 查询今日抓取到的行业信息数据
result = self.mysql_session.query(Lagoutables.industryField).filter(
Lagoutables.crawl_date==self.date
).all()
result_list1 = [x[0].split(',')[0] for x in result]
# print(result_list1)
result_list2 = [x for x in Counter(result_list1).items() if x[1]>2]
# print(result_list2)
#填充的是series里面的data
data = [{"name":x[0],"value":x[1]} for x in result_list2]
name_list = [name['name'] for name in data]
info['x_name'] = name_list
info['data'] = data
return info
# 查询薪资情况
def query_salary_result(self):
info = {}
# 查询今日抓取到的薪资数据
result = self.mysql_session.query(Lagoutables.salary).filter(Lagoutables.crawl_date==self.date).all()
# 处理原始数据
result_list1 = [x[0] for x in result]
# 计数,并返回
# print(result_list1)
result_list2 = [x for x in Counter(result_list1).items() if x[1]>1]
result = [{"name": x[0], "value": x[1]} for x in result_list2]
name_list = [name['name'] for name in result]
info['x_name'] = name_list
info['data'] = result
return info
# 查询工作年限情况
def query_workyear_result(self):
info = {}
# 查询今日抓取到的薪资数据
result = self.mysql_session.query(Lagoutables.workYear).filter(Lagoutables.crawl_date==self.date).all()
# 处理原始数据
result_list1 = [x[0] for x in result]
# 计数,并返回
result_list2 = [x for x in Counter(result_list1).items()]
result = [{"name": x[0], "value": x[1]} for x in result_list2 if x[1]>15]
name_list = [name['name'] for name in result]
info['x_name'] = name_list
info['data'] = result
return info
# 查询学历信息
def query_education_result(self):
info = {}
# 查询今日抓取到的薪资数据
result = self.mysql_session.query(Lagoutables.education).filter(Lagoutables.crawl_date==self.date).all()
# 处理原始数据
result_list1 = [x[0] for x in result]
# 计数,并返回
result_list2 = [x for x in Counter(result_list1).items()]
result = [{"name": x[0], "value": x[1]} for x in result_list2]
name_list = [name['name'] for name in result]
info['x_name'] = name_list
info['data'] = result
return info
# 职业名称,横向柱状图
def query_job_result(self):
info = {}
# 查询今日抓取到的行业信息数据
result = self.mysql_session.query(Lagoutables.positionName).filter(
Lagoutables.crawl_date == self.date
).all()
result_list1 = [x[0].split(',')[0] for x in result]
# print(result_list1)
result_list2 = [x for x in Counter(result_list1).items() if x[1] > 1]
# print(result_list2)
# 填充的是series里面的data
data = [{"name": x[0], "value": x[1]} for x in result_list2]
name_list = [name['name'] for name in data]
info['x_name'] = name_list
info['data'] = data
return info
# 根据城市计数
def query_city_result(self):
info = {}
# 查询今日抓取到的薪资数据
result = self.mysql_session.query(Lagoutables.city,func.count('*').label('c')).filter(Lagoutables.crawl_date==self.date).group_by(Lagoutables.city).all()
# print(result)
result1 = [{"name": x[0], "value": x[1]} for x in result]
# print(result1)
name_list = [name['name'] for name in result1]
# print(name_list)
info['x_name'] = name_list
info['data'] = result1
return info
#融资情况
def query_financestage_result(self):
info = {}
# 查询今日抓取到的薪资数据
result = self.mysql_session.query(Lagoutables.financeStage).filter(Lagoutables.crawl_date == self.date).all()
# 处理原始数据
result_list1 = [x[0] for x in result]
# 计数,并返回
result_list2 = [x for x in Counter(result_list1).items()]
result = [{"name": x[0], "value": x[1]} for x in result_list2]
name_list = [name['name'] for name in result]
info['x_name'] = name_list
info['data'] = result
return info
# 公司规模
def query_companysize_result(self):
info = {}
# 查询今日抓取到的薪资数据
result = self.mysql_session.query(Lagoutables.companySize).filter(Lagoutables.crawl_date == self.date).all()
# 处理原始数据
result_list1 = [x[0] for x in result]
# 计数,并返回
result_list2 = [x for x in Counter(result_list1).items()]
result = [{"name": x[0], "value": x[1]} for x in result_list2]
name_list = [name['name'] for name in result]
info['x_name'] = name_list
info['data'] = result
return info
# 任职情况
def query_jobNature_result(self):
info = {}
# 查询今日抓取到的薪资数据
result = self.mysql_session.query(Lagoutables.jobNature).filter(Lagoutables.crawl_date == self.date).all()
# 处理原始数据
result_list1 = [x[0] for x in result]
# 计数,并返回
result_list2 = [x for x in Counter(result_list1).items()]
result = [{"name": x[0], "value": x[1]} for x in result_list2]
name_list = [name['name'] for name in result]
info['x_name'] = name_list
info['data'] = result
return info
# 抓取数量
def count_result(self):
info = {}
info['all_count'] = self.mysql_session.query(Lagoutables).count()
info['today_count'] = self.mysql_session.query(Lagoutables).filter(Lagoutables.crawl_date==self.date).count()
return info
lagou_mysql = HandleLagouData()
第二部分(前端展示)
前端结果:
本前端参考哔哩哔哩
https://www.bilibili.com/video/BV1v7411R7mp?from=search&seid=13471275291359907766
原图: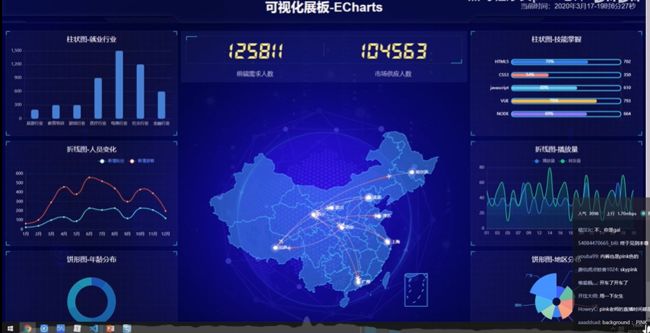
想深入了解或者修改图形样式可以看原视频
简单查看一下前端代码结构:
第三部分(flask web应用)
使用flask将index.html转化为web应用
run.py
from flask import Flask, render_template, jsonify
from lagou_spider.handle_insert_data import lagou_mysql
# 实例化flask
app = Flask(__name__)
# 注册路由
# @app.route("/")
# def index():
# return "Hello World"
@app.route("/get_echart_data")
def get_echart_data():
info = {}
# 行业发布数量分析
info['echart_1'] = lagou_mysql.query_industryfield_result()
# print(info['echart_1'] )
# 薪资发布数量分析
info['echart_2'] = lagou_mysql.query_salary_result()
# 岗位数量分析,折线图
info['echart_4'] = lagou_mysql.query_job_result()
#工作年限分析
info['echart_5'] = lagou_mysql.query_workyear_result()
#学历情况分析
info['echart_6'] = lagou_mysql.query_education_result()
#融资情况
info['echart_31'] = lagou_mysql.query_financestage_result()
#公司规模
info['echart_32'] = lagou_mysql.query_companysize_result()
#岗位要求
info['echart_33'] = lagou_mysql.query_jobNature_result()
#各地区发布岗位数
info['map'] = lagou_mysql.query_city_result()
return jsonify(info)
@app.route("/",methods=['GET','POST'])
def lagou():
# 库内数据总量,今日抓取量
result = lagou_mysql.count_result()
return render_template('index.html',result=result)
if __name__ == '__main__':
# 启动flask
app.run()
思路:
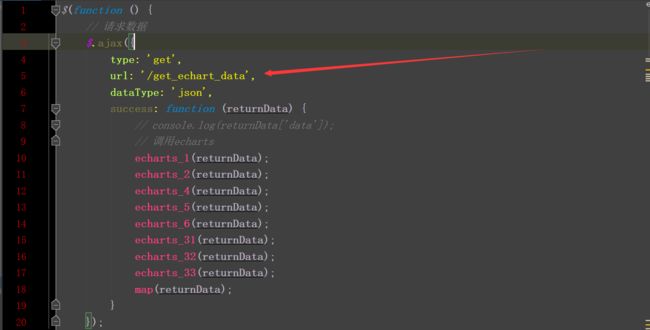
(1)首先需要通过编写JS文件,将几个图的数据放在一个方法里提高聚合,抽取出来提高可复用性。
(2)然后通过拼接把获取到的JSON格式的数据,按key:balue格式分配出来。
代码如下:
利用Ajax通信
运行run.py后查看5000端口:
本案例代码已经同步到码云,有需要的可以下载,地址:
https://gitee.com/shuaidapao/lagouflask