Linux下Git本地仓库的搭建与使用
Git教程 - 廖雪峰的官方网站:https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000/
一、Git是什么?
Git是目前世界上最先进的分布式版本控制系统(没有之一)。可以有效、高速地处理从很小到非常大的项目版本管理。 Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
Torvalds 开始着手开发 Git 是为了作为一种过渡方案来替代 BitK
二、SVN与Git的最主要的区别?
- SVN是集中式版本控制系统,版本库是集中放在中央服务器的,而干活的时候,用的都是自己的电脑,所以首先要从中央服务器哪里得到最新的版本, 然后干活,干完后,需要把自己做完的活推送到中央服务器。集中式版本控制系统是必须联网才能工作,如果在局域网还可以,带宽够大,速度够快,如果在互联网 下,如果网速慢的话,就纳闷了。
- Git是分布式版本控制系统,那么它就没有中央服务器的,每个人的电脑就是一个完整的版本库,这样,工作的时候就不需要联网了,因为版本都是在 自己的电脑上。既然每个人的电脑都有一个完整的版本库,那多个人如何协作呢?比如说自己在电脑上改了文件A,其他人也在电脑上改了文件A,这时,你们两之 间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
分布式相比于集中式的最大区别在于开发者可以提交到本地,每个开发者通过克隆(git clone),在本地机器上拷贝一个完整的Git仓库。
三、实验环境(rhel7.3版本)
1、selinux和firewalld状态为disabled
2、各主机信息如下:
| 主机 | ip |
|---|---|
| server1(git) | 172.25.83.1 |
四、Git本地仓库的搭建与使用
安装git
[root@server1 ~]# yum install git -y
创建版本库(这里创建的版本库的名字为demo)
版本库又名仓库,英文名repository,可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改、删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻可以还原。
[root@server1 ~]# mkdir demo #这里创建的版本库的名字为demo,该目录在哪里创建都可以
[root@server1 ~]# cd demo/
[root@server1 demo]# ls
[root@server1 demo]# l.
. ..
[root@server1 demo]# git init #进行初始化,需要在版本库目录中(这里的版本库目录为demo)
Initialized empty Git repository in /root/demo/.git/
[root@server1 demo]# l.
. .. .git
[root@server1 demo]# ls .git/
branches config description HEAD hooks info objects refs
可以发现当前目录下多了一个.git的目录,这个目录是Git来跟踪管理版本库的,没事千万不要手动修改这个目录里面的文件,不然改乱了,就把Git仓库给破坏了
用户信息
当安装完 Git 应该做的第一件事就是设置你的用户名称与邮件地址。
每一个 Git 的提交都会使用这些信息,并且它会写入到你的每一次提交中,不可更改。
[root@server1 demo]# git config --global user.name xjj #设置用户名
[root@server1 demo]# git config --global user.email [email protected] #设置用户邮箱
[root@server1 ~]# pwd
/root
[root@server1 ~]# cat .gitconfig
[user]
name = xjj
email = [email protected]
状态简览
git status命令的输出十分详细,但其用语有些繁琐。 如果你使用git status -s命令或git status --short命令,你将得到一种更为紧凑的格式输出。 运行git status -s,状态报告输出如下:M README MM Rakefile A lib/git.rb M lib/simplegit.rb ?? LICENSE.txt
- 新添加的未跟踪文件前面有
??标记;- 新添加到暂存区中的文件前面有
A标记;- 修改过的文件前面有
M标记。M有两个可以出现的位置:
- 出现在右边的
M表示该文件被修改了但是还没放入暂存区,- 出现在靠左边的
M表示该文件被修改了并放入了暂存区。
- 加到暂存区之后,又修改了一次,修改之后,并没有添加到暂存区,前面有
MM标记。以此类推,如果加到暂存区之后,被修改了两次,修改之后,并没有添加到暂存区,前面有MMM标记。......
把文件添加到版本库+查看文件的修改内容+查看放到提交到git仓库的日志
<1>
编写用于上传的文件,这里编写的文件是file1。
一定要放到demo目录下(子目录也行),因为这是一个Git仓库,放到其他地方Git再厉害也找不到这个文件。
[root@server1 demo]# echo xjj > file1
[root@server1 demo]# git status -s
?? file1
<2>
把一个文件放到Git仓库只需要两步。
第一步,用命令git add告诉Git,把文件添加到仓库
[root@server1 demo]# git add file1
[root@server1 demo]# git status -s
A file1执行上面的命令,没有任何显示,这就对了,Unix的哲学是“没有消息就是好消息”,说明添加成功。
<3>
第二步,用命令git commit告诉Git,把文件提交到仓库git commit命令,-m后面输入的是本次提交的说明,可以输入任意内容,当然最好是有意义的,这样你就能从历史记录里方便地找到改动记录。
[root@server1 demo]# git commit -m "add file1"
[master (root-commit) d81d6af] add file1
1 file changed, 1 insertion(+)
create mode 100644 file1
[root@server1 demo]# git status -s
[root@server1 demo]# git commit命令执行成功后会告诉你,1 file changed:1个文件被改动(我们新添加的file1文件);2 insertions:插入了一行内容(file1有两行内容)。
<4>
为什么Git添加文件需要add,commit一共两步呢?因为commit可以一次提交很多文件,所以你可以多次add不同的文件,比如:
$ git add file1.txt
$ git add file2.txt file3.txt
$ git commit -m "add 3 files."
<5>
我们已经成功地添加并提交了一个file1文件,现在,是时候继续工作了,于是,我们继续修改file1文件,改成如下内容:
[root@server1 demo]# echo is >> file1
[root@server1 demo]# git status -s
M file1 #表示file1文件被修改过,但是还没有放到暂存区
[root@server1 demo]# git add file1
[root@server1 demo]# git status -s
M file1 #表示file1文件被修改过,并且放到暂存区了
[root@server1 demo]# echo a >> file1
[root@server1 demo]# git status -s
MM file1
[root@server1 demo]# git add file1
[root@server1 demo]# git status -s
M file1
[root@server1 demo]# git commit -m "change file1"
[master 13c9b66] change file1
1 file changed, 2 insertions(+)
[root@server1 demo]# git status -s
[root@server1 demo]#
[root@server1 demo]# echo good >> file1
[root@server1 demo]# git status -s
M file1
<6>
虽然Git告诉我们file1被修改了,但如果能看看具体修改了什么内容,自然是很好的。比如你休假两周从国外回来,第一天上班时,已经记不清上次怎么修改的file1,所以,需要用git diff这个命令看看:
[root@server1 demo]# git diff file1
diff --git a/file1 b/file1
index 503ecc6..2727155 100644
--- a/file1
+++ b/file1
@@ -1,3 +1,4 @@
xjj
is
a
+good git diff顾名思义就是查看difference,显示的格式正是Unix通用的diff格式,可以从上面的命令输出看到,我们在最后一行添加了一个good单词。
知道了对file1作了什么修改后,再把它提交到仓库就放心多了,提交修改和提交新文件是一样的两步,第一步是git add:
[root@server1 demo]# git add file1
[root@server1 demo]# git status -s
M file1
同样没有任何输出。在执行第二步git commit之前,我们再运行git status看看当前仓库的状态:
[root@server1 demo]# git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD ..." to unstage)
#
# modified: file1
#
git status告诉我们,将要被提交的修改包括file1,下一步,就可以放心地提交了:
[root@server1 demo]# git commit -m "change 2 file1"
[master 94d4710] change 2 file1
1 file changed, 1 insertion(+)
提交后,我们再用git status命令看看仓库的当前状态:
[root@server1 demo]# git status
# On branch master
nothing to commit, working directory cleanGit告诉我们当前没有需要提交的修改,而且,工作目录是干净(working tree clean)的。
<7>
如果我们想查看我们往git仓库中提交了几次,可以使用git log命令
git log 命令可以显示所有提交过的版本信息
[root@server1 demo]# git log
commit 94d4710c318fef1d80b1cc3d03bc40b0b35321e8
Author: xjj
Date: Thu Apr 11 18:34:47 2019 +0800
change 2 file1 #第三次提交时添加的说明
commit 13c9b6674d0dbd96af12d8f09ffeacf637e05fa5
Author: xjj
Date: Thu Apr 11 18:21:28 2019 +0800
change file1 #第二次提交时添加的说明
commit d81d6af9e31a3281558586b8c8f1002cbadeae38
Author: xjj
Date: Thu Apr 11 18:07:09 2019 +0800
add file1 #第一次提交时添加的说明
git log命令看到的内容太过繁琐,如果我们想查看更精简的输出,可以使用git log --pretty=oneline命令。
[root@server1 demo]# git log --pretty=oneline
94d4710c318fef1d80b1cc3d03bc40b0b35321e8 change 2 file1 #第三次提交时添加的说明
13c9b6674d0dbd96af12d8f09ffeacf637e05fa5 change file1 #第二次提交时添加的说明
d81d6af9e31a3281558586b8c8f1002cbadeae38 add file1 #第一次提交时添加的说明
需要友情提示的是,你看到的一大串类似
94d4710...的是commit id(版本号),和SVN不一样,Git的commit id不是1,2,3……递增的数字,而是一个SHA1计算出来的一个非常大的数字,用十六进制表示,而且你看到的commit id和我的肯定不一样,以你自己的为准。为什么commit id需要用这么一大串数字表示呢?因为Git是分布式的版本控制系统,后面我们还要研究多人在同一个版本库里工作,如果大家都用1,2,3……作为版本号,那肯定就冲突了。
git reflog命令。相比于git log命令记录的内容的条数要多。
git reflog可以查看所有分支的所有操作记录(包括已经被删除的 commit 记录和 reset 的操作)
[root@server1 demo]# git reflog
94d4710 HEAD@{0}: commit: change 2 file1 #第三次提交时添加的说明
13c9b66 HEAD@{1}: commit: change file1 #第二次提交时添加的说明
d81d6af HEAD@{2}: commit (initial): add file1 #第一次提交时添加的说明
忽略文件
有些文件无需纳入 Git 的管理,也不希望它们总出现在未跟踪文件列表。 通常都是些自动生成的文件,比如日志文件,或者编译过程中创建的临时文件等。 在这种情况下,我们可以创建一个名为 .gitignore 的文件,列出要忽略的文件模式
- 星号(*)匹配零个或多个任意字符;
- [abc] 匹配任何一个列在方括号中的字符(这个例子要么匹配一个 a,要么匹配一个 b,要么匹配一个c);
- 问号(?)只匹配一个任意字符;
- 如果在方括号中使用短划线分隔两个字符,表示所有在这两个字符范围内的都可以匹配(比如 [0-9]表示匹配所有 0 到 9 的数字)。
- 使用两个星号(*) 表示匹配任意中间目录,比如
a/**/z可以匹配 a/z, a/b/z 或a/b/c/z等
[root@server1 demo]# cp ~/.bashrc .
[root@server1 demo]# git status -s
?? .bashrc
此时编写.gitignore文件
[root@server1 demo]# cat .gitignore
.*
[root@server1 demo]# git status -s # 无任何输出
[root@server1 demo]# l.
. .. .bashrc .git .gitignore
工作区和暂存区
工作区有一个隐藏目录.git,这个不算工作区,而是Git的版本库。
Git的版本库里存了很多东西,其中最重要的就是称为stage(或者叫index)的暂存区,还有Git为我们自动创建的第一个分支master,以及指向master的一个指针叫HEAD。
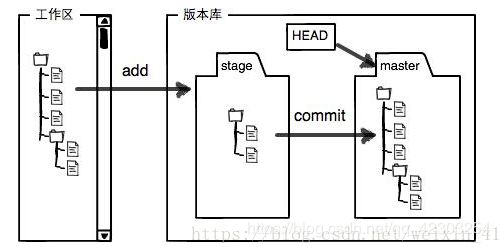
第一步是用
git add把文件添加进去,实际上就是把文件修改添加到暂存区;第二步是用
git commit提交更改,实际上就是把暂存区的所有内容提交到当前分支。
撤销修改
<1>第一种情况:file1文件修改后还没有提交到暂存区,这种情况下的撤销修改
在file1中多添加了一行内容:
[root@server1 demo]# echo girl >> file1
[root@server1 demo]# cat file1
xjj
is
a
good
girl
[root@server1 demo]# git status -s
M file1
下面的图表示:git会告诉你,"git checkout -- file"可以丢弃工作区的修改

[root@server1 demo]# git checkout -- file1
[root@server1 demo]# cat file1 #再次查看已经复原
xjj
is
a
good
<2>第二种情况:file1文件修改后提交到暂存区但还没有上传到git仓库,这种情况下的撤销修改
[root@server1 demo]# echo girl! >> file1
[root@server1 demo]# cat file1
xjj
is
a
good
girl!
[root@server1 demo]# git add file1
[root@server1 demo]# git status -s
M file1
用命令git reset HEAD 可以把暂存区的修改撤销掉(unstage),重新放回工作区
[root@server1 demo]# git reset HEAD file1
Unstaged changes after reset:
M file1
[root@server1 demo]# git status -s #再执行git checkout -- readme.txt 恢复源文件
M file1
[root@server1 demo]# git checkout -- file1
[root@server1 demo]# git status -s #没有任何输出
[root@server1 demo]# cat file1 #再次查看已经复原
xjj
is
a
good
<3>第三种情况:file1文件修改后已经提交到git仓库,这种情况下的撤销修改
(1)
方法一:
[root@server1 demo]# echo girl+ >> file1
[root@server1 demo]# cat file1
xjj
is
a
good
girl+
[root@server1 demo]# git add file1
[root@server1 demo]# git commit -m "change 3 file1"
[master 22b71eb] change 3 file1
1 file changed, 1 insertion(+)

好了,现在我们启动时光穿梭机,准备把
file1回退到上一个版本,也就是change 2 file1的那个版本,怎么做呢?首先,Git必须知道当前版本是哪个版本,在Git中,用
HEAD表示当前版本,也就是最新的提交22b71e...(注意我的提交ID和你的肯定不一样),上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。现在,我们要把当前版本
change 3 file1回退到上一个版本change 2 file1,就可以使用git reset命令:
[root@server1 demo]# git reset --hard HEAD^
HEAD is now at 94d4710 change 2 file1
[root@server1 demo]# git log --pretty=oneline
94d4710c318fef1d80b1cc3d03bc40b0b35321e8 change 2 file1
13c9b6674d0dbd96af12d8f09ffeacf637e05fa5 change file1
d81d6af9e31a3281558586b8c8f1002cbadeae38 add file1
[root@server1 demo]# cat file1 #再次查看已经复原
xjj
is
a
good
(2)
方法二:也可以通过reflog查看,进行撤销修改
[root@server1 demo]# git reflog
94d4710 HEAD@{0}: reset: moving to HEAD^
22b71eb HEAD@{1}: commit: change 3 file1
94d4710 HEAD@{2}: commit: change 2 file1
13c9b66 HEAD@{3}: commit: change file1
d81d6af HEAD@{4}: commit (initial): add file1
#想要返回至哪个状态,就在后面执行 git reset --hard + ID号码
如:回退到add file1的状态
[root@server1 demo]# git reset --hard d81d6af
HEAD is now at d81d6af add file1
[root@server1 demo]# cat file1 #再次查看已经回退
xjj
(3)
好比你从21世纪坐时光穿梭机来到了19世纪,想再回去已经回不去了,肿么办?
办法其实还是有的,通过git reflog命令的结果找到那个change 3 file1的commit id是22b71eb...,于是就可以指定回到未来的某个版本:
[root@server1 demo]# git reset --hard 22b71eb
HEAD is now at 22b71eb change 3 file1
[root@server1 demo]# cat file1 #再次查看已经回退
xjj
is
a
good
girl+
版本号没必要写全,前几位就可以了,Git会自动去找。当然也不能只写前一两位,因为Git可能会找到多个版本号,就无法确定是哪一个了。
Git的版本回退速度非常快,因为Git在内部有个指向当前版本的
HEAD指针,当你回退版本的时候,Git仅仅是把HEAD从指向change 3 file1:
删除文件+删除文件并还原文件
一般情况下,你通常直接在文件管理器中把没用的文件删了,或者用rm命令删了:
[root@server1 demo]# rm -rf file1
这个时候,Git知道你删除了文件,因此,工作区和版本库就不一致了,git status命令会立刻告诉你哪些文件被删除了:
[root@server1 demo]# git status
# On branch master
# Changes not staged for commit:
# (use "git add/rm ..." to update what will be committed)
# (use "git checkout -- ..." to discard changes in working directory)
#
# deleted: file1
#
no changes added to commit (use "git add" and/or "git commit -a")
[root@server1 demo]# git status -s
D file1
现在你有两个选择,一种情况是删错了,因为版本库里还有呢,所以可以很轻松地把误删的文件恢复到最新版本:
[root@server1 demo]# git checkout file1
[root@server1 demo]# git status -s #没有任何输出
[root@server1 demo]# ls
file1
[root@server1 demo]# cat file1 #看到file1文件恢复成功
xjj
is
a
good
girl+
git checkout其实是用版本库里的版本替换工作区的版本,无论工作区是修改还是删除,都可以“一键还原”。
另外一种情况是确实要从版本库中删除该文件,那就用命令git rm删掉,并且git commit:
[root@server1 demo]# rm -rf file1
[root@server1 demo]# git status -s
D file1
[root@server1 demo]# git rm file1
rm 'file1'
[root@server1 demo]# git status -s
D file1
[root@server1 demo]# git commit -m "del file1"
[master feedf26] del file1
1 file changed, 5 deletions(-)
delete mode 100644 file1
[root@server1 demo]# git status -s #没有任何输出
现在,文件就从版本库中被删除了。
想要恢复很简单,需要i用上上面撤销修改的第三种情况中的(3)
[root@server1 demo]# git reflog
feedf26 HEAD@{0}: commit: del file1
22b71eb HEAD@{1}: reset: moving to 22b71eb
d81d6af HEAD@{2}: reset: moving to d81d6af
94d4710 HEAD@{3}: reset: moving to HEAD^
22b71eb HEAD@{4}: commit: change 3 file1
94d4710 HEAD@{5}: commit: change 2 file1
13c9b66 HEAD@{6}: commit: change file1
d81d6af HEAD@{7}: commit (initial): add file1
[root@server1 demo]# git reset --hard d81d6af
HEAD is now at d81d6af add file1
[root@server1 demo]# cat file1 #可以看到文件还原成功
xjj
小结
命令git rm用于删除一个文件。如果一个文件已经被提交到版本库,那么你永远不用担心误删,但是要小心,你只能恢复文件到最新版本,你会丢失最近一次提交后你修改的内容。