【Java核心技术卷】I/O详析
文章目录
- 概述
- Java io基本概念
- 关于流
- 流的分类
- Java io框架
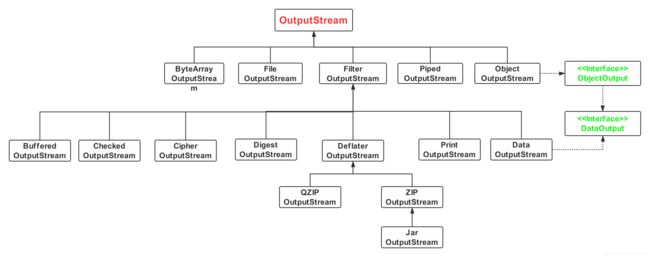
- 一、以字节为单位的输出流的框架图
- (1)框架图图示
- (2)OutputStream详解
- (3)OutputStream子类
- (4)引申:打印流
- 二、以字节为单位的输入流的框架图
- (1)框架图图示
- (2)InputStream详解
- (3)InputStream子类
- (4)引申:缓冲流(含字节输出流的内容)
- (5)引申:数据流(含字节输出流的内容)
- 三、以字符为单位的输入流和输出流的框架图
- (1)框架图图示
- (2)框架详解
- (3)引申:过滤器流
- Java io中的设计模式
- 适配器模式
- 装饰者模式
- 复盘
概述
java的IO系统的设计是为了实现 “文件、控制台、网络设备” 这些IO设置的通信,它建立在流之上,输入流读取数据,输出流写出数据,不同的流类,会读/写某个特定的数据源。
数据源(Data Source)顾名思义,数据的来源
在展开整个面之前有必要弄清楚三个概念: 比特、字节和字符
- Bit最小的二进制单位 ,是
计算机的操作部分,取值0或者1,也是计算机网络的物理层最小的传输单位。 - Byte是
计算机操作数据的最小单位由8位bit组成 取值(-128-127) - Char是
用户的可读写的最小单位,在Java里面由16位bit组成 取值(0-65535)
Java将IO进行了封装,所以我们看到的都是API,我们能做到的就是理解熟悉这些API,灵活运用即可。如果想要深入理解IO,建议从C语言入手,因为C语言是唯一一个能将IO讲明白的高级语言。
Java的IO系统是Java SE学习的重要一环,Java的文件操作 , Java网络编程基于此。它对你理解Tomcat的架构等也是必备的。
Java io基本概念
关于流
流是一串连续不断的数据的集合,你可以把它理解为水管里的水流,在水管的源头有水的供应,在另一端则是娟娟的水流,数据写入程序可以理解为供水,数据段会按先后顺序形成一个长的数据流。
对数据读取程序来说,不知道流在写入时的分段情况,每次可以读取其中的任意长度的数据,但只能先读取前面的数据后,再读取后面的数据。
流的分类
Java IO中包含字节流、字符流。按照流向还分为输入流,输出流
- 字节流:操作byte类型数据,主要操作类是OutputStream、InputStream的子类;不用缓冲区,直接对文件本身操作。
- 字符流:操作字符类型数据,主要操作类是Reader、Writer的子类;使用缓冲区缓冲字符,不关闭流就不会输出任何内容。
输入流和输出流的区分很简单:输入流是把数据写入存储介质的。输出流是从存储介质中把数据读取出来
Java io框架
一、以字节为单位的输出流的框架图
(1)框架图图示
图示基于Jdk1.8
(2)OutputStream详解
OutputStream是抽象类,它是所有字节输出流的类的超类,它与InputStream构成了IO类层次结构的基础。
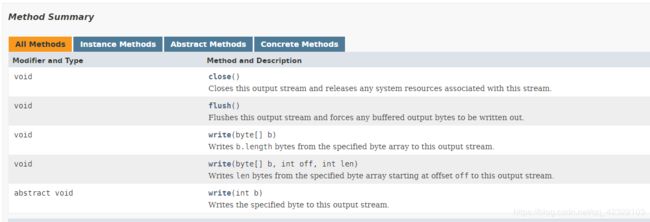
它展示了五种方法,子类针对这五个方法进行拓展, 不管是哪种介质,大都使用同样的这5种方法
?
值得注意的是 wirte(int b)
它虽然接收0~255的整数,但是实际上会写出一个无符号字节,因为Java是没有无符号字节整型数据的,所以这里用int来代替。
?
下面来看这两个方法,可用于多个字节的处理,相比上面一次处理一个字节效率要更高。
void wirte(byte[] b)
void write(byte[] b ,int off ,int len)
参数
- b:数据读入的数组
- off 第一个读入的字节 应该被放置的位置在b的偏移量
- len 读入字节的最大数量
这个还是比较好理解的,就不多说了。
?
当结束一个流的操作的时候 会调用close方法将其关闭,释放与这个流相关的所有资源,如文件句柄或端口。
文件句柄
在文件I/O中,要从一个文件读取数据,应用程序首先要调用操作系统函数并传送文件名,并选一个到该文件的路径来打开文件。该函数取回一个顺序号,即文件句柄(file handle),该文件句柄对于打开的文件是唯一的识别依据。要从文件中读取一块数据,应用程序需要调用函数ReadFile,并将文件句柄在内存中的地址和要拷贝的字节数传送给操作系统。当完成任务后,再通过调用系统函数来关闭该文件。
其实关于结束一个流,在Java6及之前有一个很经典的 完成清理的释放模式
OutputStream out = null;
try {
out = new FileOutputStream("/temp/data.txt");
}catch (IOException ex){
System.err.println(ex.getMessage());
}finally {
if(out != null){
try {
out.close();
}catch (IOException ex){
//忽略
}
}
}
这个不仅可以用于流,还可以用于socket,通道,JDBC的连接
在Java7之后出现一个语法糖 — 带资源的 try构造。写法类似于这种:
try(OutputStream out = new FileOutputStream("/temp/data.txt")){
//处理输出流
}catch (IOException ex){
System.err.println(ex.getMessage());
}
由于这个很重要,我们深究一下:
AutoCloseable接口对JDK7新添加的带资源的try语句提供了支持,这种try语句可以自动执行资源关闭过程。
只有实现了AutoCloseable接口的类的对象才可以由带资源的try语句进行管理。AutoCloseable接口只定义了close()方法:
Closeable接口也定义了close()方法。实现了Closeable接口的类的对象可以被关闭。
但是注意!!! 从JDK7开始,Closeable扩展了AutoCloseable。因此,在JDK7中,所有实现了Closeable接口的类也都实现了AutoCloseable接口。
关于带资源的try语句的3个关键点:
- 由带资源的try语句管理的资源必须是实现了AutoCloseable接口的类的对象。
- 在try代码中声明的资源被隐式声明为final。
- 通过使用分号分隔每个声明可以管理多个资源。
此外请记住,所声明资源的作用域被限制在带资源的try语句中。
我们看一下Java编译器为我们解析语法糖tryWithResource 做了哪些事情:
原本的代码
public class TryWith {
public static void main(String[] args) {
try (BufferedReader br = new BufferedReader(new FileReader("c:\\Test.jad"))) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
反编译之后
public class TryWith
{
public TryWith()
{
}
public static void main(String args[])
{
try
{
BufferedReader br = new BufferedReader(new FileReader("c:Test.jad"));
String line;
try
{
while((line = br.readLine()) != null)
System.out.println(line);
}
catch(Throwable throwable)
{
try
{
br.close();
}
catch(Throwable throwable1)
{
throwable.addSuppressed(throwable1);
}
throw throwable;
}
br.close();
}
catch(IOException e)
{
e.printStackTrace();
}
}
}
?
最后一个方法是flush()
意思是冲刷输出流,也就是将所有缓冲的数据发送到目的地。这个在 子类 缓冲流BufferedOutputStream 中体现最为明显
(3)OutputStream子类
关于子类的实现这里更多地知识点一下,如果一一详细介绍,这篇博文实在太长了。(所以把重要的放在下一篇写)
- ByteArrayOutputStream 是字节数组输出流。写入ByteArrayOutputStream的数据被写入一个 byte 数组。缓冲区会随着数据的不断写入而自动增长。可使用 toByteArray() 和 toString() 获取数据。
- PipedOutputStream 是管道输出流,它和PipedInputStream一起使用,能实现多线程间的管道通信。
- FilterOutputStream 是过滤输出流。它是DataOutputStream,BufferedOutputStream和PrintStream等的超类。
- DataOutputStream 是数据输出流。它是用来装饰其它输出流,它“允许应用程序以与机器无关方式向底层写入基本 Java 数据类型”。(简单来说就是以二进制格式写出所有的基本Java类型)
- BufferedOutputStream 是缓冲输出流。它的作用是为另一个输出流添加缓冲功能。
- PrintStream 是打印输出流。它是用来装饰其它输出流,能为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
- FileOutputStream 是文件输出流。它通常用于向文件进行写入操作。
- ObjectOutputStream 是对象输出流。它和ObjectInputStream一起,用来提供对“基本数据或对象”的持久存储。
(4)引申:打印流
平时我们在控制台打印输出,是调用 print 方法和 println 方法完成的,这两个方法都来自于java.io.PrintStream 类,该类能够方便地打印各种数据类型的值,是一种便捷的输出方式。
打印流PrintStream 为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
PrintStream特点:
- 只负责数据的输出,不负责数据的读取
- 与其他输出流不同,Printstream 永远不会抛出IOException
- 有特有的方法,print,println void print(任意类型的值)void printin(任意类型的值并换行)构造方法:
API信息
Print Stream(File file):输出的目的地是一个文件PrintStream(Outputstream out):输出的目的地是一个字节输出流PrintStream(string fileName):输出的目的地是一个文件路径
PrintStream extends OutputStream继承自父类的成员方法:
public void close():关闭此输出流并释放与此流相关联的任何系统资源。
public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。
public void write(byte[] b):将b.length字节从指定的字节数组写入此输出流。
public void write(byte[]b,int off,int len):从指定的字节数组写入len字节,从偏移量off开始输出到此输出流。
public abstract void write(int b):将指定的字节输出流。
注意:
如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表97->a
如果使用自己特有的方法print/println方法写数据,写的数据原样输出97->97
import java.io.FileNotFoundException;
import java.io.PrintStream;
public class Main{
public static void main(String[] args) throws FileNotFoundException {
//创建打印流PrintStream对象,构造方法中绑定要输出的目的地
PrintStream ps = new PrintStream("C:\\Users\\JunQiao Lv\\Desktop\\文件\\b.txt");
//如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表97->a
ps.write(97);
//如果使用自己的特有方法print/println方法写数据,写的数据原样输出97->97
ps.println(97);
ps.println(8.8);
ps.println('a');
ps.println("HelloZZU");
ps.println(true);
//释放资源
ps.close();
}
}
结果:
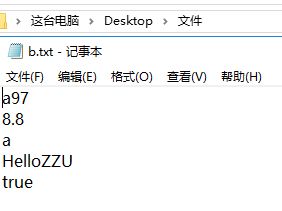
PrintStream可以改变输出语句的目的地(打印流的流向)输出语句,默认在控制台输出
使用System.setout方法改变输出语句的目的地改为参数中传递的打印流的目的地
static void setout(PrintStream out) 重新分配标准*输出流。
import java.io.FileNotFoundException;
import java.io.PrintStream;
public class Main{
public static void main(String[] args) throws FileNotFoundException {
System.out.println("我是在控制台输出的");
PrintStream ps = new PrintStream("C:\\Users\\JunQiao Lv\\Desktop\\文件\\b.txt");
System.setOut(ps); //把输出语句的自的地改变为打印流的目的地
System.out.println("我在打印流的目的中输出");
ps.close();
}
}
结果:
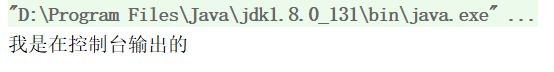

PringtStream是存在一些问题的:
- 它的输出与平台有关, 对于编写必须遵循明确协议的网络客户端和服务器来说是个灾难
- 它假定所在平台的默认编码方式,这个可能不是服务器或客户端所期望的
- 它吞掉了所有的异常
二、以字节为单位的输入流的框架图
(1)框架图图示
图示版本Jdk1.8
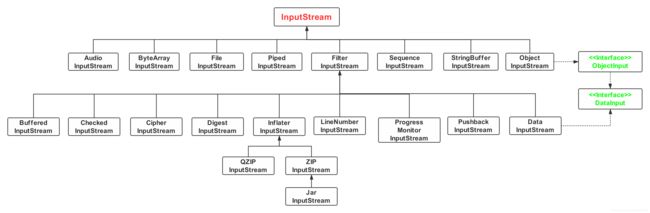
(2)InputStream详解
它提供了写入数据的基本方法,圈起来的是需要重点关注的:
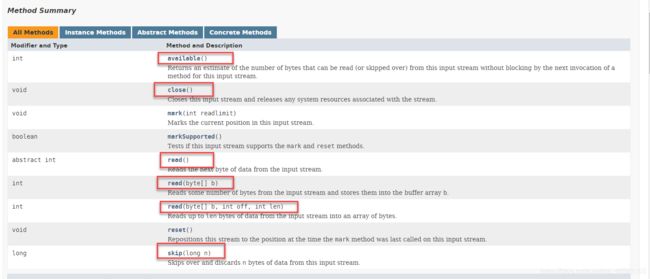
?
没有参数的read()方法: 从输入流的数据源中读入一个字节数据转为0~255的int返回, 流的结束通过返回-1来表示
这个应与OutputStream的write(int b)方法放在一起理解
.read()方法会等待并阻塞其后任何代码的执行,直到有1个字节可供读取.输入输出可能很慢,所以如果程序还要做其他事情,尽量把I/O放在单独的线程中.
read读取一个无符号字节,注意这里要求进行类型转换.可以通过下面的方法 将手里的有符号字节转换成无符号字节
int i = b>=0?b:256+b;
?
另外还有两个read() 返回-1的时候 都表示流的结束
不结束的时候 返回值为实际读取到的字节数
?
如果不想等待所需的全部字节都立即可用,可以使用available()方法来确定不阻塞的情况下有多少字节可以读取.它会返回可以读取的最少字节数(事实上还能够读取更多的字节),但至少读取available()建议的字节数
?
在少数的情况下,可能会希望跳过数据不进行读取.skip()方法会完成这项任务.
与读取文件相比,在网络连接中它的用处不大.网络连接是顺序的,一般会很慢.所以与跳过这些数据(不读取)相比,读取并不会耗费太长的时间.
文件是随机访问的,所以要跳过数据,可以简单地实现为重新指定文件指针的位置,而不需要处理要跳过的各字节.
?
InputStream类还有三个不太常用的方法,就是没圈起来的
mark()方法和reset()方法常被合起来称之为标记与重置
为了重新读取数据,需要用mark()方法标记流的当前位置.在以后的某个时刻,可以用reset()方法把流重置到之前标记的位置.
接下来的读取操作会烦会从标记位置开始的数据.
不过,不能随心所欲地向前重置任意远的位置.从标记处读取和重置的字节数由mark()的readAheadlimit参数确定.重置太远会有IO异常.
一个很重要的问题是,一个流在任何时刻都只能有一个标记.标记的第二个位置会清除第一个标记.
?
markSupported()方法是否返回true.如果返回true,这个流就支持标记和重置
Java.io仅有两个始终支持标记的输入流类是 BufferedInputStream和ByteArrayInputStream 而其他输入流(如TelnetInputStream)需要串联到缓冲的输入流才支持标记.
TelnetInputStream在文档中没有展示,被隐藏在了sun包下,这个类我们是直接接触不到的
关于串联其实是设计模式的思想,后面会单独详解
(3)InputStream子类
- ByteArrayInputStream 是字节数组输入流。它包含一个内部缓冲区,该缓冲区包含从流中读取的字节;通俗点说,它的内部缓冲区就是一个字节数组,而ByteArrayInputStream本质就是通过字节数组来实现的。
- PipedInputStream 是管道输入流,它和PipedOutputStream一起使用,能实现多线程间的管道通信。
- FilterInputStream 是过滤输入流。它是DataInputStream和BufferedInputStream的超类。
- DataInputStream 是数据输入流。它是用来装饰其它输入流,它“允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型”。
- BufferedInputStream 是缓冲输入流。它的作用是为另一个输入流添加缓冲功能。
- FileInputStream 是文件输入流。它通常用于对文件进行读取操作。
- ObjectInputStream 是对象输入流。它和ObjectOutputStream一起,用来提供对“基本数据或对象”的持久存储。
(4)引申:缓冲流(含字节输出流的内容)
BufferedOutputStream
BufferedOutputStream类将写入的数据存储在缓冲区中(一个名字是buf的保护字节数组字段),直到缓冲区满或者刷新输出流。然后它将数据一次性写入底层输出流。

这里需要好好说一下flush方法了
关于缓冲流,如果输出流有一个1024字节的缓冲区,未满之前,它会一直等待数据的到达,如果是网络发送数据的话,因为缓冲区的等待,会产生死锁,flush()方法可以强迫缓冲的流发送数据。
有一个细节就是当close缓冲流的时候会自动调用flush方法
具体方法如下:
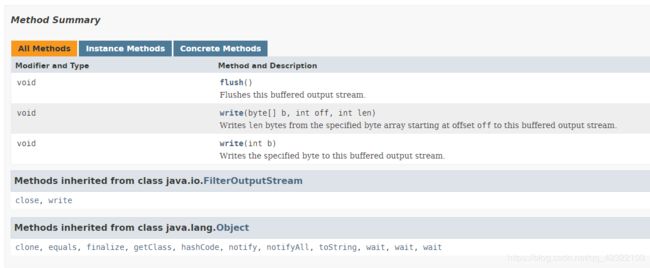
BufferedInputStream
值得一提的是它的构造方法:

第一个参数是底层流,可以从中读取未缓冲的数据。或者向其写入数据。
如果给出第二个参数,它会指定缓冲区的字节数,否则输入流的缓冲区大小设置为2048字节.输出流的缓冲区大小设置为512字节.缓冲区的理想大小取决于所缓冲的流是何种类型.
其他方法与超类类似:
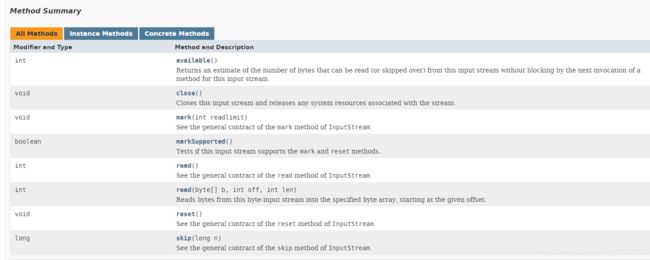
(5)引申:数据流(含字节输出流的内容)
DataInputSteam和DataOutputSteam类提供了一些方法,可以用二进制格式读/写Java的基本数据类型和字符串.
DataOutputSteam 写入的每一种数据 DatainputSteam都能够读取.
所有的数据都以big-endian格式写入.
小端格式和大端格式(Little-Endian&Big-Endian)属于计算机组成原理的内容
不同的CPU有不同的字节序类型,这些字节序是指整数在内存中保存的顺序。
最常见的有两种:
1. Little-endian:将低序字节存储在起始地址(低位编址)
2. Big-endian:将高序字节存储在起始地址(高位编址)
三、以字符为单位的输入流和输出流的框架图
(1)框架图图示
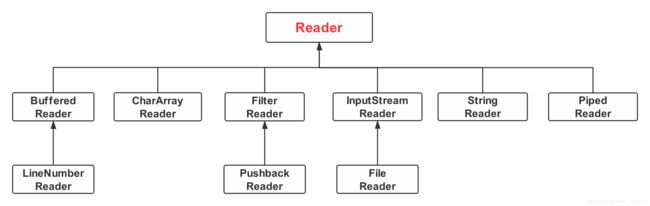
-
CharArrayReader 是字符数组输入流。它用于读取字符数组r。操作的数据是以字符为单位!
-
PipedReader 是字符类型的管道输入流。它和PipedWriter一起是可以通过管道进行线程间的通讯。在使用管道通信时,必须将PipedWriter和PipedReader配套使用。
-
FilterReader 是字符类型的过滤输入流。
-
BufferedReader 是字符缓冲输入流。它的作用是为另一个输入流添加缓冲功能。
-
InputStreamReader 是字节转字符的输入流。它是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。
-
FileReader 是字符类型的文件输入流。它通常用于对文件进行读取操作。
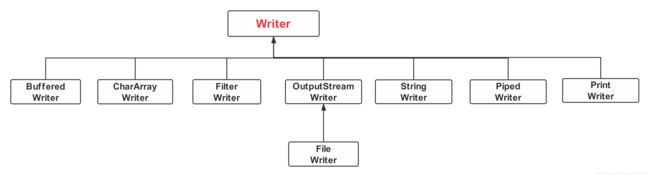
-
CharArrayWriter 是字符数组输出流。它用于读取字符数组。操作的数据是以字符为单位!
-
PipedWriter 是字符类型的管道输出流。它和PipedReader一起是可以通过管道进行线程间的通讯。在使用管道通信时,必须将PipedWriter和PipedWriter配套使用。
-
FilterWriter 是字符类型的过滤输出流。
-
BufferedWriter 是字符缓冲输出流。它的作用是为另一个输出流添加缓冲功能。
-
OutputStreamWriter 是字节转字符的输出流。它是字节流通向字符流的桥梁:它使用指定的 charset 将字节转换为字符并写入。
-
FileWriter 是字符类型的文件输出流。它通常用于对文件进行读取操作。
-
PrintWriter 是字符类型的打印输出流。它是用来装饰其它输出流,能为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
(2)框架详解
对于Unicode文本,可以使用抽象类Reader和Writer的子类。
小知识点: Java内置字符集是Unicode的UTF-16编码
很多人都将Reader及其子类称之为 阅读器, 将Writer及其子类称之为书写器,个人认为这是一个不错的做法, 后面会探讨Java io的设计模式,两个简称会用到。
Reader类的基本方法
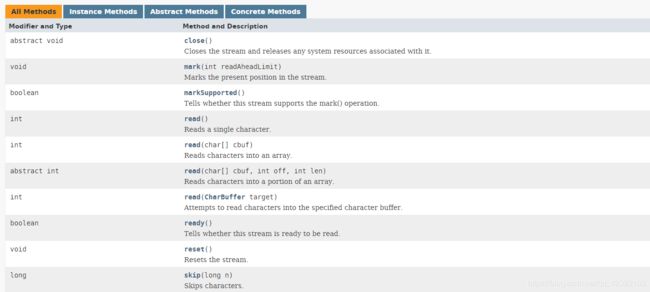
read()方法将一个Unicode字符(实际上是UTF-16码点)作为一个 int返回,可以是0~65535之间的一个值,等遇到流结束的时候返回-1
read(char[] cbuf)
read(char[] cbuf,int off,int len)
第一个方法尝试使用字符填充数组cbuf,并返回实际读取到的字节数,等遇到流结束的时候返回-1
第二个方法尝试将len个字符读入cbuf的数组中(从off开始 长度为len)它会返回实际读取到的字节数,如果遇到流结束的时候返回-1
skip(Long n)等其他方法与InputStream基本上类似。
Writer类的基本方法
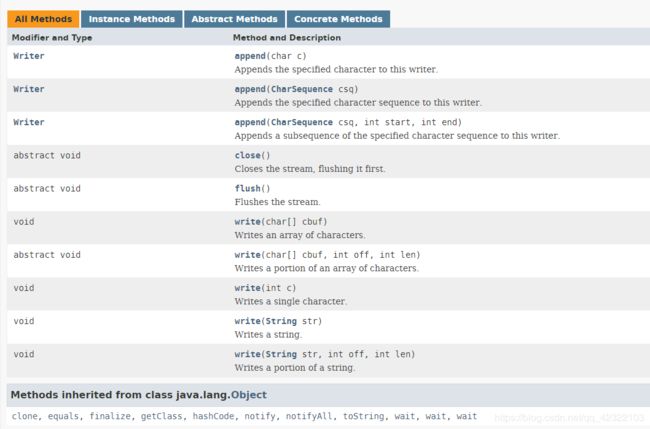
有了前面的基础,这些api也很好理解的,你会发现Writer中有一个append方法
它和writer方法最大区别是,append方法中的参数可以为null,而writer中的参数不能为null
Reader和Writer最重要的具体子类是InputStreamReader和OutputStreamWirter, 以这个为例我们看一下它的实现过程,其他类类似
关于InputStreamReader:
它包含一个底层输入流,可以从数据源中读取原始字节。它根据指定的编码方式,将这些字节转换成Unicode字符。
关于OutputStreamWriter
它从运行的程序中接收Unicode字符,然后使用指定的编码方式将这些字符转换成字节,然后字节写入底层输入流中。
有一道Java io的面试题是这样问的:字节流和字符流之间如何相互转换?
其实就是我们说的这两个具体子类,回答可以是下面的说法:
整个IO包实际上分为字节流和字符流,但是除了这两个流之外,还存在一组字节流-字符流的转换类。
OutputStreamWriter是Writer的子类,将输出的字符流变为字节流,即将一个字符流的输出对象变为字节流输出对象。
InputStreamReader是Reader的子类,将输入的字节流变为字符流,即将一个字节流的输入对象变为字符流的输入对象。
(3)引申:过滤器流
这部分内容是我学习《Java网络编程》第四版摘录下来的
Java提供了很多的过滤器类,可以附加到原始流中,在原始字节和各种格式之间进行转换.。
过滤器有两种版本:过滤器流及阅读器和书写器。
过滤器流仍然主要将原始数据作为字节处理,通过压缩数据或解释为二进制数字。阅读器和书写器处理各种编码文本的特殊情况,如UTF-8和ISO 8859-1。它以链的形式进行组织。链中的每个环节都接收前一个过滤器或流的数据,并把数据传递给链中的下一个环节。在这个示例中,从本地网络接口接收到一个加密的文本文件,在这里本地代码将这个文件表示TelnetInputStream。通过一个BufferedInputtStream缓冲这个数据来加速整个过程。由一个CipherInputStream将数据解密。再由一GZIPInputStream解压解密后的数据。一个InputStream将解压后的数据转换为Unicode文本。最后,文本由应用程序进行处理。

这其中体现了一些设计模式
Java io中的设计模式
适配器模式
关于适配器模式,这里回顾一下:
定义: 将一个类的接口转换成客户期望的另一个接口
说的通俗点就是 笔记本电脑的电源就是个适配器吧,不管它外部电压是多少,只要经过了适配器就能转变成我电脑需要的伏数
作用: 使原本接口不兼容的类可以一起工作
类型: 结构型
演示:
(1)类适配器模式
定义一个目标接口
public interface Target {
void request();
}
实现接口的类
public class ConcreteTarget implements Target{
@Override
public void request() {
System.out.println("ConcreteTarget目标方法");
}
}
被适配者
public class Adaptee {
public void adapteeRequest(){
System.out.println("被适配者的方法");
}
}
关键 : 继承被适配者且继承目标接口
//继承被适配者
public class Adapter extends Adaptee implements Target{
@Override
public void request() {
super.adapteeRequest();
}
}
类图:
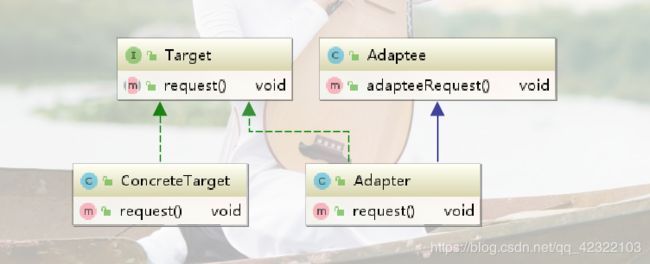
测试:
public class Test {
public static void main(String[] args) {
Target target = new ConcreteTarget();
target.request();
Target adapterTarget = new Adapter();
adapterTarget.request();
}
}
结果:

(2)下面来看一下对象适配器模式
和类适配器模式相比 只有一处发生了变化
Adapter 类 之前还继承了Adaptee,现在没有继承
//继承被适配者
public class Adapter implements Target{
private Adaptee adaptee = new Adaptee();
@Override
public void request() {
adaptee.adapteeRequest();
}
}
类图:
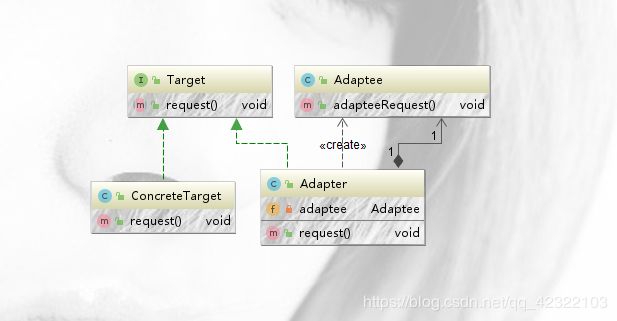
前面已经说了字节流和字符流之间的相互转换靠的是OutputStreamWriter和InputStreamReader,其实它们充当了适配器,如果不相信可以翻源码。
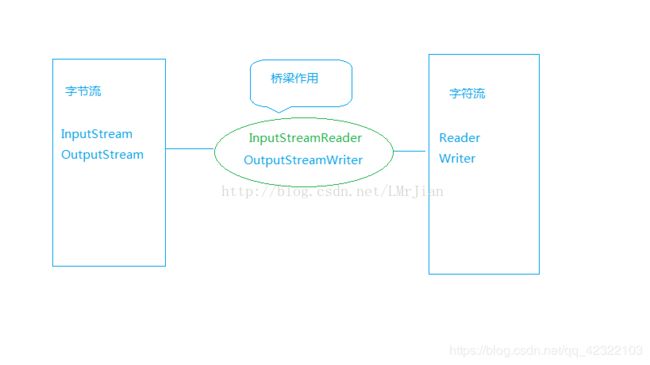
这里举个转换的例子:
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(new File("test.txt"))));
装饰者模式
同样回顾一下:
定义:在不改变原有对象的基础之上,将功能附加到对象上
作用: 提供了比继承更有弹性的替代方案(扩展原有对象功能)
类型: 结构型
使用场景:
- 扩展一个类的功能或给一个类添加附加职责
- 动态的给一个对象添加功能,这些功能可以再动态的撤销
演示
不满足装饰者模式的情况
以买煎饼为例
public class Battercake {
protected String getDesc(){
return "煎饼";
}
protected int cost(){
return 5;
}
}
煎饼 加一个鸡蛋
public class BattercakeWithEgg extends Battercake{
@Override
protected String getDesc() {
return super.getDesc()+"加一个鸡蛋";
}
@Override
protected int cost() {
return super.cost()+ 1;
}
}
煎饼加一个鸡蛋 加一个烤肠
public class BattercakeWithEggSausage extends BattercakeWithEgg{
@Override
protected String getDesc() {
return super.getDesc()+"加一根香肠";
}
@Override
public int cost() {
return super.cost()+2;
}
}
测试:
public class Test {
public static void main(String[] args) {
Battercake battercake = new Battercake();
System.out.println(battercake.getDesc()+ " 销售价格为:"+battercake.cost());
BattercakeWithEgg battercakeWithEgg = new BattercakeWithEgg();
System.out.println(battercakeWithEgg.getDesc()+ " 销售价格为:"+battercakeWithEgg.cost());
BattercakeWithEggSausage battercakeWithEggSausage = new BattercakeWithEggSausage();
System.out.println(battercakeWithEgg.getDesc()+ " 销售价格为:"+battercakeWithEgg.cost());
}
}
我们看一下它的UML类图 很容易发现 单纯的继承关系
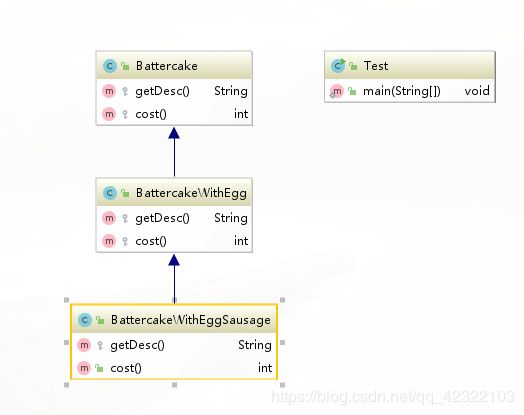
如果一个煎饼加两个鸡蛋 或者别的其他的呢 容易引起"类爆炸"
所以为了解决这个问题 引入装饰着模式,下面让我们看一下满足装饰者模式的写法
这里被装饰的是煎饼 装饰者是鸡蛋和香肠
创建煎饼的抽象类
public abstract class ABattercake {
protected abstract String getDesc();
protected abstract int cost();
}
创建煎饼
public class Battercake extends ABattercake{
protected String getDesc(){
return "煎饼";
}
protected int cost(){
return 5;
}
}
创建装饰着的抽象类
public class AbstractDecorator extends ABattercake{
private ABattercake aBattercake;
public AbstractDecorator(ABattercake aBattercake) { //注入煎饼
this.aBattercake = aBattercake;
}
@Override
protected String getDesc() {
return this.getDesc();
}
@Override
protected int cost() {
return this.cost();
}
}
鸡蛋的装饰者
public class EggDecorator extends AbstractDecorator {
public EggDecorator(ABattercake aBattercake) {
super(aBattercake);
}
@Override
protected String getDesc() {
return super.getDesc()+"加一个鸡蛋";
}
@Override
protected int cost() {
return super.cost()+1;
}
}
香肠的装饰者
public class SausageDecorator extends AbstractDecorator{
public SausageDecorator(ABattercake aBattercake) {
super(aBattercake);
}
@Override
protected String getDesc() {
return super.getDesc()+"加一根香肠";
}
@Override
protected int cost() {
return super.cost()+1;
}
}
类图:
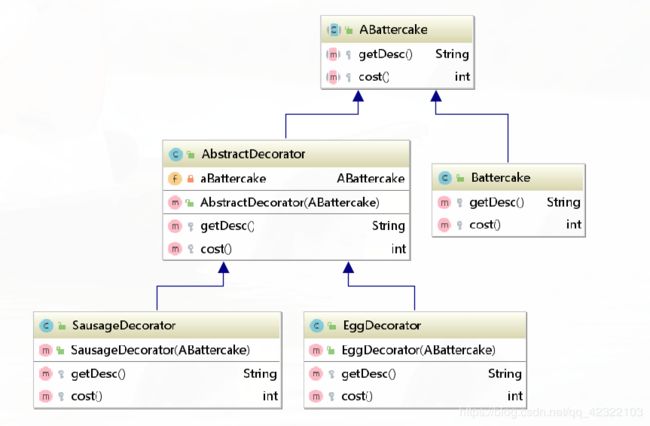
测试:
public class Test {
public static void main(String[] args) {
ABattercake aBattercake;
aBattercake = new Battercake();
aBattercake = new EggDecorator(aBattercake);
aBattercake = new EggDecorator(aBattercake);
aBattercake = new SausageDecorator(aBattercake);
System.out.println(aBattercake.getDesc() + " 销售价格为:" +aBattercake.cost());
}
}
结果:
![]()
类图:
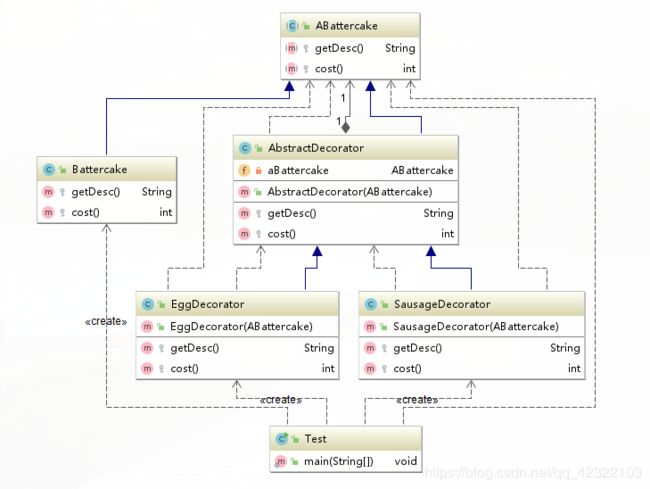
嵌套的风格有没有让你回忆出点什么?
这个时候我们就需要关注过滤器流了 FilterInputStream和 FilterOutputStream,这里以FilterInputStream为例:

举个例子
DataInputStream dataInputStream = new DataInputStream(new FileInputStream(new File("text.txt")));
其中DataInputStream给FileInputStream起到包装作用。
Java的IO流装饰模式很明显体现在这两点:
1、有原数据、可以被包装的。
2、包装类,能包装其他事物的,就是在原事物上添加点东西。
复盘
文章内容是有点多的,其实重要的是一定要理解这几个概念:
- Java的IO建立在流之上,它的体系建立在InputStream和OutputStream抽象类的基础上,这两个抽象类的基本方法被子类拓展实现了针对某一数据源的处理,因此一定要对它们的基本方法有着清晰的认识。尤其注意它们用于处理字节。
- 在InputStream和OutputStream基础上,又根据实现的具体子类的功能划分出了缓冲流、数据流等。
- 在它们的子类中还有过滤器流FilterInputStream和 FilterOutputStream,它们属于装饰者模式中的装饰者,拓展了被装饰者的功能。
- Writer和Reader被称为书写器和阅读器,它的具体子类InputStreamReader和OutputStreamWriter实现了字节到字符的过渡,运用了适配器模式的设计模式。
Java IO涉及的东西还并未结束,毕竟它是Java的一些高级技术的基石,而且也是一些大厂面试必不可少的东西,打得越牢固越好。下面要么再写一篇,要么在该篇继续补充,欢迎各位拍砖~