原文链接:原文链接
注:这篇文章是我自己根据官方文档的原文翻译的,因为能力有限,有些地方翻译的不好,欢迎批评指正,欢迎拍砖!
一、缓存Caches
例子:

1.适用性
缓存在很多数情况下都非常有用,例如,如果计算一个值或者获取一个值时,代价十分昂贵的话,你就可以考虑使用缓存,并且针对某个特定的输入,你可能不止一次需要它的值。
缓存Cache和ConcurrentMap很相像,但又不完全一样。最根本的区别是,ConcurrentMap会保存所有添加到其中的元素直到它们被明确的移除。在另一方面,Cache通常可以配置一个自动化的回收策略去限制它的内存空间。在某些情况下,LoadingCache还是非常有用的,即使它不清除条目。
一般来说,Guava Cache的功能在这些情况下,都是有用的:
(1).你打算牺牲更多内存来换取速度的提升。
(2).缓存的数据会频繁的使用到
(3).Guava Cache只会把数据存储在内存中(Guava Cache是把数据存储于你运行的单个应用上,它不会吧数据存储在文件或外部的服务器上,如果这满足不了你的需求,你可以考虑使用Memcached)
如果上面的这些条件都能比较符合你的要求的话,那么Guava Cache对你来说将是一个完美的选择。正如上面的案例代码中所描述的,你可以使用CacheBuilder来获取一个Cache缓存,但是自定义你自己的缓存才是最有趣的部分。
注意: 如果你不需要上述的这些缓存特性的话,ConcurrentHashMap将会是一个更高效内存缓存选择,但是使用任何老版本的ConcurrentMap都很难复制上面这些缓存特性。
2.population
在你使用Guava Cache时,第一个要问你自己的问题就是: 你有加载或计算一个键所关联的给定值的需求吗?如果有,那么你应该使用CacheLoader。如果没有的话,或许你需要去重写一下默认的实现。但是如果你还是想要原子性"get-if-compute" 语义的话,你可以给get()方法传递一个Callable对象。使用Cache.put()方法可以直接把元素插入到缓存里面,但是我们更偏爱于自动化缓存加载cache loading。因为这让所有的cache缓存的一致性变得更简单。
2.1 CacheLoader
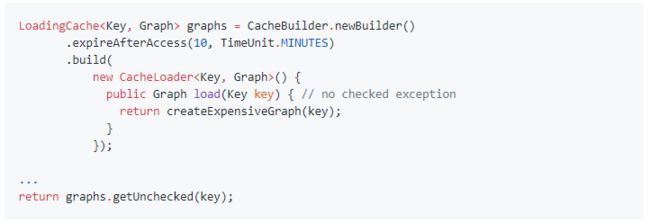
在创建一个LoadingCache时都会附带着一个CacheLoader,创建一个CacheLoader通常都比较简单,只需要实现 V load(K key) throws Exception方法就行了,因此,你可以使用下面的代码来创建一个LoadingCache:

查询一个LoadingCache的正确方式就是调用get(k)方法。这个方法要么返回一个已经存在的缓存值,要么利用缓存的CacheLoader去自动地向cache缓存中存入一个新值。 因为CacheLoader可能会抛出一个异常Excetption ,所以LoadingCache.get(K)方法也有可能抛出一个ExecutionException异常(如果cache loader抛出一个unchecked exception,那么get(k)将抛出一个UncheckedExecutionException)
当然,你也可以选择使用getUnchecked(k),这个方法会把所有的异常包裹在UncheckedExecutionException,但是如果内部的CacheLoader抛出一个检查时异常的话,这可能会产生很奇怪的行为。
我们可以调用getAll(Iterable)方法执行一个大批量的查询操作。默认情况下,针对每一个不在缓存中的key,getAll()方法都会单独调用一次CacheLoader.load。当批量获取比发出许多单独的查询更高效时,你可以重写CacheLoader.loadAll()方法,相应地,getAll(Iterable)的执行性能也会相应提升。
请注意: 你可以写一个CacheLoader.loadAll实现来加载那些没被请求的key值。如果你计算了某一个组里面任一key的值,那么loadAll方法就会与此同时把组里面的剩余的其他key值也加载出来。
2.2 Callable
所有的Guava Cache,不管加载与否 都支持get(K,Callable

2.3 直接插入inserted Directly
可以调用cache.put(key,value)方法向缓存中直接插入值,如果给定键的值已经存在于缓存cache中了,那么原来的值将会被覆盖掉。我们也可以使用Cache.asMap()视图暴露的方法对cache做一些改动。请注意,asMap视图中没有方法可以自动地把条目加载到缓存cache中,因此,Cache.get(K,Callable
3.回收 eviction
最残酷的现实就是我们并没有足够的内存去缓存我们想缓存的一切数据。你必须决定: 在什么时候不应该保存一个缓存条目?
Guava 提供了三种基本类型的对象回收策略: 基于大小的回收,基于时间的回收,基于引用的回收。
3.1基于大小的回收
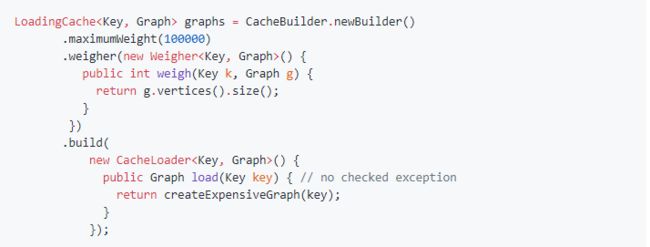
如果你的cache缓存不能超过一定大小的话,只需要使用CacheBuilder.maximumSize(long)方法即可。那么缓存cache将会试图回收那些不经常用到的条目。Warning: 缓存会在到达上限之前把某些条目的内存回收掉。
除此之外,如果不同的条目具有不同权重 --例如,如果你的不同缓存值占用不同的内存空间的话,你可以使用CacheBuilder.weigher(Weigher)方法来指定一个权重,并且可以通过CacheBuilder.maximumWeight(long) 设置最大权重值。在这里补充一个说明,和maximumSize要求的一样,权重值要在条目创建的时候被计算出来的并且在那之后都是不可变的。
3.2 基于时间的回收
CacheBuilder为基于时间的回收提供了俩个方法:
.expireAfterAccess(long,TimeUnit): 只过期那些持续了指定时间的条目。 注意: 回收条目的顺序和基于大小的回收很相似。
.expireAfterWrite(long,TimeUnit): 自条目被创建或最近替换了值之后,过了指定时间后,把这些条目过期。如果缓存中的数据在一段时间之 后变的陈旧不可用的话,那么使用这个策略将是十分可取的。
3.3基于引用的回收
3.4 显示清除
在任何时间,除了等待条目被回收之外,你还可以显示地使用清除数据,可以通过下面的方式来显示地清除:
.单独地使用 Cache.invalidate(key)
.批量清除,可以使用Cache.invalidateAll(keys)
.清除所有条目,可以使用 Cache.invalidateAll()
4.清除监听器Removal Listener
当一个条目被清除时候,你可以为你的缓存指定一个清除监听器来执行一些操作。可以通过 CacheBuilder.removalListener(RemovalListener)方法添加一个监听器。 RemovalListener会得到一个RemovalNotification,RemovalNotification中会指定清除原因RemovalCause,键和值。
注意:RemovalListener抛出的任何异常都会被日志记录并且吞下去。
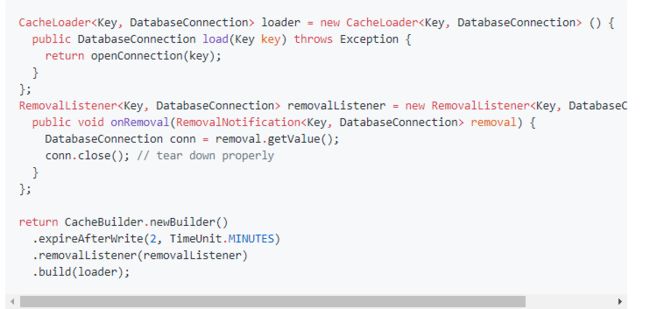
警告:默认情况下,清除监听器的操作都是同步执行的,由于cache的保存操作是在正常的缓存操作期间进行的,所以昂贵的清除监听器就会降低正常的cache缓存的功能。 使用RemovalListeners.asynchronous(RemovalListener, Executor) 可以声明一个异步操作的RemovalListener。
5.什么时候执行清理工作?
使用CacheBuilder创建的Caches 不会自动执行清理和回收工作 相反,它会在在写操作或者读操作期间,只执行小量的维护maintenance操作。
之所以这样做的原因是:
如果我们想连续地执行cache maintenance 缓存维护工作,那么我们就需要创建一个线程,并且该线程的操作会和用户的操作竞争共享锁。 除此之外,某些环境会严格限制线程的创建(因为在那些环境下,线程的创建会导致CacheBuilder不可用)。
相反,我们把选择权交给你,如果你的cache缓存吞吐量比较高的话,你没必要为执行缓存维护(cachemaintenance清除过期条目等类似的操作)而担心。
如果你的cache确实很少执行写操作的话并且你不想因为清理工作而导致缓存读受阻塞,那么你可以创建一个你自己的维护maintenance线程, 这个维护线程会以一定的时间间隔调用Cache.cleanUp()。
如果你想定期为一个写少读多的cache缓存执行维护工作(cache maintenance) ,可以使用ScheduledExecutorService来做这件事。
5.刷新refresh
刷新和回收不太一样,正如LoadingCache.refresh(K)所说的,刷新一个键key的话,会为这个键加载新的值,这可能是异步的。当键正在被刷新时,会依然把旧值返回给调用者。对比之下,回收会强制要求获取值的操作先等待直到新值被加载进去。
如果在刷新过程中出现了什么异常,那么会依然把旧值保存在cache缓存中,并且会针对这个异常做日志记录同时把异常吞掉。
在刷新时,通过重写CacheLoader.reload(K,V)方法, CacheLoader可以指定一个智能的行为:它允许你在计算新值的过程中,仍然还可以继续使用旧值。
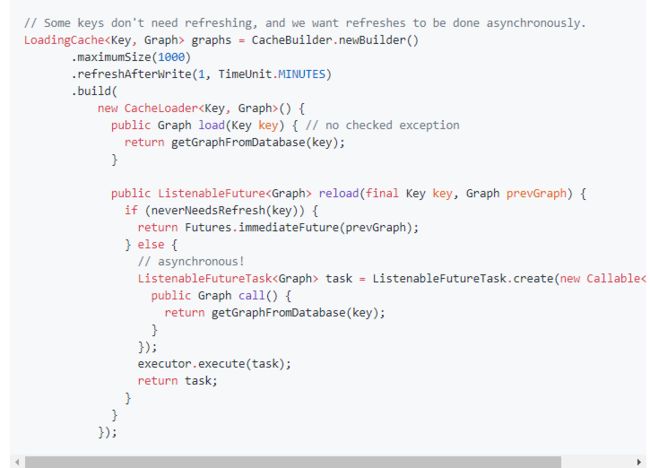
可以使用CacheBuilder.refreshAfterWrite(long,TimeUnit)设置让缓存自动定时刷新。和expireAfterWrite不同,refreshAfterWrite 会使一个key在给定的时间段之后有资格进行刷新操作。但是只有当一个条目被查询过之后,才会实际地初始化一个刷新操作。(如果CacheLoader.reload是一个异步实现,那么刷新操作不会降低查询速度)。例如,你可以在一个cache上同时设置 refreshAfterWrite和expireAfterWrite。
那么当一个条目具有资格执行刷新操作的时候,该条目上的过期定时器就不会被盲目地重置。因此,如果一个条目在它具有了刷新资格之后没被查询过,那么,就允许对它执行过期操作。
6.特性 Features
6.1 统计 Statistics
通过使用CacheBuilder.recordStats(),你可以让Guava Cache进行统计信息收集工作,Cache.stats()方法会返回一个缓存状态CacheStats对象,这个缓存状态对象里面提供如下信息:
(1).hitRate(),返回查询的命中率
(2).averageLoadPenalty(),加载新值时的平均消耗时间
(3).evictionCount(),缓存回收的数量。
还有一些其他的统计信息,这些统计信息在缓存cache调优时,十分有用,如果你这个应用比较重视性能的话,我们建议您关注一下这些统计信息。
6.2 asMap
使用缓存cache的视图,你可以把任一个cache缓存看成一个ConcurrentMap,但是asMap视图是如何跟Cache进行交互的,这里我们需要做一些解释:
(1)cache.asMap() 包含当前加载进Cache缓存中的所有条目,例如,cache.asMap().keySet()包含了所有当前已经加载的键。
(2)asMap().get(key) 本质上等同于cache.getIfPresent(key)并且不会导致值被加载进内存中,这和Map的约定是一致的。
(3)所有的cache的读操作和写操作都会导致访问时间被重置。
7.中断interruption
加载方法比如get()永远不会抛出一个InterruptedException,我们本可以把这些方法设计成支持InterruptedException的,但是我们的支持并不完整,导致的结果就是它的消耗远比它带来的效益要大得多。如果您想了解更多的话,那就继续多下去。