MySQL学习
知识点
1.数据库概述
数据库(DataBase,DB):指长期保存在计算机的存储设备上,按照一定规则组织起来,可以被各种用户或应用共享的数据集合。(文件系统)
数据库管理系统(DataBase Management System,DBMS):指一种操作和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制,以保证数据库的安全性和完整性。用户通过数据库管理系统访问数据库中的数据。
数据库软件应该为数据库管理系统,数据库是通过数据库管理系统创建和操作的。
数据库:存储、维护和管理数据的集合。
MySQL
免费的数据库系统。被广泛用于中小型应用系统。体积小、速度快、总体拥有成本低,开放源代码。2008年被SUN收购,2009年SUN被Oracle收购。
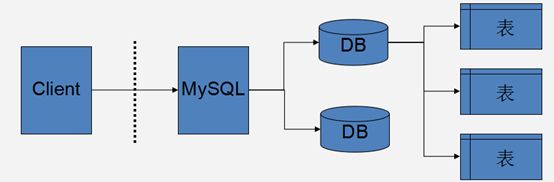
2.数据库服务器、数据库和表的关系
所谓安装数据库服务器,只是在机器上装了一个数据库管理程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
为保存应用中实体的数据,一般会在数据库创建多个表,以保存程序中实体的数据。
数据库服务器、数据库和表的关系如图所示:
3.MySQL的登录
首先确定在环境变量path里是否有mysql路径【C:\Program Files\MySQL\MySQL Server 5.7\bin】
3.1 打开命令行cmd
3.2 输入mysql -u root -p,然后密码,
3.3 接着输入show databases; 显示数据库
3.4 接着输入 exit; 退出数据库

3.5 修改mysql root用户密码
使用mysqladmin命令:
mysqladmin -u root -p旧密码 password 新密码
mysqladmin -u root -pabcdef password abc
4.sql的分类
DDL(Data Definition Language)
数据定义语言,用来定义数据库对象:库、表、列等;CREATE、 ALTER、DROP
DML(Data Manipulation Language)
数据表操作语言,用来定义数据库记录(数据);INSERT、 UPDATE、 DELETE
DCL(Data Control Language)【DBA来做】
数据控制语言,用来定义访问权限和安全级别;
DQL(Data Query Language)
数据查询语言,用来查询记录(数据)。SELECT
注意:sql语句以;结尾
5.DDL(操作数据库、表、列等)
掌握如何使用的关键字:CREATE、 ALTER、 DROP
5.1操作数据库
创建
create database mydb1;
Create database mydb2 character set gbk;
Create database mydb3 character set gbk COLLATE gbk_chinese_ci;
COLLATE :指排序规则
查询
查看当前数据库服务器中的所有数据库
show databases;
查看前面创建的mydb2数据库的定义信息
Show create database mydb2;
删除前面创建的mydb3数据库
Drop database mydb3;
修改
查看服务器中的数据库,并把mydb2的字符集修改为utf8;
alter database mydb2 character set utf8;
删除
drop database mydb3;
其他:
查看当前使用的数据库
select database();
切换数据库
use mydb2;
5.2操作数据表
语法:
create table 表名(
字段1 字段类型,
字段2 字段类型,
...
字段n 字段类型
);
常用数据类型

创建一个员工表
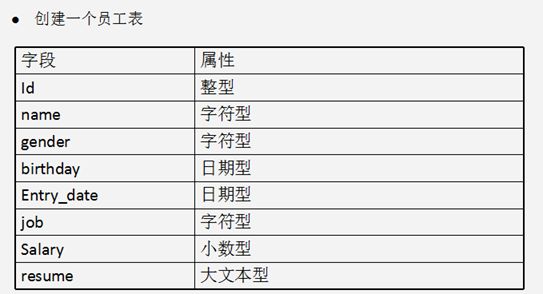
create table employee(
id int,
name varchar(20), 易洋千喜
gender bool,//true 男性 ,false 女性
gender varchar(6) male 男性 female:女性
birthday date,
Entry_date date,
job varchar(20),
salary float,
resume text
);
当前数据库中的所有表
SHOW TABLES;
查看表的字段信息
DESC employee;
增加一个image列
ALTER TABLE employee ADD image blob;
修改job列长度为60
ALTER TABLE employee MODIFY job varchar(60);
删除image列
ALTER TABLE employee DROP image;//一次只能删除一个列
表名改为user
RENAME TABLE employee TO user;
查看表格的创建细节
SHOW CREATE TABLE user;
修改表的字符集为gbk
ALTER TABLE user CHARACTER SET gbk;
列名name修改为username
ALTER TABLE user CHANGE name username varchar(100);
删除表
DROP TABLE user ;
6 DML(对表中数据操作)
DML是对表中的数据进行增、删、改的操作。不要与DDL混淆了。
INSERT 、UPDATE、 DELETE
小知识:
在mysql中,字符串类型和日期类型都要用单引号括起来。‘tom’ ‘2015-09-04’
空值:null
6.1插入操作:INSERT
语法: INSERT INTO 表名(列名1,列名2 …)VALUES(列值1,列值2…);
注意:列名与列值的类型、个数、顺序要一一对应。
可以把列名当做java中的形参,把列值当做实参。
值不要超出列定义的长度。
如果插入空值,请使用null
插入的日期和字符一样,都使用引号括起来。
create table emp(
id int,
name varchar(100),
gender varchar(10),
birthday date,
salary float(10,2),
job varchar(20),
entry_date date,
resume text
);
插入数据
insert into emp (id,name,gender,birthday,salary,entry_date,resume)
values (1,'gyf','female','1988-10-12',100000.00,'2000-10-12','good good');
insert into emp (id,name,gender,birthday,salary,entry_date,resume)
values (2,'mayun','female','1988-10-12',100000.00,'2000-10-12','good good');
insert into emp(id,name,gender,birthday,salary,entry_date,resume)
values (3,'mht','female','1988-10-12',100000.00,'2000-10-12','good good');
批量插入
insert into emp(id,name,gender,birthday,salary,entry_date,resume)
values
(4,'gyf1','female','1988-10-12',100000.00,'2000-10-12','good good'),
(5,'mayun1','female','1988-10-12',100000.00,'2000-10-12','good good'),
(6,'mht1','female','1988-10-12',100000.00,'2000-10-12','good good');
6.2修改操作 UPDATE
语法:UPDATE 表名 SET 列名1=列值1,列名2=列值2 。。。 WHERE 列名=值
6.3删除操作 DELETE
语法 : DELETE FROM 表名 【WHERE 列名=值】
7 DQL操作(查询操作-重点)
DQL数据查询语言 (重要)
数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端。
查询返回的结果集是一张虚拟表。
查询关键字:SELECT 语法(重点)
SELECT selection_list /*要查询的列名称*/
FROM table_list /*要查询的表名称*/
WHERE condition /*行条件*/
GROUP BY grouping_columns /*对结果分组*/
HAVING condition /*分组后的行条件*/
ORDER BY sorting_columns /*对结果排序*/
LIMIT offset_start, row_count /*结果限定*/
7.1基础查询
-
查询所有列
SELECT * FROM stu; -
查询指定列
SELECT sid, sname, age FROM stu;
7.2条件查询where
条件查询介绍
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用如下运算符及关键字:
=、!=、<>、<、<=、>、>=;
BETWEEN…AND;
IN(set);
IS NULL; IS NOT NULL
AND;
OR;
NOT;
7.3模糊查询like(重点)
当想查询姓名中包含a字母的学生时就需要使用模糊查询了。模糊查询需要使用关键字LIKE。
通配符:
_ 任意一个字符
%:任意0~n个字符
7.4字段控制查询
去除重复记录
去除重复记录(两行或两行以上记录中系列的上的数据都相同),例如emp表中sal字段就存在相同的记录。当只查询emp表的sal字段时,那么会出现重复记录,那么想去除重复记录,需要使用DISTINCT:
SELECT DISTINCT sal FROM emp;
查看雇员的月薪与佣金之和
因为sal和comm两列的类型都是数值类型,所以可以做加运算。如果sal或comm中有一个字段不是数值类型,那么会出错。
SELECT *,sal+comm FROM emp;
comm列有很多记录的值为NULL,因为任何东西与NULL相加结果还是NULL,所以结算结果可能会出现NULL。下面使用了把NULL转换成数值0的函数IFNULL:
SELECT *,sal+IFNULL(comm,0) FROM emp;
给列名添加别名
在上面查询中出现列名为sal+IFNULL(comm,0),这很不美观,现在我们给这一列给出一个别名,为total:
SELECT *, sal+IFNULL(comm,0) AS total FROM emp;
给列起别名时,是可以省略AS关键字的:
SELECT *,sal+IFNULL(comm,0) total FROM emp;
7.4 排序order by
- order by 列名 asc(默认) 升序 desc降序
》查询所有学生记录,按年龄升序排序
SELECT *
FROM stu
ORDER BY sage ASC;
或者
SELECT *
FROM stu
ORDER BY sage;
》查询所有学生记录,按年龄降序排序
SELECT *
FROM stu
ORDER BY age DESC;
》查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序
SELECT * FROM emp
ORDER BY sal DESC,empno ASC;
7.5聚合函数(重点)
聚合函数是用来做纵向运算的函数:
COUNT():统计指定列不为NULL的记录行数;
MAX():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
SUM():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
AVG():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
COUNT
当需要纵向统计时可以使用COUNT()。
查询emp表中记录数:
SELECT COUNT(*) FROM emp;
查询emp表中有佣金的人数:
SELECT COUNT(comm) cnt FROM emp;
注意,因为count()函数中给出的是comm列,那么只统计comm列非NULL的行数。
查询emp表中月薪大于2500的人数:
SELECT COUNT(*) FROM emp
WHERE sal > 2500;
统计月薪与佣金之和大于2500元的人数:
SELECT COUNT(*) FROM emp WHERE sal+IFNULL(comm,0) > 2500;
查询有佣金的人数,有领导的人数:
SELECT COUNT(comm), COUNT(mgr) FROM emp;
SUM和AVG
当需要纵向求和时使用sum()函数。
查询所有雇员月薪和:
SELECT SUM(sal) FROM emp;
查询所有雇员月薪和,以及所有雇员佣金和:
SELECT SUM(sal), SUM(comm) FROM emp;
查询所有雇员月薪+佣金和:
SELECT SUM(sal+IFNULL(comm,0)) FROM emp;
统计所有员工平均工资:
SELECT AVG(sal) FROM emp;
MAX和MIN
查询最高工资和最低工资:
SELECT MAX(sal), MIN(sal) FROM emp;
7.6分组查询GROUP BY(重点)
当需要分组查询时需要使用GROUP BY子句,例如查询每个部门的工资和,这说明要使用部门来分组。
注:凡和聚合函数同时出现的列名,一定要写在group by 之后
HAVING子句
查询工资总和大于9000的部门编号以及工资和:
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno
HAVING SUM(sal) > 9000;
7.7LIMIT 方言(查询结果行数限定)
- LIMIT用来限定查询结果的起始行,以及总行数
查询5行记录,起始行从0开始
SELECT * FROM emp LIMIT 0, 5;
注意,起始行从0开始,即第一行开始!
查询10行记录,起始行从3开始
SELECT * FROM emp LIMIT 3, 10;
分页查询
如果一页记录为5条,希望查看第3页记录应该怎么查呢?
第一页记录起始行为0,一共查询5行;
第二页记录起始行为5,一共查询5行;
第三页记录起始行为10,一共查询5行;
8.数据的完整性
**作用:**保证用户输入的数据保存到数据库中是正确的。
- 确保数据的完整性 = 在创建表时给表中添加约束
完整性的分类:
实体完整性
域完整性
引用完整性
8.1实体完整性(重要)
实体:即表中的一行(一条记录)代表一个实体(entity)
实体完整性的作用:标识每一行数据不重复。
约束类型: 主键约束(primary key) 唯一约束(unique) 自动增长列(auto_increment)
主键约束(primary key)
特点:数据唯一,且不能为null
第一种添加方式:(最常用)
CREATE TABLE student(
Id int primary key,
Name varchar(50)
);
第二种添加方式:
此种方式优势在于,可以创建联合主键
CREATE TABLE student(
id int,
name varchar(50),
primary key(id)
);
CREATE TABLE student(
id int,
name varchar(50),
primary key(id,name)
);
第三种添加方式:
CREATE TABLE student(
id int,
name varchar(50)
);
ALTER TABLE student
ADD PRIMARY KEY (id);
唯一约束(unique):
要求该列唯一,允许为空,但只能出现一个空值。唯一约束可以确保一列或者几列不出现重复值。
CREATE TABLE student(
id int primary key,
name varchar(50) unique
);
自动增长列(auto_increment)
给主键添加自动增长的数值,列只能是整数类型,但是如果删除之前增长的序号,后面再添加的时候序号不会重新开始,而是会接着被删除的那一列的序号
CREATE TABLE student(
id int primary key auto_increment,
name varchar(50)
);
INSERT INTO student(name) values(‘tom’);
8.2域完整性(重点,包含了外键约束)
- 域完整性的作用:限制此单元格的数据正确与否
- 域完整性约束:数据类型 非空约束(not null) 默认值约束(default)
Check约束(mysql不支持) check();
非空约束:not null
CREATE TABLE student(
id int pirmary key,
name varchar(50) not null,
sex varchar(10)
);
INSERT INTO student values(1,’tom’,null);
默认值约束 default
CREATE TABLE student(
Id int pirmary key,
Name varchar(50) not null,
Sex varchar(10) default ‘female’
);
insert into student1 values(1,'tom','female');
insert into student1 values(2,'jerry',default);
外键约束:FOREIGN KEY
– 添加外键的语法格式:
– CONSTRAINT 自定义外键名称 FOREIGN KEY (外键字段) REFERENCES 表名(主键)
学生(student)和成绩(score)
CREATE TABLE student(
id int primary key,
name varchar(50) not null,
gender varchar(10) default '男'
);
create table score(
id int,
score int,
name varchar(6),
sid int,
CONSTRAINT fk_score_student FOREIGN KEY(sid) REFERENCES student(id)
);
第二种添加外键方式。
ALTER TABLE score ADD CONSTRAINT fk_stu_score FOREIGN KEY(sid) REFERENCES student(id);
插入数据
INSERT INTO student values(1,'jerry','女');
INSERT INTO student values(2,'tony','女');
INSERT INTO student values(3,'mia','男');
INSERT INTO score values(2,80,’数学’,4);
8.3表与表之间的关系
一对一:
例如t_person表和t_card表,即人和身份证。这种情况需要找出主从关系,即谁是主表,谁是从表。人可以没有身份证,但身份证必须要有人才行,所以人是主表,而身份证是从表。设计从表可以有两种方案:
在t_card表中添加外键列(相对t_user表),并且给外键添加唯一约束;
给t_card表的主键添加外键约束(相对t_user表),即t_card表的主键也是外键。
一对多(多对一):
最为常见的就是一对多!一对多和多对一,这是从哪个角度去看得出来的。t_user和t_section【部门】的关系,从t_user来看就是一对多,而从t_section的角度来看就是多对一!这种情况都是在多方创建外键!
多对多:
例如t_stu和t_teacher表,即一个学生可以有多个老师,而一个老师也可以有多个学生。这种情况通常需要创建中间表来处理多对多关系。例如再创建一张表t_stu_tea表,给出两个外键,一个相对t_stu表的外键,另一个相对t_teacher表的外键。
9.多表查询(最重要)
多表查询有如下几种:
a合并结果集;UNION 、UNION ALL
b连接查询
内连接 [INNER] JOIN ON
外连接 OUTER JOIN ON
左外连接 LEFT [OUTER] JOIN
右外连接 RIGHT [OUTER] JOIN
全外连接(MySQL不支持)FULL JOIN
自然连接 NATURAL JOIN
c子查询
9.1 合并结果集
作用:合并结果集就是把两个select语句的查询结果合并到一起!
合并结果集有两种方式:
UNION:去除重复记录,例如:SELECT * FROM t1 UNION SELECT * FROM t2;
UNION ALL:不去除重复记录,例如:SELECT * FROM t1 UNION ALL SELECT * FROM t2。
要求:被合并的两个结果:列数、列类型必须相同
CREATE TABLE employee_china(
id int,
name varchar(50)
);
CREATE TABLE employee_usa(
id int,
name varchar(50)
);
INSERT INTO employee_usa VALUES (1,'michal');
INSERT INTO employee_usa VALUES (2,'lucy');
INSERT INTO employee_usa VALUES (3,'anmy');
INSERT INTO employee_china VALUES (1,'马云');
INSERT INTO employee_china VALUES (2,'郭永峰');
INSERT INTO employee_china VALUES (3,'马化腾');
INSERT INTO employee_usa VALUES (4,'vincent');
INSERT INTO employee_china VALUES (4,'vincent');
SELECT * FROM employee_china UNION SELECT * FROM employee_usa;
SELECT * FROM employee_china UNION ALL SELECT * FROM employee_usa;
9.2连接查询 (非常重要)
连接查询就是求出多个表的乘积,例如t1连接t2,那么查询出的结果就是t1*t2。
SELECT * FROM employee_china,employee_usa;
连接查询会产生笛卡尔积,假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}。可以扩展到多个集合的情况。
那么多表查询产生这样的结果并不是我们想要的,那么怎么去除重复的,不想要的记录呢,当然是通过条件过滤。通常要查询的多个表之间都存在关联关系,那么就通过关联关系去除笛卡尔积。
CREATE TABLE department(
id int,
name varchar(50)
);
INSERT INTO department VALUE(10001,'销售部');
INSERT INTO department VALUE(10002,'咨询部');
INSERT INTO department VALUE(10003,'人事部');
INSERT INTO department VALUE(10004,'技术部');
CREATE TABLE employee(
id int,
name varchar(50),
depno int
);
INSERT INTO employee VALUES(1,'tony',10001);
INSERT INTO employee VALUES(2,'lucy',10001);
INSERT INTO employee VALUES(3,'mia',10001);
INSERT INTO employee VALUES(4,'amy',10002);
INSERT INTO employee VALUES(5,'jerry',10002);
INSERT INTO employee VALUES(6,'micheal',10003);
INSERT INTO employee VALUES(7,'lily',10003);
INSERT INTO employee VALUES(8,'elain',10004);
INSERT INTO employee VALUES(9,'ruly',10004);
INSERT INTO employee VALUES(10,'kk',10004);
INSERT INTO employee VALUES(11,'cici',10004);
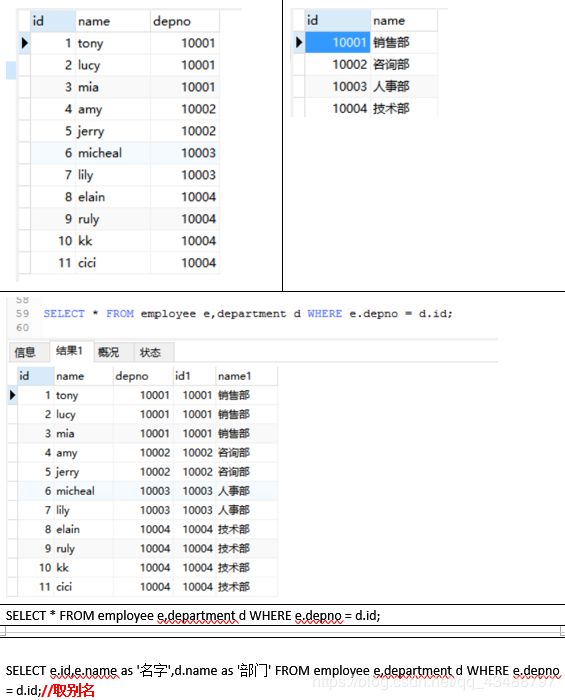
内连接
上面的连接语句就是内连接,但它不是SQL标准中的查询方式,可以理解为方言!SQL标准的内连接为:
SELECT * FROM employee e INNER JOIN department d
ON e.depno=d.id;
外连接(左连接、右连接)
外连接的特点:查询出的结果存在不满足条件的可能。
左连接
是先查询出左表(即以左表为主),然后查询右表,右表中满足条件的显示出来,不满足条件的显示NULL。
INSERT INTO department VALUE(10005,‘保洁部’);
INSERT INTO employee (id,name) VALUES(12,‘ela’);
#左连接
SELECT * FROM employee e LEFT OUTER JOIN department d
ON e.depno=d.id;

右连接
右连接就是先把右表中所有记录都查询出来,然后左表满足条件的显示,不满足显示NULL。
#右连接
SELECT * FROM employee e RIGHT OUTER JOIN department d
ON e.depno=d.id;

自然连接
大家也都知道,连接查询会产生无用笛卡尔积,我们通常使用主外键关系等式来去除它。而自然连接无需你去给出主外键等式,它会自动找到这一等式:
两张连接的表中名称和类型完全一致的列作为条件,例如emp和dept表都存在deptno列,并且类型一致,所以会被自然连接找到!
当然自然连接还有其他的查找条件的方式,但其他方式都可能存在问题!
select * from t_employee natural join t_department;//自然连接
SELECT * FROM t_employee inner JOIN t_department using(depno);//等同于自然连接
select * from t_employee natural left join t_department;//左连接
select * from t_employee leftjoin t_department using(depno);//左连接
select * from t_employee natural right join t_department;//右连接
select * from t_employee right join t_department using(depno);//右连接
子查询
- 子查询概念:
一个select语句中包含另一个完整的select语句。
子查询就是嵌套查询,即SELECT中包含SELECT,如果一条语句中存在两个,或两个以上SELECT,那么就是子查询语句了。
子查询出现的位置:
where后,作为查询条件的一部分;
from后,作表;
当子查询出现在where后作为条件时,还可以使用如下关键字:
any
all
子查询结果集的形式:
单行单列(用于条件)
单行多列(用于条件)
多行单列(用于条件)
多行多列(用于表)
10.MySQL中的函数
10.1时间日期函数
#varchar的长度最多255,如果字符超过255,用text
CREATE TABLE student(
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(10),
entry_date date
);
#如果是date,只保存年月日
INSERT INTO student VALUES (1,‘my’,‘2013-02-12 11:30:30’);
SELECT entry_date FROM student;
#在时分秒加上一个值
SELECT ADDTIME(‘2018-03-15 12:00:00’,‘1:12:20’);
#在月份、年份、日 加上一个值
SELECT DATE_ADD(entry_date,INTERVAL 2 MONTH) FROM student;
SELECT DATE_ADD(entry_date,INTERVAL 2 YEAR) FROM student;
#在月份、年份、日 减上一个值
SELECT DATE_SUB(entry_date,INTERVAL 2 YEAR) FROM student;
#当前时间 用于插入当前的时间
SELECT NOW();
INSERT INTO student VALUES (2,‘mht’,NOW());
SELECT CURRENT_DATE();#获取当前年月日
SELECT CURRENT_TIME();#获取当前时分秒
SELECT CURRENT_TIMESTAMP();#获取当前的年月日时分秒
SELECT DATEDIFF(‘2018-03-15’,‘2018-03-12’);#两个时间的天数差
SELECT DATE(CURRENT_TIMESTAMP());
10.2字符串相关函数
#字符串的拼接
SELECT CONCAT(‘Guo’,‘YongFeng’);
SELECT CONCAT(name,entry_date) FROM student;
#INSTR 查找位置
SELECT INSTR(‘daydayup’,‘up’);
#UCASE(str) 转大写
SELECT UCASE(name) FROM student;
#转小写
SELECT LCASE(name) FROM student;
#LEFT(str,len) 从左边截取len长度字符串
SELECT LEFT(‘ILoveU’,5);
#获取名字长度
SELECT name, LENGTH(name) ‘长度’ FROM student;
#替换
SELECT REPLACE(‘MHt’,‘Ht’,‘DM’);
#STRCMP (string1 ,string2 ) 比较两个字符串的大小
#结果只有3个 0:相等 1:左边字符大 -1 :右边的字符串
SELECT STRCMP(‘cc’,‘aa’);
#SUBSTRING截取字符串
SELECT SUBSTR(‘ILoveU’,2,4);
#LTRIM (string2 ) 去除左空格
SELECT LTRIM(’ gyf ');
#RTRIM (string2 ) 去除右空格
SELECT RTRIM(’ gyf ');
#trim 去除前后空格
SELECT TRIM(’ gyf ');
10.3数学函数
SELECT ABS(-11);#取绝对值
SELECT BIN(8);#转二进制
#CEILING (number2 ) 向上取整
SELECT CEILING(14.5);
SELECT CEILING(-14.5);
#FLOOR (number2 )向下取整
SELECT FLOOR(14.5);
#FORMAT (number,decimal_places ) 保留小数位数:会四舍五入
SELECT FORMAT(3.141565,4);
SELECT FORMAT(3.145565,2);
– HEX (DecimalNumber ) 转十六进制
SELECT LCASE(HEX(15));
– LEAST (number , number2 [,…]) 求最小值
SELECT LEAST(10,4,6);
– MOD (numerator ,denominator ) 求余
SELECT MOD(10,4);#10%3
– RAND([seed]) RAND([seed]) 随机数0~
SELECT RAND();
SELECT RAND(123424);
11.数据库的备份与恢复
目的:保证数据库的安全性,防止黑客删除数据
备份步骤:
- 用管理员的方式打开命令框,输入cmd
- 输入:mysqldump -uroot -proot mydb3 > C:\Users\lenovo\Desktop\mydb3.sql(root root 是账号和密码,要和-u -p挨着写)
恢复步骤:
- 用管理员的方式打开命令框,输入cmd
- 输入:mysql -u root -p 进入数据库
- 创建数据库: create database mydb3;
- 使用数据库: use mydb3
- 恢复: source C:\Users\lenovo\Desktop\mydb3.sql
注:上面的操作时以mydb3为例。
练习题
1.DML练习题(修改数据操作)
1.1将所有员工薪水修改为5000元。
UPDATE emp SET salary=5000
1.2将姓名为zhangsan的员工薪水修改为3000元。
UPDATE emp SET salary=3000 WHERE name=’ zhangsan’;
1.3将姓名为lisi的员工薪水修改为4000元,job改为工程师。
UPDATE emp SET salary=4000,gender=‘female’ WHERE name=‘lisi’;
1.4将wangwu的薪水在原有基础上增加1000元。
UPDATE emp SET salary=salary+1000 WHERE name=‘wangwu’;
2.DML练习题(删除数据操作)
删除表中名称为’zs’的记录。
DELETE FROM emp WHERE name=‘zs’;
删除表中所有记录。
DELETE FROM emp;
使用truncate删除表中记录。
TRUNCATE TABLE emp;
3.DQL(条件查询练习)
3.1查询性别为女,并且年龄50的记录
SELECT * FROM stu WHERE gender=‘female’ AND age<50;
3.2查询学号为S_1001,或者姓名为liSi的记录
SELECT * FROM stu WHERE sid =‘S_1001’ OR sname=‘liSi’;
3.3查询学号为S_1001,S_1002,S_1003的记录
select * from stu where sid in (‘S_1001’,‘S_1002’,‘S_1003’);
3.4查询学号不是S_1001,S_1002,S_1003的记录
select * from stu where sid not in (‘S_1001’,‘S_1002’,‘S_1003’);
3.5查询年龄为null的记录
select * from stu where age is null;
3.6查询年龄在20到40之间的学生记录
select * from stu where age >= 20 and age <= 40;
select * from stu where age between 20 and 40;
3.7查询性别非男的学生记录
SELECT * FROM stu WHERE gender!=‘male’;
或者
SELECT * FROM stu WHERE gender<>‘male’;
或者
SELECT * FROM stu WHERE NOT gender=‘male’;
查询姓名不为null的学生记录
SELECT * FROM stu WHERE sname IS NOT NULL;
或者
SELECT * FROM stu WHERE NOT sname IS NULL;
4.DQL(模糊查询练习)
4.1查询姓名由5个字母构成的学生记录
SELECT *
FROM stu
WHERE sname LIKE ‘_____’;
模糊查询必须使用LIKE关键字。其中 “”匹配任意一个字母,5个“”表示5个任意字母。
4.2查询姓名由5个字母构成,并且第5个字母为“i”的学生记录
SELECT *
FROM stu
WHERE sname LIKE ‘____i’;
4.3查询姓名以“z”开头的学生记录
SELECT *
FROM stu
WHERE sname LIKE ‘z%’;
其中“%”匹配0~n个任何字母。
4.4查询姓名中第2个字母为“i”的学生记录
SELECT *
FROM stu
WHERE sname LIKE ‘_i%’;
4.5查询姓名中包含“a”字母的学生记录
SELECT *
FROM stu
WHERE sname LIKE ‘%a%’;
5.DQL(分组查询练习)
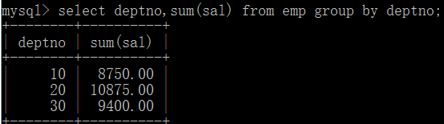
查询每个部门的部门编号和每个部门的工资和:
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno;
查询每个部门的部门编号以及每个部门的人数:
SELECT deptno,COUNT(*)
FROM emp
GROUP BY deptno;
查询每个部门的部门编号以及每个部门工资大于1500的人数:
SELECT deptno,COUNT(*)
FROM emp
WHERE sal>1500
GROUP BY deptno;

HAVING子句
查询工资总和大于9000的部门编号以及工资和:
SELECT deptno, SUM(sal)
FROM emp
GROUP BY deptno
HAVING SUM(sal) > 9000;
6.子查询 (重点,常用)
1.工资高于JONES的员工。
分析:
查询条件:工资>JONES工资,其中JONES工资需要一条子查询。
第一步:查询JONES的工资
SELECT sal FROM emp WHERE ename=‘JONES’
第二步:查询高于甘宁工资的员工
SELECT * FROM emp WHERE sal > (${第一步})
结果:
SELECT * FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename=‘JONES’)
2、查询与SCOTT同一个部门的员工。
子查询作为条件
子查询形式为单行单列
SELECT * FROM emp WHERE deptno = (SELECT deptno FROM emp WHERE ename = ‘SCOTT’);
3、工资高于30号部门所有人的员工信息
分析:
SELECT * FROM emp WHERE sal>(
SELECT MAX(sal) FROM emp WHERE depno=30);
查询条件:工资高于30部门所有人工资,其中30部门所有人工资是子查询。高于所有需要使用all关键字。
第一步:查询30部门所有人工资
SELECT sal FROM emp WHERE depno=30;
第二步:查询高于30部门所有人工资的员工信息
SELECT * FROM emp WHERE sal > ALL (${第一步})
结果:
SELECT * FROM emp WHERE sal > ALL [大于所有](SELECT sal FROM emp WHERE depno=30)
子查询作为条件
子查询形式为多行单列(当子查询结果集形式为多行单列时可以使用ALL或ANY关键字)
4、查询工作和工资与MARTIN(马丁)完全相同的员工信息
分析:
查询条件:工作和工资与MARTIN完全相同,这是子查询
第一步:查询出MARTIN的工作和工资
SELECT job,sal FROM emp WHERE ename=‘MARTIN’
第二步:查询出与MARTIN工作和工资相同的人
SELECT * FROM emp WHERE (job,sal) IN (${第一步})
结果:
SELECT * FROM emp WHERE (job,sal) IN (SELECT job,sal FROM emp WHERE ename=‘MARTIN’)
子查询作为条件,子查询形式为单行多列
5、有2个以上直接下属的员工信息
SELECT * FROM emp WHERE empno IN(
SELECT mgr FROM emp GROUP BY mgr HAVING COUNT(mgr)>=2);
子查询作为条件,子查询形式为多行单列
6、查询员工编号为7788的员工名称、员工工资、部门名称、部门地址
分析:(无需子查询)
查询列:员工名称、员工工资、部门名称、部门地址
条件:员工编号为7788
两种方式
SELECT e.ename,e.sal,d.name,d.location
FROM emp e,depart d
WHERE e.depno = d.depno AND e.empno = ‘7788’;
SELECT e.ename,e.sal,d.name,d.location
FROM emp e,(SELECT depno,name,location FROM depart) d
WHERE e.depno = d.depno AND e.empno = ‘7788’;
- 子查询作为表,子查询形式为多行多列
7.求7369员工编号、姓名、经理编号和经理姓名(自连接:自己连接自己,起别名)
SELECT e1.empno , e1.ename,e2.mgr,e2.ename
FROM emp e1, emp e2
WHERE e1.mgr = e2.empno AND e1.empno = 7369;
8. 求各个部门薪水最高的员工所有信息
select e.* from emp e,
--部门最高工资
(select max(sal) maxsal,depno from emp
group by depno) a
where e.depto = a.depto
and e.sal =a.maxsal
面试题
1.DELETE 、TRUNCATE删除的区别
DELETE 删除表中的数据,表结构还在;删除后的数据可以找回
TRUNCATE 删除是把表直接DROP掉,然后再创建一个同样的新表。删除的数据不能找回。执行速度比DELETE快。
2.having与where的区别
1.having是在分组后对数据进行过滤.
where是在分组前对数据进行过滤
2.having后面可以使用聚合函数(统计函数)
where后面不可以使用聚合函数。
3.WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束。
3.子查询好处
查询员工编号为7788的员工名称、员工工资、部门名称、部门地址
– 多表多列,用于表
SELECT e.ename ‘员工名称’,e.sal ‘工资’, d.name ‘部门名称’,d.location ‘部门地址’
FROM emp e,depart d
WHERE e.depno = d.depno;
#下面的性能好,笛卡尔集的数据会比较少
SELECT e.ename ‘员工名称’,e.sal ‘工资’, d.name ‘部门名称’,d.location ‘部门地址’
FROM emp e,(SELECT depno,name,location FROM depart) d
WHERE e.depno = d.depno;
SELECT depno,name,location FROM depart;
SELECT * FROM depart;
4.UNIQUE 和 PRIMARY KEY 的区别
一个表可以有多个字段声明为 UNIQUE,但只能有一个 PRIMARY KEY 声明;声明为 PRIMAY KEY 的列不允许有空值,但是声明为 UNIQUE 的字段允许空值的存在。
总结
连接查询心得:
连接不限与两张表,连接查询也可以是三张、四张,甚至N张表的连接查询。通常连接查询不可能需要整个笛卡尔积,而只是需要其中一部分,那么这时就需要使用条件来去除不需要的记录。这个条件大多数情况下都是使用主外键关系去除。
两张表的连接查询一定有一个主外键关系,三张表的连接查询就一定有两个主外键关系,所以在大家不是很熟悉连接查询时,首先要学会去除无用笛卡尔积,那么就是用主外键关系作为条件来处理。如果两张表的查询,那么至少有一个主外键条件,三张表连接至少有两个主外键条件。