酒店评论数据分析和挖掘-展现数据分析全流程(一)报告展示篇

本系列文章应该会出四篇博客展现数据分析的整个流程
- 数据报告成品展示(本文)
- 描述性数据分析
- 关键字提取分析
- 评论情感分类建模
- LDA主题模型分析
下面是本文的写作框架:

1. 分析背景
1.1 分析原理—为什么选择分析酒店网络评论
随着互联网的发展, 我们的生活也愈加便捷, 网上购物及预订酒店和景点门票已是多少数人的选择。移动互联网时代,酒店业的市场更加风云变幻,其中最为显著的问题就是酒店该如何正确理解消费者的期望,据此评估自己服务质量的表现,并针对性的加以改善呢?
1.2 分析目的
在本项目中的分析目的主要有4个:
- 对酒店数据进行描述性分析,主要针对出差类型、酒店房型及评分等方面;
- 通过文本分类对酒店评论进行情感分类标注,便于进行下一步分析;
- 依据情感分类标注对数据级,对正负样本分别进行LDA主题分析探索评论数据;
- 将杂芜无序的结构化数据和非结构化数据进行可视化,展现数据之美
1.3 分析方法— 分析工具和分析类型
python3.7.4 (编程语言)
numpy (数组转换)
pandas (数据转换)
Gensim (词向量、主题模型)
Scikit-Learn(分类)
Jieba(分词和关键词提取)
matplotlib (可视化)
Tableau (可视化)
使用上述数据分析工具, 我将进行两类数据分析: 第一类是比较传统的、针对数值型数据的描述下统计分析,如评论量、评论分数等在时间维度上的分布;另一类将进行深层次的数据挖掘, 包括 关键字提取、情感分类、评论内容LDA主题模型提取
2. 数据采集和文本预处理
2.1 数据采集
使用 Python 爬取网络订购酒店网站的网络评价,数据采集的时间区间为2016.12~2019.12,共计35,867条,采集的字段为评论日期、酒店评分、评论内容、出差类型及酒店房型, 然后经过人工提取4个特征,主要是时间特征(时点和周几)和评论长度特征(标题字数和文章字数),数据如下图所示:
2.2 文本预处理
数据分析/挖掘领域有一条金科玉律:“Garbage in, Garbage out”,**做好数据预处理,对于取得理想的分析结果来说是至关重要的。**本文的数据规整主要是对文本数据进行清洗,处理的条目如下:
(1)分词
要进行文本挖掘,分词是最为关键的一步,它直接影响后续的分析结果。本次使用jieba来对文本进行分词处理,它有3类分词模式,即全模式、精确模式、搜索引擎模式:
- 精确模式:试图将句子最精确地切开,适合文本分析;
- 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
现以“做好数据预处理对于取得理想的分析结果来说是至关重要的”为例,3种分词模式的结果如下:
【全模式】: 做好/数据/预处理/处理/对于/取得/理想/的/分析/结果/来说/是/至关/至关重要/重要/的
【精确模式】: 做好/数据/预处理/对于/取得/理想/的/分析/结果/来说/是/至关重要/的
【搜索引擎模式】: 做好/数据/处理/预处理/对于/取得/理想/的/分析/结果/来说/是/至关/重要/至关重要/的
为了避免歧义和切出符合预期效果的词汇,本次采取的是精确(分词)模式。
(2) 去停用词
这里的停用词主要包括以下三类:
-
标点符号:’!’, ‘"’, ‘#’, ‘$’, ‘%’, ‘&’, “’”, ‘(’, ‘)’, ‘*’, ‘+’,
-
特殊符号:’[①①]’, ‘[①②]’, ❤❥웃유♋☮✌
-
无意义的虚词:‘他’, ‘他人’, ‘他们’, ‘以’, ‘以上’, ‘以下’, ‘以为’
3. 描述性分析
本环节主要对数值型类型的数据进行探索性数据分析,了解数据分布,从数据中获得有用的信息,它属于较为常规的数据分析,能揭示出一些问题,做到知其然。
3.1 评论数量、评分变化走势及出游类型
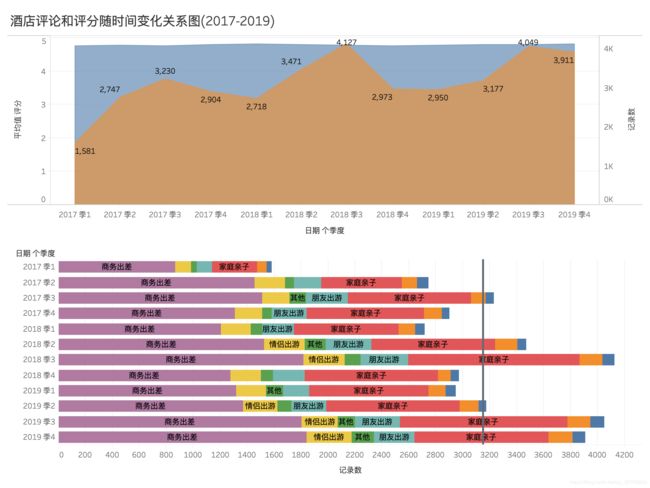
从下图可以看出从(2017.01-2019.12)平均评分起伏波动不大,在均值 4.7 上下波动,进入2019年酒店评论数有上升趋势,每年的第3季度为酒店高峰期。
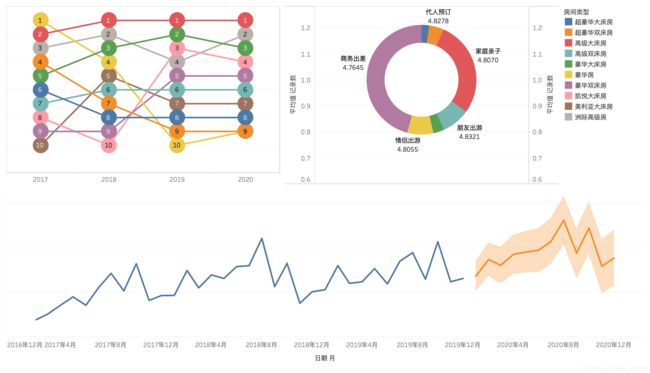
下面是一张复合图,左上角的图主要描述的是房型在每年的排名凹凸图,我们可以发现高级大床房一直都是比较受欢迎的房型,从环形图我们可以看出大部分游客都是商务出差和亲子旅游,从平均评分来看商务出差的平均评分是最低的,这样的结果让人深思,应该从哪些角度去改善呢?最下面的折线图是以月为单位评论数据的趋势,橙色为预测评论数量结果。
4. 文本挖掘
数据挖掘是从有结构的数据库中鉴别出有效的、新颖的、可能有用的并最终可理解的模式;而文本挖掘(在文本数据库也称为文本数据挖掘或者知识发现)是从大量非结构的数据中提炼出模式,也就是有用的信息或知识的半自动化过程。
4.1 关键字提取
衡量指标:一个词在文章中出现的次数越多,则它就越重要。因而,本次采用的是TF-IDF(termfrequency–inverse document frequency)的关键词提取方法:
它用以评估一字/词对于一个文件集或一个语料库中的其中一份文件的重要程度,字/词的重要性会随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
由此可见,在提取某段文本的关键信息时,关键词提取较词频统计更为可取,能提取出对某段文本具有重要意义的关键词。
下面是本次利用jieba在经预处理后的、近32万的评论词料中抽取出的TOP50关键词。

从宏观角度来看,从上面可以明显的识别出4类关键词:
- 酒店服务:服务员、热情、服务态度、态度、前台、接待
- 酒店周边:地理位置、机场、公园、停车场、购物、便利、古镇
- 酒店设施:房间、大堂、客房、装修、游泳池、设施、餐厅
- 其他关键字:早餐、安静、孩子、便利、整洁、吃饭、行李
由上可得:客户在考量一家酒店上多方面的,酒店的服务,房间是否干净卫生,网络订票是否方便快捷,设施是否完善。在收集数据中我也了解了一些信息,比如:有些客户带着小孩,酒店是否有婴儿床,是否能给小孩一个舒适的休息环境、有些客户早晨起的比较晚,卡在早上餐厅快关闭的时候去吃饭,结果餐厅提前关闭,所以很懊恼,从微观角度来看,居于首要位置的就是“服务”
下图上按照一个服务员的图片为背景生成的一个酒店关键字词云图:

4.2 情感分类
基于网络开源的酒店评论语料库,对正负面情绪的评论各进行关键字提取,然后使用 Gensim 做出词向量模型,然后使用 SVM(支持向量机)进行训练,最后使用模型将收集的酒店评论进行情感分类,进行情感分类的目的是为了使用LDA主题模型分析的时候能够精准提取到酒店的优缺点的主题,下图是情感分类后的数据展示:
- 正向情感分类数据:
- 负面情感分类数据:
4.3 LDA主题模型分析
在前面的一个环境里我们针对关键词的分类较为粗略,且人为划分,难免有失偏颇,达不到全面的效果。因此,我们使用情感分类后的数据进行LDA主题模型来发现该评论语料中的关于酒店优缺点。
- 首先我们将正面情绪的评论进行LDA分析
0.072*"酒店" + 0.062*"服务" + 0.043*"不错" + 0.038*"环境" + 0.031*"房间" + 0.031*"设施" + 0.025*"干净" + 0.020*"交通" + 0.019*"下次" + 0.019*"入住"
0.033*"酒店" + 0.031*"房间" + 0.027*"床" + 0.020*"舒服" + 0.018*"孩子" + 0.017*"住" + 0.015*"早餐" + 0.014*"不错" + 0.013*"赞" + 0.013*"适合"
0.064*"分钟" + 0.034*"还行" + 0.029*"地铁" + 0.026*"##" + 0.025*"铁站" + 0.017*"万科" + 0.016*"高铁" + 0.014*"距离" + 0.013*"绝佳" + 0.013*"十分钟"
0.033*"贵阳" + 0.029*"市区" + 0.029*"中心" + 0.021*"近" + 0.018*"酒店" + 0.018*"周边" + 0.017*"贵阳市" + 0.017*"市中心" + 0.017*"离市" + 0.015*"距离"
0.058*"酒店" + 0.044*"位置" + 0.026*"购物" + 0.022*"中心" + 0.021*"地理" + 0.021*"地理位置" + 0.018*"楼" + 0.018*"不错" + 0.017*"房间" + 0.015*"周边"
0.063*"服务" + 0.040*"前台" + 0.037*"酒店" + 0.027*"热情" + 0.025*"入住" + 0.021*"房间" + 0.015*"特别" + 0.013*"感谢" + 0.013*"升级" + 0.013*"人员"
0.036*"房间" + 0.023*"性价比" + 0.017*"金源" + 0.016*"高速" + 0.014*"世纪" + 0.013*"比高" + 0.013*"价比高" + 0.011*"干净" + 0.010*"宾客" + 0.008*"高"
0.150*"方便" + 0.141*"时间" + 0.024*"火车" + 0.020*"火车站" + 0.019*"车站" + 0.013*"柔软" + 0.013*"生日" + 0.012*"效率" + 0.011*"蛋糕" + 0.007*"顶顶"
0.064*"不错" + 0.063*"酒店" + 0.021*"早餐" + 0.016*"五星" + 0.014*"房间" + 0.014*"高" + 0.013*"服务" + 0.013*"价格" + 0.013*"性价比" + 0.011*"星级"
0.106*"停车" + 0.066*"泳池" + 0.054*"游泳" + 0.049*"车场" + 0.048*"停车场" + 0.040*"游泳池" + 0.033*"健身" + 0.029*"早餐" + 0.029*"健身房" + 0.017*"免费"
因为LDA主题模型算法是一个 “从概率的角度看文学” 的算法,每次运行结果都不相同,通过几次运行我们收集了比较有参考性质的四个主题:
| 服务 | 房间 | 地理位置 | 硬件设施 |
|---|---|---|---|
| 办理 | 舒适 | 市中心 | 游泳池 |
| 热情 | 孩子 | 地铁 | 健身房 |
| 工作人员 | 柔软 | 高铁 | 酒廊 |
| 帮忙 | 套房 | 购物 | 小吃 |
| 行李 | 干净 | 距离 | 餐厅 |
| 入住 | 床 | 方便 | 开心 |
| 前台 | 早餐 | 高速 | 停车场 |
- 服务:主题中的高频特征词有办理、工作人员、热情、行李等说明酒店办理入住的前台很热情,而且有些酒店的工作人员还会帮客户主动拿行李,会令顾客感到很满意。
- 房间:主题中的高频特征词有床、舒适、孩子、干净等,说明酒店房间很干净床比较柔软并且带孩子旅游的顾客还有婴儿床并且有早餐,会令顾客给予好评。
- 地理位置:主题中的高频特征词有市中心、地铁、购物、方便说明酒店的地理位置好,方便购物也是不可缺德的优势。
- 硬件设施:主题中有游泳池、健身房、酒廊、餐厅、停车场、开心等,酒店的硬件设施好,也会令顾客心情好
综合以上主题,我们可以分析到酒店的服务质量、房间质量、地理位置、硬件设施都是客户所关心的地方,因为我们分析的是正向评论所以如果从用户的角度出发,前台服务态度好、房间干净舒适、地理位置方便、硬件设施完善如果做到以下几点,就是人们心目中的五星级酒店。
- 下面对负面情绪的评论进行LDA主题分析:
0.009*"感觉" + 0.009*"泉水" + 0.008*"矿泉水" + 0.008*"矿泉" + 0.007*"厕所" + 0.006*"有感" + 0.005*"住" + 0.004*"房间" + 0.004*"打扫" + 0.004*"毛巾"
0.069*"酒店" + 0.043*"服务" + 0.025*"房间" + 0.016*"五星" + 0.016*"设施" + 0.014*"早餐" + 0.012*"前台" + 0.011*"星级" + 0.011*"住" + 0.011*"贵阳"
0.013*"酒店" + 0.012*"房" + 0.011*"前台" + 0.011*"間" + 0.011*"務" + 0.010*"服" + 0.008*"還" + 0.007*"這" + 0.006*"##" + 0.005*"送"
0.015*"早餐" + 0.012*"还好" + 0.006*"楼梯" + 0.006*"早" + 0.006*"黄果" + 0.006*"黄果树" + 0.006*"果树" + 0.005*"吃" + 0.005*"瀑布" + 0.004*"工会"
0.146*"好好" + 0.026*"55" + 0.018*"楼" + 0.016*"古镇" + 0.007*"电梯" + 0.006*"青岩" + 0.004*"活动" + 0.004*"大堂" + 0.004*"市场" + 0.004*"空气"
0.030*"酒店" + 0.016*"房" + 0.015*"床" + 0.014*"携程" + 0.008*"订" + 0.008*"租车" + 0.008*"出租" + 0.008*"元" + 0.007*"出租车" + 0.005*"入住"
0.012*"城区" + 0.009*"老城" + 0.008*"老城区" + 0.005*"订" + 0.005*"预定" + 0.004*"敲" + 0.003*"大学" + 0.003*"水量" + 0.003*"ok" + 0.003*"大学城"
0.030*"酒店" + 0.024*"服务" + 0.021*"前台" + 0.021*"说" + 0.016*"入住" + 0.016*"房间" + 0.010*"住" + 0.009*"电话" + 0.008*"服务员" + 0.008*"退房"
0.044*"房间" + 0.023*"空调" + 0.018*"停车" + 0.017*"酒店" + 0.016*"声音" + 0.012*"卫生" + 0.011*"太" + 0.010*"车场" + 0.010*"停车场" + 0.010*"晚上"
处理方式和正向情感一样,我们运行几次提收集其中有参考价值的主题高频特征词,通过几次运行我们归纳为下面几类主题:
| 主题1 | 主题2 | 主题3 | 主题4 | 主题5 | 主题6 |
|---|---|---|---|---|---|
| 空调 | 有待 | 携程 | 淋浴 | 专业 | 车位 |
| 坏 | 马桶 | 押金 | 洗澡 | 工作人员 | 停车场 |
| 晚上 | 脏 | 预定 | 坏 | 态度 | 地下 |
| 吵 | 卫生 | 发票 | 漏水 | 费用 | 导航 |
| 温度 | 早餐 | 损失 | 不好 | 服务员 | 房间 |
| 隔音 | 价格 | 前台 | 洗手间 | 一般 | 车位 |
- 主题1:主要在吐槽房间里的空调,和房间里的隔音,在收集数据中发现:有些客户在房间发现空调或者其他地方有问题的时候报修,修理不及时或者没人搭理导致客户体验不好,给予差评。
- 主题2:主要体现出酒店酒店卫生差,早餐价格昂贵的问题。
- 主题3:因我们本次的数据都是通过携程订酒店,所以会牵扯到发票押金的问题,在收集过程中发现:有些酒店将费用从押金直接扣除,可是在携程客户已经付过账,酒店说在携程里面可以退,携程客服又全是机器人客服,处理和响应都不及时等问题,还有就是发票问题,有些人是例行公事,想省钱在携程上订酒店,遇到网上订单不开发票的酒店,只能自己掏腰包。
- 主题4:主题体现出洗手间淋浴间漏水的问题。
- 主题5:可以看出某些酒店工作人员不专业,态度不友好,服务质量一般,收费不明细令顾客不满意,在收集数据过程中发现有些酒店房间里的矿泉水顾客以为是免费的结果8块一瓶,标记不明的物品令顾客不满意。
- 主题6:说明了有些酒店目的地与导航不符合,停车场管理不好,客户在停车时体验不好。
综合以上主题,我们发现:基础设施故障问题主要体现在空调坏了或者声音大和淋浴间漏水等问题;环境卫生问题主要体现在卫生间或者马桶等卫生问题;押金和发票问题主要体现在线上和线下双重扣费,开发票等问题。
根据对携程贵州五星级酒店评论的LDA主题分析,我对酒店提出以下建议:
- 定时排差房间基础设施是否正常,不要让客户发现问题,要自己发现问题。
- 优化线上和线上订购管理,避免多重收费,及时主动向顾客开发票。
- 保洁工作一定要加大力度,尤其是卫生间,注意卫生死角。
- 工作人员态度一定要友好,主动帮住客人解决问题。
- 房间里的东西价格一定要明细,每个房间免费提供矿泉水
- 优化停车场管理,不要让客户在停车场浪费时间,积极指导客户停车和注明车位。
通过以上改善措施,满足消费者需求,以此在众多酒店中凸显优势。