面试题系列-HashMap
文章目录
- HashMap
- 数据结构
- put原理:
- 链表插入方式:
- 为啥改为尾插法
- 扩容机制
- 尾插法由来(头插法在多线程下可能产生环形链表)
- 尾插是怎么样的呢?
- HashMap的默认初始化长度
- 总结
HashMap
数据结构
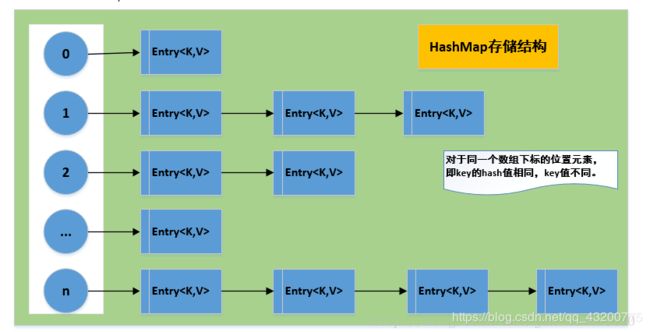
由数组和链表组合构成的数据结构
- HashMap底层是以数组的方式进行存储的,将key-value对作为数组中的一个元素进行存储
- key-value都是Map.Entry的属性,其中将Key的值进行hash之后进行存储,即每一个key都是计算hash值,然后存储。每一个Hash值对应一个数组下标,数组下标是根据hash值和数组长度计算得来的
- 由于不同的key有可能出现hash值相同,也就是说数组中该下标位置的元素出现了两个,对于这种情况,hashmap使用了链表形式进行存储。
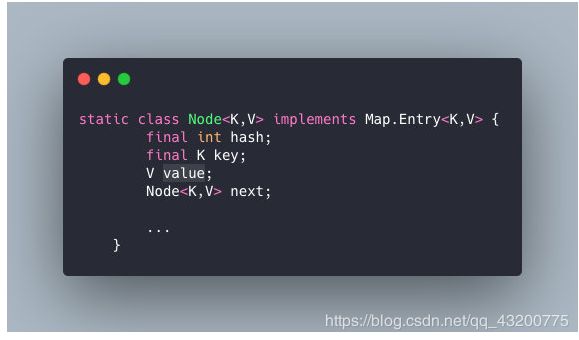
在Java7时叫做Entry
Java8 叫做Node
put原理:
put("key","value") 时,通过哈希函数计算出插入的位置,然后进行插入
需要链表是因为在put的时候,哈希和希哈两个都去hash有一定的概率会一样, 在极端情况下,就形成了链表。
链表插入方式:
1.8之前使用的是头插法 1.8之后使用的是尾插法。
为啥改为尾插法
扩容机制
hash的扩容机制:数组容量是有限的,数据多次插入的,到达一定的数量就会进行扩容,也就是resize
- Capacity:Hash Map当前长度
- LoadFactor:负载因子,默认为0.75f。
负载因子就是说,如果当前的容量大小为100,当你存进第76个的时候,判断发现需要进行resize,那就进行扩容,但HashMapd的扩容不是简单的扩大点容量这么简单,
扩容步骤:
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
为什么要重新hash,不直接复制过去。
Hash的公式:index = HashCode(Key)&(length-1)
因为数组的长度扩大之后,Hash的规则也会进行改变。原来计算出来的Hash值在新数组重不一样。
尾插法由来(头插法在多线程下可能产生环形链表)
比如 ,我们现在往一个容量大小为2的put两个值,负载因子在put第二个的时候就会进行resize。
那么现在我们在容量为2的容器里用不同线程插入a,b,c 。假如我们在resize之前打了一个断电,那么意味着三个数据都插入了,但是还没resize,那么扩容前可能是这样的,
a->b->c
因为resize的赋值方式,使用了单链表的头插入,同一位置上,新元素总会放在链表的头部位置,在旧数组重,同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置
所以有可能出现下面的情况

b指向了a
当线程调整完成时,就可能出现环形链表:因为在旧数组中,a是指向b的,而这个指向存在新数组是不会改变,所以会导致环形链表。
尾插是怎么样的呢?
使用头插会改变链表上的顺序,但是使用尾插,在扩容时保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说本来A->b 在扩容后还是A->b
Java7 在多线程操作HashMap时可能引起死循环,主要原因是扩容转移前后链表顺序倒置,在转移过程中修改了原来链表节点的引用关系。
Java8在同样的前提下,在扩容时保持链表元素原本的顺序,就不会出现链表成环的问题了。
那是不是意味着Java8就可以把HashMap用在多线程中呢?
即使不会出现死循环,但源码中Put/Get方法都没有加同步锁,多线程情况最容易出现的就是:无法保证上一秒put的值,下一秒get的时候还是原来的值,所以线程安全还是无法保证
HashMap的默认初始化长度
HashMap的默认初始化长度是16。
源码中使用的是
static final int DEFAILT_INITAL_CAPACITY = 1<<4;
我们在创建HashMap的时候,阿里巴巴规范插件会提醒我们最好赋初值,最好是2的幂
这样是为了位运算的方便,位与运算比算数计算的效率高了很多,之所以选择16,是为了服务
将key映射到index的算法。
打个比方,key为“帅丙”的十进制为766132那二进制就是10111011000010110100
index的计算公式:index= HashCode(Key)&(Length-1)
10111011000010110100(HashCode)&15的二进制1111(length-1)=4
所以用位与运算效果与取模一样,性能也提高了不少!
为啥不用别的用16?
因为在使用不是2的幂的数字的时候,length-1的值是所有二进制位为1,这种情况下,index的结果等同于HashCode的后几位的值,只要输入的HashCode本身分布均匀,Hash的算法的结果也就是均匀的。为了实现均匀分布。
为啥我们重写equals方法的时候需要重写hashCode方法呢,
因为在java中,所有的对象都是继承于Object类,Object类中有两个方法equals、hashCode、这两个方法都是用来比较两个对象是否相等的。
在没有重写equals方法我们都是继承了object的equals方法,哪里的equals的比较两个对象的内存地址,显然我们new了两个对象,内存地址肯定不一样。
- 对于值对象,==比较的是两个对象的值
- 对于引用对象,比较的是两个对象的地址
因为HashMap是通过Key的HashCode去寻找index的,index一样就形成了链表,也就是说两个不同的key,index都是一样的,那么get的时候,get根据key去hash然后计算出index,然后找到了位置,那么怎么找具体的两个key呢,equals,所以如果对equals方法进行重写,hashCode也要重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。
否则会导致hashCode都一样。
HashMap线程安全的场景
一般使用hashTable 或者ConcurrentHashMap,因为前者的并发度原因所以没有太多的使用场景,所以一般有线程不安全的场景我们都使用的是ConcurrentHashMap。
总结
HashMap绝对是最常问的集合之一
篇幅和精力的原因我就介绍到了一部分的主要知识点,我总结了一些关于HashMap常见的面试题。
-
HashMap的底层数据结构?
数组加链表的组合
-
HashMap的存取原理?
-
存
public V put(K key, V value) { //当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因 if (key == null) return putForNullKey(value); //计算key的hash值 int hash = hash(key.hashCode()); ------(1) //计算key hash 值在 table 数组中的位置 int i = indexFor(hash, table.length); ------(2) //从i出开始迭代 e,找到 key 保存的位置 for (Entry<K, V> e = table[i]; e != null; e = e.next) { Object k; //判断该条链上是否有hash值相同的(key相同) //若存在相同,则直接覆盖value,返回旧value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; //旧值 = 新值 e.value = value; e.recordAccess(this); return oldValue; //返回旧值 } } //修改次数增加1 modCount++; //将key、value添加至i位置处 addEntry(hash, key, value, i); return null; }- 当key为空的时候,将Entry
- 当key不为空的时候,执行key.hashCode()方法计算出Hash值找到index,
- index位置没有元素时,此时直接将Entry
- index位置有元素且对象相同(key值相等或者key.equals),则替换掉原来的值V
- index位置有元素切对象不同,则hashCode发生碰撞,HashMap通过单链表解决,
- 当key为空的时候,将Entry
-
取
通过key的hash值找到table数组中的索引处的Entry,然后返回该key对应的value即可
public V get(Object key) { // 若为null,调用getForNullKey方法返回相对应的value if (key == null) return getForNullKey(); // 根据该 key 的 hashCode 值计算它的 hash 码 int hash = hash(key.hashCode()); // 取出 table 数组中指定索引处的值 for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; //若搜索的key与查找的key相同,则返回相对应的value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }
-
-
Java7和Java8的区别?
1.7 头插法
1.8 尾插法
-
为啥会线程不安全?
上面有
-
有什么线程安全的类代替么?
线程安全:ConcurrentHashMap,HashTable
线程不安全:HashMap
-
默认初始化大小是多少?为啥是这么多?为啥大小都是2的幂?
16 均匀分布
-
HashMap的扩容方式?负载因子是多少?为什是这么多?
-
HashMap的主要参数都有哪些?
K,V,指向下一节点的next,hash值
-
HashMap是怎么处理hash碰撞的?
**碰撞:**hashCode如果相等则有冲突,对于这种情况叫碰撞
-
hash的计算规则?
-
index = HashCode(Key)&(length-1)