Redis提高篇——哨兵模式
哨兵模式
- 哨兵模式
- 哨兵机制简介
- 哨兵的作用
- 启动哨兵模式
- 哨兵模式的配置
- 启动哨兵模式
- 哨兵工作原理
- 阶段一:监控阶段
- 阶段二:通知阶段
- 阶段三:故障转移阶段
哨兵模式
哨兵机制简介
之前介绍集群的时候有这么个结构,有一个master的服务器,之后有很多个slave去连接master,master负责数据的写入,slave负责从master读出数据

但是现在思考一个问题,如果说master宕机了怎么办?
难道说就等着??让用户反馈之后再去修复?显然是不行的。针对这种情况,redis采取了如下办法:
1、将宕机的master下线
2、找一个slave作为master
3、通知所有的slave连接新的master
4、启动新的master与slave
5、全量复制N+部分复制N
改了之后,结构就是这样的:

什么是哨兵??
哨兵(sentinel)是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的master并将所有slave连接到新的master。
哨兵的作用
- 监控
不断的检查master和slave是否正常运行。master存活检测、master 与slave运行情况检测 - 通知(提醒)
当被监控的服务器出现问题时,向其他(哨兵间,客户端)发送通知。 - 自动故障转移
断开master与slave连接,选取一个slave作为master,将其他slave连接到新的master,并告知客户端新的服务器地址
注意
哨兵也是一台redis服务器, 只是不提供数据服务通常哨兵配置数量为单数,为什么要设置哨兵的数量是单数呢??这个问题先保留,后面会有介绍。
启动哨兵模式
哨兵模式的配置
配置哨兵
- 配置一拖二的主从结构(一个主机,两个从服务器)
- 配置三个哨兵(三个哨兵配置相同,端口不同) sentinel-26379.conf、sentinel-26380.conf、sentinel-26381.conf
- 启动哨兵
redis-sentinel sentinel-端口号.conf
哨兵的配置文件
# 打开redis安装目录下的那个,sentinel.conf配置文件,查看一下文件的内容(这里去掉了“#”和“$”开头的语句,那都是没啥用的提示信息)
[root@localhost redis-4.0.10]# cat sentinel.conf | grep -v "#" | grep -v "^$";
port 26379· # 打开的端口
dir /tmp # 数据信息存储的位置
# 哨兵模式的主机端口和master端口 2 是当后面的投票超过两票之后就确认master已经宕机了
sentinel monitor mymaster 127.0.0.1 6379 2
# 设置master断开之后多长时间哨兵可以确定master断开了
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
# 设置连接超时的时间
sentinel failover-timeout mymaster 180000
创建三个哨兵的配置文件:
# 把sentinel.conf里面重要的东西重定向到新的文件当中
cat sentinel.conf | grep -v "#" | grep -v "^$" > config/sentinel-26379.conf
# 复制sentinal-26379.conf里面的东西到sentinel-26380.conf、sentinel-26381.conf当中,并且改变端口号为26380、26381
sed 's/26379/26380/g' config/sentinel-26379.conf > sentinel-26380.conf
sed 's/26379/26381/g' config/sentinel-26379.conf > sentinel-26381.conf
# 最终得到的三个配置文件的内容是
port 26379
dir /usr/local/redis/redis-4.0.10/data
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
# 当前这个是sentinel-26379.conf文件的配置, 剩下两个配置文件只需改一下端口就行
主数据库和从数据库的配置信息
# master配置
port 6379 #运行在6379的redis数据库实例
daemonize no #后台运行redis
dir /usr/local/redis/redis-4.0.10/data/log #指定redis日志文件的生成目录
dbfilename dump-6379.log # 设置rdb文件的名称
rdbcompression yes # rdb存储到本地是否压缩,默认yes,采用LZF压缩
rdbchecksum yes # 是否进行RDB文件格式校验,写文件和读文件的时候都进行
save 10 2
appendonly yes # 是否开启aof持久化功能,默认是no
appendfsync everysec # 指定aof写策略
auto-aof-rewrite-min-size 300 # 设置最小的自动重写aof文件的长度
appendfilename appendonly-6379.aof # 设置aof文件的名称
bind 127.0.0.1 # 绑定master的地址信息
databases 16 # 设置master存储的数据的位置 设置数据库号16
# 另外两个slave的配置如下:
[root@localhost config]# cat redis-6380.conf
port 6380
daemonize no
dir /usr/local/redis/redis-4.0.10/data
slaveof 127.0.0.1 6379
[root@localhost config]# cat redis-6381.conf
port 6381
daemonize no
dir /redis-4.0.10/data
slaveof 127.0.0.1 6379
启动哨兵模式
1、首先开启redis服务
redis-server redis-6379.conf
redis-server redis-6380.conf
redis-server redis-6381.conf
然后对应的redis的master服务器出现一些信息:
4073:M 27 May 23:35:13.881 * Ready to accept connections # 准备去接受连接
4073:M 27 May 23:35:14.494 * Slave 127.0.0.1:6381 asks for synchronization # slave127.0.0.1 6381请求同步
4073:M 27 May 23:35:14.494 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for '56c106b870d6d7c80581fc8e5fe64cfdb275b546', my replication IDs are '9f6c358bd59938841d99cd7dae5335751eaa736e' and '0000000000000000000000000000000000000000') # 为进程创建ID
4073:M 27 May 23:35:14.494 * Starting BGSAVE for SYNC with target: disk # 开始bgsave到磁盘当中
4073:M 27 May 23:35:14.494 * Background saving started by pid 4077 # 后台开启一个进程进行bgsave操作
4077:C 27 May 23:35:14.497 * DB saved on disk # 数据库保存到磁盘当中
4077:C 27 May 23:35:14.497 * RDB: 0 MB of memory used by copy-on-write
4073:M 27 May 23:35:14.585 * Background saving terminated with success # 后台保存成功
4073:M 27 May 23:35:14.585 * Synchronization with slave 127.0.0.1:6381 succeeded
2、开启哨兵模式
redis-s`在这里插入代码片`entinel sentinel-26379.conf
redis-sentinel sentinel-26379.conf
redis-sentinel sentinel-26379.conf
之后显示一些信息(这里只是对26379的那个哨兵进行介绍)

4350:X 27 May 23:49:59.193 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
4350:X 27 May 23:49:59.193 # Sentinel ID is 55457717cbb08474b4bd3084994b5bfb061a9e97 # 开启的id是……
4350:X 27 May 23:49:59.193 # +monitor master mymaster 127.0.0.1 6379 quorum 2
4350:X 27 May 23:49:59.194 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 # 有slave连入的时候,写入提示信息
4350:X 27 May 23:49:59.195 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 # 另外一个slave连入的时候,写入提示信息
4350:X 27 May 23:50:55.926 * +sentinel sentinel 2b3bf52cbaf2df685d41009826ce4c9f073e7eb4 127.0.0.1 26380 @ mymaster 127.0.0.1 6379
4350:X 27 May 23:51:53.181 * +sentinel sentinel cb0f76e1bc9c7652f261793db59c3a56d0954266 127.0.0.1 26381 @ mymaster 127.0.0.1 6379
哨兵工作原理
阶段一:监控阶段
在监控阶段的工作原理:
1、需要进行各个sentinel的状态,检验是不是在线,第一个连接master的sentinel向其他的sentinel发送ping,接收到返回值pong,说明相应的sentinel在线。
2、获取master的状态,其中包括master的属性信息(runid,role: master),同时获取slave的详细信息(因为master当中有slave的信息)
3、之后获取各个slave的状态(根据master当中的slave信息),主要是slave的属性信息(runid、role:slave、master_host、master_port、offset等信息)
上面描述的这些流程,看一下sentinel的配置文件就知道:
[root@localhost config]# cat sentinel-26379.conf
port 26379
dir "/usr/local/redis/redis-4.0.10/data"
sentinel myid 55457717cbb08474b4bd3084994b5bfb061a9e97 # 这个是生成这个哨兵的id,和上面的那个id可以对应上
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
# Generated by CONFIG REWRITE
sentinel known-slave mymaster 127.0.0.1 6381 # 哨兵已知的slave 6380 和 6381
sentinel known-slave mymaster 127.0.0.1 6380
# 所有的哨兵的信息
sentinel known-sentinel mymaster 127.0.0.1 26380 2b3bf52cbaf2df685d41009826ce4c9f073e7eb4
sentinel known-sentinel mymaster 127.0.0.1 26381 cb0f76e1bc9c7652f261793db59c3a56d0954266
sentinel current-epoch 0
图形理解:
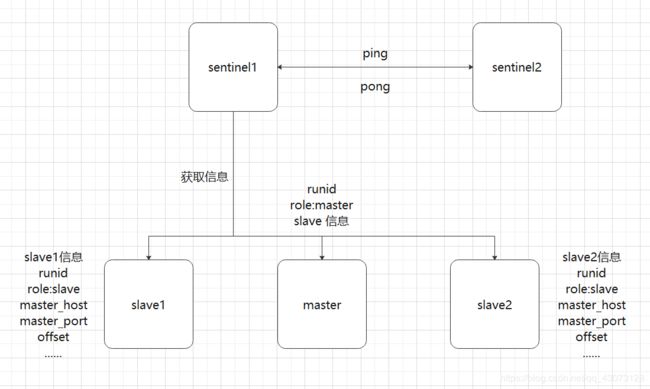
基本的原理是这样,但是具体的工作顺序是怎么样的呢???
1、首先sentinel获取master的信息,包括master和slave的信息,在master生成一个sentinelRedisinstance的实例,包括master、多个slave的信息、多个sentinel的信息。在sentinel也生成一个sentinelState。
2、因为master和sentinel之间需要进行指令通信,所以通过一个连接进行指令传输,叫cmd连接
3、之后sentinel通过刚才获得的slaves的信息继续获得其他slaves的信息
4、其实sentinel2也去获取master的信息,但是发现有一个sentinels的信息,那么为了保证数据的同步,就和sentinel1保持联系,互相ping,保证数据的同步,在获取slave2的信息的时候也是这个样子
5、当第三个sentinel3进入的时候,也会去访问master和slave,之后和sentinel1、sentinel2进行连接和数据的交换
阶段二:通知阶段
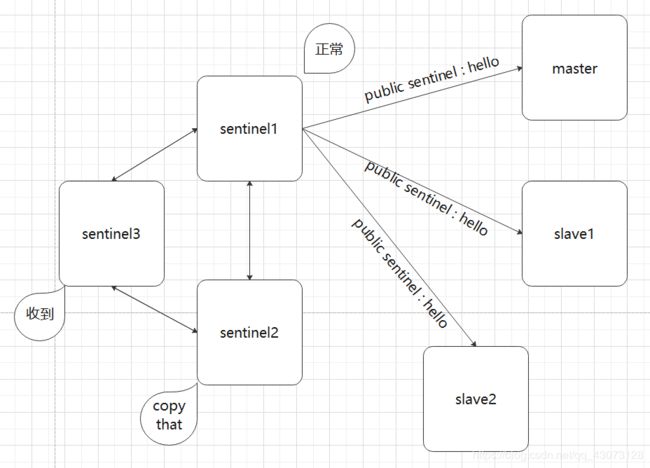
1、任意一个sentinel(假设是sentinel1)向master以前所有的slave发送hello消息,收到回复
2、如果正常,那么立刻通知其他的sentinel现在的系统正常信息,其他的sentinel和这个sentinel进行同步
3、下一次可能是别的sentinel走上面的流程,通知的过程和上面的也都一样。
阶段三:故障转移阶段
图形理解:

1、首先sentinel向master发送hello消息,如果没有回应就一直发,发到一定程度的时候,就判断master是挂掉了,master记录一个标记flags:SRI__S_DOWN,s是subject的意思,也就是主观,叫做主观下线
2、光是记录挂掉的消息不行,还得通知其他的sentinel主服务器挂掉了,所以在内网发送消息,如图③
3、其他的sentinel发现了这条消息,得确认是不是到底挂掉了,所以也会发送hello到master上,如果也是长时间没反应,那么也认为master是真的挂掉了。
4、等到半数的sentinel认为master挂掉了,那么master状态变为flags:SRI__O_DOWN, O是Object,客观的意思,叫做客观下线
刚才强调的半数,就是sentinel的投票机制,当master挂掉的时候,之前设置的奇数个sentinel开始投票,半数的通过,说明master挂掉了,之后选取新的slave作为master,那么这个投票的过程是怎么样的呢?
选取主sentinel:首先,这些sentinel首先要选出来一个头头,执行后面的选master操作,选出这个头头就要进行这个投票的过程。

1、首先五个sentinel在他们的内部交流网络当中发出一个主机挂了的消息,当中包含一些属性(挂了的ip,port,这个哨兵的竞选次数,哨兵的runid)、
2、之后开始进行票选,每一个哨兵都根据别的哨兵对自己的请求的先后顺序决定把自己的票给谁,党一个哨兵获取到票数的时候,他的竞选次数+1
一次选票时候的结果可能是这样:

可能是sentinel1的发送速度比sentinel2块,所以先获取到一票,最后会选出来一个票数多的哨兵作为最后的主哨兵(票数超过总哨兵的一半,所以这就是为什么之前提到哨兵的个数是奇数, 因为防止出现大屏的情况)
在选出哨兵之后,就开始执行选master的阶段……
选取一个slave作为master:选出来一个sentinel作为头头,开始选取slave的操作
选取的过程当中按照如下标准:
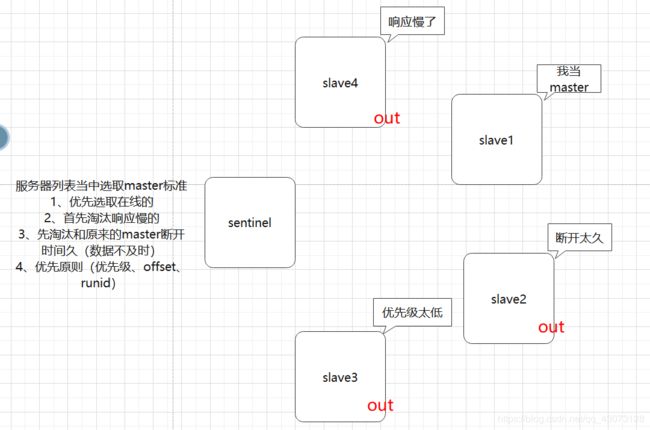
master的选取规则
1、优先选取在线的。断线的肯定是不选
2、首先淘汰响应慢的。响应慢的也不适合当master
3、先淘汰和原来的master断开时间久。断开时间越久,数据的偏差越大。
4、优先原则(优先级、offset、runid)优先级高的是最合适的;offset最大的说明数据也是最新的,也适合
发送指令(sentinel)
1、选出来之后sentinel向最合适的slave发出指令slaveof no one其他的salve都
2、光选出来master不行,还得让其他的slave知道master改变了,所以sentinel向其他的slave发送新的master IP端口,之前断掉的master也算一个被通知的slave
关于哨兵模式就写到这,感谢你可以看到结尾。