Java网络爬虫入门
网络爬虫简介
随着互联网的迅速发展,网络资源越来越丰富,信息需求者如何从网络中抽取信息变得至关重要。目前,有效的获取网络数据资源的重要方式,便是网络爬虫技术。简单的理解,比如您对百度贴吧的一个帖子内容特别感兴趣,而帖子的回复却有1000多页,这时采用逐条复制的方法便不可行。而采用网络爬虫便可以很轻松地采集到该帖子下的所有内容。
网络爬虫技术最广泛的应用是在搜索引擎中,如百度、Google、Bing 等,它完成了搜索过程中的最关键的步骤,即网页内容的抓取。下图为简单搜索引擎原理图。
网络爬虫的作用,总结为以下几点:
- 舆情分析:企业或政府利用爬取的数据,采用数据挖掘的相关方法,发掘用户讨论的内容、实行事件监测、舆情引导等。
- 企业的用户分析:企业利用网络爬虫,采集用户对其企业或商品的看法、观点以及态度,进而分析用户的需求、自身产品的优劣势、顾客抱怨等。
- 科研工作者的必备技术:现有很多研究都以网络大数据为基础,而采集网络大数据的必备技术便是网络爬虫。利用网络爬虫技术采集的数据可用于研究产品个性化推荐、文本挖掘、用户行为模式挖掘等。
网络爬虫(Web Crawler),又称为网络蜘蛛(Web Spider)或 Web 信息采集器,是一种按照一定规则,自动抓取或下载网络信息的计算机程序或自动化脚本,是目前搜索引擎的重要组成部分。
狭义上理解:利用标准的 HTTP 协议,根据网络超链接(如https://www.baidu.com/)和 Web 文档检索的方法(如深度优先)遍历万维网信息空间的软件程序。
功能上理解:确定待爬的 URL 队列,获取每个 URL 对应的网页内容(如 HTML/JSON),解析网页内容,并存储对应的数据。
爬虫分类
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
通用网络爬虫又称全网爬虫(Scalable Web Crawler),爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。 这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,但需要较长时间才能刷新一次页面。 简单的说就是互联网上抓取所有数据。
聚焦网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler),是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求 。简单的说就是互联网上只抓取某一种数据。
增量式网络爬虫(Incremental Web Crawler)是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。简单的说就是互联网上只抓取刚刚更新的数据。
深层网络爬虫:Web 页面按存在方式可以分为表层网页(Surface Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。 表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面,比如百度百科之类的页面,深层页面比如QQ空间这些需要登录的页面。Web 是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。
爬虫的流程
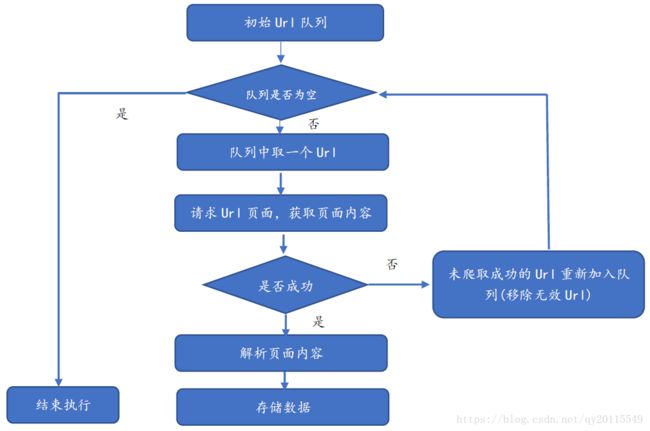
入门Demo
1. 准备工作,创建maven项目,添加httpclient和slf4j依赖,配置log4j.properties
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
2. 创建http客户端,发送请求,获取返回数据
package cn.lzx.magic;
import org.apache.http.NameValuePair;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
/**
* HttpClient测试
*
*/
public class HttpClientDemo {
public static void main(String[] args) throws UnsupportedEncodingException {
//创建Http客户端
CloseableHttpClient client = HttpClients.createDefault();
//创建不带参数的Get请求
HttpGet request = new HttpGet("https://www.ithome.com/");
//创建带参数的GET请求
//HttpGet request = new HttpGet("https://live.ithome.com/item/414560.htm");
//创建不带参数的Post请求
//HttpPost request = new HttpPost("https://soft.ithome.com/qq/");
//创建带参数的Post请求 参数为keys=java
//HttpPost request = new HttpPost("http://yun.itheima.com/search");
//创建集合 用于存放post请求体内容
//ArrayList param = new ArrayList<>();
//param.add(new BasicNameValuePair("keys","java"));
//将集合转换为entity
//UrlEncodedFormEntity form = new UrlEncodedFormEntity(param, "utf-8");
//将请求体放到post里
//request.setEntity(form);
//创建Request配置对象 配置相关参数 (可选)
RequestConfig config = RequestConfig.custom()
.setConnectTimeout(1000) //设置创建连接的超时时间
.setConnectionRequestTimeout(1000) //设置请求超时时间
.setSocketTimeout(10 * 1000) //设置数据传输的超时时间
.build();
request.setConfig(config);
try {
//发送请求 接受返回数据
CloseableHttpResponse response = client.execute(request);
//获取相应数据 判断请求状态
if (response.getStatusLine().getStatusCode()==200){
//响应状态200 请求成功
//获取响应数据 EntityUntils是http自带的工具类 用于将获取到的entity数据转换为String
String content = EntityUtils.toString(response.getEntity(),"utf-8");
System.out.println(content);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
3. 解析数据
我们抓取到页面之后,还需要对页面进行解析。可以使用字符串处理工具解析页面,也可以使用正则表达式,但是这些方法都会带来很大的开发成本,所以我们需要使用一款专门解析html页面的技术。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
jsoup的主要功能如下:
1. 从一个URL,文件或字符串中解析HTML
2. 使用DOM或CSS选择器来查找、取出数据
3. 可操作HTML元素、属性、文本
Jsoup演示
首先加入依赖
org.jsoup
jsoup
1.10.3
junit
junit
4.12
org.apache.commons
commons-lang3
3.7
commons-io
commons-io
2.6
package cn.lzx.magic;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
/**
* Jsoup测试
*/
public class JsoupDemo {
public static void main(String[] args) throws Exception {
//Jsoup可以直接输入url,它会发起请求并获取数据,封装为Document对象
Document document = Jsoup.parse("http://www.zol.com.cn/");
//根据标签获取数据 获得第一个title标签的内容
Element element = document.getElementsByTag("body").first();
System.out.println(element.text());
//解析本地文件
//获取title的内容
Document document2 = Jsoup.parse(new File("D:\\jsoup.html"), "UTF-8");
Element title = document2.getElementsByTag("title").first();
System.out.println(title.text());
//1. 根据id查询元素getElementById
Element element2 = document.getElementById("city_bj");
//2. 根据标签获取元素getElementsByTag
element = document.getElementsByTag("title").first();
//3. 根据class获取元素getElementsByClass
element = document.getElementsByClass("s_name").last();
//4. 根据属性获取元素getElementsByAttribute
element = document.getElementsByAttribute("abc").first();
element = document.getElementsByAttributeValue("class", "city_con").first();
//通过select选择器获得元素
//#id: 通过ID查找元素,比如:#city_bjj
String str = document.select("#city_bj").text();
//.class: 通过class名称查找元素,比如:.class_a
str = document.select(".class_a").text();
//[attribute]: 利用属性查找元素,比如:[abc]
str = document.select("[abc]").text();
//[attr=value]: 利用属性值来查找元素,比如:[class=s_name]
str = document.select("[class=s_name]").text();
//select选择器组合使用
//el#id: 元素+ID,比如: h3#city_bj
String str2 = document.select("h3#city_bj").text();
//el.class: 元素+class,比如: li.class_a
str = document.select("li.class_a").text();
//el[attr]: 元素+属性名,比如: span[abc]
str = document.select("span[abc]").text();
//任意组合,比如:span[abc].s_name
str = document.select("span[abc].s_name").text();
//ancestor child: 查找某个元素下子元素,比如:.city_con li 查找"city_con"下的所有li
str = document.select(".city_con li").text();
//parent > child: 查找某个父元素下的直接子元素,
//比如:.city_con > ul > li 查找city_con第一级(直接子元素)的ul,再找所有ul下的第一级li
str = document.select(".city_con > ul > li").text();
//parent > * 查找某个父元素下所有直接子元素.city_con > *
str = document.select(".city_con > *").text();
}
}
由上面的实例可以看出,虽然使用Jsoup可以替代HttpClient直接发起请求解析数据,但是往往不会这样用,因为实际的开发过程中,需要使用到多线程,连接池,代理等等方式,而jsoup对这些的支持并不是很好,所以我们一般把jsoup仅仅作为Html解析工具使用。
jsoup获取元素方式总结如下:
- 根据id查询元素getElementById
- 根据标签获取元素getElementsByTag
- 根据class获取元素getElementsByClass
- 根据属性获取元素getElementsByAttribute
- 使用选择器获取元素
4. 数据存储
解决了元素解析之后,然后通过持久化框架(mybatis、spring data jpa等)将数据存储进数据库。
总结
通过以上介绍,了解了网络爬虫以及如何利用Java来做网络爬虫,但httpclient和jsoup仍存在以下问题:
- 编码复杂,无论是httpclient的创建还是jsoup解析获得html文档都比较复杂
- 当需要爬取的数据量很大时,单线程的性能远远不够,需要手动实现线程池,配合一起使用
- 现在每次程序只能爬取单个网页(单个http请求),而我们一般需要爬取大量数据
为了解决以上问题,引入WebMagic框架,WebMagic的底层还是httpclient和jsoup,但对他们进行了封装,简化了代码编写并实现了多线程,多任务等功能,他的设计参考了Python的网络爬虫Scapy框架,但是实现方式更Java化一些。