全网最全精析破解 Springboot+Jpa 对数据库增删改查
前言:
昨天做的是springboot+mybatis 对数据库进行增删改查
但是我感觉配置文件太多了 很麻烦 繁琐
今天搞一下springboot+Jpa对数据库进行增删改查, 感觉很好用 ,所以记录一下
关于Jpa:
一、JPA 概述
-
Java Persistence API(Java 持久层 API):用于对象持久化的 API
-
作用:使得应用程序以统一的方式访问持久层
-
前言中提到了 Hibernate,那么JPA 与 Hibernate究竟是什么关系呢:
1)JPA 是 Hibernate 的一个抽象,就像 JDBC 和 JDBC 驱动的关系
2)JPA 是一种 ORM 规范,是 Hibernate 功能的一个子集 (既然 JPA 是规范,Hibernate 对 JPA 进行了扩展,那么说 JPA 是 Hibernate 的一个子集不为过)
3)Hibernate 是 JPA 的一个实现
- JPA 包括三个方面的技术:
1)ORM 映射元数据,支持 XML 和 JDK 注解两种元数据的形式
2)JPA 的 API
3)查询语言:JPQL
一:
使用工具:eclipse
首先看一下我们项目的目录结构

这里补充一点 我这个项目创建方式为 在Spring官网上创建,选择好自己所需要的依赖(jar包)点击生成 ,就会在官网上下载一个.zip的压缩文件。下载完成后再eclipse中导入即可
该网址为 https://start.spring.io/
————————————————————————————————————————————————————————————————————
好了我们开始进入正题
我么生成好了项目 看一下pom文件
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.1.RELEASE
com.example
demo_2
0.0.1-SNAPSHOT
demo_2
Demo project for Spring Boot
1.8
org.springframework.boot
spring-boot-starter-data-jpa
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-devtools
runtime
mysql
mysql-connector-java
runtime
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
如上我们可以看到 我所使用的依赖有 web lombook devtools mysql jpa等
1. 看到我们的实体层Entity
package com.example.demo_2.entity;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name="role")
public class Role {
@Id
@GeneratedValue
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
- @Table 标注类对应的表
- 若表名和类型相同时,省略@Table,比如类Users 和表 users;
- 若不相同时,必须有@Table,并设置name,为该类对应的表名。@Table(name=“users”)
- @Entity 标注实体
- @Id 标注id
- @Transient 标注该属性不做与表的映射(原因:可能表中没有该属性对应的字段)
- 有该注解,在执行sql语句时,就不会出现该属性,否则会有,若表中没有该字段则会报错
- @Basic 默认所有属性都有该注解(主键需要单独使用@Id),所以可以省略
-
该注解可以放在属性上,也可以放在对应的getter方法上。 -
注意:要么统一将@Basic放在属性上,要么统一放在对应的getter方法上。(一般都放在属性上,可读性比较好) - @Column 类中属性名和表中对应字段名不相同时,会使用该注解,指明在类中对应的字段
-
@Column(name="对应的表中字段名")
注意了:
1、GeneratedValue与GenericGenerator的区别
@GeneratorValue注解----JPA通用策略生成器
@GenericGenerator注解----自定义主键生成策略
一个是通用的一个是自定义的这就是他们的区别。
2、@GeneratorValue注解----JPA通用策略生成器
GeneratorValue属于一个JPA接口,其接口下包含了两个抽象的参数,GenerationType类型的strategy和String类型的generator,并且两个参数都有相应的默认值。
.generator : String //JPA 持续性提供程序为它选择的主键生成器分配一个名称,如果该名称难于处理、是一个保留字、与事先存在的数据模型不兼容或作为数据库中的主键生成器名称无效,则将 generator 设置为要使用的 String 生成器名称。
例如用hibernate的uuid主键生成器就如下来写:
@GeneratedValue(generator="system-uuid")
@GenericGenerator(name="system-uuid", strategy = "uuid.hex")
那么问题来了 ?
什么是uuid
我已经给大家查阅资料
UUID 的目的是让分布式系统中的所有元素,都能有唯一的辨识资讯,而不需要透过中央控制端来做辨识资讯的指定。如此一来,每个人都可以建立不与其它人冲突的 UUID。
就是一个32位的序列码,让每一个ID都成为一个唯一的值
.strategy : String // 指定生成策略
他这个东西呢,有四种生成策略
1.TABLE:使用一个特定的数据库表格来保存主键。
2.SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
3.IDENTITY:主键由数据库自动生成(主要是自动增长型)
4.AUTO:主键由程序控制。
**虽然这么多但是我感觉还使用AUTO好一点!**自动智能
以上就是对我们的实体类Entity的写法 包括这个东西Jpa使用的注解进行介绍
————————————————————————————————————————————————————————————————————————————
控制层 Controller层
package com.example.demo_2.controller;
import java.util.List;
import java.util.Optional;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.example.demo_2.dao.RoleDao;
import com.example.demo_2.entity.Role;
@RestController
public class RoleController {
@Autowired
private RoleDao dao;
@RequestMapping("/add")
public void addOne() {
Role role=new Role();
role.setId(4);
role.setName("金喜善");
role.setAge(40);
dao.save(role);
}
@RequestMapping("/select")
public List selcetAll(){
return dao.findAll();
}
@RequestMapping("/find")
public Role findOne(){
return dao.findById(3).get();
//用get()方法会返回该对象
}
@RequestMapping("/findName")
public List findName() {
return dao.findNameTyer();
}
@RequestMapping("/updateName")
public int updateName() {
return dao.updateNameTyer();
}
}
自动注入Dao层 ,@RestController @RequestMapping("/add")
还是使用这几个注解
里面的方法我们一会在详聊 这里先说一下吧!
Controller层里面的方法 有Jpa这个工厂吧 人家已经提供给我们一些简单的对数据(增删改查)的操作 ,但是如果是复杂一点的增删改查我们就要自定义sql语句
但是又不是sql语句,因为我们使用的是Jpa对数据库进行操作,所以呢 !人家的语句叫JPQL语句
具体怎么使用我们在Dao层在说
————————————————————————————————————————————————————————————————————————————
进入Jpa关键的地方
我们先说Dao层
package com.example.demo_2.dao;
import java.util.List;
import javax.transaction.Transactional;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Modifying;
import org.springframework.data.jpa.repository.Query;
import com.example.demo_2.entity.Role;
@Transactional//来代表这是一个事务级别的操作,增删改查除了查都是事务级别的 teshuguifan
public interface RoleDao extends JpaRepository{
//@Modifying 涉及到删除和修改在需要加上@Modifying.
//jpql与SQL的区别就是SQL是面向对象关系数据库,他操作的是数据表和数据列,而jpql操作的对象是实体对象和实体属性
@Query("select name from Role")
List findNameTyer ();
//改 如果我们修改成功后返回值为1 再次修改为0
@Query("update Role set name='成龙' where name='泰尓'")
@Modifying
int updateNameTyer();
}
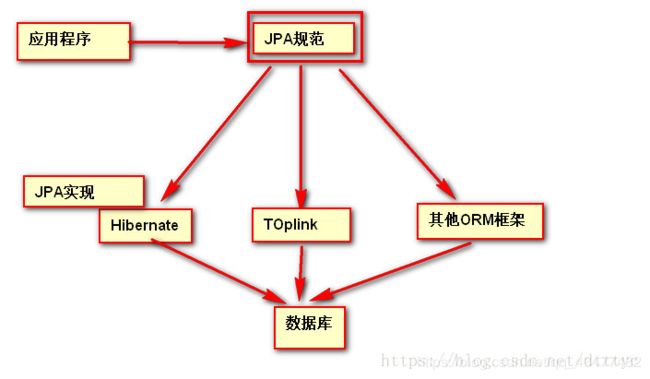
关于JPA规范和JPA实现他们之间的关系,以及JPQL和HIbernate等之间的关系。其实用一张图就可以说明他们之间的关系
什么叫持久化?
我们现在主流结构,还是三层结构
狭义的理解: “持久化”仅仅指把域对象永久保存到数据库中;广义的理解,“持久化”包括和数据库相关的各种操作。
● 保存:把域对象永久保存到数据库。
● 更新:更新数据库中域对象的状态。
● 删除:从数据库中删除一个域对象。
● 加载:根据特定的OID,把一个域对象从数据库加载到内存。
● 查询:根据特定的查询条件,把符合查询条件的一个或多个域对象从数据库加载内在存中。
2.为什么要持久化?
持久化技术封装了数据访问细节,为大部分业务逻辑提供面向对象的API。
● 通过持久化技术可以减少访问数据库数据次数,增加应用程序执行速度;
● 代码重用性高,能够完成大部分数据库操作;
● 松散耦合,使持久化不依赖于底层数据库和上层业务逻辑实现,更换数据库时只需修改配置文件而不用修改代码。
那么实体在他这个Jpa中怎么理解
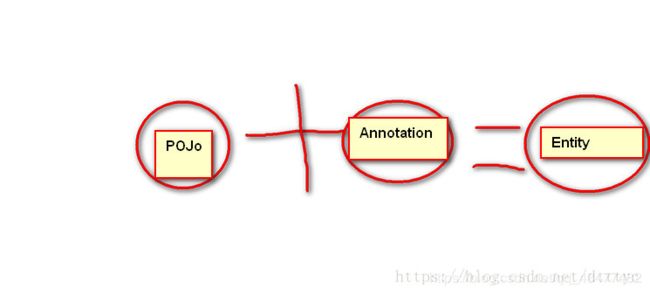
实体:实体就是一个普通的POJO,ps当你看到POJO的时候一定不要感觉很难,POJO其实就是一个普通的java类而已,只是名字高大尚了而已。实体的作用就是辅助我们orm.xml映射文件或者是Annotation
那么这个持久层有是啥?
EntityManager:上面所说的实体是与我们数据库映射的,但是没有起到持久化的作用,只有用上EntityManager的实体进行操作的时候才会有持久化能力
JPQL查询:Hibernate提供的是HQL查询,而JPA提供的是JPQL查询语言
我们都知道Jpa给我们提供了一些方法,对数据进行(增删改查)。
那么当我们的业务很复杂的时候呢,换句话说 Jpa这些方法是对数据的简单(增删改查)。当复杂的(增删改查呢你?)
我们就需要自定义sql语句了!
1.Jpql和sql进行比较
jpql与SQL的区别就是SQL是面向对象关系数据库,他操作的是数据表和数据列,而jpql操作的对象是实体对象和实体属性
2.Jpql 语句基本格式
下面是JPQL的基本格式,根据基本格式我们执行jpql语句
select 实体别名.属性名, 实体别名.属性名 from 实体名 as 实体别名 where 实体别名.实体属性 op 比较值
在我写的代码中体现就是:
//改 如果我们修改成功后返回值为1 再次修改为0
@Query("update Role set name='成龙' where name='泰尓'")
@Modifying
int updateNameTyer();
这就是对实体类 和实体类中的属性进行操作 ,这种写法就是Jpql语句
注意:
在写语句的时候我们可能需要使用到参数,如果是位置参数使用“?” ,如果是参数则使用 “:XX “
**JPQL 查询基本格式**
jpql的查询语句设计非常简单。主要是由于Query接口来完成的,而我们的Query接口是由EntityManager创建出来的。
Query createNamedQuery(String name):创建查询的名称来创建一个命名查询,使用sql和jpql都可以
Query createNativeQuery(String SQLString)根据的原生的sql语句查询
QuerycreateQuery(String jpqlString)根据指定的JPQL语句创建一个查询
**JPQL 执行基本格式**
当我们的参数和语句完事之后我们就应该执行,对于jpql执行分为以下几种
1.List getResultList()执行JPQL的select语句,并且返回的是list集合
2.Object getSingleResult()执行返回的那个结果的select语句
3.int executeupdate()表示执行批量的删除和更新
4.Query setFirstResult(int startPosition)设置查询结果从第几条记录开始
5.Query setMaxResults(int maxResult)表示设置查询最多返回几条语句
Jpql就是这么使用
还有几个注解
@Query与@Modifying执行更新操作
@Query 与 @Modifying这两个annotation一起声明,可定义个性化更新操作,例如只涉及某些字段更新时最为常用,
//改 如果我们修改成功后返回值为1 再次修改为0
//@Modifying 涉及到删除和修改在需要加上@Modifying.
@Query("update Role set name='成龙' where name='泰尓'")
@Modifying
int updateNameTyer();
•注意:
–方法的返回值应该是int,表示更新语句所影响的行数
–在调用的地方必须加事务,没有事务不能正常执行
这个时候我们还需要事务
事务
•Spring Data 提供了默认的事务处理方式,即所有的查询均声明为只读事务。
•对于自定义的方法,如需改变 SpringData 提供的事务默认方式,可以在方法上注解@Transactional声明
•进行多个 Repository操作时,也应该使它们在同一个事务中处理,按照分层架构的思想,这部分属于业务逻辑层,因此,需要在Service 层实现对多个 Repository的调用,并在相应的方法上声明事务。
————————————————————————————————————————————————————————————————————————————
总结一句话就是 当我们自定义使用方法时Jpql, 复杂的对数据进行(增删改查)的时候。
首先我们要加一个
@Query(这里面写Jpql语句 对数据进行操作)
@Modifying 涉及到删除和修改在需要加!
@Transactional 因为我们自定义了方法,Spring Data 提供了默认的事务处理方式,即所有的查询均声明为只读事务。
来代表这是一个事务级别的操作,增删改查除了查都是事务级别的 teshuguifan
—————————————————————————————————————————————————————————————————————————————
当我们要对数据进行修改时,写Jpql语句时update我们的方法返回值必须为int。可以看到这个Jpql对数据库的影响。
这样当在网页上返回值为1时,说明当前Jpql语句对数据有一条影响
当网页上返回值为0时,说明当前Jpql语句对数据没有影响,
换句话说就是Jpql语句已经执行完成。
//改 如果我们修改成功后返回值为1 再次修改为0
@Query("update Role set name='成龙' where name='泰尓'")
@Modifying
int updateNameTyer();
自己遇到的错误
当初自己实验的时候 Modifying我给他的返回值类型为Role 一个实体类型
执行的时候,出现错误
报错信息
java.lang.IllegalArgumentException: Modifying queries can only use void or int/Integer as return type!
Modifying查询语句中能用于void/int/Integer 返回类型,必须要给他一个void/int/Integer 返回类型,这样才可以清楚的看到这个JPQL(update语句)
对数据影响的条数。。
最后了 看一下我的配置文件
#mysql connect
spring.datasource.url=jdbc:mysql://localhost:3306/springboot?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
#jpa
spring.jpa.hibernate.ddl-auto=update
spring.jpa.show-sql=true
当时运行入口文件的时候,还给我报了个错误
The server time zone value 'Öйú±ê׼ʱ¼ä' is unrecognized or represents more than one time zone
当时很懵逼,最后才找到原来是mysql默认服务器时区问题
mysql服务器时区一定要和我们当前计算机系统时区匹配才可以
修改为:
jdbc:mysql://localhost:3306/test?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
就好了
感想一下
这两天 一天搞了Springboot+mybatis 一天搞了Springboot+Jpa
个人感觉吧 ,我认为还是Springboot+Jpa好用一些。
我觉得很大一部分的原因是 可能是我的sql语句太差了吧。感觉简单的直接调用Jpa给我们提供的方法,复杂一点的直接自定义方法 只要是别忘了使用那几个注解 ,最重要的一点就是你要遵循人家JPQL语句的写法啊 。
我感觉就是这些注意点就可以了 ,平时我也会加强sql语句的练习。
最近看到一句话,感觉挺好的吧
Crawling on the way of programming
意思就是:在编码路上爬行