基于scrapy框架的爬虫项目(近乎完美的可视化以及分词呈现)
python爬虫项目(完整项目流程以及源码分享)
注:本网站采集的数据来源于51job.com,仅做学习参考
项目流程大体概述:
友情提示:之后的源代码文件顺序按照如下次序排列。
1.首先,分析网站,明确采集数据,创建scrapy框架环境,编写爬虫主程序;
(本文为:jobspider.py文件)
2.开辟临时存储空间,将主程序爬取的数据进行临时存储(类似于字典封装);
(本文为:items.py文件)
3.通过管道文件获取存储空间中的采集信息,并输出打印到控制台(类似于获取value值的操作);
(本文为:pipelines.py管道文件)
4.更改初始的settings.py文件设置;
(本文为:settings.py文件)
5.编写启动爬虫程序(目的是为了更友好的采集多个不同职位的数据),之后还包括向jobpositiondao.py文件中传入采集记录的方法;
(本文为:startspider.py文件)
6.创建dao包,在其中创建pymysql.json配置文件,存储连接数据库的基本信息;
(本文为:pymysql.json文件)
7.在dao包中创建连接mysql数据库的通用主程序文件;
(本文为:basedao.py文件)
8.在dao包中创建写入(方法)以及查询(方法)数据库中数据的文件;
(本文为:jobpositiondao.py文件)
9.在dao包中创建将用户采集记录写入到数据库的方法文件;
(本文为:taskdao.py文件)
10.数据的优化处理以及向jobpositiondao.py文件中传入采集数据的方法(数据来源于临时存储空间中主程序所采集的数据);
(本文为:mysqlpipelines.py管道文件)
11.编写启动sql查询以及进行可视化显示的文件;
(本文为:showstatics.py文件)
如下为最终可视化效果以及项目源码:

jobspider.py文件,代码如下:
# -*- coding: utf-8 -*-
import scrapy
from ..items import SpiderprojectItem
class JobspiderSpider(scrapy.Spider):
name = 'jobspider'
# allowed_domains = ['www.baidu.com']
start_urls = []
def __init__(self, start_urls=None, taskid=0, *args, **kwargs):
super(JobspiderSpider, self).__init__(*args, **kwargs)
# print(start_urls)
# print(taskid)
self.start_urls.append(start_urls)
self.taskid = int(taskid)
pass
def parse(self, response):
jobItems=response.xpath("//div[@class = 'el']") #返回xpath的选择器列表结果
#遍历选择器列表
jobLen = len(jobItems)
jobCount = 0
# 分页
nextURL = response.xpath("//li[@class='bk']/a/@href").extract()
nextText = response.xpath("//li[@class='bk']/a/text()").extract()
realURL = ""
if nextURL and nextText[-1].strip()=="下一页":
# if nextText[-1].strip()=="下一页":
realURL = response.urljoin(nextURL[-1])
# print('url',url)
pass
pass
for jobItem in jobItems:
jobCount += 1
sItem = SpiderprojectItem()
sItem['taskId']=self.taskid
#extract()解析职位 strip()去掉多余空格
jobposition = jobItem.xpath("p/span/a/text()")
if jobposition:
sItem['jobposition']=jobposition.extract()[0].strip() #相当于字典
#取链接
positionDetail = jobItem.xpath("p[@class='t1 ']/span/a/@href")#返回的是选择器
#解析公司名称
jobCompany = jobItem.xpath("span[@class='t2']/a/text()")
if jobCompany:
sItem['jobCompany'] = jobCompany.extract()[0].strip()
#解析公司地点
jobAddress = jobItem.xpath("span[@class='t3']/text()")
if jobAddress:
sItem['jobAddress'] = jobAddress.extract()[0].strip()
#解析月薪
jobMMoney = jobItem.xpath("span[@class='t4']/text()")
if jobMMoney:
sItem['jobMMoney'] = jobMMoney.extract()[0].strip()
#解析发布日期
FBTime = jobItem.xpath("span[@class='t5']/text()")
if FBTime:
sItem['FBTime'] = FBTime.extract()[0].strip()
if jobposition and jobCompany and jobAddress and jobMMoney and FBTime and positionDetail:
detailURL = positionDetail.extract()[0]
# print(detailURL)
sItem['nextURL'] = realURL
# 访问二级页面
yield scrapy.Request(url=detailURL, callback=self.parse_detail,meta={'item':sItem,'jobLen':jobLen, 'jobCount':jobCount},dont_filter=True)
pass
pass
#将解析的数据写到数据库(用管道)
#实现分页爬取
#定义爬取详情(点进去)页的方法
def parse_detail(self, response):
sItem = response.meta['item']
jobLen = response.meta['jobLen']
jobCount = response.meta['jobCount']
detailData = response.xpath("//div[@class='bmsg job_msg inbox']")
print('detailData:', detailData)
if detailData:
contents=detailData.xpath('//p/text()') #返回当前选择器
ct = ""
if contents:
for temp in contents.extract():
if temp.strip()=="" or temp.strip()=="/":
continue
ct += temp +"\n"
sItem['jobDetail'] = ct
yield sItem #保顺序
pass
# 判断当前页是否爬取完成了,完成就继续爬取下一页
if jobLen == jobCount:
if sItem['nextURL']:
yield scrapy.Request(sItem['nextURL'], self.parse, dont_filter=False)
pass
pass
pass
items.py文件,代码如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
#数据封装的实体类
class SpiderprojectItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
jobposition = scrapy.Field()
jobCompany = scrapy.Field()
jobAddress = scrapy.Field()
jobMMoney = scrapy.Field()
FBTime = scrapy.Field()
nextURL = scrapy.Field()
jobDetail = scrapy.Field() #存放详情页
taskId = scrapy.Field()
pass
pipelines.py管道文件,代码如下:
class SpiderprojectPipeline(object):
def process_item(self, item, spider):
print("通过管道输出数据")
print(item['jobposition'])
print(item['jobCompany'])
print(item['jobAddress'])
print(item['jobMMoney'])
print(item['FBTime'])
print(item['jobDetail'])
return item
settings.py文件,将如下内容前的注释(#)去掉即可:
ROBOTSTXT_OBEY = False #注意,去掉注释符号#后,将原来的值改为False
DOWNLOAD_DELAY = 5 #注意,去掉注释符号#后,将原来的3改为5
SPIDER_MIDDLEWARES = {
'spidermovieproject.middlewares.SpidermovieprojectSpiderMiddleware': 543,
}
DOWNLOADER_MIDDLEWARES = {
'spidermovieproject.middlewares.SpidermovieprojectDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'spidermovieproject.pipelines.SpidermovieprojectPipeline': 300,
}
startspider.py文件,代码如下:
#此脚本是爬虫启动脚本(不用去cmd输入命令)
from scrapy.cmdline import execute
from Include.day022.spiderproject.spiderproject.dao.taskdao import TaskDao
#启动爬虫
td = TaskDao()
result,taskId = td.create(('Python职位数据采集','https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare= '))
if result>0:
execute(['scrapy','crawl','jobspider',
'-a','start_urls=https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare= ',
'-a','taskid='+str(taskId)])
# result,taskId = td.create(('Java职位数据采集','https://search.51job.com/list/000000,000000,0000,00,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='))
#
# if result>0:
# execute(['scrapy','crawl','jobspider',
# '-a','start_urls=https://search.51job.com/list/000000,000000,0000,00,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=',
# '-a','taskid='+str(taskId)])
# result,taskId = td.create(('C++职位数据采集','https://search.51job.com/list/000000,000000,0000,00,9,99,c%252B%252B,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='))
# if result>0:
# execute(['scrapy','crawl','jobspider',
# '-a','start_urls=https://search.51job.com/list/000000,000000,0000,00,9,99,c%252B%252B,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=',
# '-a','taskid='+str(taskId)])
# result,taskId = td.create(('js职位数据采集','https://search.51job.com/list/000000,000000,0000,00,9,99,js,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='))
#
# if result>0:
# execute(['scrapy','crawl','jobspider',
# '-a','start_urls=https://search.51job.com/list/000000,000000,0000,00,9,99,js,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=',
# '-a','taskid='+str(taskId)])
# result,taskId = td.create(('php职位数据采集','https://search.51job.com/list/000000,000000,0000,00,9,99,php,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='))
#
# if result>0:
# execute(['scrapy','crawl','jobspider',
# '-a','start_urls=https://search.51job.com/list/000000,000000,0000,00,9,99,php,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=',
# '-a','taskid='+str(taskId)])
pymysql.json文件,代码样式如下:
{"host":"127.0.0.1","user":"你的数据库的用户名","password":"你的数据库的密码", "database" :"db_movie_data","port":3306}
basedao.py连接数据库文件,代码如下:
import pymysql
import json
import logging
import sys
import os
class BaseDao():
def __init__(self,configPath = 'pymysql.json'):
self.__connection =None
self.__cursor = None
self.__config = json.load(open(os.path.dirname(__file__) + os.sep + configPath,'r')) #通过json配置获得数据的连接配置信息
print(self.__config)
pass
def getConnection(self):
#当有连接对象时,直接返回连接对象
if self.__connection:
return self.__connection
#否则通过建立新的连接对象
try:
self.__connection = pymysql.connect(**self.__config)
return self.__connection
except pymysql.MySQLError as e:
print("Exception"+str(e))
pass
pass
#用于执行Sql语句的通用方法
def execute(self,sql,params):
try:
self.__cursor = self.getConnection().cursor()
#execute:返回的是修改数据的条数
if params:
result = self.__cursor.execute(sql,params)
else:
result = self.__cursor.execute(sql)
return result
except (pymysql.MySQLError,pymysql.DatabaseError,Exception) as e:#捕获多个异常
print("出现数据库访问异常:"+str(e))
self.rollback()
pass
pass
pass
def fetch(self):
if self.__cursor: #提高代码健壮性
return self.__cursor.fetchall()
pass
def commit(self):
if self.__connection:
self.__connection.commit() #回滚问题
pass
def rollback(self):
if self.__connection:
self.__connection.rollback()
pass
def getLastRowId(self):
if self.__cursor:
return self.__cursor.lastrowid
def close(self):
if self.__cursor:
self.__cursor.close()
if self.__connection:
self.__connection.close()
pass
if __name__=="__main__":
ms = BaseDao()
jobpositiondao.py数据库读写文件,代码如下:
from .basedao import BaseDao # . 代表当前目录
#定义一个职位数据操作的数据库访问类
class JobPositionDao(BaseDao):
def __init__(self):
super().__init__()
#向数据库插入职位信息
def create(self,params):
sql = "insert into job_position (jobposition,jobCompany,jobAddress,job_MMoney,FBTime,job_taskid,job_lowsalary,job_highsalary,job_meansalary,job_city) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
result = self.execute(sql,params)
lastRowId = self.getLastRowId()
self.commit()
return result,lastRowId
pass
def createDetail(self,params):
sql = "insert into job_position_detail (detail_desciption,detail_positionid) values (%s,%s)"
result = self.execute(sql,params)
self.commit()
return result
pass
pass
def findPositionClassify(self):
sql = "select avg(job_meansalary),job_taskid,task_title from job_position,job_collect_task where job_position.job_taskid = job_collect_task.task_id group by job_taskid,task_title;"
result = self.execute(sql,params=None)
self.commit()
return self.fetch()
def findCityPositionClassify(self):
sql = "select avg(t1.job_meansalary) as m,t1.job_taskid,t2.task_title,t1.job_city from job_position t1 left join job_collect_task t2 on t1.job_taskid = t2.task_id group by job_taskid,job_city,t2.task_title order by t1.job_taskid asc,m desc;"
result = self.execute(sql,params=None)
self.commit()
return self.fetch()
pass
def findPositionDetail(self): #查询各职位具体内容
sql = "select detail_desciption from job_position_detail"
result = self.execute(sql,params=None)
self.commit()
return self.fetch()
pass
taskdao.py数据库写入采集记录文件,代码如下:
from .basedao import BaseDao
class TaskDao(BaseDao):
def create(self,params):
sql = "insert into job_collect_task (task_title,task_url) values (%s,%s)"
result = self.execute(sql,params)
lastRowId = self.getLastRowId()
self.commit()
self.close()
return result,lastRowId
pass
mysqlpipelines.py数据库管道文件,代码如下:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from .dao.jobpositiondao import JobPositionDao
class SpidermysqlPipeline(object):
def process_item(self, item, spider):
jobPositionDao = JobPositionDao()
try:
jobAddress = item['jobAddress']
jobMMoney = item['jobMMoney']
lowSalary = 0
highSalary = 0
meanSalary = 0
#根据 地址信息 拆分出 城市信息 例:北京市-海淀区
jobCity = jobAddress.split('-')[0]
#处理薪资数据 1.判断单位
if jobMMoney.endswith('万/月'):
jobMMoney = jobMMoney.replace('万/月','')
if jobMMoney.find('-'):
MoneyArray = jobMMoney.split('-')
lowSalary = float(MoneyArray[0])*10000
highSalary = float(MoneyArray[1])*10000
pass
else:
lowSalary = highSalary =float(jobMMoney)*10000
meanSalary = (lowSalary + highSalary)/2
pass
elif jobMMoney.endswith('千/月'):
jobMMoney = jobMMoney.replace('千/月', '')
if jobMMoney.find('-'):
MoneyArray = jobMMoney.split('-')
lowSalary = float(MoneyArray[0]) * 1000
highSalary = float(MoneyArray[1]) * 1000
pass
else:
lowSalary = highSalary = float(jobMMoney) * 1000
meanSalary = (lowSalary + highSalary) / 2
elif jobMMoney.endswith('万/年'):
jobMMoney = jobMMoney.replace('万/年', '')
if jobMMoney.find('-'):
MoneyArray = jobMMoney.split('-')
lowSalary = float(MoneyArray[0]) * 10000/12
highSalary = float(MoneyArray[1]) * 10000/12
pass
else:
lowSalary = highSalary = float(jobMMoney) * 10000/12
meanSalary = (lowSalary + highSalary) / 2
pass
elif jobMMoney.endswith('元/天'):
jobMMoney = jobMMoney.replace('元/天', '')
if jobMMoney.find('-'):
MoneyArray = jobMMoney.split('-')
lowSalary = float(MoneyArray[0]) * 22
highSalary = float(MoneyArray[1]) * 22
pass
else:
lowSalary = highSalary = float(jobMMoney) * 22
meanSalary = (lowSalary + highSalary) / 2
pass
else:
return
result,lastRowId=jobPositionDao.create((item['jobposition'],item['jobCompany'],item['jobAddress'],item['jobMMoney'],item['FBTime'],item['taskId'],lowSalary,highSalary,meanSalary,jobCity))
if result:
jobPositionDao.createDetail((item['jobDetail'],lastRowId))
pass
except Exception as e:
print(e)
finally:
jobPositionDao.close()
return item
showstatics.py是sql查询以及可视化文件,具体代码如下:
from Include.day022.spiderproject.spiderproject.dao.jobpositiondao import JobPositionDao
import numpy as np
import matplotlib.pyplot as plt
jp = JobPositionDao()
# print(jp.findPositionClassify())
# print(jp.findCityPositionClassify())
# 两行代码支持显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#分块代码:
fig = plt.figure()
subplot = fig.add_subplot(2,2,1)
#------绘制各职位平均月薪条状图(第一个子图)---------------
Result_fnPosCla = np.array(jp.findPositionClassify())
Result_fnPosCla = Result_fnPosCla.T
# print(Result_fnPosCla)
xlabel = Result_fnPosCla[2]
x = Result_fnPosCla[1].astype(np.float) #刻度
y = Result_fnPosCla[0].astype(np.float) #工资
bars = subplot.bar(x,y,width=0.3)
subplot.set_xlabel("热门语言职位分类")
subplot.set_ylabel("月薪资")
subplot.set_xticks(x)
subplot.set_xticklabels(xlabel)
subplot.grid(linestyle="--")
for x,y in zip(x,y):
subplot.text(x,y+0.05,'{0}元/月'.format(np.floor(y)),ha = 'center',va = 'bottom')
#--------------绘制折线图(第二个子图)---------------------------
subplot2 = fig.add_subplot(2,2,2)
Result_fnCiPosClas = np.array(jp.findCityPositionClassify())
# print(Result_fnCiPosClas)
#准备数据
Py = [temp for temp in Result_fnCiPosClas if temp[1] == '1']
Py=np.array(Py)
# print(Py)
Ja= [temp for temp in Result_fnCiPosClas if temp[1] == '2']
Ja=np.array(Ja)
# print(Ja)
Cpp= [temp for temp in Result_fnCiPosClas if temp[1] == '3']
Cpp=np.array(Cpp)
# print(Cpp)
Js= [temp for temp in Result_fnCiPosClas if temp[1] == '4']
Js=np.array(Js)
# print(Js)
datalist = []
for py in Py:
for ja in Ja:
for cpp in Cpp:
for js in Js:
if py[3] == ja[3] == cpp[3] == js[3]:
if py[3]==ja[3] == cpp[3] == js[3]!='异地招聘':
datalist.append([py,ja,cpp,js])
data = np.array(datalist)
data = data.T
print(data)
##绘制多折线图
xlabel = [address for address in data[3,0]]
print(xlabel)
pyData = [Salary.astype(np.float) for Salary in data[0,0]]
jaData = [Salary.astype(np.float) for Salary in data[0,1]]
cppData =[Salary.astype(np.float) for Salary in data[0,2]]
jsData = [Salary.astype(np.float) for Salary in data[0,3]]
subplot2.plot(xlabel,pyData,'bp-',alpha=0.5,label = 'python')
subplot2.plot(xlabel,jaData,'mp-',alpha=0.5,label = 'java')
subplot2.plot(xlabel,cppData,'yp-',alpha=0.5,label = 'c++')
subplot2.plot(xlabel,jsData,'gp-',alpha=0.5,label = 'javascript')
#绘制辅助标签
subplot2.set_xlabel("全国热门IT省份")
subplot2.set_ylabel("平均月薪资/元")
subplot2.legend(loc='best')
subplot2.grid(linestyle="--")
#----------------------第三个子图(饼图)-----------------------
subplot3 = fig.add_subplot(2,2,3)
# Result_fnPosCla = np.array(jp.findPositionClassify())
# Result_fnPosCla = Result_fnPosCla.T
# print(Result_fnPosCla)
##准备数据
jobs = [job for job in Result_fnPosCla[2]]
colorlist = ["green","red","orange","yellow"]
colors = [color for color in colorlist]
#比例处理
Salaries = [salary.astype(np.float) for salary in Result_fnPosCla[0]]
sumSalary = np.sum(Salaries) #各语言的月薪资总和
SalaBlis = [temp.astype(np.float)/sumSalary*100 for temp in Result_fnPosCla[0]] #全国范围内大多数城市各热门编程语言的月薪资比例
# print(SalaBlis)
#绘饼图如下
labels = ["{0}\n{1} %\n{2}元/月".format(job,np.floor(SalaBli*1000)/1000,str(salary).split(".")[0] )for job,SalaBli,salary in zip(jobs,SalaBlis,Result_fnPosCla[0])]
explode = np.where(np.array(jobs)=="Python职位数据采集" ,1,0)
subplot3.pie(SalaBlis,colors=colors,labels=labels,explode=explode)
subplot3.axis('equal')
#-------------------词云以及jieba的使用(第四个子图)---------------------------
#jieba
import jieba
from wordcloud import WordCloud, STOPWORDS
subplot4 = fig.add_subplot(2,2,4)
print("内容")
text = str(jp.findPositionDetail())
with open("job_detail_text.txt","w") as fp: #写成.txt文件
fp.write(text)
signatures = []
with open('job_detail_text.txt', mode='r', encoding='gb18030') as fp:
signatures = fp.read()
# 设置屏蔽词,去除特殊符号以及低价值的分词
stopwords = STOPWORDS.copy()
stopwords.add('xa0')
stopwords.add('xa03')
stopwords.add('n')
stopwords.add('n1')
stopwords.add('n2')
stopwords.add('n3')
stopwords.add('n4')
stopwords.add('n5')
stopwords.add('无忧')
stopwords.add('推荐')
stopwords.add('xa009')
stopwords.add('发布')
stopwords.add('有限公司')
stopwords.add('民营公司')
# 导入背景图
bg_image = plt.imread('xiaoxi.jpg')
# 设置词云参数,参数分别表示:画布宽高、背景颜色、背景图形状、字体、屏蔽词、最大词的字体大小
wc = WordCloud(width=1000,height=800,background_color='white', mask=bg_image, font_path='STKAITI.TTF', stopwords=stopwords,max_font_size=220, random_state=50)
# 将分词后数据传入云图
wc.generate_from_text(words)
subplot4.imshow(wc) # 绘制图像
subplot4.axis('off') # 不显示坐标轴
# 保存结果到本地
wc.to_file('51job词云图.jpg')
plt.show()
jp.close()
如下图所示,为可视化结果:
mysql数据表结构如下(本文章用到了三张数据表):
job_collect_task数据表:主要存储采集数据记录
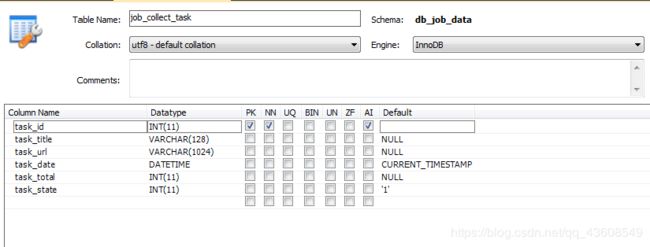
job_position数据表:主要存储一级界面的基本信息

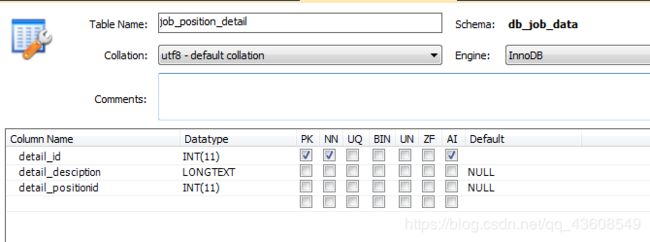
job_position_detail数据表:主要存储二级界面的详细信息
以上就是本项目的具体内容,如有纰漏,请多指教 ^ _ ^